

All You Can Do Before Airflow:
4 Orchestration Levels From Cron to Full Pipelines


Hello, this is Daniel! Today, we have another Guest Post from Alejandro Aboy. You can check out his Substack The Pipe and the Line.

Alejandro Aboy is a data engineer at Workpath, building scalable pipelines with Airflow, dbt, and the modern data stack. Through The Pipe & The Line, he writes hands-on tutorials on topics like building dbt-style orchestrators with Python and DuckDB, and implementing RAG systems for data engineers
Let’s get started!
Most orchestration tutorials start with Airflow DAGs processing static CSV files.
You see the fancy UI, the complex graphs, the task dependencies, and think, “this is what real data engineering looks like.”
When I say Airflow I also mean Mage, Kestra, Dagster, Prefect or whatever many other options of orchestrator we have out there in the market right now.
I remember when I was starting out and first saw Airflow demos. Beautiful graphs, complex DAGs, Redis queues, Celery workers.
Data enthusiasts might be getting the wrong idea, bootcamps or courses out there place Airflow as the only option to make your workflows come to life.
The truth? There are levels to this. Your orchestration approach should match your project maturity, not your aspirations.
And this principle also gets dragged everywhere else, even to data teams making decisions based on FOMO and now on their own context.
The Modern Data Stack narrative usually pushes dbt, Airflow, Snowflake, and Fivetran as the default starting point.
Most teams don’t need the complete solution on day one, or they don’t even need it at all. There’s something in the middle that offers many alternatives.
Orchestration Fundamentals: Beyond Tool Names
Before diving into tools, let’s talk about what orchestration actually means.
This helped a lot when I was getting started: understanding that knowledge can be transferred and that you can break down the orchestration approach into layers.
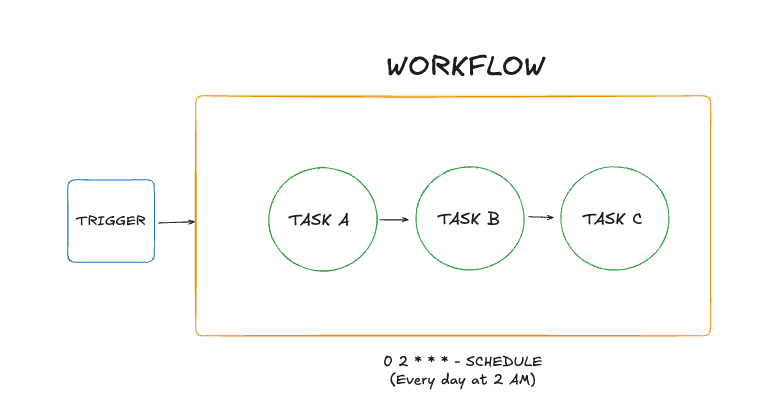
A schedule is when something runs. Daily at 2 AM. Every 15 minutes. Universal across all approaches, from cron to EventBridge.
A task is a discrete unit of work. Extract from API. Transform DataFrame. Load to S3. Building blocks of any workflow.
A workflow is a set of tasks with an execution order.
Dependencies define what runs when. Task B needs Task A’s output. Task C runs in parallel with Task B.
Triggers determine when workflows start beyond scheduled times. File lands in S3, run workflow. Workflow completes, start another. Webhook arrives, process it.
The tools are just different interfaces to these concepts. Airflow calls it DAG, Prefect a workflow, Mage a block, that’s not the point here.
Different Levels of Orchestration For Different Stages
GitHub Repository: Check out the full implementation at Github - Orchestration Levels

I built a project to show what this journey actually looks like.
It’s a real ETL workflow that extracts data from Piwik PRO (web analytics) that calls multiple endpoints, and stores results in S3.
The business logic stays identical across all four orchestration levels. Only the scheduling mechanism changes.
Note that the code won’t change across different stages because that’s not what we are pursuing. What changes is the ecosystem around it based on the use cases to orchestrate it.
Let’s go over the different levels.
Level 1: Local Cron
If you just want to see how this behaves, with a simple POC and without rushing into more complex orchestration setups, start here.
Start here. Cron has been around forever, and it can handle more than you think. You don’t have to worry about setting up anything else for the moment, and it can keep going.
Ask yourself: Can this script finish before the next run?

Level 2: GitHub Actions + Docker
When CRON isn't enough and you need version control and secret management, but still don’t want to worry about infrastructure headaches, GitHub Actions is the right choice.
By default, you are generating logs, monitoring, and manual triggers.
You keep using CRON to set up the schedule. In this particular case, I am using Docker, but it’s not mandatory.
You can see a successful run here.

Level 3: ECR Registry + Lambda
Now we are getting into a more Cloud-based context. But we haven’t got to the orchestrator stage yet.
In this case, I added CI/CD to the mix to deploy the Docker Image to AWS ECR so it’s available for building the Lambda.
There are some extra steps on IAM you need to take care of, not to mention that if you need your script to work locally, on Github Actions and on Lambdas, you will need to adapt it so it can double check in which environment its working.
In this case, AWS EventBridge triggers on schedule, but the trigger could be a file landing in S3 or an SNS topic receiving a message.
You get all the logs from CloudWatch metrics, so that part is already covered.
Lambda’s 15-minute limit gives you an idea on what’s your thresold to consider other options. If your batch job needs more, rethink your approach.

Level 4: Full Orchestration (e.g. Prefect)
You realise that the previous 3 levels are not enough, you need an orchestrator.
Maybe you can get away with chaining lambdas, I’ve been seen saavy data engineers do it and I would not prefer to follow that path.
I decided to use Prefect instead of Airflow because we mentioned knowledge can be transferred, so here’s a good example to prove it.
The principles are quite similar to Airflow.
You use decorators @task, same as Airflow does:
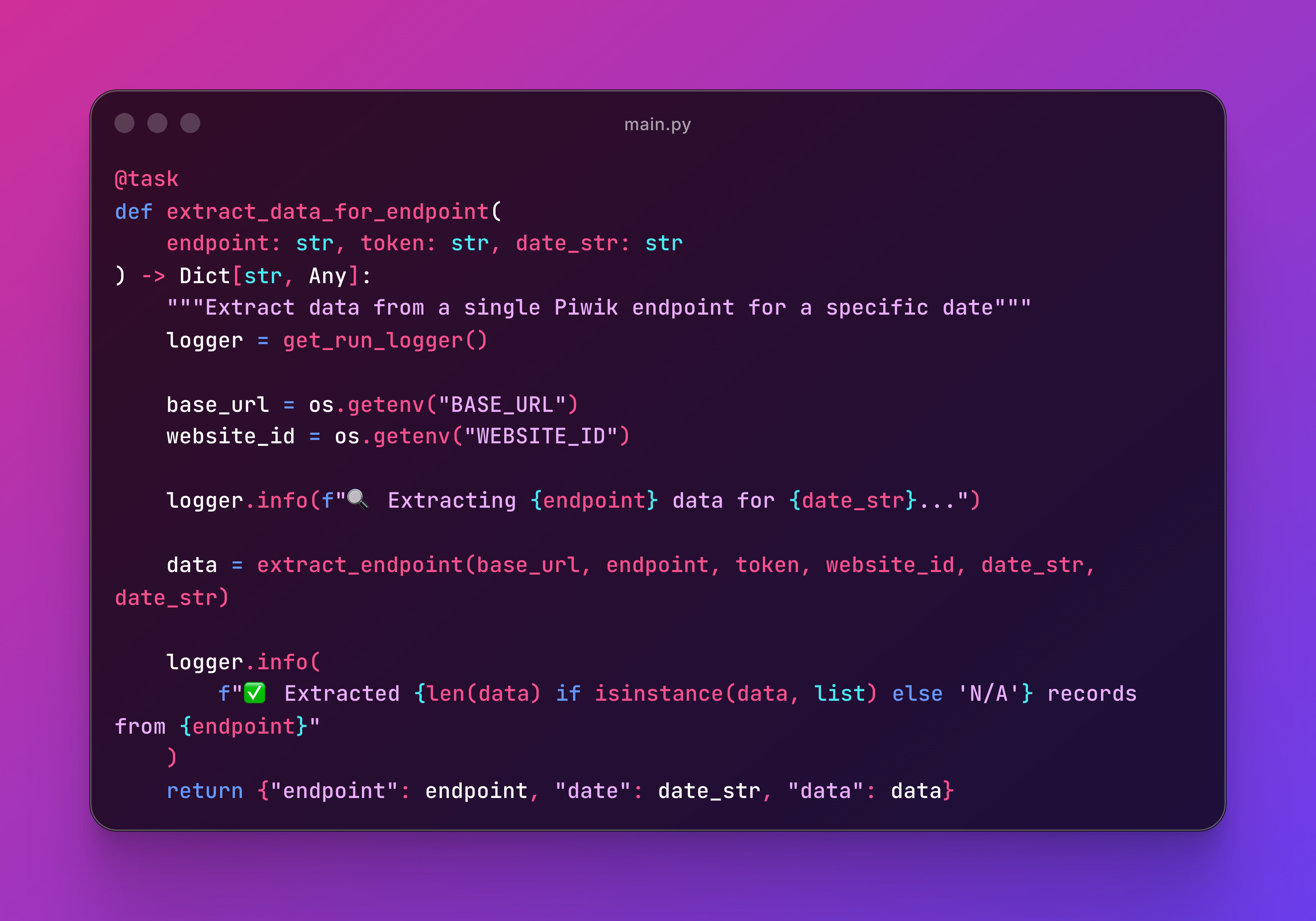
Then can be referenced in @flow, what Airflow calls @dag:
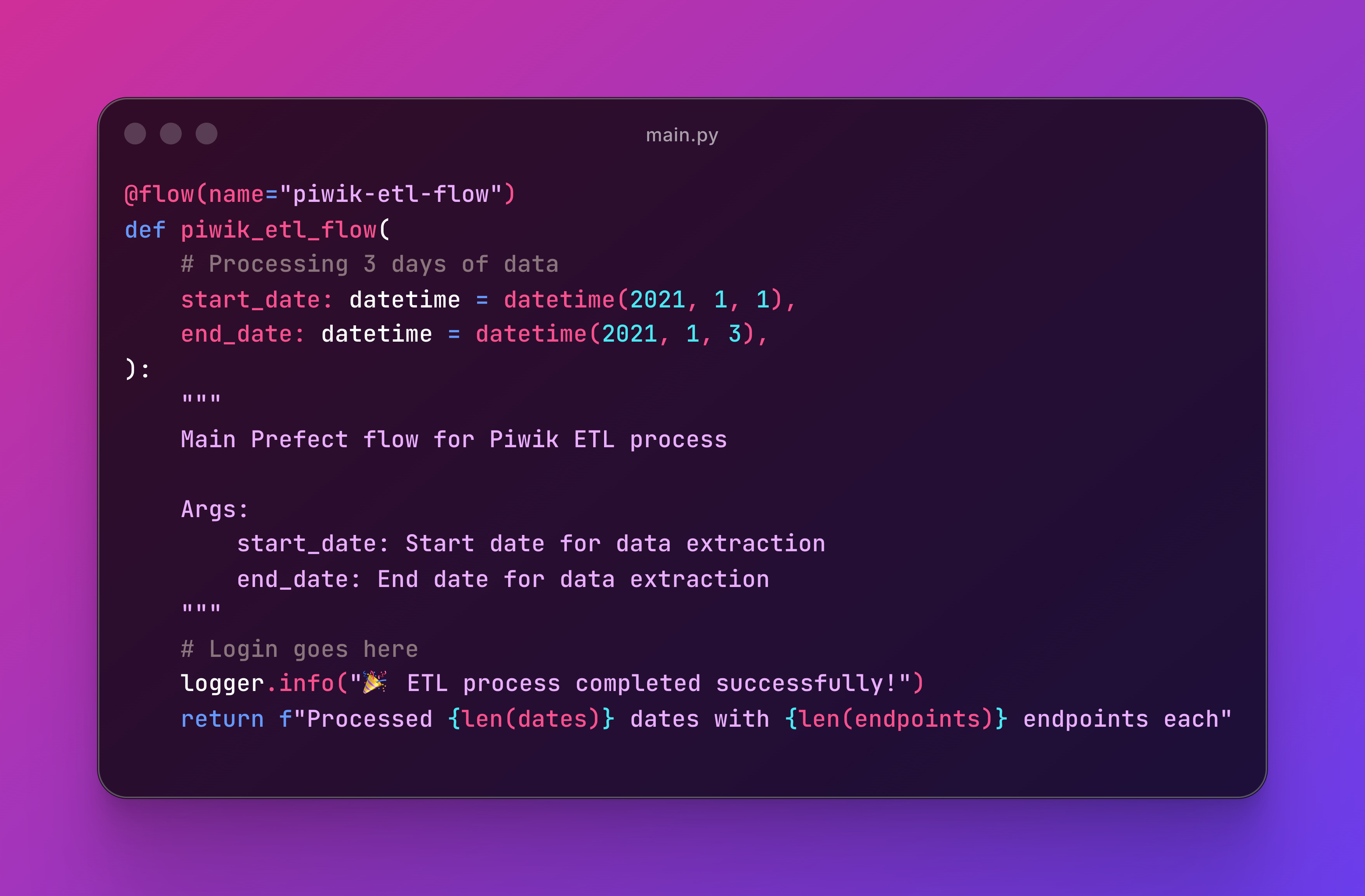
There are many opportunities, such as parallelization, reusable outputs across tasks, custom retry definitions, rich observability, and more.
As you can see, you should only need this when you have these problems and are asking for it

How to Actually Choose
Here’s a decision tree that can help:
Level 1: Local Cron
- Use when: POC, single machine, development testing
- Perfect for: Scripts that run on schedule and finish before the next runLevel 2: GitHub Actions + Docker
- Use when: Need version control for schedules, container parity, no server maintenance
- Perfect for: Small daily batches, simple CI/CD workflows (most teams should stop here)Level 3: ECR Registry + Lambda
- Use when: Deep AWS integration, jobs under 15 minutes, serverless preferred
- Perfect for: Cloud native teams already invested in AWS infrastructureLevel 4: Full Orchestration (Prefect/Airflow)
- Use when: Complex task dependencies, managing dozens of workflows, parallel execution needs
- Perfect for: Multi-step pipelines with genuine orchestration requirements📝 TL;DR
Start simple, feel the pain, then add complexity. At the end of the day, orchestration is about reliability, not sophistication.
Typical orchestration tutorials jump to Airflow with static CSVs, making it seem binary when there are actually four maturity levels
Start simple (cron) and add complexity only when you feel actual pain: version control needs → GitHub Actions, AWS integration → Lambda, task dependencies → Prefect
Your business logic should stay identical across all orchestration levels; only the scheduling mechanism changes
Most teams should stop at GitHub Actions; full orchestrators are justified only with genuine task dependencies and multiple workflows
Orchestration thinking is asking “what’s the simplest thing that works?” not “what tool do senior engineers use?”
 | A guest post by
|
These systems require different levels because getting set-up is so damn hard. Orchestra is a much easier, ready-to-go option that gives you full capability without needing to run through this mental calculation!
GitHub Actions are so underrated! In very lightweight contexts, they are more than up to do the trick.
I have a GH workflows that's been runing every hour for several months now, and it runs like a charm.