

Apache Datafusion Comet (Spark Accelerator)
any better than last time?


As I was winding my way through the various twists and turns of LinkedIn lately, strange it has become the least of the social media evils, by happenstance there popped a post about Comet, that Datafusion baby that’s been trying to take a corner out of Spark for a few years now.
I did poke a stick at Comet back in 2024, but it was a little painful. You can read about that experience blew if you’re interested.

One would have to assume with the increase in Comet chatter, that the project has gotten its sea legs under it and hopefully is a slightly better experience this time. I’m crossing my fingers at this point that I don’t have to build my own JAR this time.
I hope one can simply download the correct pre-built JAR for the Spark version we are interested in. That would be a step in the right direction.
Truth is I have do no “pre-work” when I sit down to write articles like this and explore or revisit tools. Endevoring to simply approach the problem space like the average engineer who interact with some new “thing” for the first time. I want to encounter that same experience and relay that to you. Save you some trouble.
I do not have particularly high hopes from what I might encounter on this foray into Mordor, based on past experience. Let me explain what I mean by this. There are two types of Engineers and tooling they build in the world …
1. Smart engineers building cool tools but lack critical
developer-centric awareness.
2. Smart engineers building cools tools and understand
developer-centric are the key to success.This has been a problem as long as I’ve been (attempting) to write code for the last 20 years. To this day, it simply doesn’t change. Some tool and their ardent acolytes say “Look, we are faster, come unto us.” Yet, they never seem to crack the nut and become mainstream, and can’t figure out why.
All the while continuing to waste their resources on negativity, pulling down other people and tools in an effort to lift themselves into a place by pulling other things down. This never has worked, and never will, longterm, in any sphere in life.
I’ve been privy to see behind the curtains, meeting people at Databricks and MotherDuck (DuckDB), who are creating and running the creme-de-la-creme of data tooling. What makes them succesful?
The have the fastest tool … NO
The focus their energies on negativity and others .. NO
They simply have an almost irresistible set of qualities that is impossible to ignore or hid … or be pulled down in the mud by others.
Positivity in all things
Love what they do and other people
Put Developer experience BEFORE everything else
Serve and give back to the data community
So simple, but yet so hard for some folk to grasp. Why? I don’t know. It’s probably something inside them, unhappy people will always be bumbling along looking for people to suck down into their misery.
Let’s start what I’ve been avoiding
Ok, at some point we have to get to what we are after today, namely figuring out if Apache Datafusion Comet has improved itself over the few years since we last visited it. One thing is for sure. In the Year of Lord 2026 if someone is using Spark, they better be using Databricks.
I know there are still a few odd old-school curmudgeons banging around in the dark corners, BUT if you want to be taken seriously in the Spark world today, you must go where the users are. Databricks. Sorry. Not Sorry.
Can we get Comet working on Databricks?
First, we need a JAR.
The GitHub page for Comet gives a semi-not-so-much clear instructions.

The installation guide gives us more info, including what Spark Versions we are allowed to use with Comet.

So, we will have to pick a DBR version that matches something in here. Strangely, they say “Published jar files are only available for released versions, ” which insinuates they have published, pre-built JARs for supported Spark versions, although there is no link or mention of where to find those JARs … one could assume Maven maybe?
You would think linking and being obvious about where pre-built JARs are located for potential dev “customers” might be a fairly obvious thing to do. Or not.
Ok, let’s go find some JARs (hopefully), before falling back to building our own. Indeed, they have a Maven repo with the different Spark version Jars.

We should be able to line this up with a Databricks DBR version that fits our needs eh.

Let’s pick Spark 4.0.
So now we’ve got our comet-common-spark4.0_2.13-0.16.0.jar that we can align with DBR 17.3 LTS. Next, we just need to gather the required Spark configs needed to go along with this JAR, we can unwind what we need from the Comet examples given.
Based on what I can see, this is what we will need to add to our Databricks Cluster config.
--jars $COMET_JAR \
--conf spark.driver.extraClassPath=$COMET_JAR \
--conf spark.executor.extraClassPath=$COMET_JAR \
--conf spark.plugins=org.apache.spark.CometPlugin \
--conf spark.shuffle.manager=org.apache.spark.sql.comet.execution.shuffle.CometShuffleManager \
--conf spark.comet.explainFallback.enabled=true \As well as possibly
--driver-class-path spark/target/comet-spark-spark4.1_2.13-0.17.0-SNAPSHOT.jar
Also, if you want your brain to go numb, you can read through the Comet Configs located here, it’s the next page that comes up in the Installation Instructions.
I’m assuming some of these are important, and greatly assist with how Comet performs, but God knows how one is simply supposed to scroll through all 1000 of them and know what to do. Your guess is as good as mine.
Might be nice if they put some sort of overview of the the most important ones, things that should not be left to default, or the most commonly used ones and put some sort of conceptual overview together for how to tune them.
To top it all off, there is a very large and complex “Compatibility” section detailing what Comet can, and cannot do, where it will fall back to Spark etc. This one will give you a headache as well.
Between that and the configs, you either need to have an ungodly amount of time on your hands, or be a core maintainer … or know someone who is … at that point you can probably get everything figured out.
If you meet someone behind the old oak tree at midnight, throw salt over your left shoulder, and say these words … “Ooga Booga” 3 times over. At that point you will know if the production Spark pipeline you have will benefit from Comet and how to tune the configs for optimal performance.
Tear* … let’s do this thing.
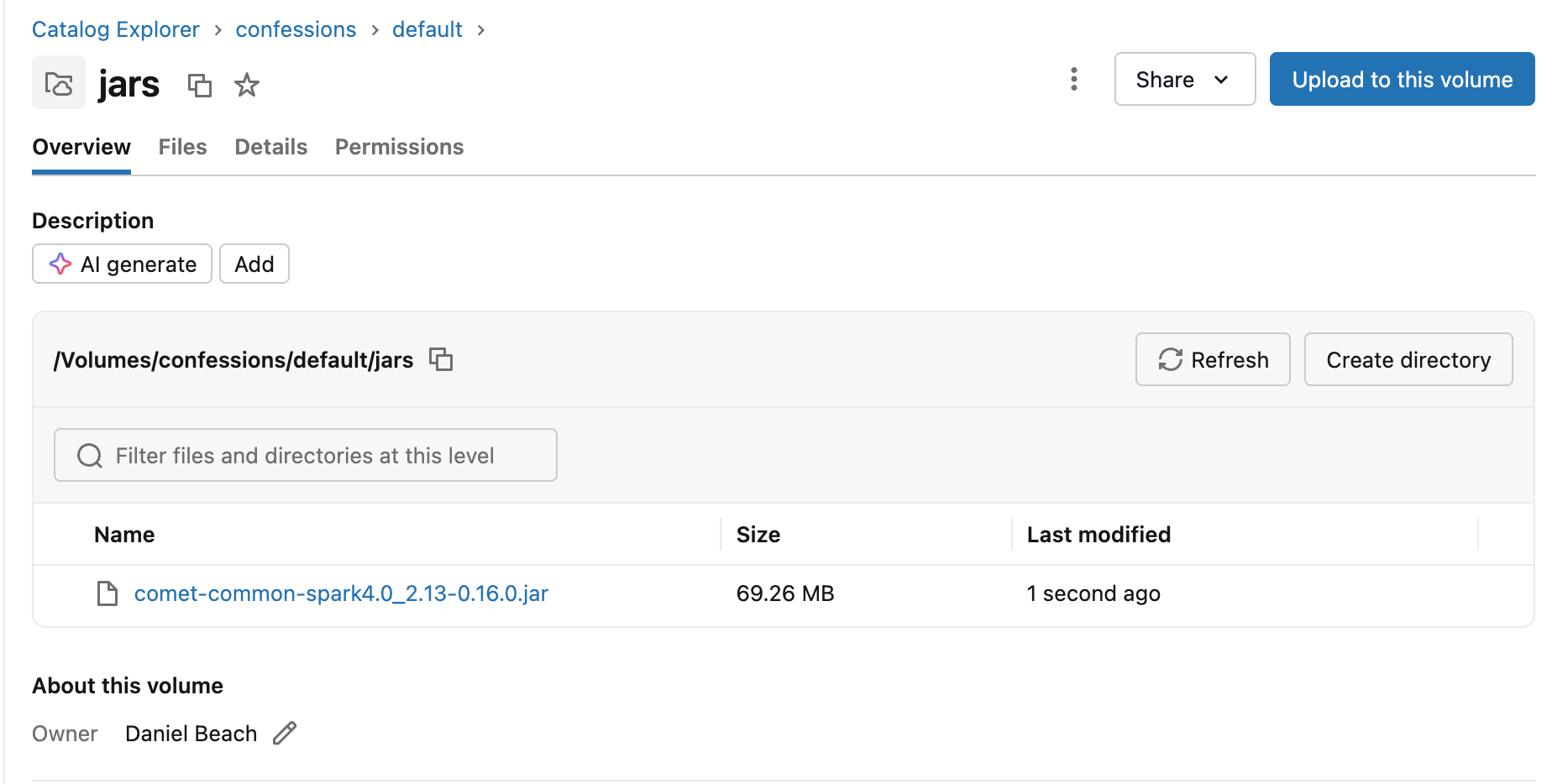
Ok, let’s switch over to Databricks and get our cluster setup. First, let’s get this JAR available somewhere Databricks clusters can access it. Probably a Volume would be the easiest way to do this.
Here I have made a volume Volumes/confessions/default/jars and put our JAR up in there.
Next, let’s make a little init.sh script that can run on any cluster.
#!/bin/bash
COMET_JAR="/Volumes/confessions/default/jars/comet-common-spark4.0_2.13-0.16.0.jar"
LOCAL_JAR="/databricks/jars/comet-common-spark4.0_2.13-0.16.0.jar"
cp "$COMET_JAR" "$LOCAL_JAR"
chmod 644 "$LOCAL_JAR"Next, we can put that bash file into the same Databricks volume.

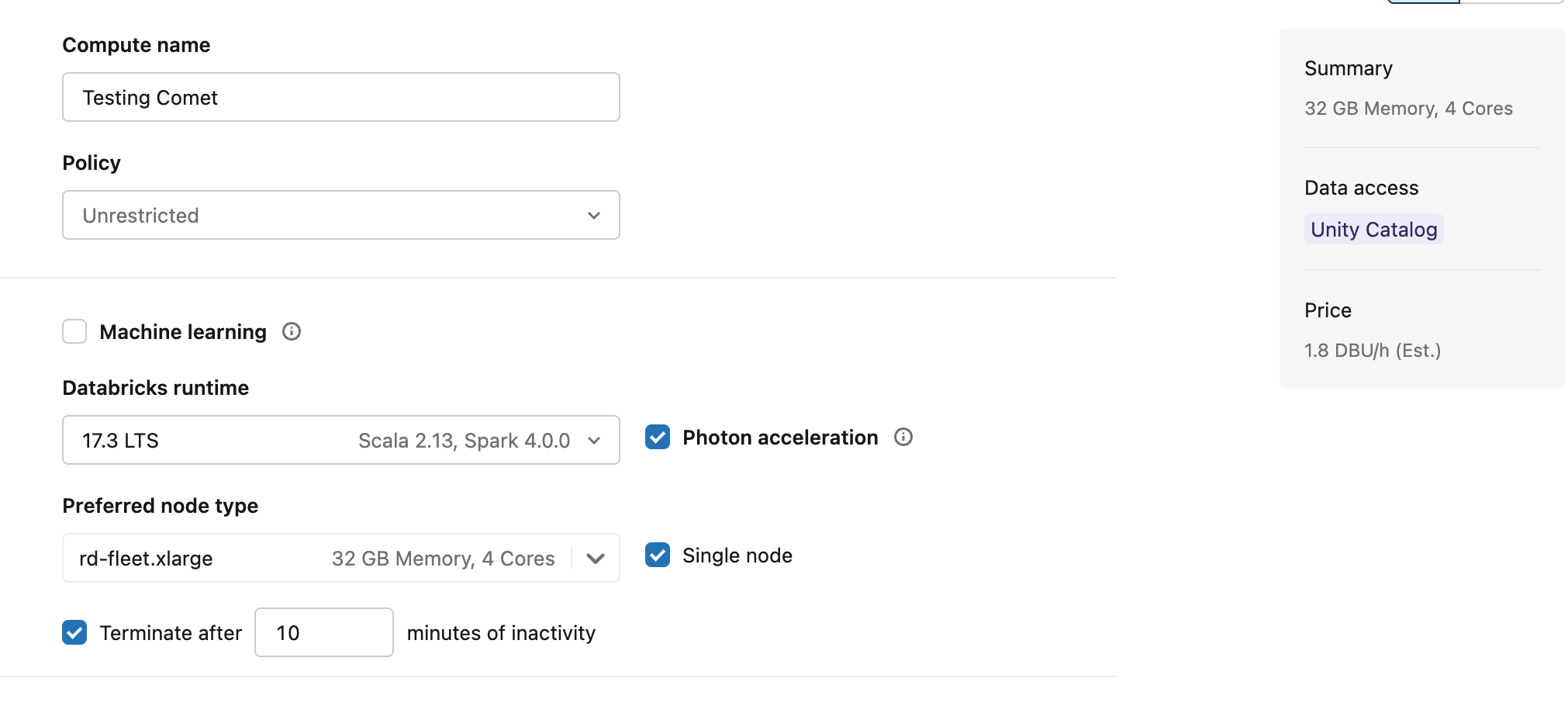
Ok, so let’s just use one of those dreaded All-Purpose clusters in Databricks, configure it with the init script, as well as the rest of our configs.
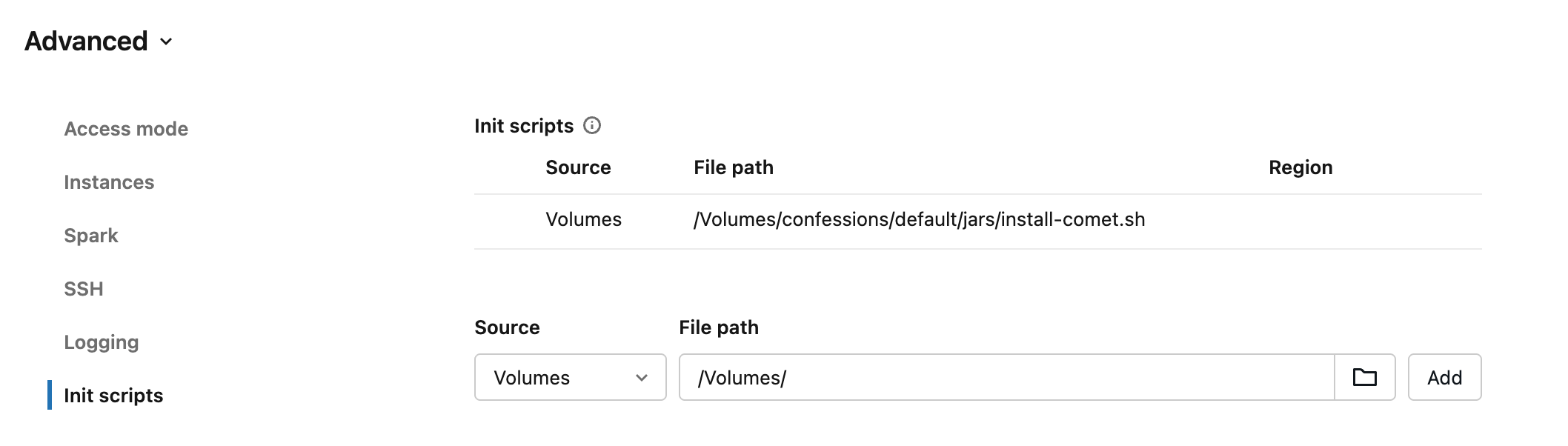
As well, we can add in that init script we made.
And finally, our Spark configs for Comet.

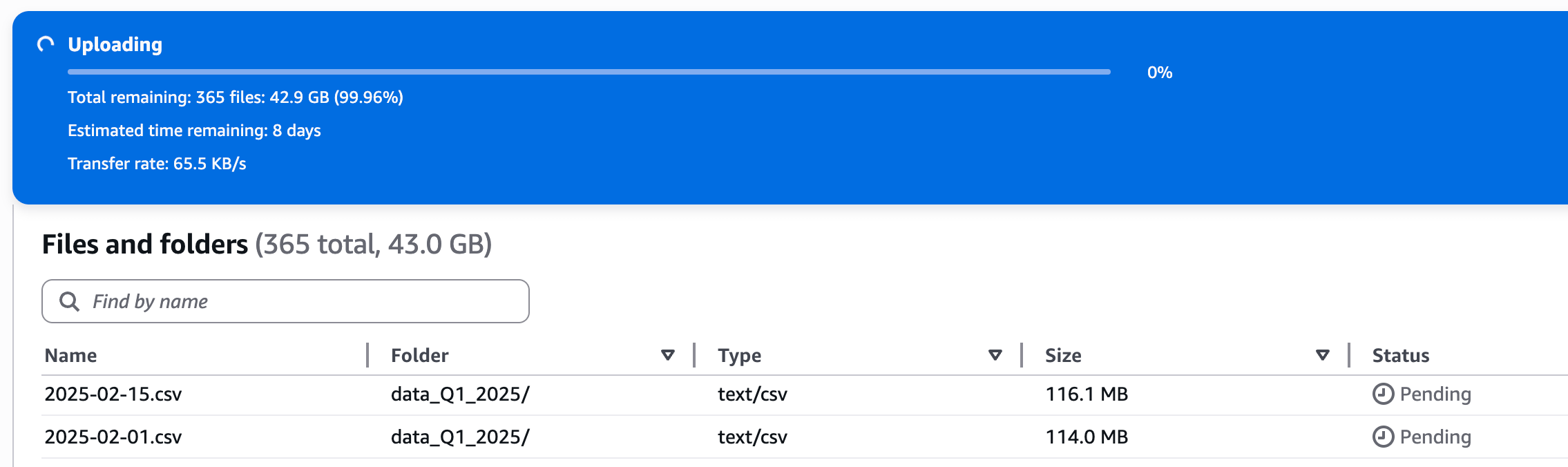
I have zero idea if this is going to work, just a shot in the dark. We will find out soon enough, maybe. Ok, next we need some data in s3 to munge around with. Let’s use the open-source Backblaze harddrive dataset.

We can get all the 2025 data and use that. This is 365 files for about 43GB of CSV data in total. Not big data, but then again, most Spark pipelines running today picking up CSV files at not munching on Big Data.
This will do for now. Let’s write some average Spark code that would represent the average Spark pipeline in production.
