

Architectural Foundations & Infrastructure - Part 2
Lambda vs Kappa Architecture

Part 1 - The Importance of Architecture in a Data Platform
Part 3 - Architectural Foundations & Infrastructure
Building data platforms that actually work and provide value has to be grounded in the day-to-day realities of the messy data systems you will encounter in the real world.
Neither life nor the systems we will encounter exists in a vacuum. Every single data platform from the Fortune 500 company to the twelve-person startup is going to have a certain amount of …
Tech debt
Nuances
Custom build-outs
Pitfalls and challenges
But because I don’t want to be accused of skipping the fundamentals, I’ll have to break my promise to mostly be snarky and very un-educational, and give you some brief academic lessons on a well-known, industry-accepted high-level architecture, if for no other reason than introducing words you might hear or read about.
To do such a thing, excuse me, it’s hard to get the words out, we must talk …
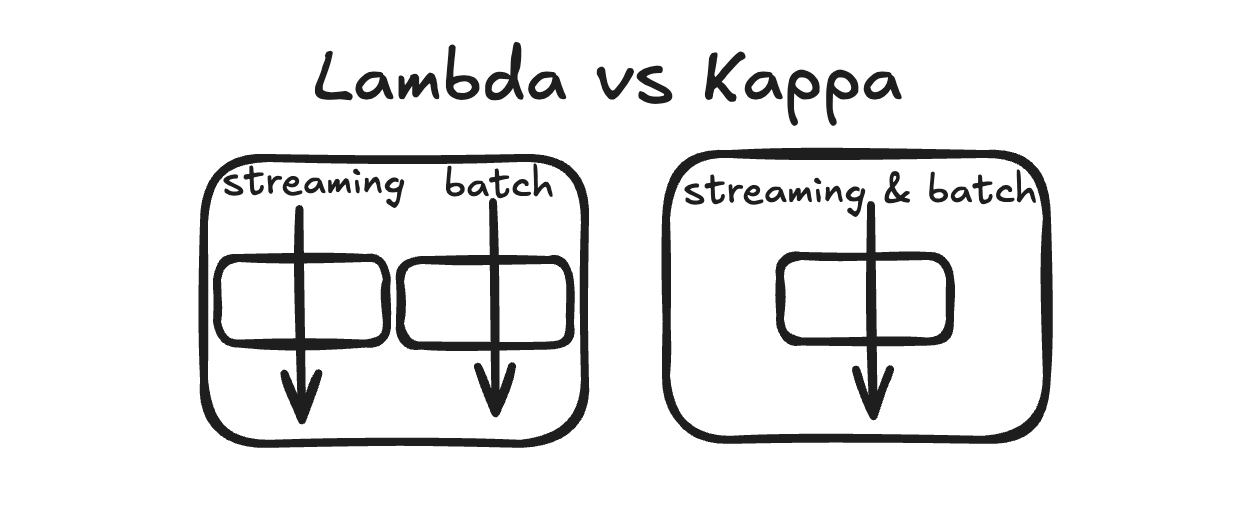
Lambda vs Kappa
Lambda
We have separate batch and streaming approaches and pipelines.
Kappa
Single, unified data processing approach built around streaming. Everything is a stream.
If you think about it, this is what we can find in nature and is highly dependent on the business and data use cases. It is usually obvious what kind of architecture, Lambda or Kappa, you are dealing with, or should be building with, even with a superficial knowledge of the business and datasets.
Of course, as with many topics and tools, these ideas can be abused, and with time and effort, you can force any data into any architecture you like, even if you shouldn’t. Sometimes streaming tools and architectures are sold as a remedy for “slow” data pipeline problems, even when the data only needs to be updated once a day.
Thanks to Delta for sponsoring this newsletter! I use Delta Lake daily, and I believe it represents the future of Data Engineering. Content like this would not be possible without their support. Check out their website below.

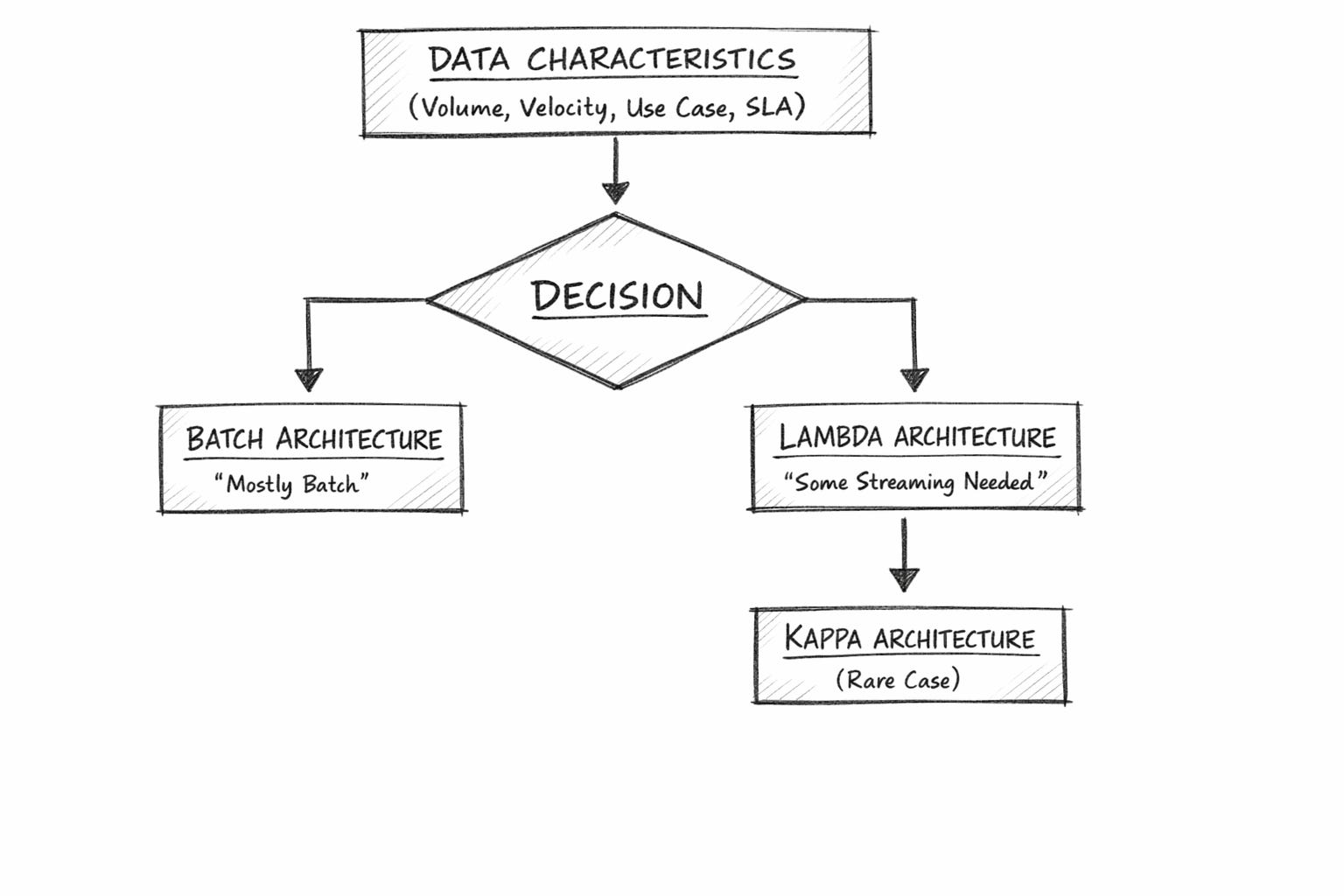
We need to recognize up front when working on data platform architecture, whether we are dealing with streaming data and business needs, simple batch processing, or both. It’s very easy to align these needs with our definitions of Kappa and Lambda. You will probably find that the following is true.
Most data needs are batch in nature
Some data sources are obviously streaming in nature
Many data platforms will be Lambda, with batch and streaming in different pipelines.
You might notice that I’m throwing a bit of shade towards the Kappa architecture, where everything is treated as a streaming pipeline (including batch).
Why? In most cases, even with a heavy streaming disposition in the data and platform approach, it’s rare that there isn’t also batch analytics and aggregation happening elsewhere in the same system, say to feed dashboards.
Indeed, we can say that the Kappa architecture is a gold star, sounds terrific, and is a great place to head towards, but in practice, it is difficult to implement.
Is it possible to use Spark Structured Streaming or Kafka to ingest all data into the Lake House? Yes. It is possible to have Spark Streaming and Kafka build Data Marts that feed the dashboards. Not really, that’s like fitting a square peg into a round hole. If you push hard enough, it might go in, but it just wasn’t made to do that sort of thing.
Let’s apply Lambda and Kappa architecture to our three made-up companies from Part 1.
Acme Mfg Corp.
Lambda architecture: there will be only batch systems; no need for any streaming technology.
Acme FinTech
Probably as close to Kappa architecture as any company will get.
Acme AgTech
Will use Lambda architecture, large-scale batch processing of big data, along with smaller but needed streaming use cases.
That is where you have to be careful when building data platforms, especially when considering the streaming vs batch arguments that will inevitably follow.
In most cases, businesses will likely need just a batch, or a batch combined with streaming, many times in different pipelines. The most important thing is to let the requirements, both business and technical, drive the decisions.
Taking the path of least resistance and letting data velocity, size, and growth guide you toward the Lambda and Kappa architectures that best fit your particular data platform is the best approach to these high-level decisions.
What you want to avoid is pre-picking a batch or streaming architecture simply because someone likes it or wants it, and then forcing that architecture onto the data, rather than the other way around.
The Brave New World
Recent developments in the data framework landscape have greatly helped data teams in this area. Traditionally, streaming frameworks have been notoriously difficult to build, maintain, and run at scale, requiring dedicated teams just to manage and tune these complex architectures.
Of course, this led to large cloud providers like AWS and GCP, as well as various SaaS companies, releasing managed versions of streaming frameworks that reduce the maintenance burden.
Additionally, there has been significant progress in new streaming platforms and frameworks that blur the line between batch and streaming at their core, offering a better, simpler development experience. But that still begs the question: how do you know whether you are dealing with streaming or batch processing? Two things …
The data size and velocity
The business requirements
Both of these things combined will guide you down the right path. The main decision point in choosing between Kappa and Lambda designs is the data itself. When it comes to the data sources, what is the size of a “data unit” and what is the “velocity”? Technically, what do we mean?
When ingesting a data point, what is its size?
A large CSV file, or a single JSON struct?
What is the velocity of the data?
How much data is coming, and how often?
Are we receiving JSON or Avro data every second, minute, or hour? CSV files hourly?
The answers to these sorts of questions will either make batch or streaming an obvious choice. If you are dealing with a large volume of small data units, say, a few thousand JSON files/messages every few minutes, a streaming pattern would work well. On the other hand, if you are ingesting a few decent-sized CSV files twice daily, a batch approach is the best option.
Of course, your kind SaaS vendors and their marketing departments will have their own opinions, but you should not let unnecessary complexity drive your decision. Letting the data itself tell you how it wants to be handled is the best approach.
Let the business needs drive the architecture.
The other decision point we mentioned earlier was the business requirements. This is, or should be, aligned with the answers that data itself gives you. Does the business require real-time or near-real-time analytics and monitoring? Then, batch pipelines could struggle to meet these requirements as they scale over time.
Again, we can often approach the same problem with different tools and get close enough. But we are looking for the obvious answer that requires the least complexity.
Why should a data team take on the complexity of managing Kafka streams for Dashboards that only need to be updated daily? Of course, we are glossing over many technical details, but I argue that, at a high level, architecture is a big-picture design, as we discussed before.
Building and selecting the architecture of a data platform is about the logical approach to solving a problem. It’s more of a thought exercise to find out what kind of technology is best suited to the data and business requirements that are presenting themselves to us.
I hope you are still with me after that little side quest to understand Lambda and Kappa architectures at a high level. We needed to set expectations for this topic before we dive into other sections and build the blocks of a data platform.
Remember, many of the issues that we will cover related to building data platforms are supposed to rise above any particular tool or framework we choose.
Does it matter whether we use a streaming platform or batch ingestion for monitoring and observability? No.
We need visibility into the health and status of data pipelines, whether they are streaming or batch, so teams using both don’t have to leave this decision about monitoring out of the design and end up scrambling at the end of the day. Different approaches to data platforms, such as Lambda and Kappa, will still share many building blocks.