

Benchmarking Vortex File Format ... vs Parquet, CSV ... vs DuckDB, Polars, Datafusion.
just because we want to make em' mad

If we had a dollar for every time someone came along to become the Apache Parquet killer, we would all be living on the side of a mountain tending to our alpacas. A boy can dream, can’t he?
Because it’s a holiday Monday, and I’ve been up since dawn running amok on the river, and now I’m lying on the porch with a cool breeze, it’s time we put our hand to the plow and turn up something interesting.
Today, that will be the Vortex file format.

100x faster random access
10-20x faster scans
5x faster writes
Similar compression ratio (vs. Apache Parquet)
At this point, half of you probably know more about Vortex than I. I’ve heard the name rattle around here and there, but never touched it. So, I don’t expect much today, really just a little poke here and there, a little benchmark to bring the craizes out of the swap, ya know, the usual stuff.
Vortex file format for ninnies.
It isn’t really apparent to me, on a simple poking around in the docs, what niche is being chased down by Vortex. I mean, if you read between the lines, and not hard to find lines, seeing worlds like “… vs Parquet” or “compressed columnar data,” heck, even a “unlike Arrow …” makes me sit up and take note.
Seems like these little buggers are taking potshots at everyone worth anything today.

The GitHub page actually brings it home a little better.
“Vortex is a next-generation columnar file format and toolkit designed for high-performance data processing. It is the fastest and most extensible format for building data systems backed by object storage.”
- GitHub
It also boasts some impressive features that stand out to me beyond what has already been mentioned.
appears to be written in Rust
“Zero-copy compatibility with Apache Arrow”
Arrow, DataFusion, DuckDB, Spark, Pandas, Polars, & more
Modeled after Apache DataFusion’s extensible approach
So, we shall see, eh?
Python + Vortex and benchmarking performance.
Well, if any tool worth its salt wants to make a go of the data community, it must have first-class Python support; otherwise, all is for naught. Rustaceans might cringe, but that’s simply the way of the world.
Let us kill those two birds with one stone.
Try out the Python integrations with DuckDB, Polars, and Datafusion.
Benchmark those against each other, plus vs CSV, Parquet, maybe Lance?
We can see what it’s like to use Vortex inside Python code, and see if there is any indication its performance is a thing or not.
Remember, if you leave me nasty comments about scientific benchmarking, there is a high probability that I will make fun of you in front of 35,000 people who follow me on this platform. Just saying. Take your chances.
Next, let us grab some data to use. We will use the Backblaze open-source hard drive dataset about failure rates.

Let’s take these two zip files, each containing two quarters of data, totaling about 23.91 GB on disk.
This should be enough for our purposes.
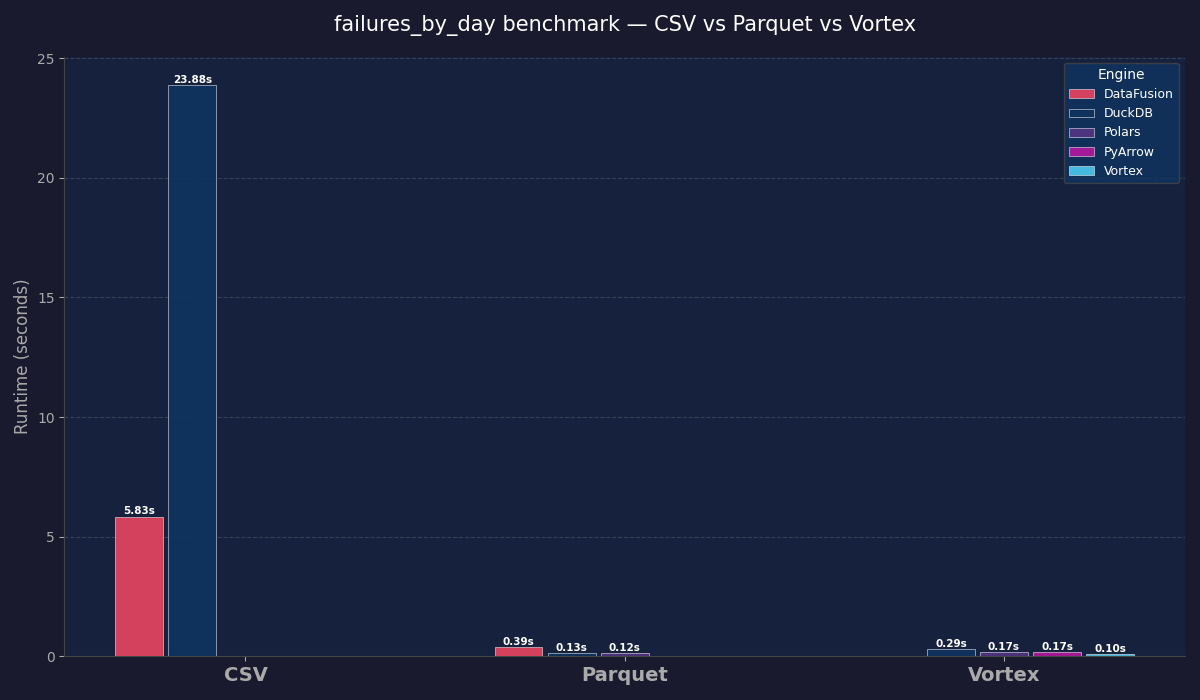
First, let’s run a simple DuckDB query on these raw CSV files to get a baseline, then we will convert to Vortex and test again.
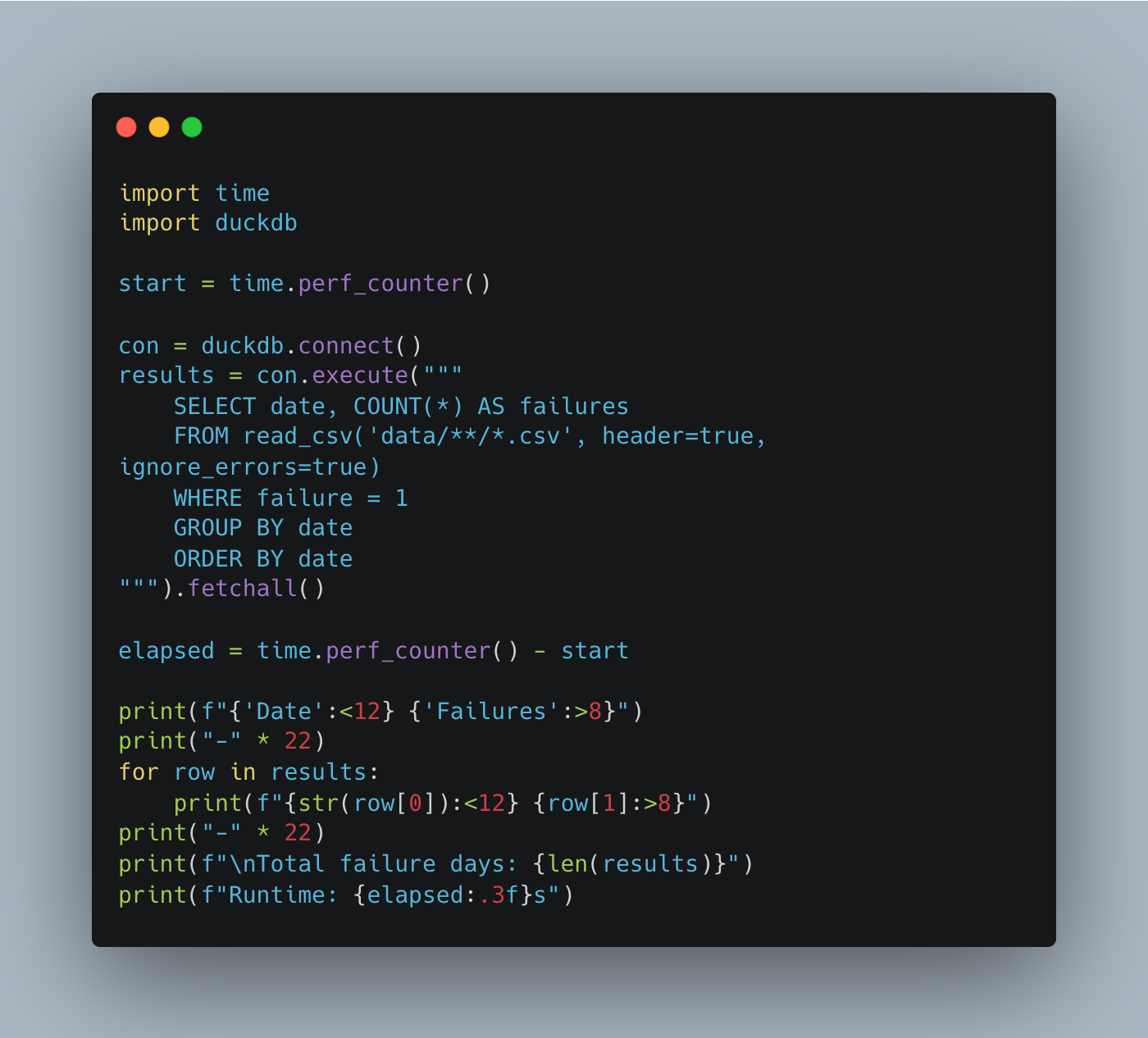
Total failure days: 181
Runtime: 25.465sOk, longer than I thought. Let’s run the exact same code on raw CSV with both Polars and DataFusion before we switch to Vortex, and then test Parquet and Lance as well.
Oh … what do you flipping know, another one of those mysterious Polars failures that doesn’t exist, and you are anathema and a heretic for even saying it.
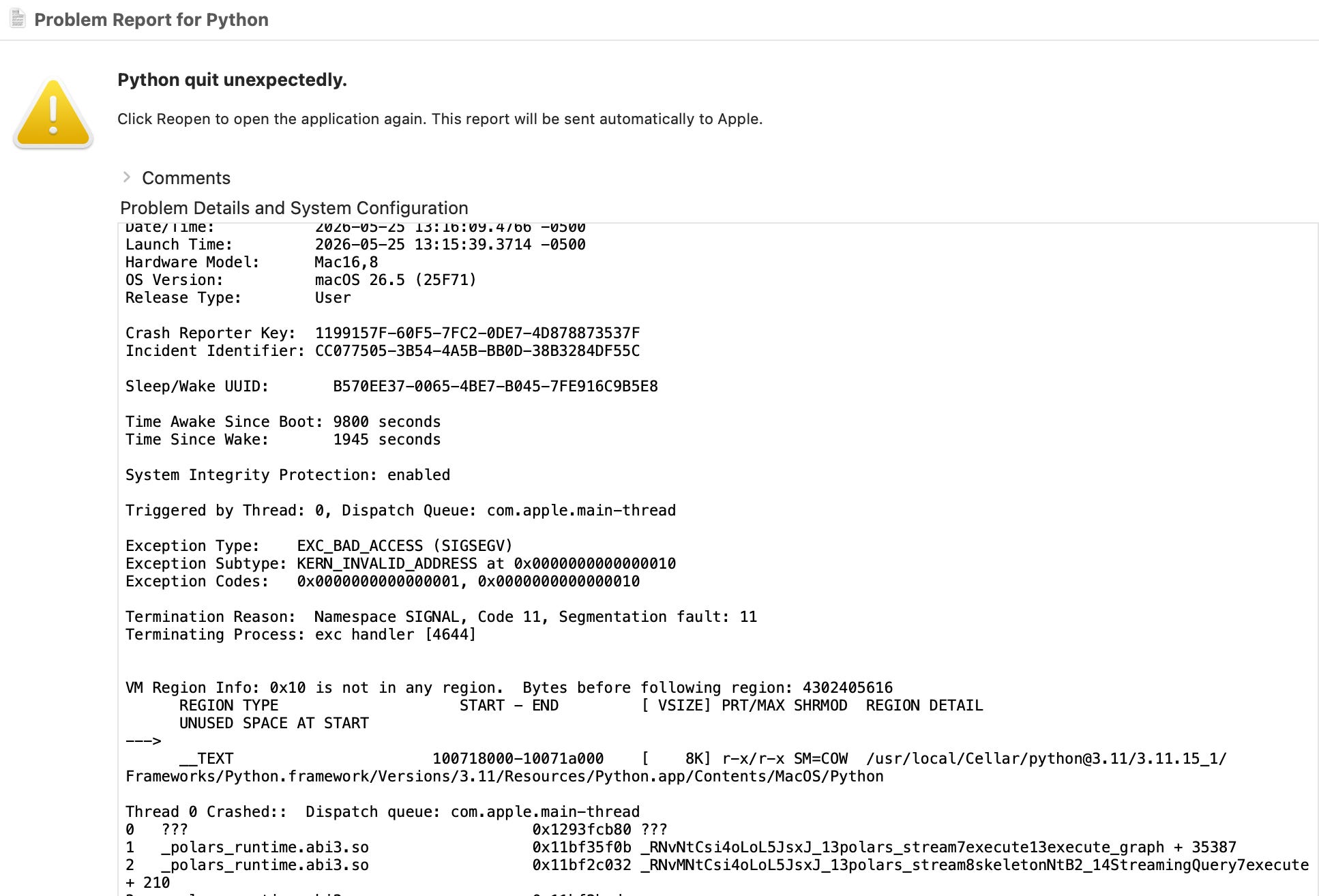
I highly suggest you go read this. And also, I encourage you to go to Google OOM Polars issues yourself, don’t let that powerful and slinking Nazgul scare you away, you will find enough evidence yourself. You can only hide the pea for so long.
This is why I had to rip Polars out of production: simply unpredictable and unreliable in an unacceptable way, for tasks that other tools handle with ease.

Anyway, stick Polars in the ditch, let’s move on to DataFusion.
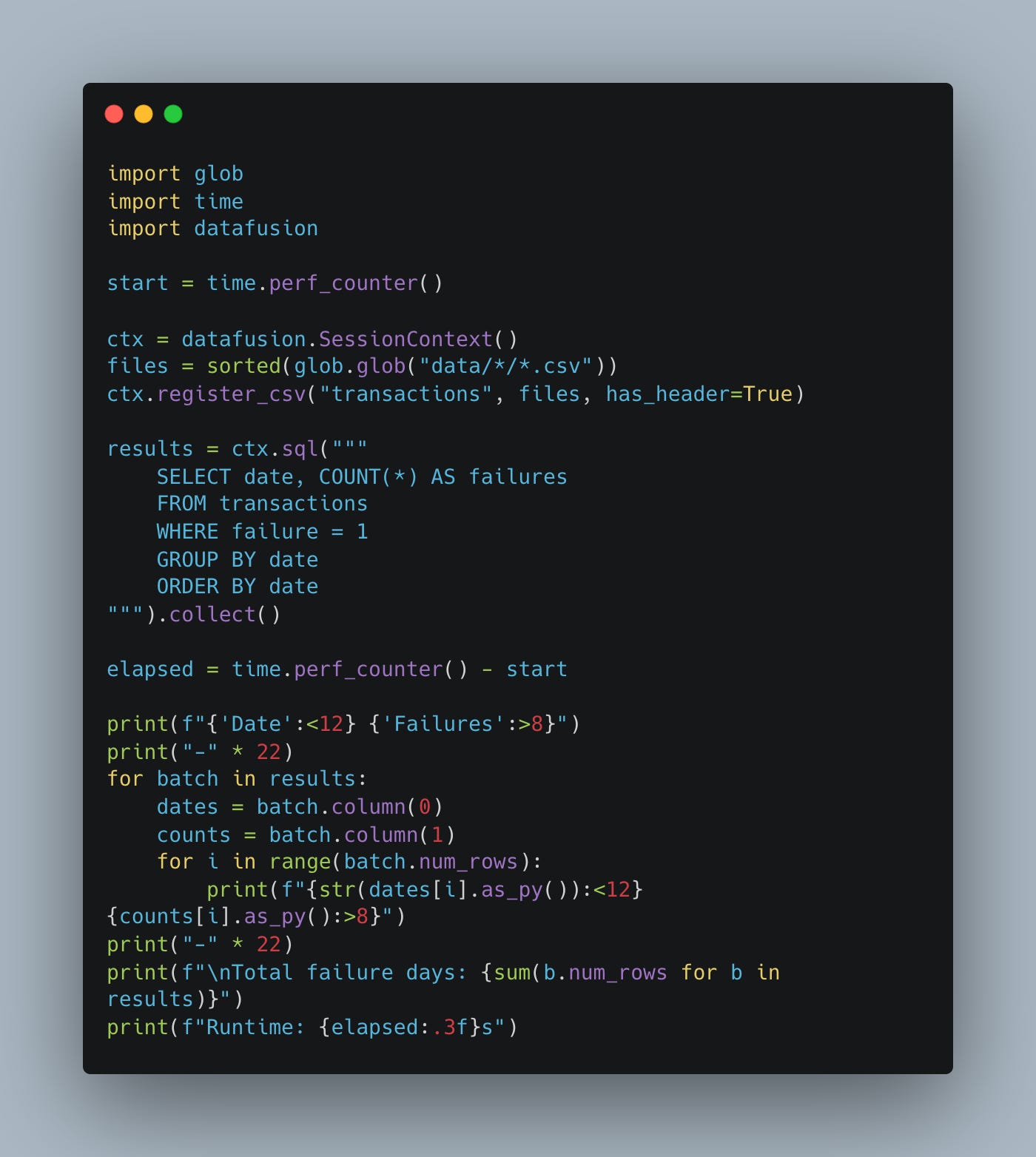
Oh dang, Datafusion is fast.
Total failure days: 181
Runtime: 5.106sOk, let’s move to Parquet files.
So, let’s convert all the CSV files to Parquet and re-run those scripts with DuckDB, Polars, and Datafusion on them. See what’s cracken.
184 CSVs → 20 Parquet files (10 per quarter, last batch 2 files each).
Again, all the code is on GitHub, and we converted all our previous scripts to just read Parquet instead of raw CSV. You can go look at the scripts if you please. I’m just going to show results here.
- failures_by_day_duckdb.py — 0.125s
- failures_by_day_datafusion.py — 0.370s
- failures_by_day_polars.py — 0.193sWell, that is quite the difference, eh.
Ok, let’s move to Vortex files.
So, let’s finally get to what we’ve been waiting for this whole time: will these packages really integrate well with Vortex, and will the performance be noticeably faster than Parquet?
First, let’s convert from Parquet to Vortex with DuckDB.
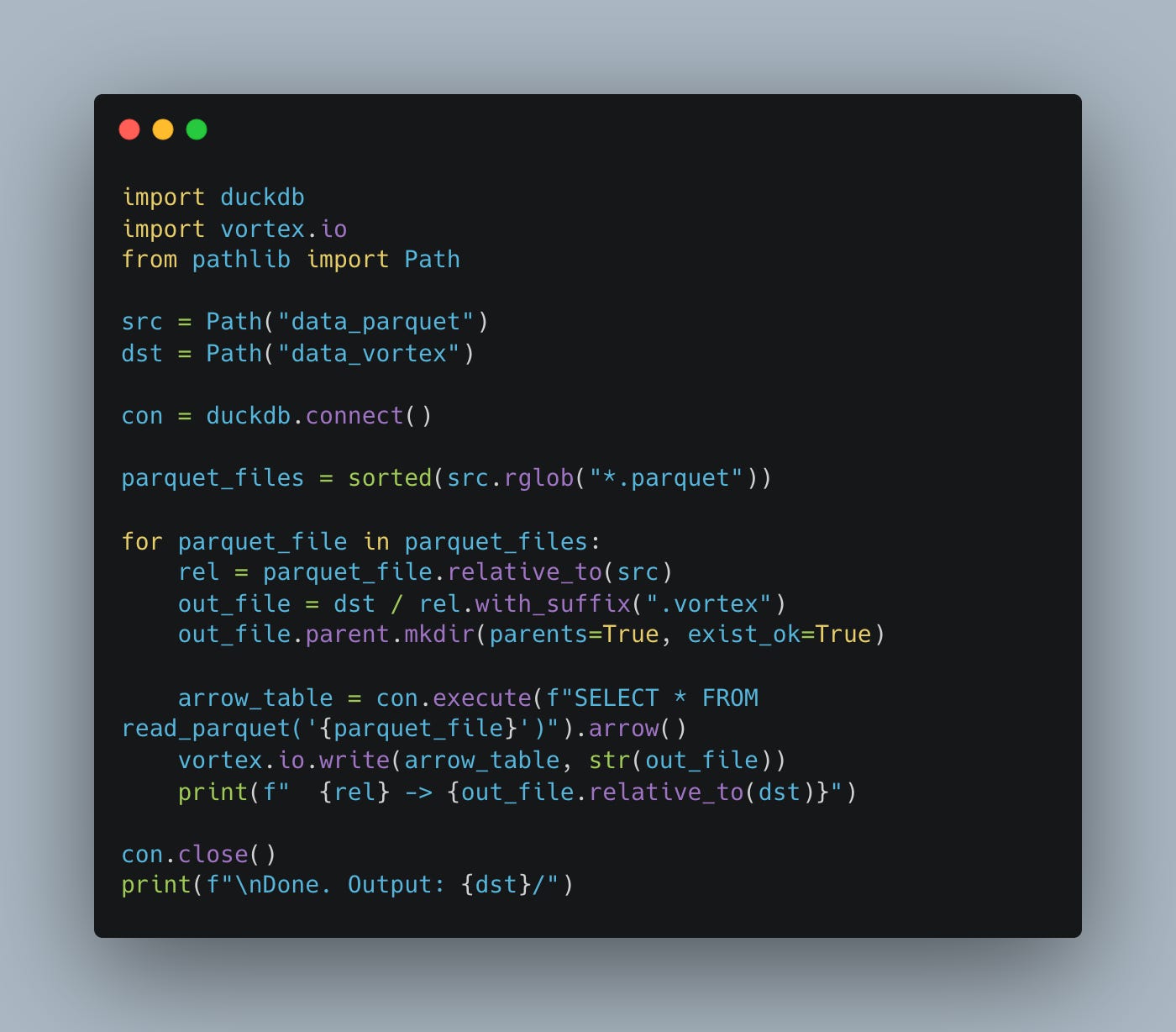
With that done, let’s run the benchmarks with the same set of tools again for DuckDB, Polars, and Datafusion on Vortex. I will put the DuckDB example in; you can check the rest in GitHub, and print the results only here.
- vortex_scripts/failures_by_day_vortex.py — pure vortex scan with filter pushdown, 0.111s
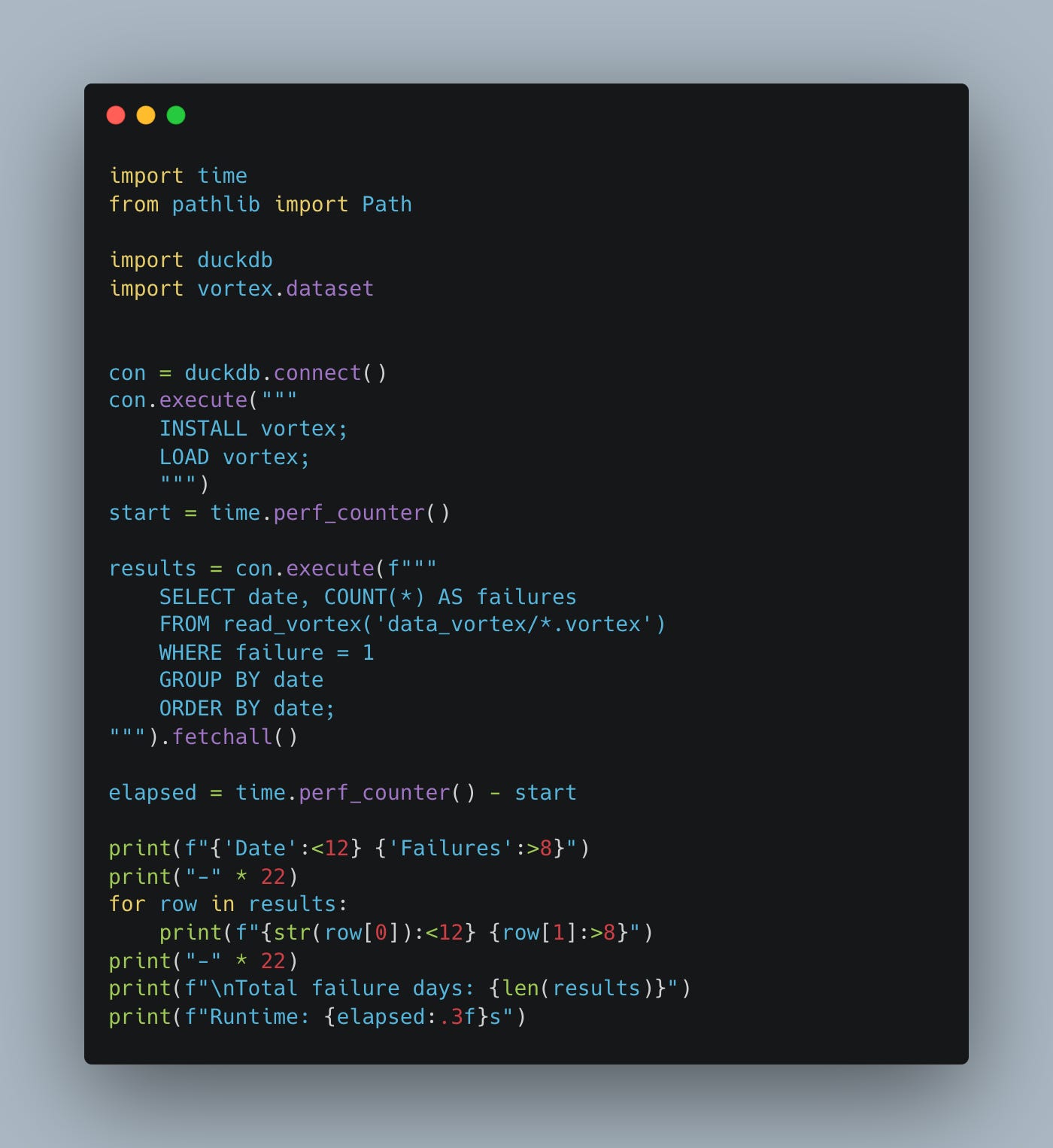
- vortex_scripts/failures_by_day_duckdb.py — DuckDB querying VortexDataset (PyArrow interface), Runtime: 0.201s
- vortex_scripts/failures_by_day_polars.py — VortexFile.to_polars() LazyFrame, Runtime: 0.114sFYI, the integrations aren't as solid as they claim. The DuckDB vortex extension blows up with memory errors. OOM like Polars on CSV files.
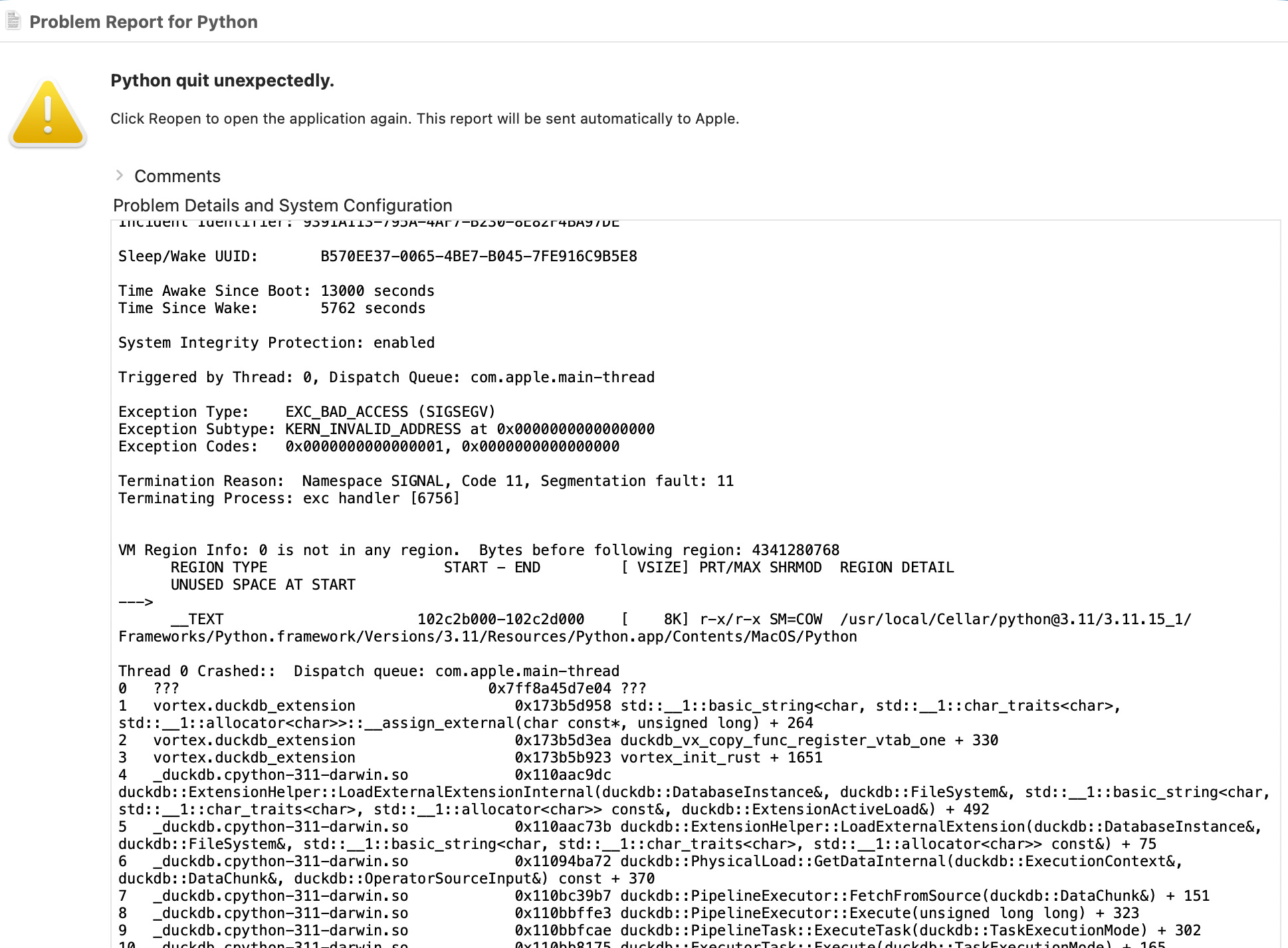
Polars only seems to support per-file-type code; I couldn't get any globbing patterns to work. On top of that, we convert to PyArrow and Polars right away in that code.
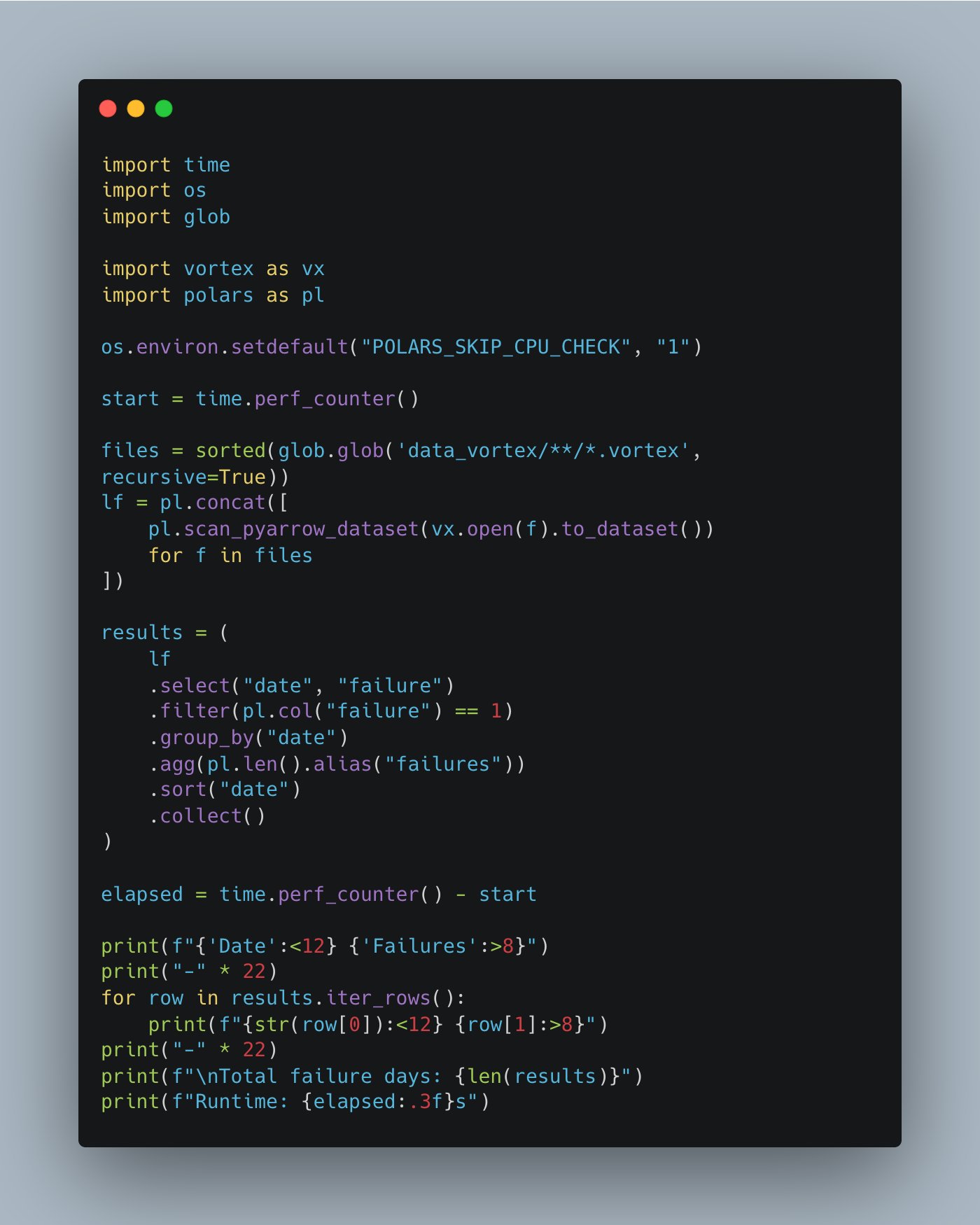
Heck, maybe I’m doing stuff wrong, but the farther I get into the weeds with Vortex, the more I realize this might be early days yet. Seems there are still some problems to solve and wrinkles to iron out in the Python ecosystem.
We could probably make DuckDB work with Vortex by doing what we did with Polars, convert to Arrow right away?
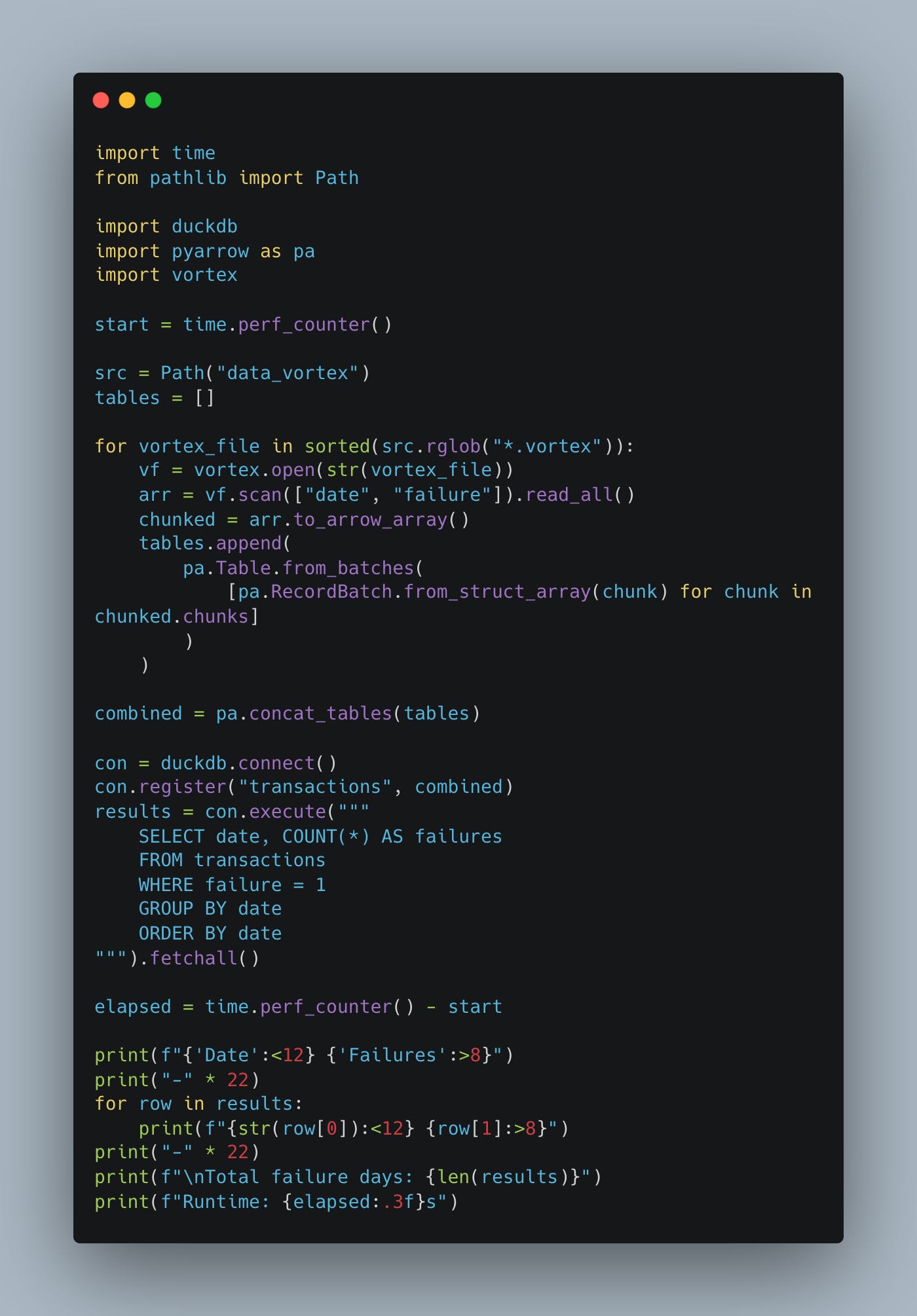
Blah, performance is fine, but that is some nasty-looking code. No fault of these third-party tools, just a little early in the lifecycle methinks.
Anywho, here ya go.
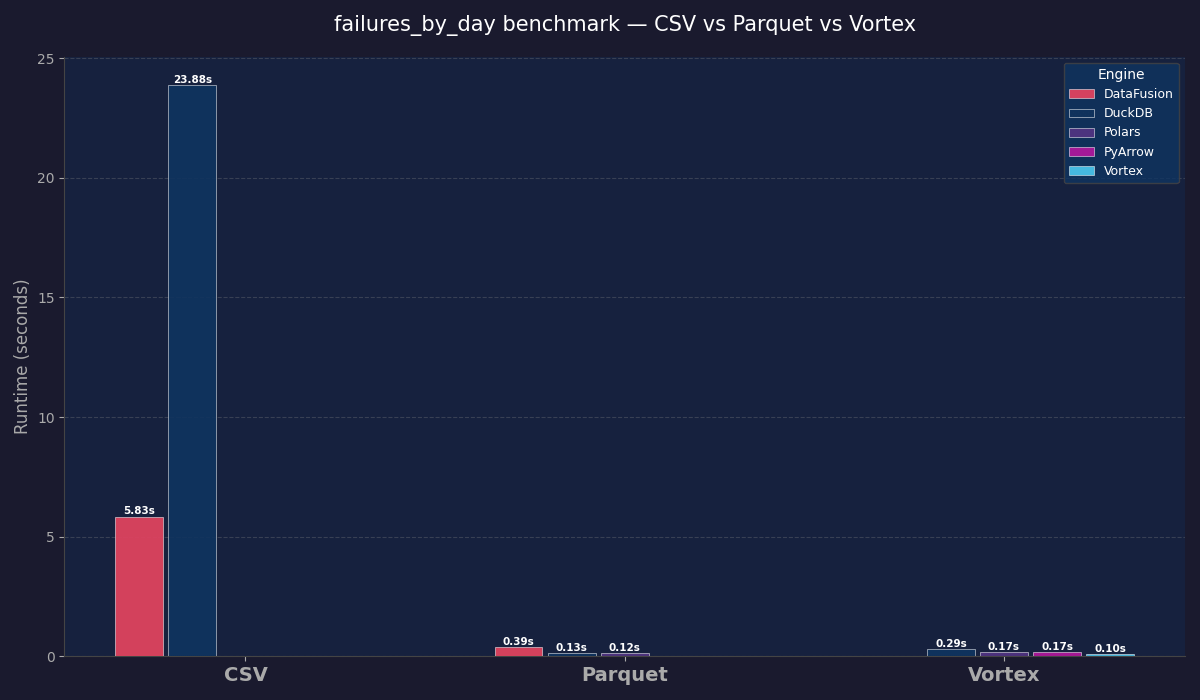
I didn’t learn a ton. Maybe the lift over Parquet is larger on massive datasets, but I'm not sure it’s worth the hassle of subpar Python framework integrations and ugly code, along with OOM issues when you try to read directories of Vortex files.
Is datafusion still a thing at this point?
Yeah the thing that struck me with Vortex when I first looked into it was that you have to move it to a Pyarrow Dataset to use it with a query engine. You can read it directly using the Vortex library but basically it became just Arrow for me to read it with something else. Maybe it's changed, I need to dive into it more.