

1TB of Parquet files. Single Node Benchmark. (DuckDB style)
Haters gonna hate.


I give the people what they want; I’m a slave to clicks and the buzz of internet anger and mayhem. Not so long ago, I tried, with limited success, to convince a legion of engineers who were raised on the Snowflake and Databricks teat, that salvation lay right at their feet; all they must do is lean down and put their hand to the plow.
When you’ve been doing what I’ve been doing (writing whatever you damn well please) for over a decade, the list of haters grows ever longer and longer. Get in line pickles.
A little stone tossed into the pond, where do the ripples go? Apparently, my first article on the matter stirred the monsters in the deep. My mamma always told me, haters gonna hate.

I mean, writing such things is the teaching of heresy in the inner circles of the distributed devils and warmongers, whose purse strings are tied inextricably to the masses of data engineering peons passing on their tithe in compute to the inner sanctum of the data illuminati bent on bringing me to account for my many sins.
I’ve made many a power enemy for you, the 99%, yet here I am, still trudging along in the trenches to bring the good word to waiting converts. Midwest boys raised on the river and in the woods don’t bow the knee very easily. The Single Node Rebellion awaits you.
Generating 1TB of Parquet files with Rust.
I’ve got nothing much else today on this wonderful holiday break besides oiling my muzzleloader and waiting for deer season to start, just as well break out cargo and spin up some Rust.
Head over to the GitHub repo and see for yourself.

I went ahead and generated 1 TB of data and put it into an S3 bucket using the above Rust code.
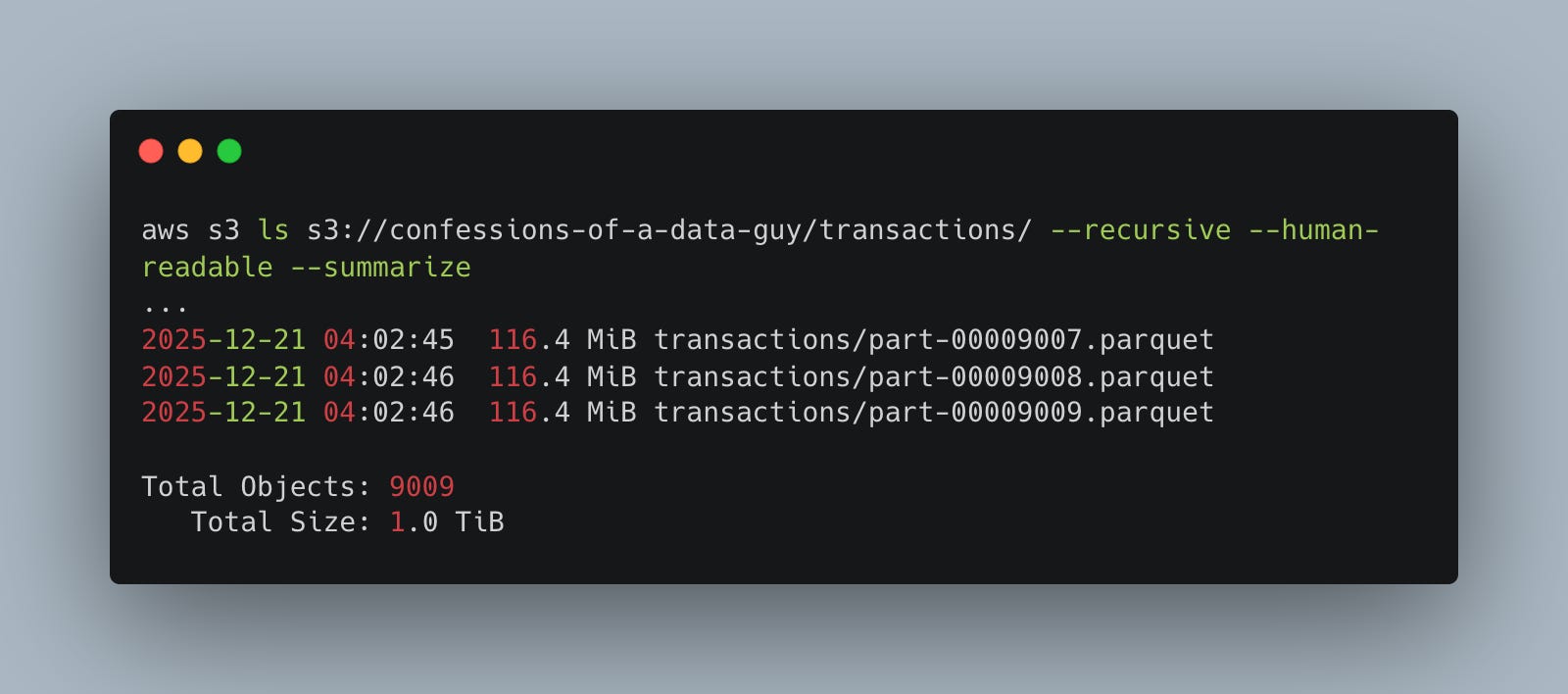
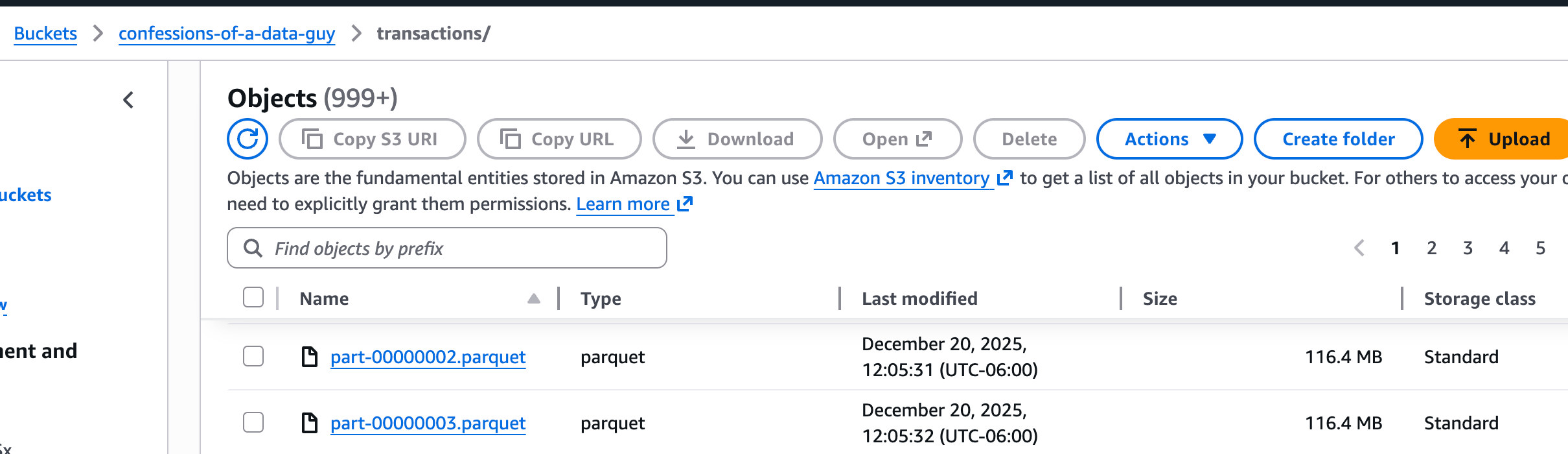
And the schema generated is straightforward.
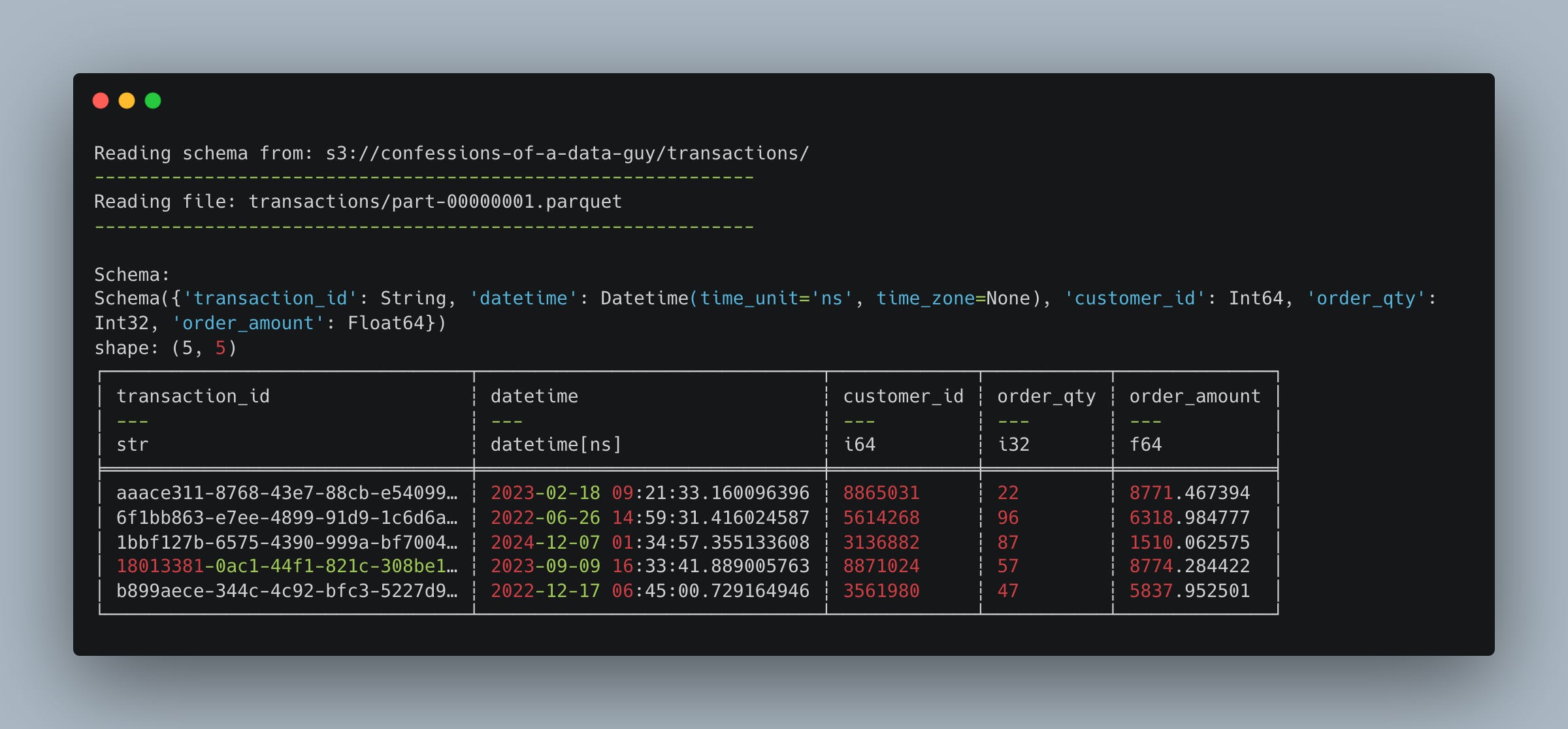
transaction_id
datetime
customer_id
order_qty
order_amount
We should be able to run a straightforward SQL query to piddle with this 1TB of data and see what gremlins, or not, we can sus out.
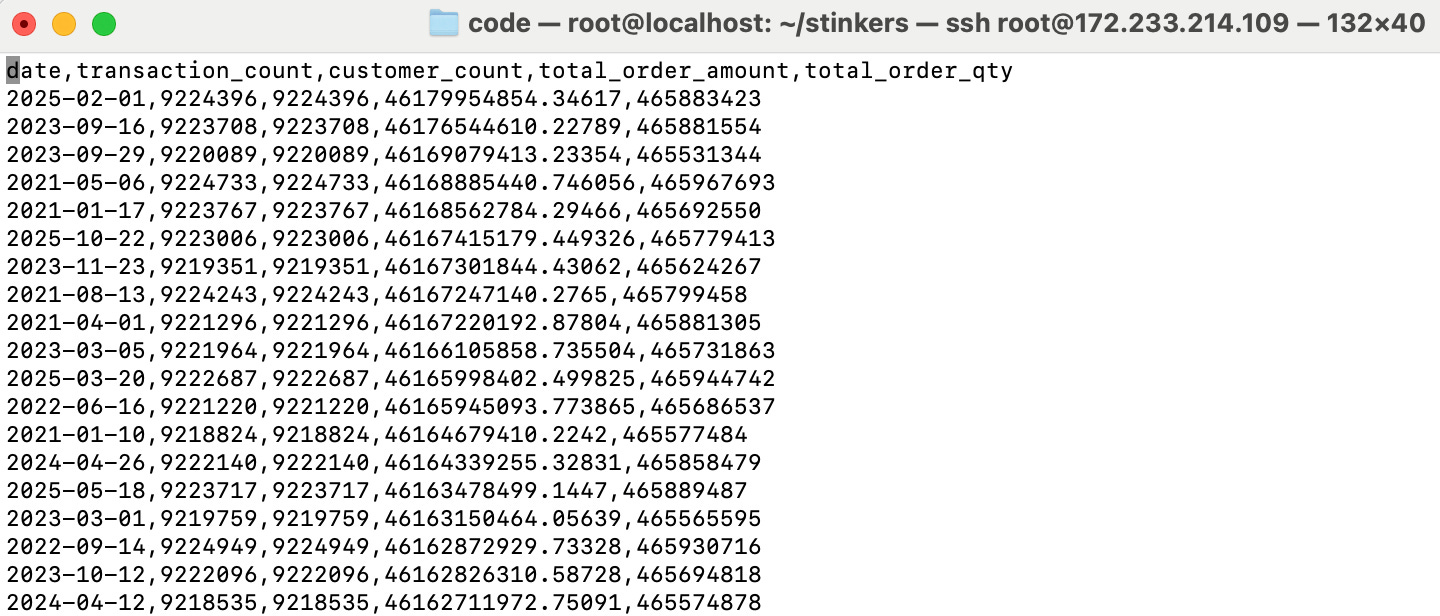
Many sorry saps, complainers, anons, milk toast programmers, and the like, where complaining in my last benchmark that I didn’t FORCE the tools to use every single column and gulp the entire dataset … (why wouldn’t you, that doesn’t happen in production), but to shut the dirty mouths of all those goblins, our query will include every single column of the dataset.
Using Linode, we will spin up LittleStinker (named affectionately after all my haters)
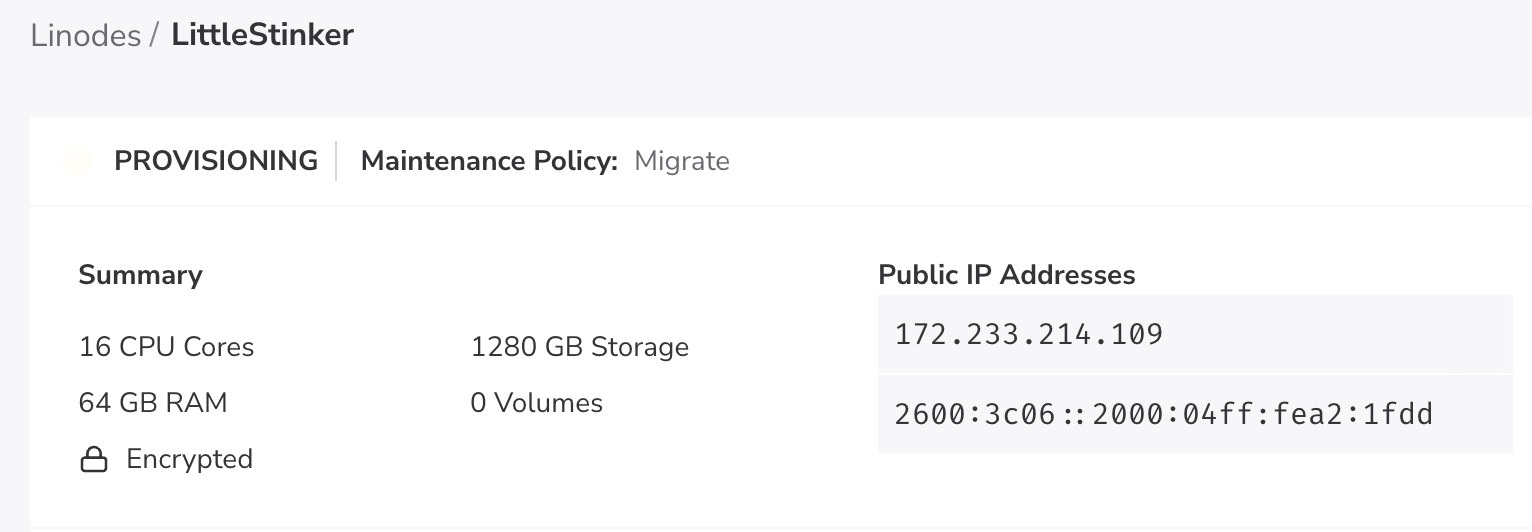
Hold your breath: a gigantic 16 CPUs and 64 GB of RAM. We are going to light ‘er up, make ‘er burn red hot.
>> curl -LsSf https://astral.sh/uv/install.sh | sh
>> uv init stinkers
>> cd stinkers
>> uv add duckdb pyarrow boto3
>> nohup uv run main.py > script.log 2>&1 &Let’s get to the simple code.
DuckDB gobbles 1TB of Parquets in S3.
If anyone can do this deed, it’s DuckDB, our feathered and weathered friend of SQL. Why pick DuckDB? Well, we need something that won’t blow up memory, of course, and DuckDB allows us to do two things …
spill to disk as needed
set MEMORY limits
There is nothing really complicated about this code at all, simply normal DuckDB with the added local disk spill crud and setting the memory limit at 50GB.
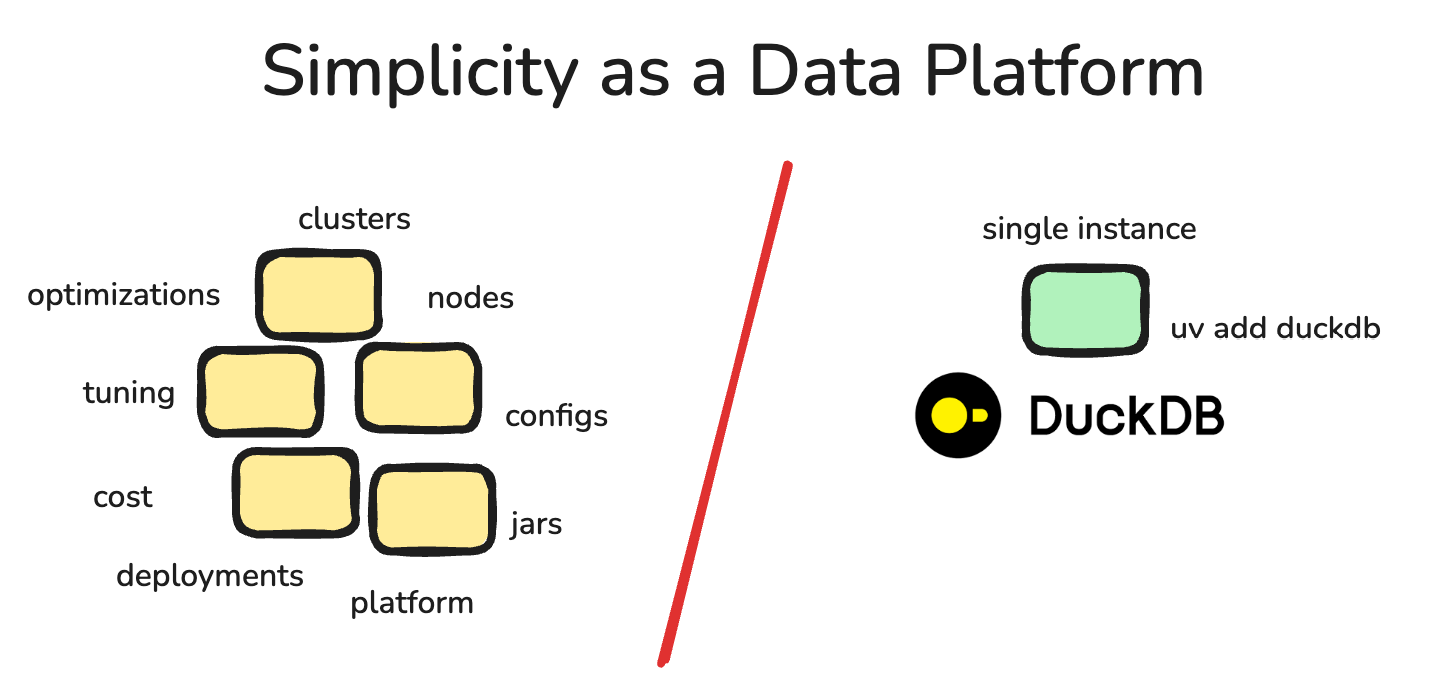
This is part of the attraction. Before we get to results, the more important part that many engineers seem to miss … is the simplicity of this architecture.
No Spark clusters, no complicated installs, dependencies, or JARs, no backflips to use Apache Commet with some JAR to speed up Spark, no Docker images needed.
There is not only real cost savings here in terms of compute ... a single 64GB node vs some oversized cluster at a very high-priced charge. There is real savings in complexity and architecture.It’s hard to imagine anything simpler than a single EC2 instance, or whatever compute, with two extra requirements …
uv or pip
There is no free lunch. I say this as someone who relishes using big-data platforms on Spark that gobble up whatever you throw at them. But it comes at a cost, both real and otherwise.
The hidden cost of using distributed systems for everything is more than just the large compute bill at the end of the month. Complexity, complexity, complexity, it spills out into every part of the data stack, from top to bottom.
Everything becomes complicated “with scale,” no matter how hard they try to hide the pea under the mattress. The truth is that less code == fewer bugs (generally). The truth is that simple infrastructure == fewer problems.
I’m not saying you CAN’T use those platforms. I’m saying some of you DONT HAVE TO.
There are simple options, such as DuckDB and a reasonably sized Linux instance. Literally, a 3- or 4-line install later, there is nothing left to do but work on the data.
Results
DuckDB does just what we tell it to do with that 1TB of parquet data in S3; it makes that Linode 64GB instance sing a song of joy—sitting around 48GB of memory used while in the thick of it.
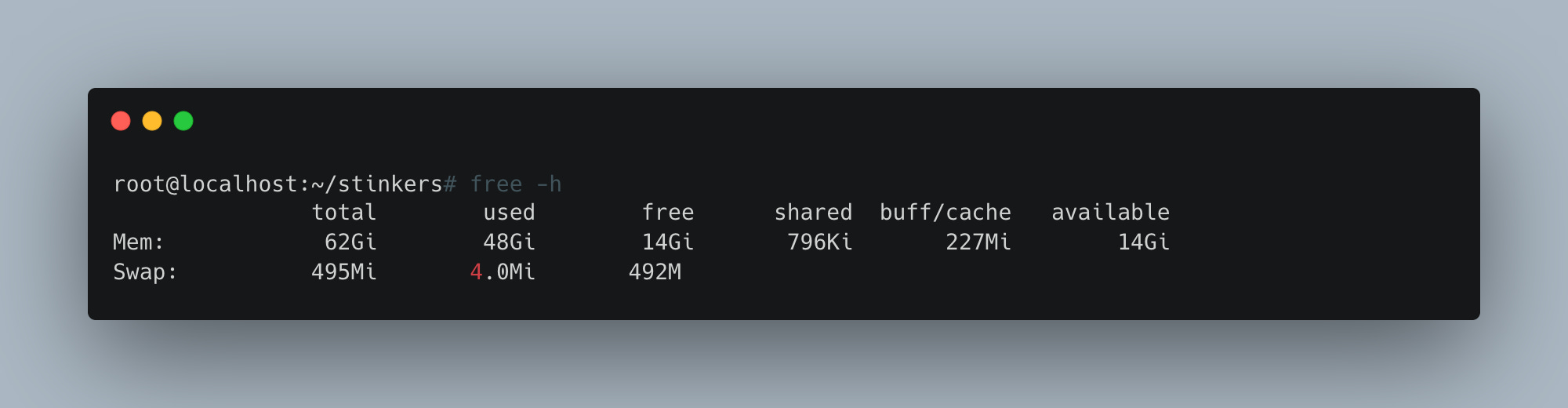
Heck, we aren’t really tuning anything either. I’m sure there’s work to be done, but it’s the holidays, and we're lazy.
Here is what you’ve been waiting for, probably, ignoring all my comments about the existential questions of overall data platform design with a focus on simplicity.
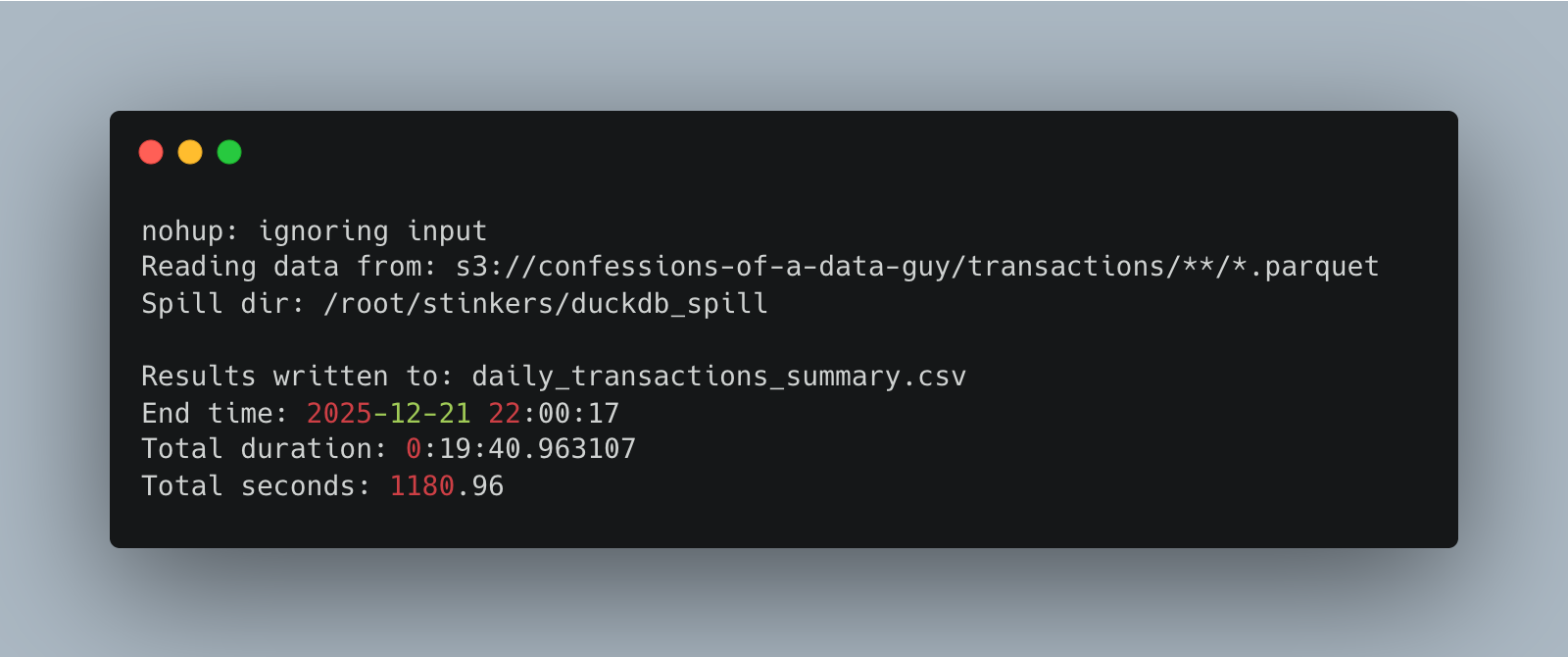
A little less than 20 minutes. Of course, it wrote out the results to the CSV file as well.
I don’t see why we couldn’t keep cranking up the data sizes as well. I’m sure nothing would change but the runtimes. Most of ‘yall ain’t crunching a literal TB in a single query anyway.
What do you think, DuckDB is the only tool that can do such black magic? Not so.
Daft gobbling 1TB of Parquet files in S3.
The truth is, there are plenty of tools that can do this (besides Polars … more to come on that later; it failed this task). We live in a C++ and Rust world where single-node data frameworks are the new law of the land, many of which are more than capable of crunching large datasets.
Daft is one of those Rust-based tools that doesn’t get enough love. It’s always fast and straightforward.
If you are interested in both the DuckDB and Daft code (I’d be curious to know if you can make it run faster), you can find it on GitHub.

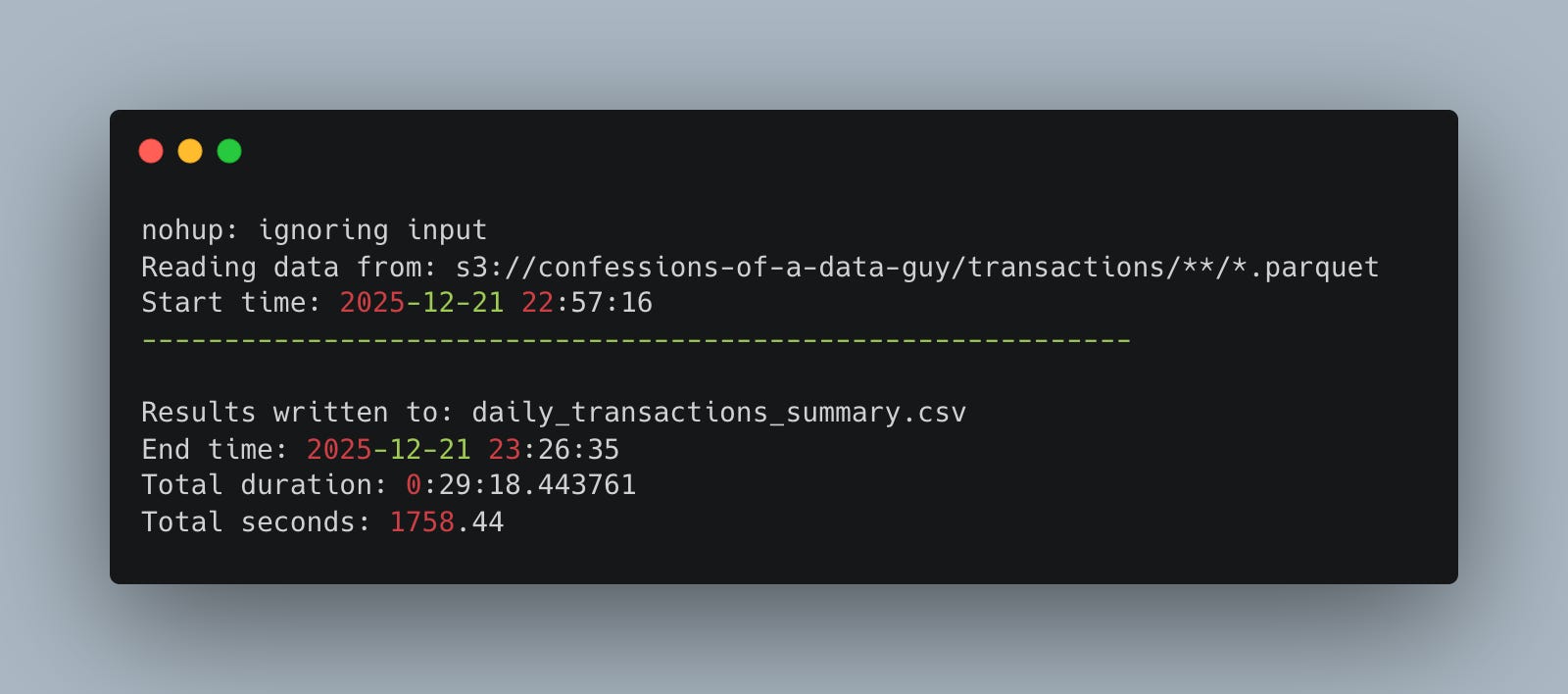
Daft appears to be much slower than DuckDB, but it's probably my fault; who knows? Under 30 minutes for 1TB on a single node, no complaints at the end of the day.
What’s the problem, bruv?
I still don’t get it; it must be some distributed brain rot that is connected to money, fame, fortune, who knows … that causes people to fight against this so hard. Maybe it’s just the folks who have Panda’s brain or something.
Ignoring the fact that we are living in the age of swift and capable single-node processing frameworks is like burying one’s head in the sand. Polars, DuckDB, Daft … these tools are going nowhere and will continue to be widely adopted as time goes by.
Maybe old habits are hard to break, new patterns of thought and solutions can be complicated to adopt once you’ve tread the same path year after year.
A little open-mindedness to consider alternative approaches and solutions is what drives innovation and success.
It’s clear these tools and scale way beyond what we did today. I’m trying to make a conceptual point that apparently is hard to swallow for some. Either way, haters gonna hate.
You, friend, be a healthy learner: always consider all options, push things to the edge, and never take no for an answer. The future is bright and full of interesting things; never forget to turn over the rocks and see what’s underneath.
Ignore the smart, pretentious, loud, doubters, haters who lurk in the shadows and suck all joy and life out of all that is good in this data life we live.
Careful young Padawan…I was chewed out for a recent post on querying a 1TB dataset with the duck because I didn’t give some long-winded exact title such as “I worked with a 1TB dataset in duckdb, and pruned the columns to a subset that is common for analytical queries and it ran in under 30 seconds”…doesn’t quite roll off the tongue 🤣
Haters are gonna hate
irlchortling at “milk toast”