



A Treatise on Database Connections, Cursors, and Transactions.
For Data Engineers


Today I’m feeling a little nostalgic for the old days. The days in the beginning when I was enthralled with Python and Postgres, entangling them together like some medieval monk spinning and winding my web of mysticism and superstition on an unsuspecting audience.
To me, there is nothing more classically Data Engineering from back in the day, and I suppose people still do it now, than connecting to Postgres with some code, probably Python. So easy, yet fraught with so many problems.
Transactions, Cursors, and Connections, all hail and bow before the Great Three. Let’s explore these topics around Python + Databases (Postgres for our examples) to give us the refresher we all need.
You should check out Prefect, the sponsor of the newsletter this week! Prefect is a workflow orchestration tool that gives you observability across all of your data pipelines. Deploy your Python code in minutes with Prefect Cloud.

When Code talks to Database.
When, as Data Engineers, we start to write code that interacts with some relational database, there are a few important topics that we should get a good grasp upon to avoid problems and broken databases.
As we all know, at least some of us, from experience, it doesn’t matter if you’re working on an SQL Server or Postgres instance, these relational database systems are reliable, but at the same time, they can be very fragile.
They are susceptible to bad programming practices that arise from Engineers who possibly don’t understand the implications and importance of the actions they take against a database from their code. It’s easy for things to go wrong, and hard to troubleshoot those problems.
So, let’s cover the basics, Connections, Transactions, and Cursors. We will approach them in the order they are used in the code, as shown below. First, create a connection, then a cursor, then a transaction.
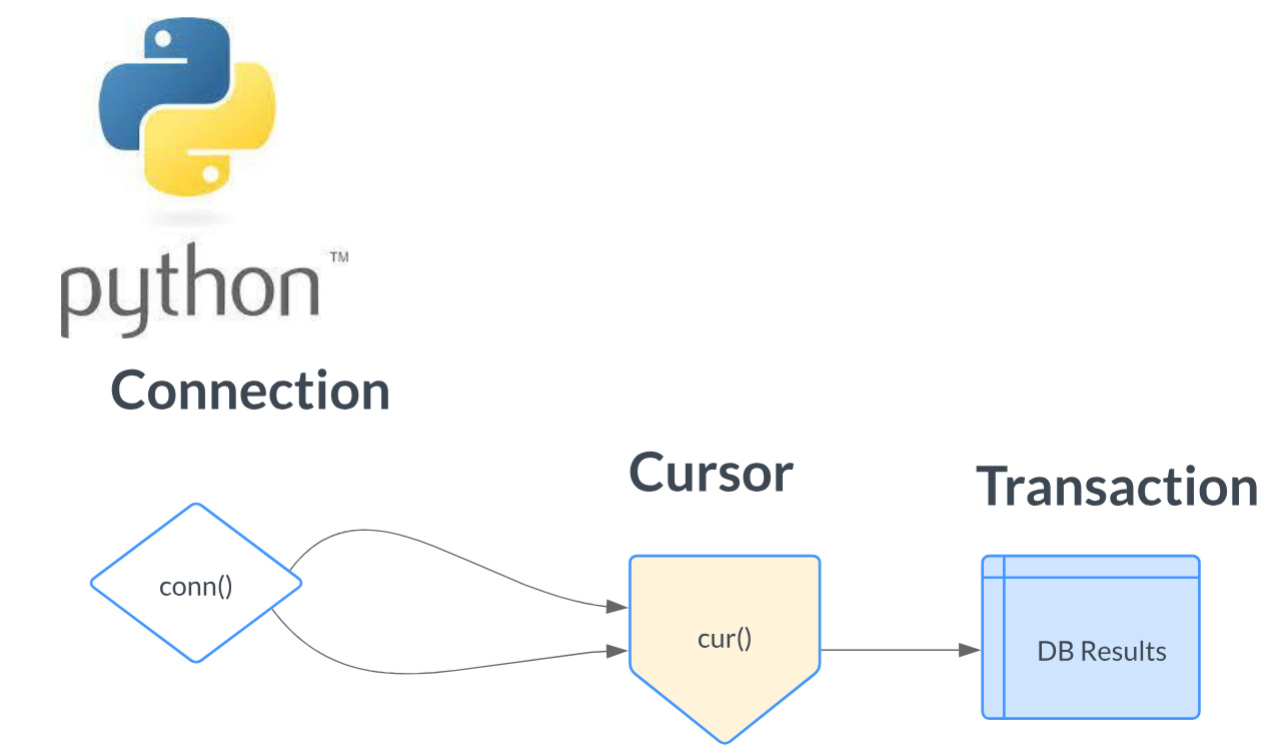
Database Connections.
Connections refer to the connection objects that represent a connection to the (PostgreSQL) database. When programming in Python, you establish a connection to the (PostgreSQL) database using a library (like psycopg2 or SQLAlchemy) to send SQL statements and receive results through that connection.
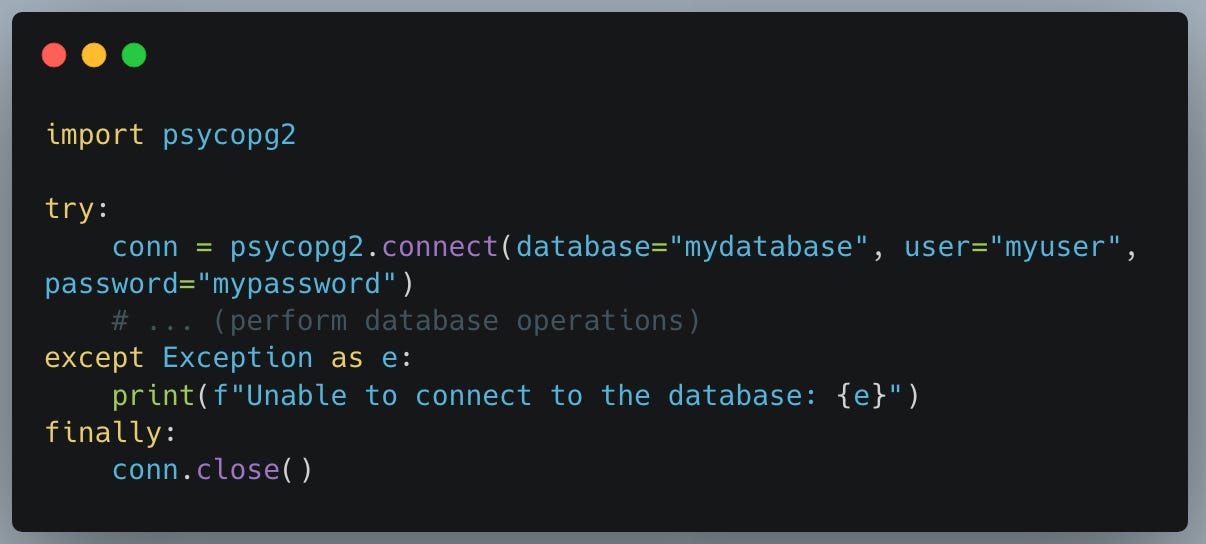
In the Python script, a connection is often created using a connection function with the necessary parameters such as database name, user, password, etc., and it returns a connection object. You generally close the connection after performing the necessary database operations to free up database resources.
Here is an example of creating and closing a connection in Python using the psycopg2 library:
I’ve personally seen the (non) management of database connections by code cause serious problems. Here is what you should think about and keep in mind.
Creating database connections via code for every request is expensive (to the code and the database)
You should consider reusing connections in your program, rather than throwing them away and getting new ones.
Connection pooling is an important topic, learn it.
Always close connections when you are done with your work. Clean up after yourself.
Connections are the gateway to the database, treat them with respect and use them wisely and quickly.
Database/Code Cursors
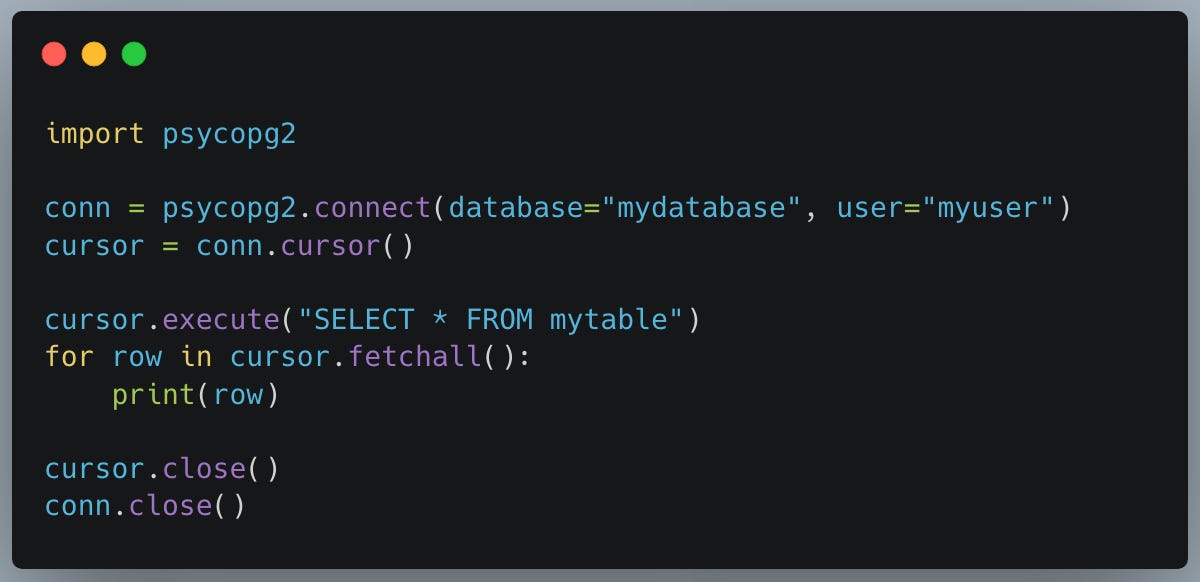
Cursors in Python and databases like PostgreSQL are database objects that allow you to retrieve rows from a result set one at a time. When using Python with PostgreSQL, you often use a cursor object to interact with the database, sending SQL commands and receiving results through the cursor.
The “idea” of a cursor when interacting via code with most any relational database is a central concept.
Here is a simple example of using a cursor to execute a SQL query in Python using the psycopg2 library:
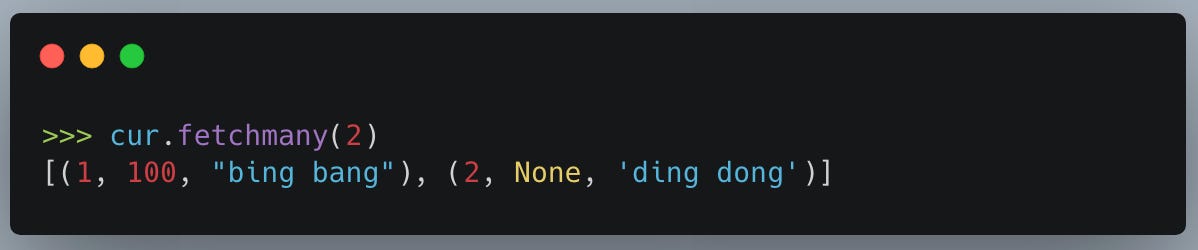
For example, when working with cursors you can fetch results in a few different “ways.”
For example …
Cursors are your entry point into database results. They allow your code to access and iterate results from a query.
Transactions
Database transactions are one of those things that a lot of new developers gloss over, and which come back to bite them in the you-know-what later. Understanding database transactions at least on the surface, is a very important skill to have.
In the context of databases, a transaction is a single unit of work that is performed against a database. Transactions in PostgreSQL are used to manage and maintain the integrity of the database by ensuring that a series of operations either all succeed or all fail as a single unit.
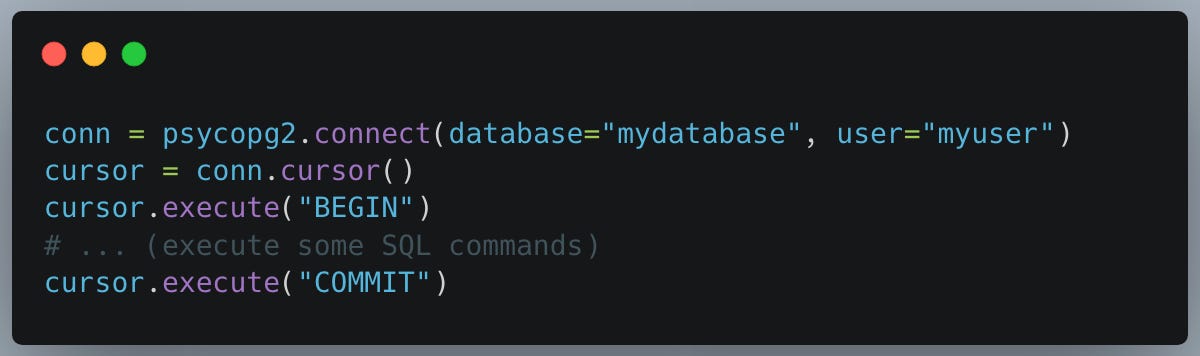
Transactions generally adhere to the ACID properties which stand for:
Atomicity: Ensures that all operations in a transaction are completed successfully; otherwise, the transaction is aborted.
Consistency: Ensures the database remains in a consistent state before and after the transaction.
Isolation: Ensures that transactions are securely and independently processed at the same time without interference.
Durability: Ensures that the results of the transaction are permanent and survive future system and database failures.
In Python, when working with PostgreSQL (often through a library like psycopg2 or SQLAlchemy), you initiate a transaction with a BEGIN statement and can end it with either a COMMIT (to save changes) or a ROLLBACK (to discard changes) statement.
This can be important when doing tasks that require multiple steps that are tied together very closely, where you want an “all or nothing” approach. Either everything works, or nothing goes.
Pitfalls of working with Databases via code.

Working with Python and relational databases is common in a Data Engineering context, but there is always a gloomy side to most things, this included. When doing so, several "gotchas" or pitfalls can emerge. Here's a list of some of these pitfalls:
SQL Injection:
One of the most critical vulnerabilities in web applications is SQL injection. If you concatenate strings to create SQL queries, your code may be vulnerable.
Use parameterized queries or ORM tools to avoid this.
Charset and Collation Mismatch:
Make sure the character set and collation settings of your Python environment match those of your database, especially if you're dealing with non-ASCII characters.
Handling of NULLs:
Remember that in SQL,
NULLis not the same as an empty string or zero. Operations withNULLcan have unexpected results.
Fetching Large Result Sets:
Fetching huge amounts of data into memory can cause performance issues or even crash your application.
Use paging or limit the number of rows returned by queries.
ORM Overhead:
ORMs (like SQLAlchemy, Django ORM) can make database interactions more Pythonic but can add overhead.
Be aware of the "N+1 query problem" when accessing related data.
Hardcoding Configuration:
Hardcoding database configurations (like passwords) in your code is a security risk.
Use environment variables or configuration files and make sure these are kept secure.
Datetime Issues:
Always ensure time zones are handled correctly. This can be a source of many subtle bugs.
Use libraries like
pytzfor timezone handling.
Error Handling:
Not handling database-related errors can lead to data loss or inconsistencies.
Catch and handle errors like connection failures, constraint violations, etc.
The list goes on as well. While on the surface code + database = power and easy, the more complicated the systems and interactions become, the more problems arise and the harder debugging and problem-solving can become.
Do you have stories of nightmares involving database + code? Share them in the comments!!
Daniel, the content is great. Just passing by to say your writing skills are better every day. Keep up.