

ClickHouse: A Super-Fast Columnar Database
Guest Post Series


Hello! This is Daniel. I’m excited to introduce a new guest post series that showcases other data professionals, giving them a space to teach us all new tech and ideas.
Today we are going to hear from Ahmed Shaaban, you can check out his work here on Substack and find him on Linkedin.
With that, meet our first guest, Ahmed.

As a passionate and results-driven Data Engineer, I specialize in designing and building robust data systems that support advanced analytics and decision-making.
With experience in developing and optimizing Data Lakes and Data Warehouses, I enable organizations to manage vast datasets seamlessly. My expertise extends to creating real-time Dashboards that provide actionable insights, empowering stakeholders to make informed decisions. Outside of work, I enjoy writing and sharing what I learn with the community.
When it comes to databases, there are two main types you’ll hear about: row-based and column-based. That’s pretty much the big divide in the database world.
Column-based databases are the go-to choice for analytics. They’re great when you want to run large aggregations quickly—like calculating totals, averages, or trends across millions or billions of rows.
That’s because they store records column-by-column, instead of the traditional row-by-row format. So whey you need to read all values for a column to do some sort of aggregation on it, you can read only that column directly from the disk. You don’t have to read other columns simply because they are stored together.
But if you’re looking to set a columnar database, you’ll quickly notice there aren’t a ton of options. One of the most interesting (and powerful) ones out there is ClickHouse.

It’s an open-source, columnar database built specifically for real-time analytics. It scales both vertically (beefier servers) and horizontally (more servers), and if you don’t want to manage infrastructure yourself, there’s also a fully managed SaaS version that handles setup and maintenance.

ClickHouse by the Numbers
ClickHouse makes some bold performance claims:
Up to 95% faster than Google BigQuery
3–5 times cheaper than Snowflake
Uses half the storage of PostgreSQL
Sure, some of these numbers might be a little hyped up by sales teams, but even if they’re only half true, that still says a lot. You’ve got to be pretty confident to make claims like that, and in many real-world scenarios, ClickHouse does live up to the hype.
Why Is ClickHouse So Fast?
So, what’s the secret sauce behind ClickHouse’s speed? It all comes down to smart architectural choices and clever optimizations. Here’s a quick breakdown:
Columnar Format
ClickHouse stores data by column, not by row. This is perfect for analytical queries that need only a few columns but scan through many rows. Less data read = faster results.
Row-oriented DBMS

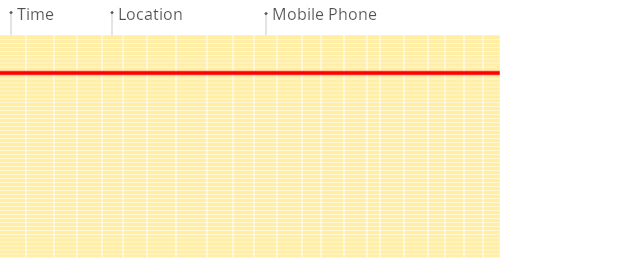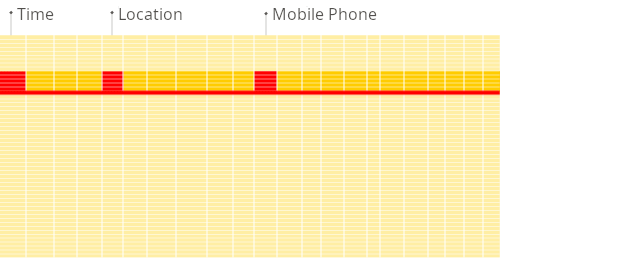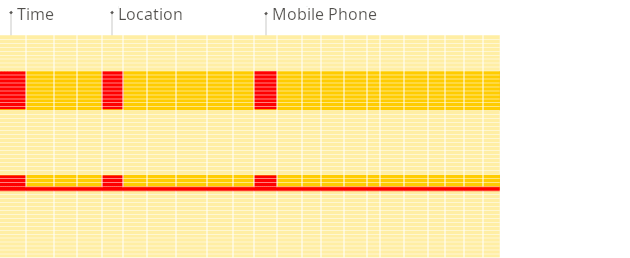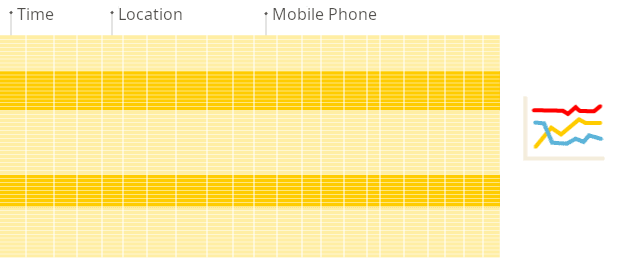
Column-oriented DBMS
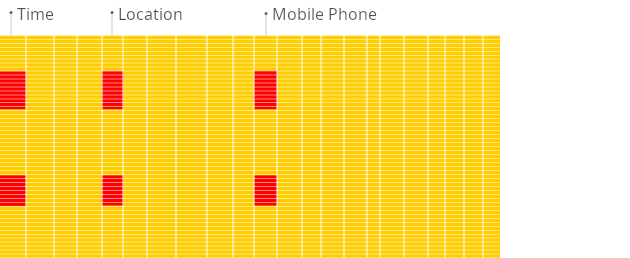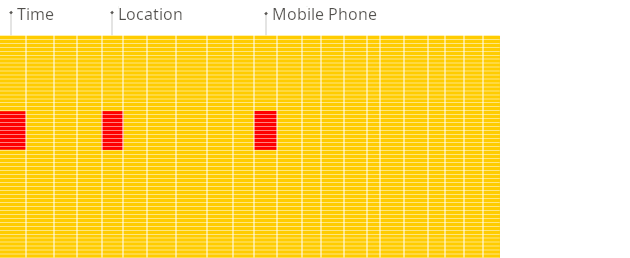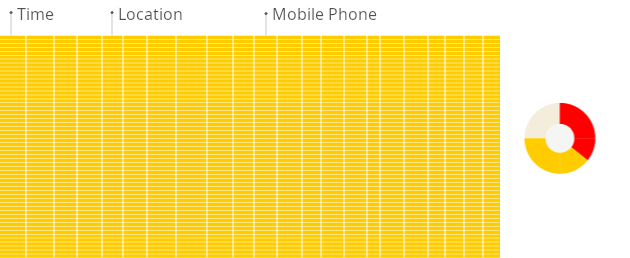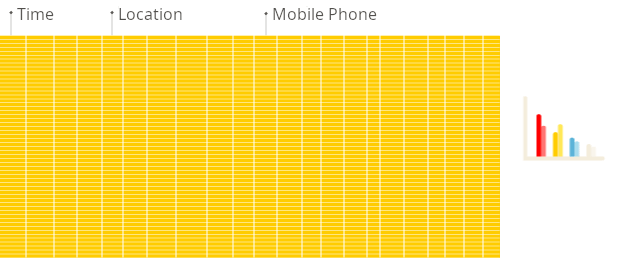
Source (https://clickhouse.com/docs/intro#row-oriented-vs-column-oriented-storage)
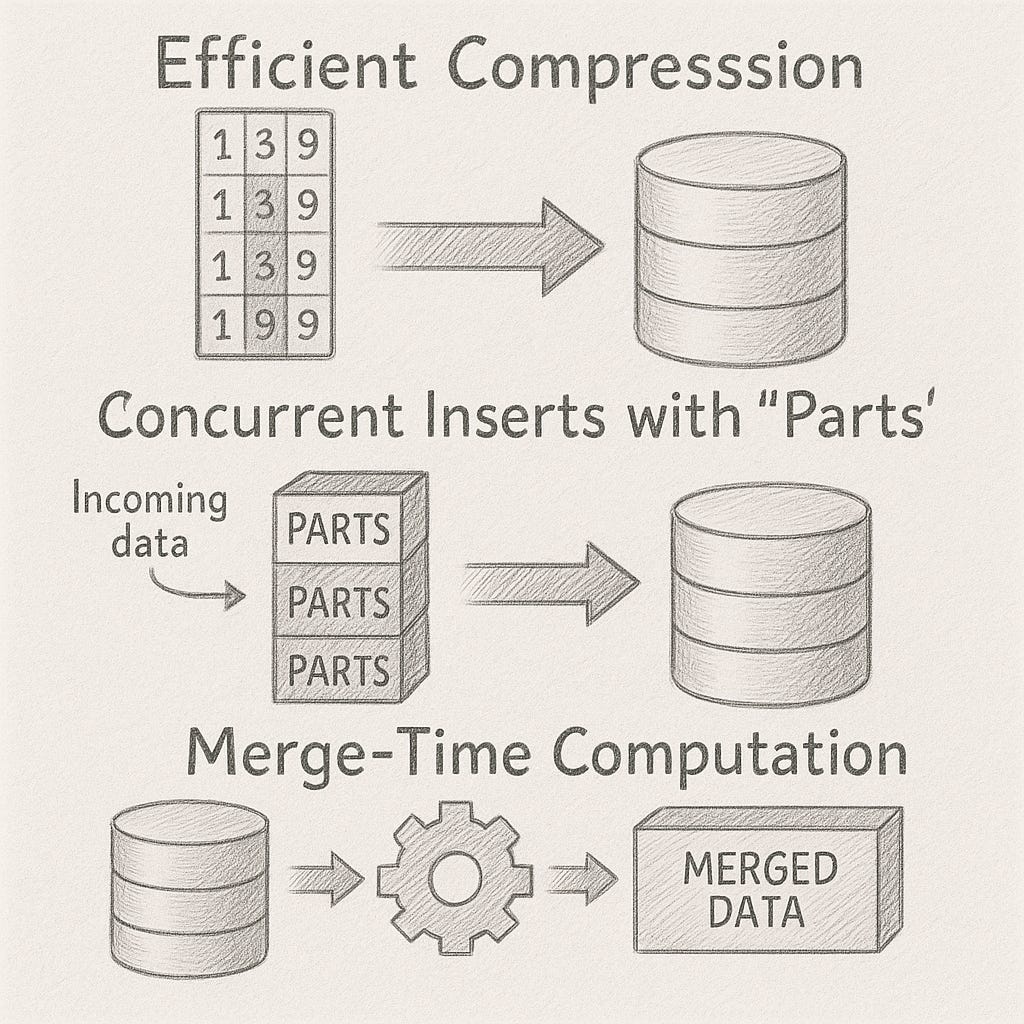
Efficient Compression
Similar values are stored next to each other in a columnar layout, which makes compression much more effective.
ClickHouse supports several compression algorithms, like ZSTD and LZ4 (general-purpose), and more specialized ones like FPC for floating-point data or Delta for integers.
Concurrent Inserts with “Parts”
Incoming data is written into separate chunks called parts. These parts are later merged in the background.
This means inserts are fast and isolated—you’re not constantly locking or rewriting existing data.
Merge-Time Computation
Instead of doing expensive computations or checks when data is inserted, ClickHouse defers that work until the background merge phase.
This makes writing data fast and opens up room for smart transformations later—like replacing duplicates, aggregating rows, or even archiving old data.
All of these architectural choices explain why ClickHouse is fast— but performance isn’t everything. What really makes ClickHouse stand out is how much flexibility and control it gives you when designing your data model and optimizing for different workloads.
Let’s take a look at some of the features that make it more than just a fast engine.
ClickHouse Features That Stand Out
Now that we’ve covered why ClickHouse is so quick, let’s talk about some of the cool features that make it even more powerful—and flexible.
Sparse Primary Indexes
In ClickHouse, indexes are sparse, which means they don’t store an entry for every single row. Instead, they keep track of just the first row in each granula.A granule is the smallest indivisible data set that is stored on disk and streamed into ClickHouse for data processing.
Since tables are sorted by the primary key, this is usually all you need to quickly find the data you’re looking for. And because the index is small, it often fits entirely in memory, making lookups super fast.
Data part (on disk)
┌───────────────────────────────────────────────┐
│ Columns: (UserID) (URL) (EventTime) │
│ │
│Sorted by primary key: (UserID, URL, EventTime)│
│ │
│Partitioned into “granules” (e.g. 8,192 rows) │
│ ┌──────────────┐ ┌──────────────┐ … │
│ │ Granule 0 │ │ Granule 1 │ │
│ │ rows 0–8191 │ │ rows 8192–… │ │
│ └──────────────┘ └──────────────┘ │
└───────────────────────────────────────────────┘
Sparse Primary Index (in memory)
┌────────────────────────────┐
│ Mark 0 → (UserID₀, URL₀) │ ← first row of Granule 0
│ Mark 1 → (UserID₁, URL₁) │ ← first row of Granule 1
│ … │
│ Mark N → (UserID_N, URL_N) │ ← first row of Granule N
└────────────────────────────┘
Projections
Tables in ClickHouse are sorted based on their primary keys, so it’s smart to design those keys to match your most common queries. But what if you have multiple types of queries that need different sort orders?That’s where projections come in. A projection is basically a different physical version of your table—one that’s optimized for a specific query pattern. It can have a different primary key, be filtered, or even pre-aggregated.
Multiple Storage Engines
ClickHouse lets you choose different storage engines depending on your use case, even within the same schema. The two main families are:MergeTree-based engines: These support background merges and are super flexible. Most production tables use one of these. Examples include:
MergeTree: The default, general-purpose engine.
ReplacingMergeTree: Automatically deduplicates rows based on a version column.
AggregatingMergeTree: Stores data in an intermediate aggregating state, which greatly improves aggregations
Log-based engines: These are simpler and append-only. Good for smaller, quick jobs or temporary tables. Examples:
Log: Basic append-only engine.
TinyLog: Lightweight version for tiny datasets or testing.
Materialized Views
Materialized views in ClickHouse help you shift processing from query time to write time. They let you precompute results and store them as data comes in. There are two types:Incremental materialized views: Automatically update as new data is inserted.
Refreshable materialized views: Can be recomputed manually or on a schedule.
While projections give you multiple layouts of the same data (ideal for speeding up queries), materialized views let you transform the data during insert time (great for things like aggregations, rollups, or schema simplification). Think of it this way:
Projections = multiple optimized copies
Materialized views = preprocessed summaries

ClickHouse Isn’t a One-Size-Fits-All Tool
As fast and powerful as it is, ClickHouse isn’t built to do everything. It’s amazing for real-time analytics and large-scale data crunching, but it’s not a transactional database. You won’t get full ACID guarantees, and it’s not meant to replace systems like MySQL or PostgreSQL for complex transactions.
Also, if your workload relies heavily on frequent updates or deletes, ClickHouse might give you some headaches.
While those operations are supported, they come with a serious performance cost and often require rethinking your data model to fit ClickHouse’s strengths (It’s worth noting here that ClickHouse has improved the updates statement’s performance by a lot recently, so this assumption may not be valid in the near future)
In the end, we can say that ClickHouse is a powerful option if you need real-time analytics, fast inserts, and low-latency queries over huge datasets. It’s used by companies across industries for observability, product analytics, monitoring, and time-series storage.
It’s not trying to be your all-in-one database. But if you understand its strengths—and design around them—it can be a game-changer.
So if you’re building a system that needs to move fast, crunch data hard, and scale effortlessly, ClickHouse is definitely worth a look.
 | A guest post by
|