

AWS Lambda + DuckDB (and Delta Lake)
simplicity in Data Engineering

I’m well aware volumes of words have been written about simplicity in the context of Software Engineering, ye ole’ KISS concept that your grandmother taught you is as old as time. Yet the siren call of the modern data stack has lured many a poor soul down the proverbial Davey Jones locker of the data sea.
Let that not be us.
The idea of simplicity in the design of Data Platforms, Pipelines, ETLs, and data in general is incredibly under-appreciated. It is simply given lip service but not taught or followed in any real manner.
In fact, in the name of building resumes and being seen as smart, overly complicated designs are the common fare of the day, served up on Linkedin, Reddit, and YouTube to fill the bellies and itch the ears of the restless data practitioners.
Thanks to Delta for sponsoring this newsletter! I personally use Delta Lake on a daily basis, and I believe this technology represents the future of Data Engineering. Check out their website below.

AWS Lambda + DuckDB. The Ultimate Data Pipeline?
I’ve spent 15 years tinkering with data, and I would like to think I’ve learned a thing or two in that time, although there are always a fair number of internet trolls who tell me otherwise.
When building and maintaining Data Platforms at scale and in production, one of the most overlooked pieces of the puzzle is the compute software and infrastructure.
We tend to get caught up in the shiny and popular and are decidedly UNcreative in our thinking about how to solve problems. We reach for what we’ve always done and what has been done.
Overall, the Software and Data community seems to be starting to appreciate the possibilities of a more straightforward approach to data processing.

The simplicity of DuckDB.
If I were in the business of making predictions, which strangely, I do find myself in that position often, I would say one of the hottest rising stars for the next 5 years in Data Engineering will be DuckDB.

When it comes to simplifying a complex data world, DuckDB is the clear winner. This is probably one of the most under-appreciated aspects of DuckDB and needs to be discussed more.
For those of us who have fought complex and challenging to deal with architectures for years, trying to solve installs and integrations, DuckDB is uniquely powerful AND, at the same time, one of the most simple tools to manage and use.
pip install anywhere, anytime
no centralized configurations or metadata
powerful integrations inside DuckDB
cloud storage, databases, etc (read-writes)
The flexibility and extensibility of DuckDB is rare in the data world, and it’s capable of combining multiple tasks into a single tool.
Analytics
General ETL and Data Pipelining
SQL
Data Connector via Integrations
(ex, Postgres, Delta Lake, S3, etc, etc)
Instead of using various tools and Python packages to bring together disparate data sources and gain insights or further processing, you could simply use DuckDB for ALL that stuff.
Combining DuckDB with Lambda for the perfect data processing tool.
When on the topic of simplicity and DuckDB I think a natural companion to create the ultimate lightweight Data Stack is AWS Lambdas. I mean, can you imagine?
No heavy infrastructure to manage, no clusters to setup, no complex tooling to install and configure, talk about being able to concentrate on what really matters … providing business value.
As someone who manages and has built many Data Platforms the appeal of this sort of lightweight setup is …
reduced infrastructure costs
reduced infrastructure management
reduced complexity at all levels

Yes, there is always a tradeoff, like everything in life, there is no free lunch. But, the AWS Lambda and DuckDB combination is about as low cost of a lunch as you are going eat in this Data Engineering life.
On top of it all, the number of provided DuckDB integrations does not make it feel like a simple solution.
The number of DuckDB extensions is out of this world. Arrow, AWS, Delta, Excel, Iceberg, MySQL, Postgres, SQLite, etc, etc.
Enough chitter chatter, time to get to it.
So, without further ado, let’s show to the world the simplicity of AWS Lambda + DuckDB with a simple data pipeline. Let’s start with a “raw” CSV hitting an S3 bucket, then using Lambda+ DuckDB to process the data into two different Delta Tables, one for general storage, another for summary analytics.
This type of data pipeline flow would typically be done with Airflow + Snowflake/Databricks/BigQuery etc + a lot of code.
Below is a conceptual data flow that we will be building.

We have a few tasks ahead of us …
create AWS Lambda
create Lambda trigger for CSV file hitting S3
create two Delta Lake’s in S3
write the DuckDB code

I’m thinking we start working on these things in reverse, let’s start with writing the DuckDB code for the Lambda. Essentially when a file hits our S3 bucket, it will trigger the lambda, one of the arguments of automatically sent to our triggered lambda will be the s3 URI of the file that triggered. We will want to do two things …
transform the data as needed with DuckDB and insert into a basic accumulating Delta Table.
Do some analytics to update a cumulative Delta Table
be reading the current state of the accumulating Delta Table and adding to those records the current records coming in, calculate some metrics for that day, and write the results back the cumulative Delta Table.
Let’s just get too it, you will see it in action if I lost you there.
Building Dockerfile for AWS ECR to use with the Lambda.
First, we need to build a simple Docker image we can upload to ECR (Elastic Container Registry on AWS). I find this an easy and great option with it comes to deploying Lambdas on AWS when you want a simple architecture.
The reason for this is that building and deploying Docker images, even when you submit new code to a repository and can easily be automated with something like GitHub actions etc.

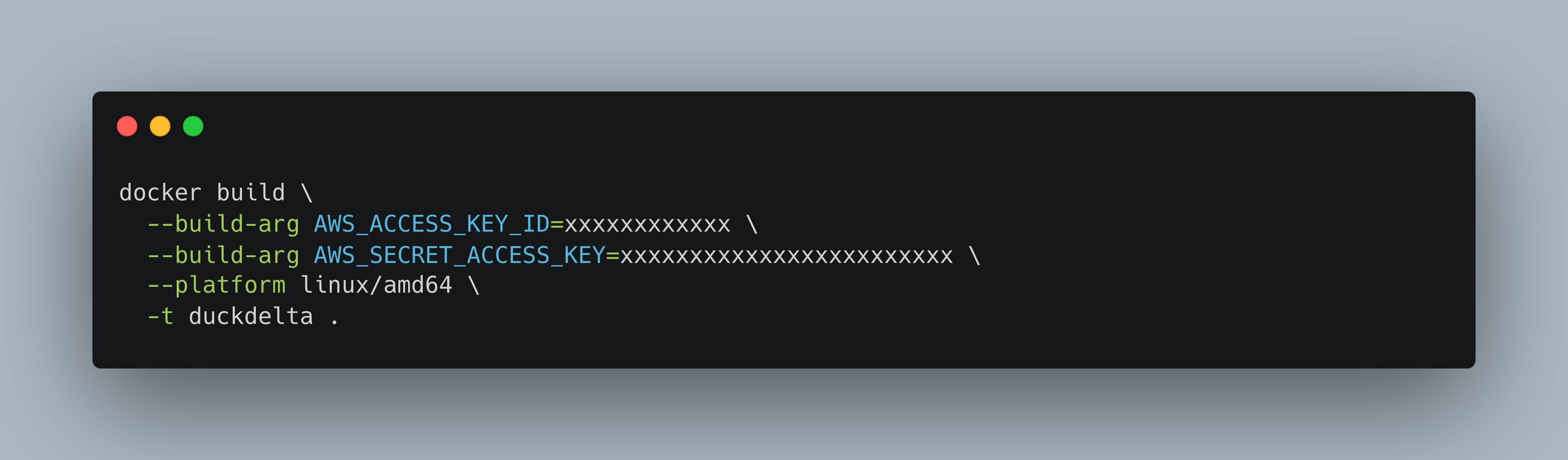
We can then build the image as follows …
In case you were wondering what was in the requirements.txt file, it’s nothing special.
duckdb
deltalake
getdaft[deltalake]
numpy
pandas
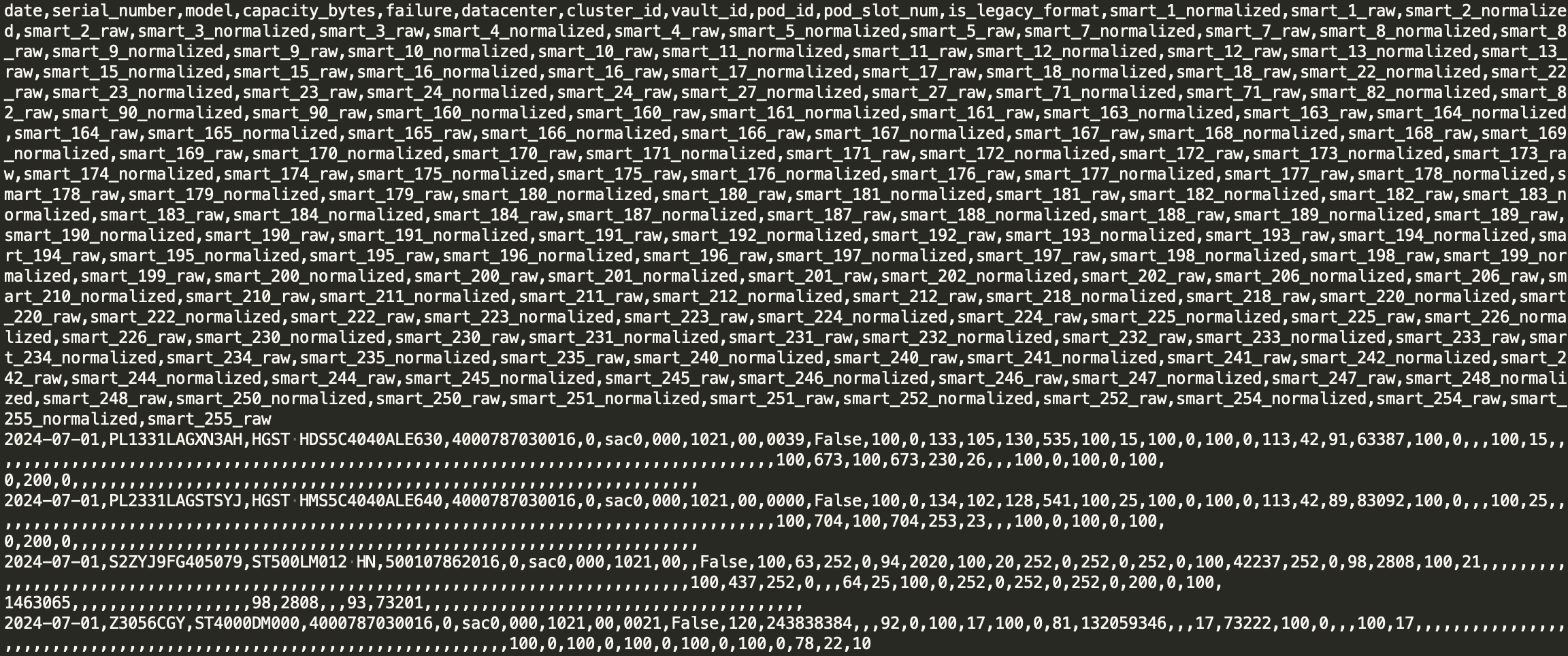
We need some toy data that we can play around with for our little experiment. I often turn to the Backblaze Hard Drive Dataset that is free, it will work perfect for this.
The data is large and dirty, making it more real life than some classic “taxi cab” dataset.
Creating Delta Lake tables on S3.
The next part of our project involves having two Delta Lake tables available in S3 that our AWS Lambda will interact with. Let’s go ahead and write some simple code to create those two tables.
I’m going to use Daft to create the Delta Lake tables, because it’s simple and easy. Here is the code to do that, remember we are building two tables …
general “accumulating” table in a “Fact” style.
analytics type daily “cumulative” table in a “Data Mart” style.
Luckily, Daft does a good job at picking up and sensing the data types on this massively wide dataset, keeping me from doing too much work. (I’m going to select a subset of these columns just to speed this all up).

Let’s just save this out as our accumulating style Delta Table in s3. Next, let’s make an analytics “cumulative” style table, it will basically hold a daily rollup.

Let’s a decent amount of work before we even get to our Lambda and DuckDB isn’t it? Oh well, we have our Delta Tables and data now, so we can finally get to it.
Creating an AWS Lambda with DuckDB.
Ok, so now let’s write the core our Lambda code that will use DuckDB to process incoming CSV files that land in S3, so we can process them downstream into …
accumulating table
cumulative table
Now I’m going to just throw all the code at you, and after you look it over we can talk about it.

Ok, so let’s just talk about of a few things, first, I think for the work we are doing, what we have here is a fairly simple and straight forward solution.
I mean sure, there is a little complexity with …
messing with partitions
back and forth with arrow()
getting configs correct to write Delta Lake tables
getting data types correct to Delta and Dataframes play nice
But, considering the complexity of what we are doing … ingesting raw CSV files from S3 into a accumulating table, and calculating daily cumulative Delta Table … the solution is simple.
Most people doing ingestion of flat-files, CSV is this case, in a remote storage bucket, pushing that data into multiple Delta Lake tables would probably see that as a “complex” problem requiring a “heavy solution,” and come up with some serious architecture to support it … aka Apache Spark, Databricks, etc.
Clearly, if one thinks outside the box, there are much more light weight options … namely DuckDB and AWS Lambda.
Things to note about DuckDB code with Lambda for Delta Lake tables (all in S3).
There is a lot to talk about here, almost too much, so I will just put together a list of benefits that I see here.
Lambda’s are a “light” solution in context of architecture.
also simple to maintain and automate
DuckDB makes it simplistic to read remote files in S3.
DuckDB’s use of default credential chain is nice
it could pickup creds from .aws or the ENV etc
The ability to materialize queries as Arrow datasets is awesome
Arrow datasets are universally integrated into many tools
DuckDB’s ability to read remote Delta Lake tables is seemless.
DuckDB’s ability to support complex SQL statements to manipulate data is first-class.
A little creativity is all that is needed to create easy, cheap, and lightweight solutions.
Finishing the project.
Ok, before we get carried away and pretend like we are done, let’s finish the work surrounding creating the AWS Lambda since we have our code finished up.
First, we need to create an ECR Registry that will hold our Docker image.

Next, we simply need to build our previous Docker image, and the push it our new ECR Repository.
Below is our simple Docker build statement.

Next we can login to our ECR.

And now we can tag and push our newly built image.

Next we need to create our AWS Lambda that will use this image, attach a trigger on s3 for when we get a new file in a certain bucket and prefix so our Lambda can process that data into our Delta Tables.
We could use the CLI to create the lambda, or Terraform, or Cloud Formation, or whatever, but let’s just use the UI so we can get his article finished before we all fall asleep.

Make sure the role you give the AWS Lambda either has, or afterwards gets, access to read/write from S3. Also, make sure the “timeout” setting on your Lambda is something reasonable (default is 3 seconds, which isn’t much). Don’t forget about memory size limits as well.
Easy enough. Next, let’s add a Trigger.

Always good to double check the Prefix and Suffix for when to trigger the Lambda.
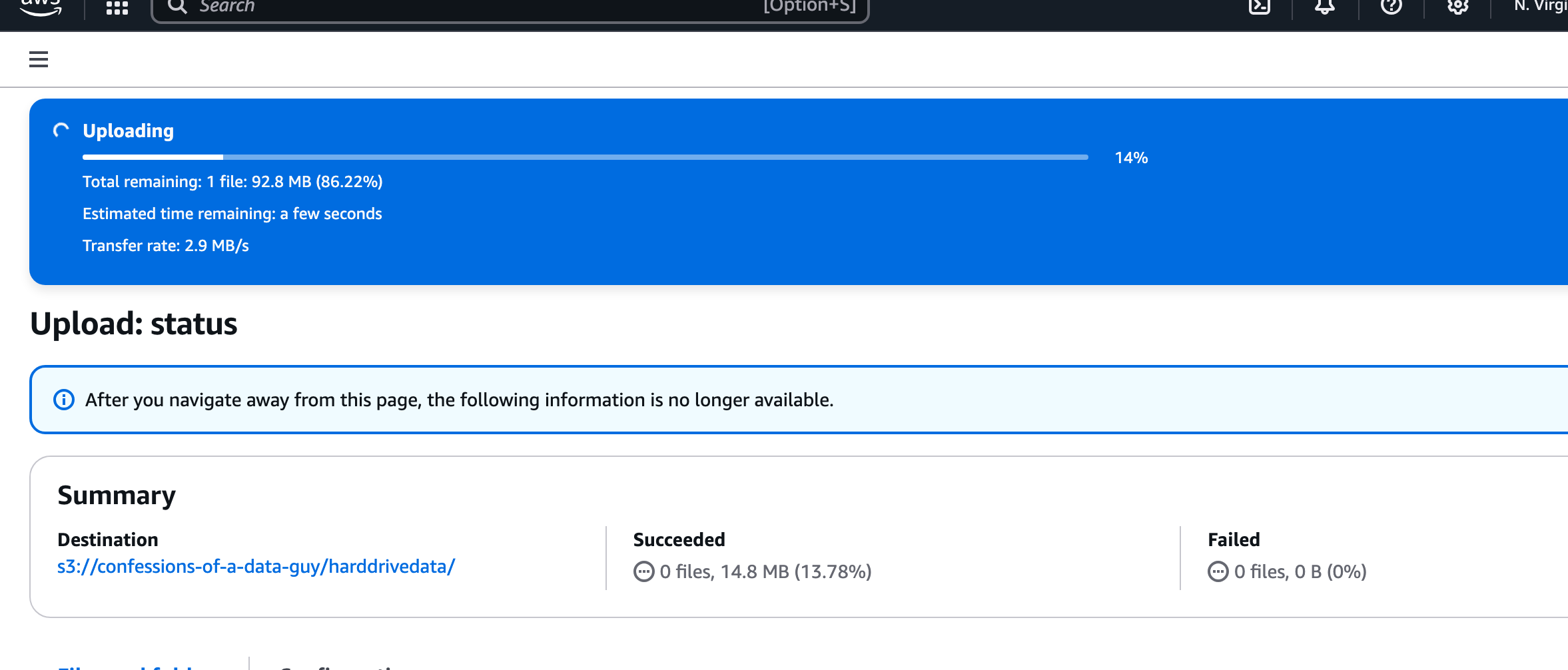
Next, to test our Lambda and Trigger, let’s upload a file to that location in S3!
Let’s go check the Logs on our Lambda and see what happened.

Looking good! All is well according to the logs.
To confirm we can go look at that S3 Delta Lake table for our “cumulative” daily table and inspect the the files themselves and see that new partitions were actually written out, per below.

Also, let’s read and look at the table in code.
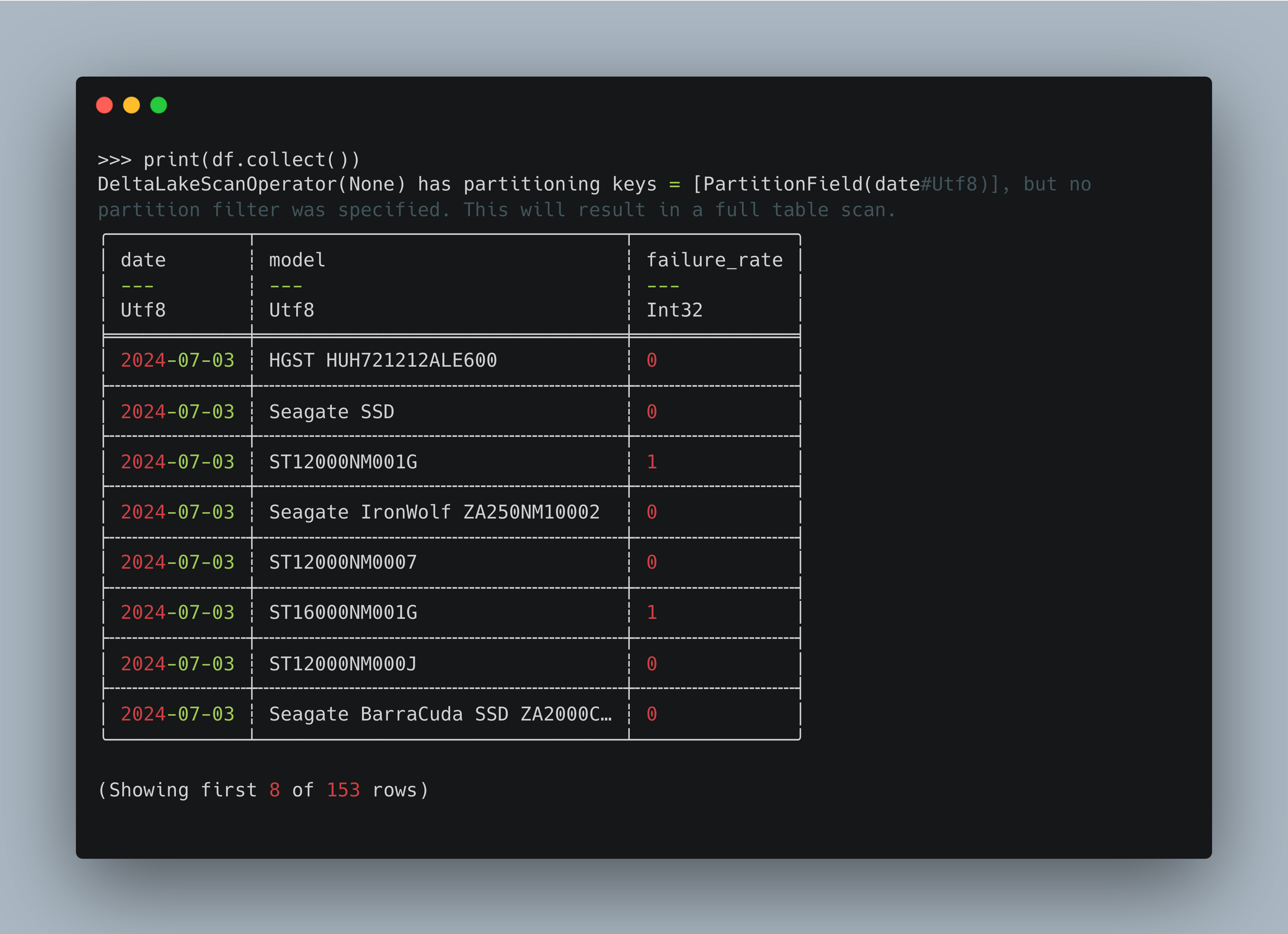
Looks just as we expected and wanted!!
Impressive and minimalist data stack if I do say so myself. Nothing is easier to work with than Lambda’s, and you don’t have to worry or think about them. They just run.
DuckDB? Well, you have to admit, it’s pretty slick for running any sort of simple or complex data transformations. Did you note how we were able to use DuckDB to read a CSV file into memory, read a Delta Lake table into memory, combine those datasets with a UNION and do calculations? All in just a few lines of code??
If Lake Houses are truly the future for us all, which they probably are, it’s clear that tools like AWS Lambda and DuckDB can play an essential role in building out any data stack.
NOTE: If you need concurrency with Delta Lake and multiple writes, check out the DynamoDB model.
Thanks for your support of this Newsletter, it takes me a lot of time, blood, sweat, and tears. If you would consider becoming a paid subscriber, that helps me out a ton and allows me to pay for things like AWS services to bring you this content.
Good stuff…nice and clean and “real time baby!”
The final screenshot that indicates reading and looking at the table in code. Is that also via Daft? What have you found the best way to manage querying and rolling back to versions of delta tables?