

Apache Datafusion Comet
making Apache Spark scream


Y’all knew this was coming, didn’t you? I mean think about it. We live in a TikTok and Instagram culture, we want stuff quick, now, and above all fast. Of course, it’s never fast enough, we need it faster.
We are Data Engineers, after all, we spend our days cracking the proverbial whip on those bits and bits, we want to make them scream for mercy. It’s every engineer’s obsession is it not? To make a thing faster?
Today, we are going to poke at something that’s trying to make Apache Spark faster. No surprise there. With the rise of Databricks … Apache Spark has become the de facto tool to process data … Big Data or NOT.
Meaning there is a real need to have Spark work fast on datasets that aren’t 300TBs. Everyone wants Spark to be faster.

“Apache DataFusion Comet is an Apache Spark plugin that uses Apache DataFusion as a native runtime to achieve improvement in terms of query efficiency and query runtime.”
A shift in Data Engineering tooling.
I want to take a moment to talk about something interesting, a trend that I’ve perceived in Data Engineering over the last 10 years+.
Basically, it can be summed up as …
“Rust and Rust based tooling is replacing Java/Scala tooling and infastructure in many places.”
Things like this don’t happen overnight, they take time, and they happen by degrees. With the advent of things like Apache Arrow, tools like Polars and Datafusion, and the general popularity of Rust for building … there seems to be an ever-increasing flow of Rust making inroads and supplanting the JVM as the defacto tool.
Heck, even Databricks has started to develop ways around the JVM to increase things (think Photon etc).
Back to Apache Datafusion Comet.
Let’s get back on track before we run this train off the track. Apache Datafusion Comet. If you are unfamiliar with Datafusion you should probably check yourself first, second just do some reading and get with it.
Datafusion is Rust-based, built for Dataframes and SQL, and is quickly becoming the defacto tool … for building other tools.
It’s the GOAT, and now apparently it’s being used to “speed up” Apache Spark by bypassing the JVM.
“Apache DataFusion Comet is a high-performance accelerator for Apache Spark, built on top of the powerful Apache DataFusion query engine. Comet is designed to significantly enhance the performance of Apache Spark workloads while leveraging commodity hardware and seamlessly integrating with the Spark ecosystem without requiring any code changes.”
Below is the classic TPC benchmark with this tool, which we of course no one ever messed with or lied about.

Today we are going to see if the Apache Datafusion Comet is a bunch of dirty old liars or if they are the real deal. We shall
install it
run it
performance test it against vanilla Spark
We shall see if our dreams will be fulfilled or dashed upon the rocky crags of reality.
First, let’s just see what the instructions are like for installing and running Apache Datafusion Comet on a Spark cluster … because that is the point after all isn’t it?
Here is the official install guide.
It appears you need …
>= Apache Spark 3.3
JDK8+
Linux or Mac
Next, the instructions say you can build the binary from scratch using the Git repo, or use the official pre-build binaries located here.
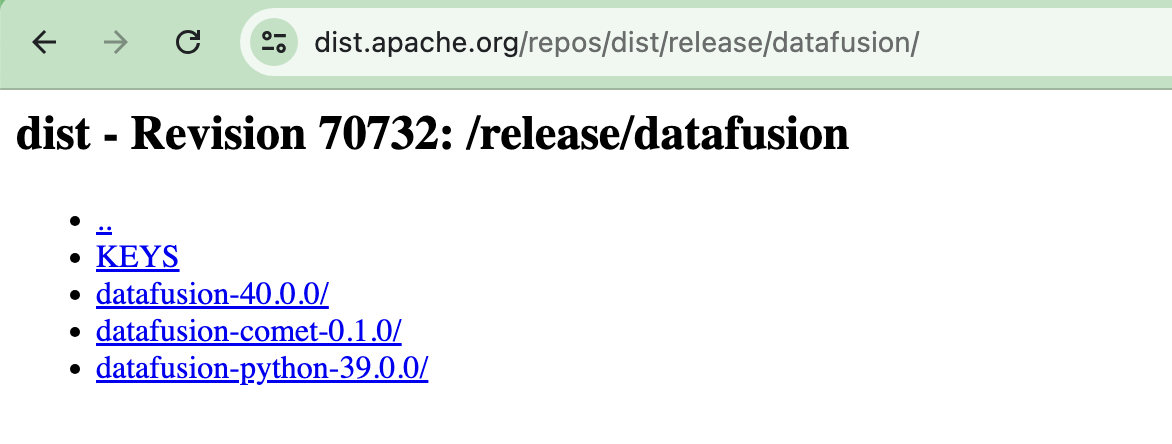
It is not clear at all, which `tar` I’m supposed to download. I decided to go with the `datafusion-40.0.0` one.
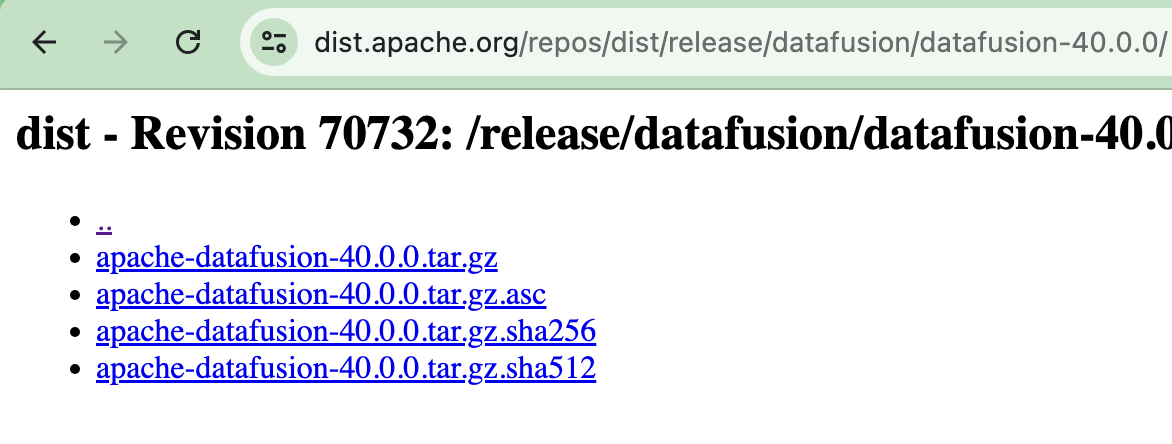
After unpacking and inspecting the `tar` file, there is a TON of files but nothing obvious to do next … the README is no help.

How do I get from here to the apparent JAR file I need to submit a Spark job and include Apache Datafusion Comet? Your guess is as good as mine.
The instructions say …
Building from a source release is mostly the same as building directly from the GitHub repository but requires the use of the command make release-nogit ...But that results in …
danielbeach@Daniels-MacBook-Pro Downloads % cd apache-datafusion-40.0.0
danielbeach@Daniels-MacBook-Pro apache-datafusion-40.0.0 % make release-nogit
make: *** No rule to make target `release-nogit'. Stop.Ok, we can’t give up that easily, let’s just switch over to cloning and building from Git.
git clone https://github.com/apache/datafusion-comet.git
make release PROFILES="-Pspark-3.5"Might as well go to lunch, that build takes FOREVER … in classic Rust fashion.
[INFO] ------------------------------------------------------------------------
[INFO] Reactor Summary for Comet Project Parent POM 0.2.0-SNAPSHOT:
[INFO]
[INFO] Comet Project Parent POM ........................... SUCCESS [ 52.958 s]
[INFO] comet-common ....................................... SUCCESS [02:52 min]
[INFO] comet-spark ........................................ SUCCESS [03:32 min]
[INFO] comet-spark-integration ............................ SUCCESS [ 4.623 s]
[INFO] comet-fuzz ......................................... SUCCESS [ 20.085 s]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 07:42 min
[INFO] Finished at: 2024-08-06T18:23:25-05:00
[INFO] -----------------------------------------------------------------Now the instructions don’t tell you what to do next, I’m assuming, reading the following instructions we need to go find a JAR that can be used along with the Spark Submit command. But of course, they don’t tell you that, or tell you where to find it. We are on our own.
I can assume from the build messages, that this might be The One True JAR we are looking for.
[INFO] Building jar: /Users/danielbeach/Downloads/datafusion-comet/fuzz-testing/target/comet-fuzz-spark3.5_2.12-0.2.0-SNAPSHOT-jar-with-dependencies.jarWell, we have a JAR we think we need, now what?
Trying out Apache Datafusion Comet.
The first thing you will need to do is have access to Spark, in my case 3.5. You can do this in many ways, local install, Docker, Databricks … whatever you have access to.
I just used a Docker image with Spark 3.5 and included my above JAR file in the image as well. I used their (Comet’s) instructions to see if Comet would work properly or not.
I ran this …
/usr/local/spark/bin/spark-shell \
--jars $COMET_JAR \
--conf spark.driver.extraClassPath=$COMET_JAR \
--conf spark.executor.extraClassPath=$COMET_JAR \
--conf spark.sql.extensions=org.apache.comet.CometSparkSessionExtensions \
--conf spark.comet.enabled=true \
--conf spark.comet.exec.enabled=true \
--conf spark.comet.exec.all.enabled=true \
--conf spark.comet.explainFallback.enabled=true \
--driver-class-path $COMET_JARWell, I saw a Warning about a failure with Comet immediately on Spark startup. This is good and bad, good in the fact Comet appears to be alive and getting picked up (attempted) by Spark, bad that it’s a failure.
24/08/08 10:01:04 WARN SparkSession: Cannot use org.apache.comet.CometSparkSessionExtensions to configure session extensions.
java.lang.ClassNotFoundException: org.apache.comet.CometSparkSessionExtensions
at scala.reflect.internal.util.AbstractFileClassLoader.findClass(AbstractFileClassLoader.scala:72)It’s hard to know what is wrong at this point, I could have done something bad all the way in the beginning trying to build the JAR file.
Going the Docker route.
Instead of trying to figure out what went wrong, for the sake of time, I figured I would try out the Docker route, better than nothing.
Turns out that the GitHub had a Dockerfile we could try building. After a few tries of copying the Dockerfile and cloning the GitHub repo and running the build, command I finally got it done.

If you want to get the Dockerfile to build, here are some notes that they won’t tell you.
You can’t just copy the Dockerfile and try to build it, you have to clone the entire repo.
You MUST run the Docker build command from the main repo directory, you can’t change directories into the directory where the Dockerfile lives, it will fail.
Finally, at this point I’m just happy to apparently have a working version of Spark and Comet running.
docker run -it comet /bin/bashWhen I look inside the JAR directory for `/opt/spark/jars` I can see …
comet-spark-spark3.4_2.12-0.2.0-SNAPSHOT.jarSo this is a good sign. At this point let’s just try to running something and see what happens.

Above is what I ran to see if things would just work. (I had to play with the instructions given in the Datafusion Documentation, there were some —-conf they had that seemed to blow up Spark. The above worked for me.
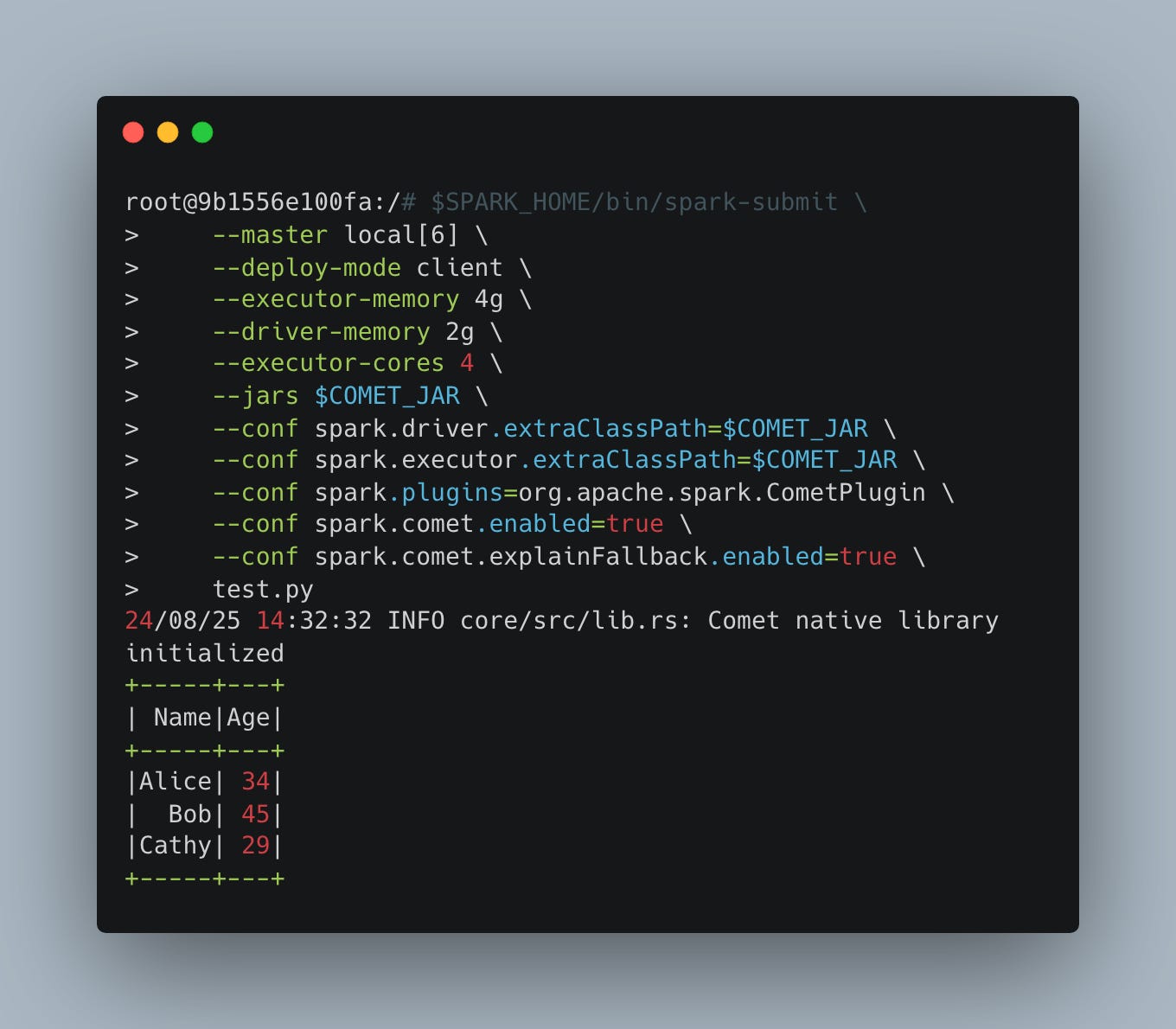
As far as I can tell my sample script worked fine. It appears the Comet JAR loaded with Spark without any errors. Below is the simple script I am running.

Upgrade a free subscription to paid and get 50% off.
Seeing if Apache Comet Datafusion is as FAST as they say.
Ok, so now that I’ve burned a few weekends working on this for all you unappreciative milk toast programmers, the time has finally come to see if this tool can speed up some smaller data processing scripts by a significant amount.
This is going to be about as unscientific as it gets, but that’s alright, we are just learning a new tool. It’s the journey that matters most usually.
I went ahead and downloaded some of the Divvy Bike Trip opensource dataset CSV files inside this Docker image.
root@9b1556e100fa:/# ls /data
202401-divvy-tripdata.csv 202402-divvy-tripdata.csv 202403-divvy-tripdata.csv 202404-divvy-tripdata.csv 202405-divvy-tripdata.csvI then converted those CSV files to Parquets … apparently, Comet doesn’t support CSV files right now.
We are going to run this very simple script … twice …

Things to note … I’m reading and writing Paruqets since that’s what Comet supports, I’m also printing the EXPLAIN on the final dataframe to see if COMET shows up … to ensure it’s working.
once without Comet → Time to run pipeline: 0:00:09.511450
once with Comet → Time to run pipeline: 0:00:09.243452
== Physical Plan ==
AdaptiveSparkPlan isFinalPlan=false
+- HashAggregate(keys=[date#26, _groupingexpression#80, _groupingexpression#81, _groupingexpression#82, rideable_type#1], functions=[sum(cast(ride_id#0 as double))])
+- Exchange hashpartitioning(date#26, _groupingexpression#80, _groupingexpression#81, _groupingexpression#82, rideable_type#1, 200), ENSURE_REQUIREMENTS, [plan_id=171]
+- HashAggregate(keys=[date#26, _groupingexpression#80, _groupingexpression#81, _groupingexpression#82, rideable_type#1], functions=[partial_sum(cast(ride_id#0 as double))])
+- Project [ride_id#0, rideable_type#1, date#26, year(date#26) AS _groupingexpression#80, month(date#26) AS _groupingexpression#81, dayofmonth(date#26) AS _groupingexpression#82]
+- Project [ride_id#0, rideable_type#1, cast(started_at#2 as date) AS date#26]
+- CometScan parquet [ride_id#0,rideable_type#1,started_at#2] Batched: true, DataFilters: [], Format: CometParquet, Location: InMemoryFileIndex(1 paths)[file:/data/parquets], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<ride_id:string,rideable_type:string,started_at:string>
We can see if the EXPLAIN that CometScan and CometParquet shows up, so I’m going to take this as it’s doing its thing.
Interestingly, Apache Datafusion Comet doesn’t seem to make much of a difference at this level. It probably has something to do with the data size maybe?
I mean we are only doing a GROUP BY and AGG on about 1,694,242 rows. Even Pandas can do that.
I’m curious if increasing the data size wides the runtime gap between Comet and No Comet. I added another 100 files, see what happens. This now is about 16,182,111 records.
once without Comet → Time to run pipeline: 0:00:24.621078
once with Comet → Time to run pipeline: 0:00:25.065360
Interesting! Comet (confirmed EXPLAIN still showed Comet) appears to be a little slower this time around with more data!
(this probably has to do with Comet only being used for CometScan and CometParquet … not for the aggregations)
That’s enough for me today. I think Comet is going to be an upcoming and powerful tool as it continues to get developed and adds features!
Very promising project, hopefully they continue to work on it and market it well so Data Engineers know about this … super interested to find out if others are using this in production yet.
Where is the good part LMAO my first ever experience with Iceberg in 2021 was something like this also