

Building a DuckLake ... Open Source Style.
behold


I am sort of an addict for a good Lake House; it’s just an incredible architecture that is a joy to build and use daily. No more SQL Server or Oracle, you know what I’m saying if you were born in the right decade.
Truth be told, at this point in the Modern Data Stack lifecycle, you pretty much have two major Lake House storage layers that dominate the landscape: Iceberg and Delta.
I was surprised when DuckDB/MotherDuck threw their hat in the ring with DuckLake. Didn’t see that coming at the time.

Like anything done by DuckDB, it’s always top-notch and for a good reason. They have a knack for doing things right. Ever since I wrote that first article, I’ve been meaning to return to DuckLake and try it out in a more open-source setting again.
What I mean by that is can I use maybe a RDS Postgres instance and back DuckLake on AWS S3.
I mean, if someone is actually looking to use DuckLake in the open as a viable alternative to Iceberg and Delta Lake, then that is the game.
Checkout today’s sponsor Carolina Cloud
One-click notebooks, genomics tools, and Ubuntu VMs at 1/3 the cost of AWS with no egress fees

If you enjoy Data Engineering Central, please check out our sponsor's website above. It helps us a lot!
Also, since it’s been a while since I’ve looked at DuckLake, one telling note we will look for is: has there been any adoption of frameworks in the broader data community? Aka, can I read DuckLake with Polars, Daft, Airflow, whatever?

Simple Review of DuckLake
Again, there are better places than here to learn about DuckLake in depth. That’s not my focus today, as usual, I want to simply throw a problem at the DuckLake architecture, turn over a few rocks, and see what crawls out.

DuckLake is built on simplicity, of course, and that appears to be one of its main features.
Built on top of parquet
SQL database for catalog/metadata
Of course, they will give you a myriad of other reasons to use DuckLake, but at the end of the day … simplicity.

As I wrote before, this seems to be one of the main differences between say DuckLake and Apache Iceberg. Below is the concept visually, no more hosting a complicated Catalog.

DuckLake lets you use pretty much any SQL database as the metadata and catalog. Easy. That’s the point. No spinning up an instance to host some heavy catalog, or worse yet, having to pay for SaaS Catalogs.
This lowers the barrier to entry.
Setting up DuckLake on AWS (S3 + RDS Postgres)
There is no time like the present, so let’s dive in and see if we can get DuckLake up and running on an AWS setup, far away from that feathery MotherDuck, to see if indeed DuckLake is open-source-worthy.
Either it will be easy and boring, or it will be bumps in the night.
We need two things to make this work, in true open source style.
RDS Postgres instance.
S3 bucket.
We can use my gigantic and massive RDS instance, which I use for various sundry projects, a mighty db.t4g.micro. That little blighter costs me like $.50 per day to run.
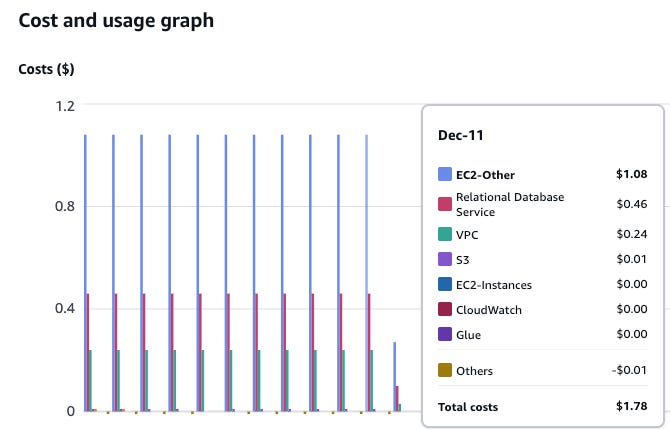
Also, we will attempt to use my S3 bucket, s3://confessions-of-data-guy, as the data path for DuckLake to store the parquets it generates.
In theory, this DuckDB/DuckLake command will look something like this.
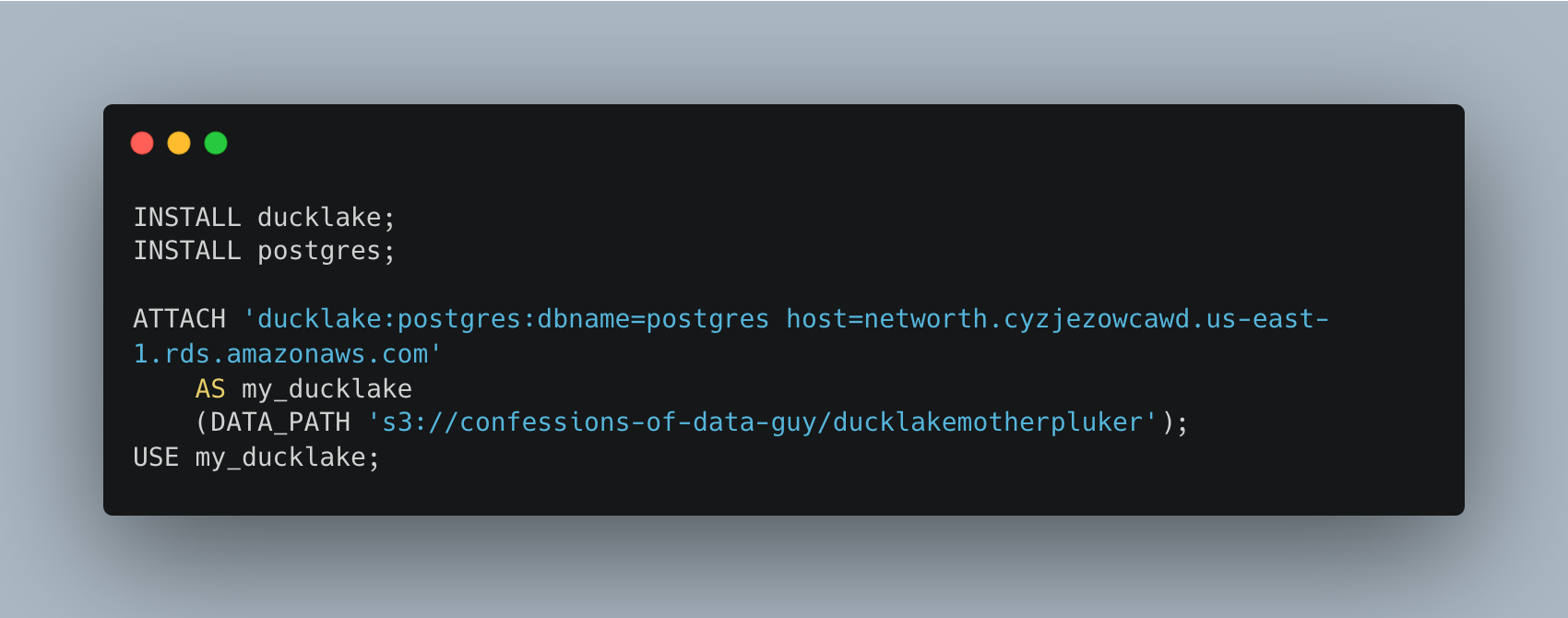
Of course, I will have to ensure that AWS credentials are available and that Postgres is available for DuckDB. Hold onto your seatbelt, Rita, here we go.
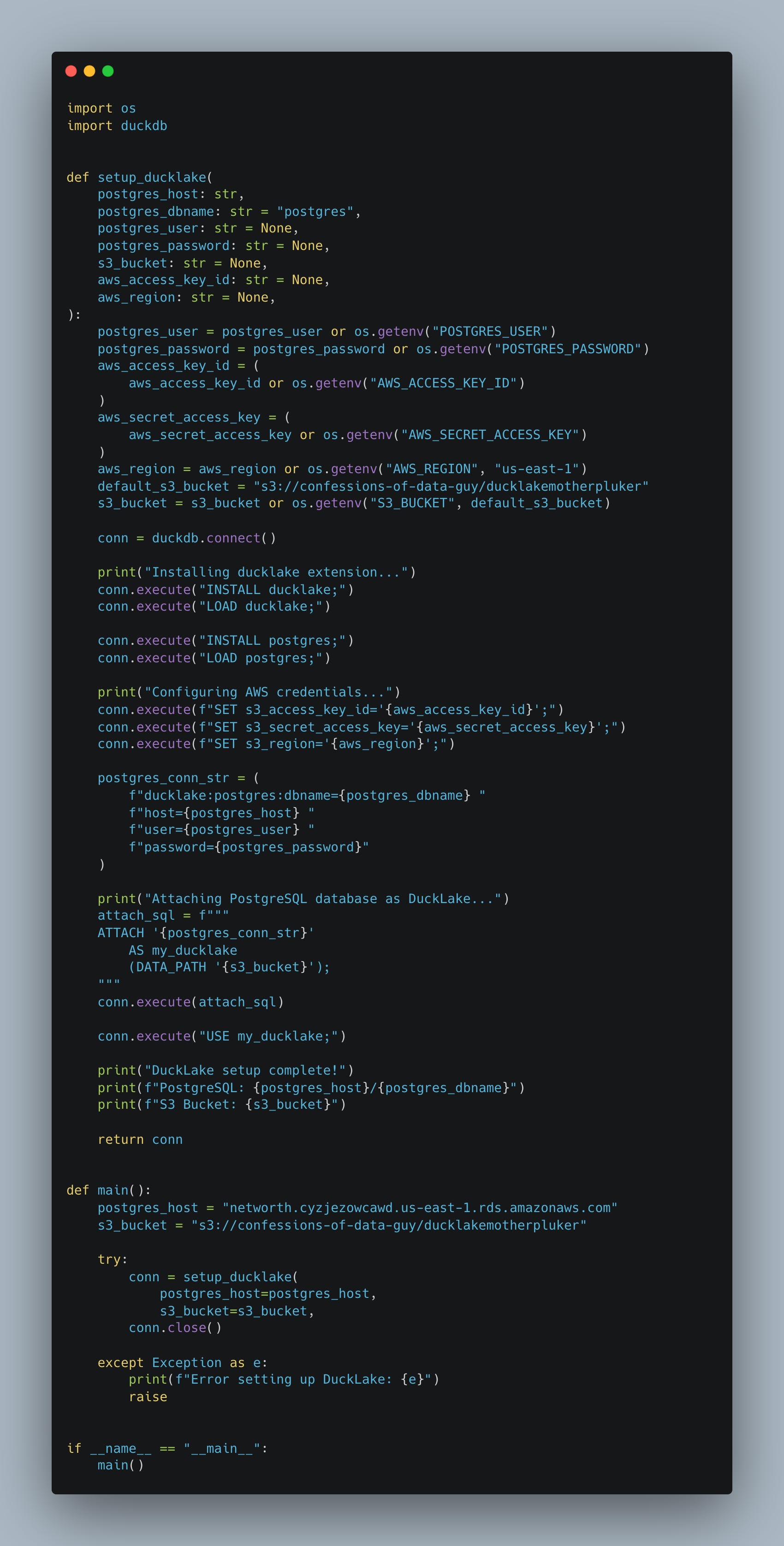
A lot of code, but it appears to run fine with UV.

Well, that was dissapointly easy. I know you all come here from the mess and mayhem. Not today, at least not yet. Let’s get some of that Divvy Bike trip data from the ole’ iterwebs, and see if can shove that data in there.

After munging the code a bit, this seemed to work like a charm.

Heck, to make sure I wasn’t hallucinating, I checked S3 and can see the files written there for our DuckLake.
They are there, and the results of those sample queries appear to be running fine.
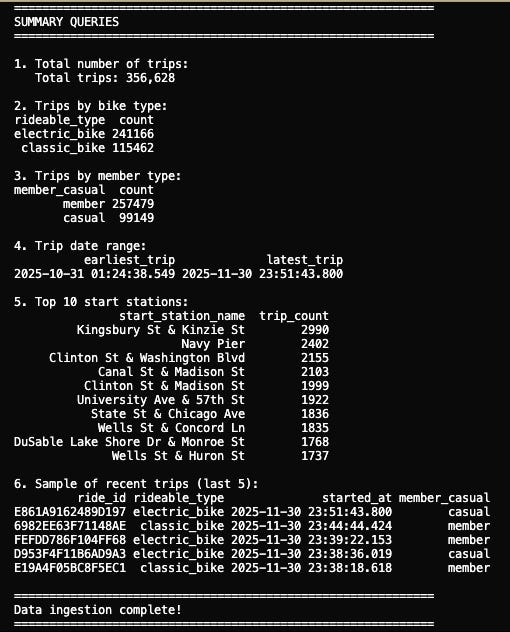
Please leave it to DuckDB and MotherDuck to make this a boring article, those little rats. They could have made me try a little bit harder, you know? Indeed, DuckLake is a valid Lake House option in the open source world if you’re looking for a lightweight option.
Don’t get no lighter than that. No Big A$$ catalog needed here.
If you want to do this yourself, all the code is available on GitHub.

More thoughts on DuckLake
That went better than I expected, although I should have learned my lesson; DuckDB rarely gets anything wrong, and the same applies to DuckLake. You never know how a tool will react to trustworthy open source. I enjoyed the fact that I could use an RDS Postgres database for the metadata and a random S3 location for the data storage.
What remains to be seen is whether MotherDuck and DuckDB will push for first-class support in other popular tools, such as Polars and Daft.
It looks like some of this is already underway, but time will tell whether it keeps chugging forward.

It’s hard to imagine anyone giving Delta Lake and Apache Iceberg a run for this money. Still, with Data Catalogs now and in the future heavily integrated into those tools, there might come a day when people have had enough and look for an easier option, DuckLake being one, as long as it has broad tooling adoption.
Love the simplicity angle here—skipping the heavy catalog layer feels like such a practical win for smaller teams. The RDS Postgres + S3 setup is exactly what I've been looking for without vendor lock-in. Curious how DuckLake handles schema evolution compared to Iceberg though, since that's been a sticking point in past migrations I worked on. The fact DuckDB just works reliably every time is kinda refershing in this space honestly.