



Cloudflare R2 + Apache Iceberg + R2 Data Catalog + Daft
the S3 Table killer?


Sometimes, we do things without thinking because that is what our forefathers have taught us; we walk the well-trod path before us without question — lemmings doing lemming things.
S3 from AWS is one of those things. We use it a thousand times a day; it is a critical path and component of our Data Platform and Pipelines. If it disappeared, we would come to a collective grinding halt.
It costs a lot of money too.
I’ve been meaning to check out R2 from Cloudflare to see if it is what they say … a s3 killer. Then they did something that made me sit up in bed and scream. A managed R2 Data Catalog for Apache Iceberg that is built right into the bucket.

R2 storage and buckets from Cloudflare.
Let's start from the beginning, see what this storage option from Cloudflare is, is like and how it compares to AWS s3; then we shall explore the new R2 Data Catalog for building Apache Iceberg tables in the cloud.

“Cloudflare R2 is a global object storage service offered by Cloudflare that allows users to store and access unstructured data without incurring egress fees. It is designed to be S3-compatible, making it easy to migrate existing applications or build new ones that utilize object storage.”
- AI
One of the most attractive parts of Cloudflare’s R2 storage is that they are realists. They made it S3 API compatible, which is simply a must. This makes the migration of code and data, as well as the onboarding of new Engineers, much simpler and straightforward.

I hate to touch on pricing because, most of the time, you need a degree from Gandalf’s School of Wizardry to understand any cloud tool's minute and hidden costs. Being that is what it is, let’s take them at their word and compare them to s3.
R2 charges based on the total volume of data stored, along with two classes of operations on that data:
Class A operations which are more expensive and tend to mutate state.
Class B operations which tend to read existing state.
For the Infrequent Access storage class, data retrieval fees apply. There are no charges for egress bandwidth for any storage class.

As compared to AWS s3.

I will let you smart people figure out the rest yourselves. I set up a personal account with Cloudflare; they give you some free storage, etc.
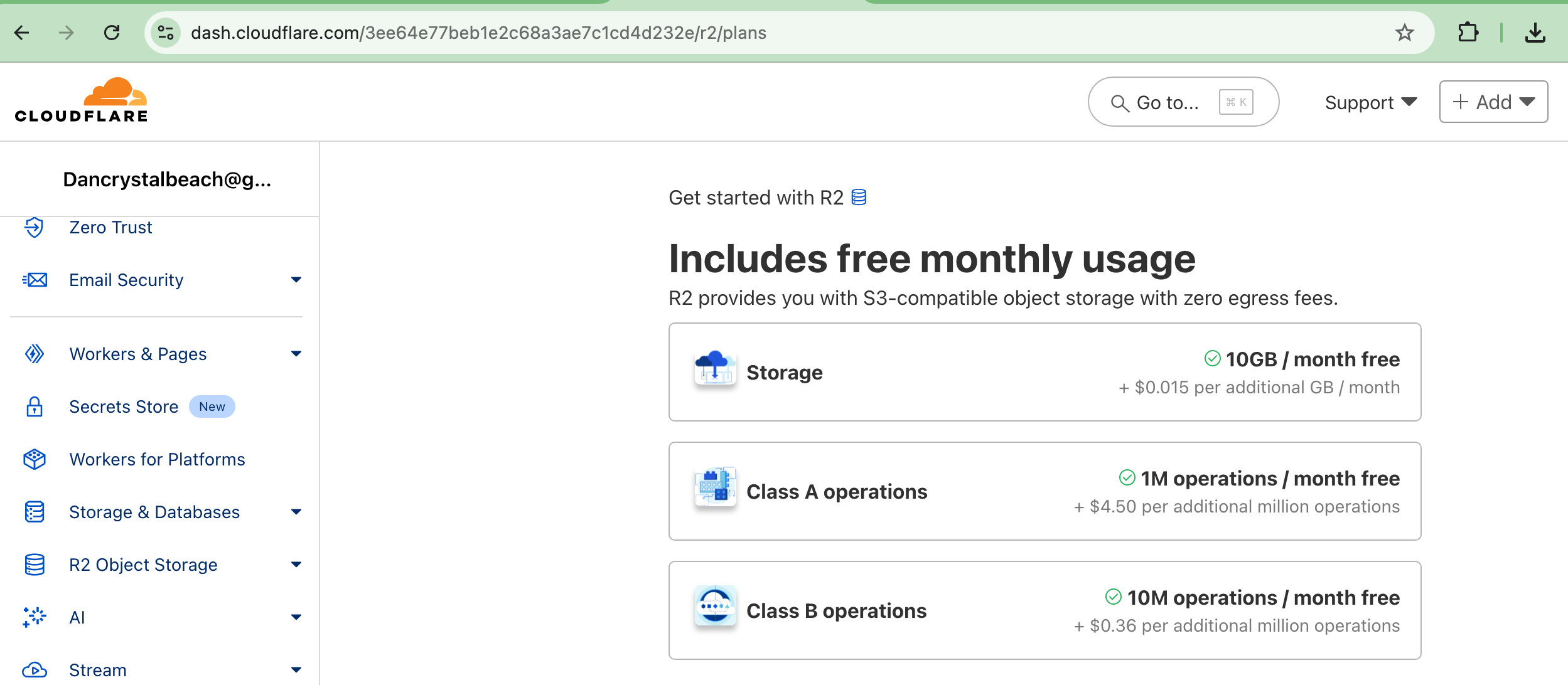
Next, let’s just set up a new R2 bucket and see if we can get the R2 Data Catalog going. Wait, I’m getting ahead of myself. We’ve been talking about R2 for storage, but we haven’t talked much about the Apache Iceberg and managed Data Catalog that Cloudflare is now providing.

“R2 Data Catalog in open beta, a managed Apache Iceberg catalog built directly into your Cloudflare R2 bucket …
R2 Data Catalog exposes a standard Iceberg REST catalog interface, so you can connect the engines you already use, like PyIceberg, Snowflake, and Spark. And, as always with R2, there are no egress fees, meaning that no matter which cloud or region your data is consumed from, you won’t have to worry about growing data transfer costs.”
This is exciting indeed. Yet another SaaS and Cloud behemoth is entering the Lake House race, getting involved in the ongoing Storage Format War, and making Big Data at scale as simple as a click of a button.
But this is nothing new to you, my fickle reader. Everyone under the sun has been trying to make it as frictionless as possible to build and manage Lake House tables in the cloud. Cloudflare’s entry into the fray is good for competition and will push others to up their game.
Now that we have the boring part out of the way, let’s get to actually creating an Apache Iceberg table in R2, using the provided Data Catalog. Should be fun!!!
Create R2 Bucket and Apache Iceberg table with R2 Data Catalog.
So, if you are new to Cloudflare, they have a tool called Wrangler that you can use on the CLI to run many commands, think of it like the aws cli many of you use (requires NPM to install Wangler).
>> brew install node
>> npm create cloudflare
──────────────────────────────────────────────────────────────────────────────────────────────────────────
👋 Welcome to create-cloudflare v2.44.1!
🧡 Let's get started.
📊 Cloudflare collects telemetry about your usage of Create-Cloudflare.
Learn more at: https://github.com/cloudflare/workers-sdk/blob/main/packages/create-cloudflare/telemetry.md
──────────────────────────────────────────────────────────────────────────────────────────────────────────
╭ Create an application with Cloudflare Step 1 of 3
│
╰ In which directory do you want to create your application? also used as application name
... blah, blah, blahNow, we already have a R2 bucket …

What we need to Enable R2 Data Catalog on your bucket.
>> npx wrangler r2 bucket catalog enable testing-iceberg-r2
Successfully logged in.
✨ Successfully enabled data catalog on bucket 'testing-iceberg-r2'.
Catalog URI: 'https://catalog.cloudflarestorage.com/3ee64e77beb1e2c68a3ae7c1cd4d232e/testing-iceberg-r2'
Warehouse: '3ee64e77beb1e2c68a3ae7c1cd4d232e_testing-iceberg-r2'
Use this Catalog URI with Iceberg-compatible query engines (Spark, PyIceberg etc.) to query data as tables.
Note: You will need a Cloudflare API token with 'R2 Data Catalog' permission to authenticate your client with this catalog.
For more details, refer to: https://developers.cloudflare.com/r2/api/s3/tokens/Well, that was way too easy wouldn’t you say? Nothing works the first time without problems, what a breath of fresh air. We can see from the notes above that we will need an API token to assist with authentication.
I went ahead and used the docs to create tokens, one nice thing is that they give you s3 compatible tokens … aka if you are using or migrating s3 code.
Creating Apache Iceberg table on Cloudflare’s R2.
Next, let’s get to actually creating an Iceberg table on R2, and to prove out that it works well, let’s use my Databricks account and Daft to do this.
Let’s be real, if this is going to be used in production, we have to be able to do it like this … not on someones laptop. It’s the Cloud or bust.
We will use BackBlaze hard drive dataset as our base data to create an R2 Apache Iceberg table with the R2 Data Catalog.

That’s the data. This is how we can create our Iceberg table on R2. You can get the R2 Details needed from the Cloudflare Dashboard.
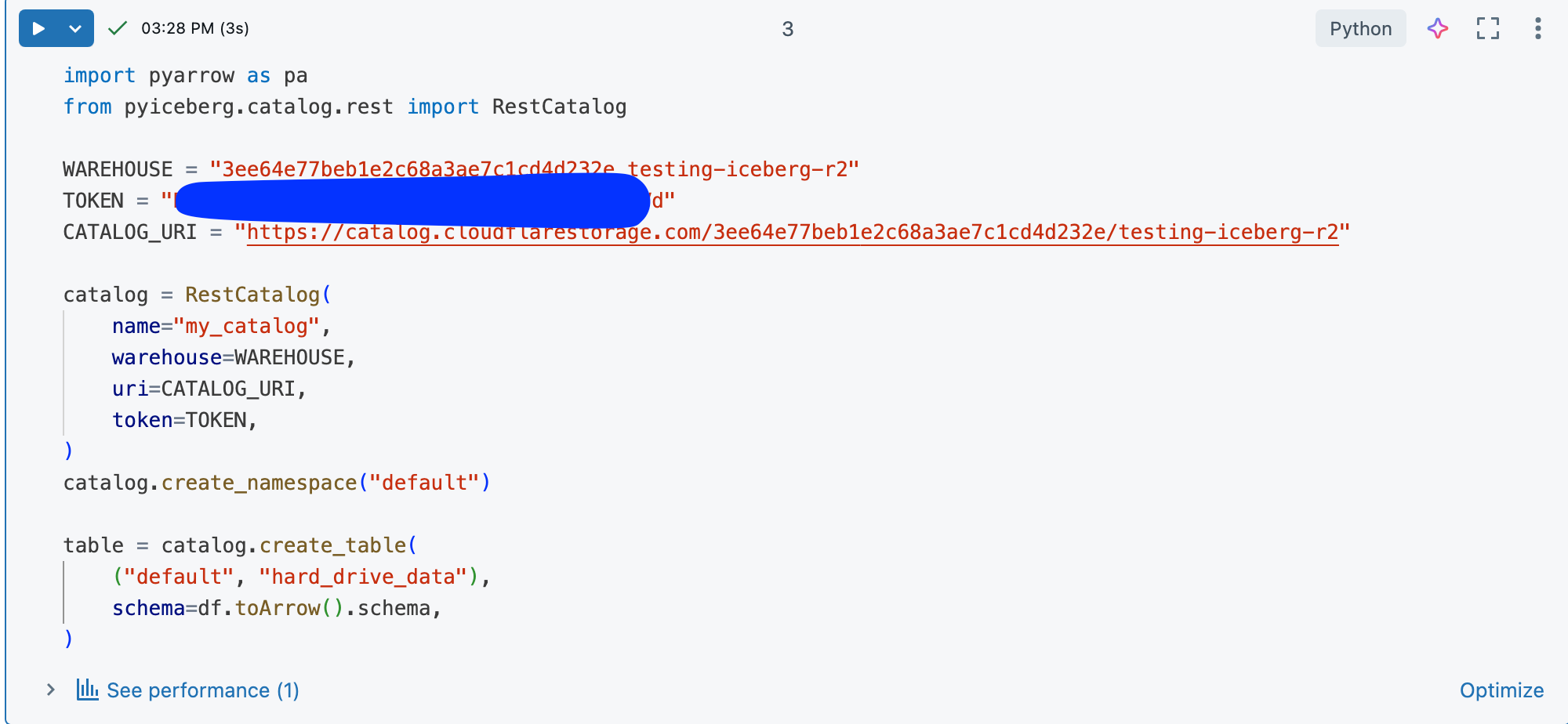
I to comment on this … how easy is this?? That is the beauty of working with Iceberg on Cloudflare’s R2 … it’s idiot proof, even I can do it.
Unless you’ve spent time like me piddling around with Iceberg using LakeKeeper, Polaris, etc etc, it’s hard to appreciate the utter simplicity with which R2’s Iceberg Catalog makes working with Lake House tables … all stored, served, managed via Cloudflare.
Next, let’s see if we can read this empty R2 Iceberg table with Daft on a Databricks Cluster.
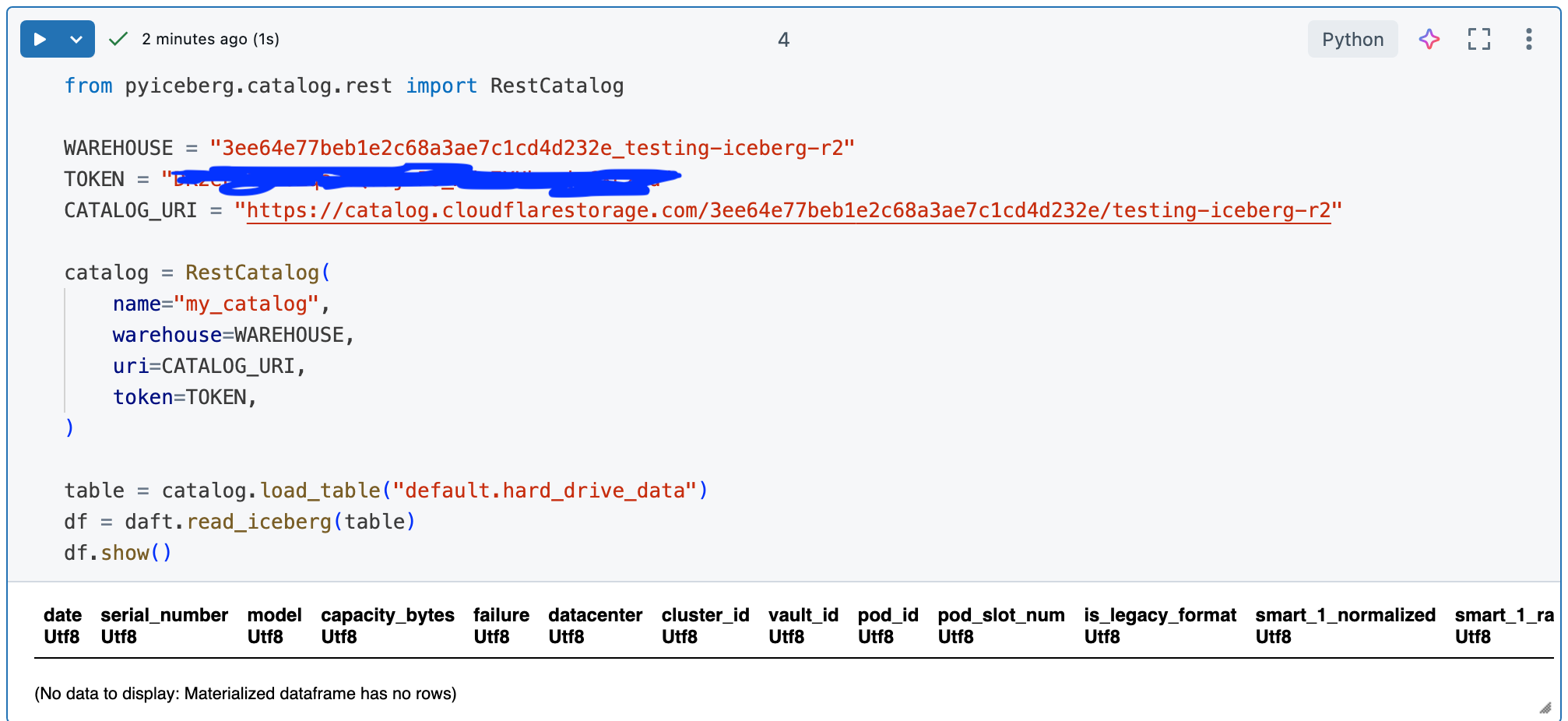
Look at that! Just as simple and easy as could be. Well, can we go a step farther and write a bunch of data into our R2 Iceberg table with Daft?
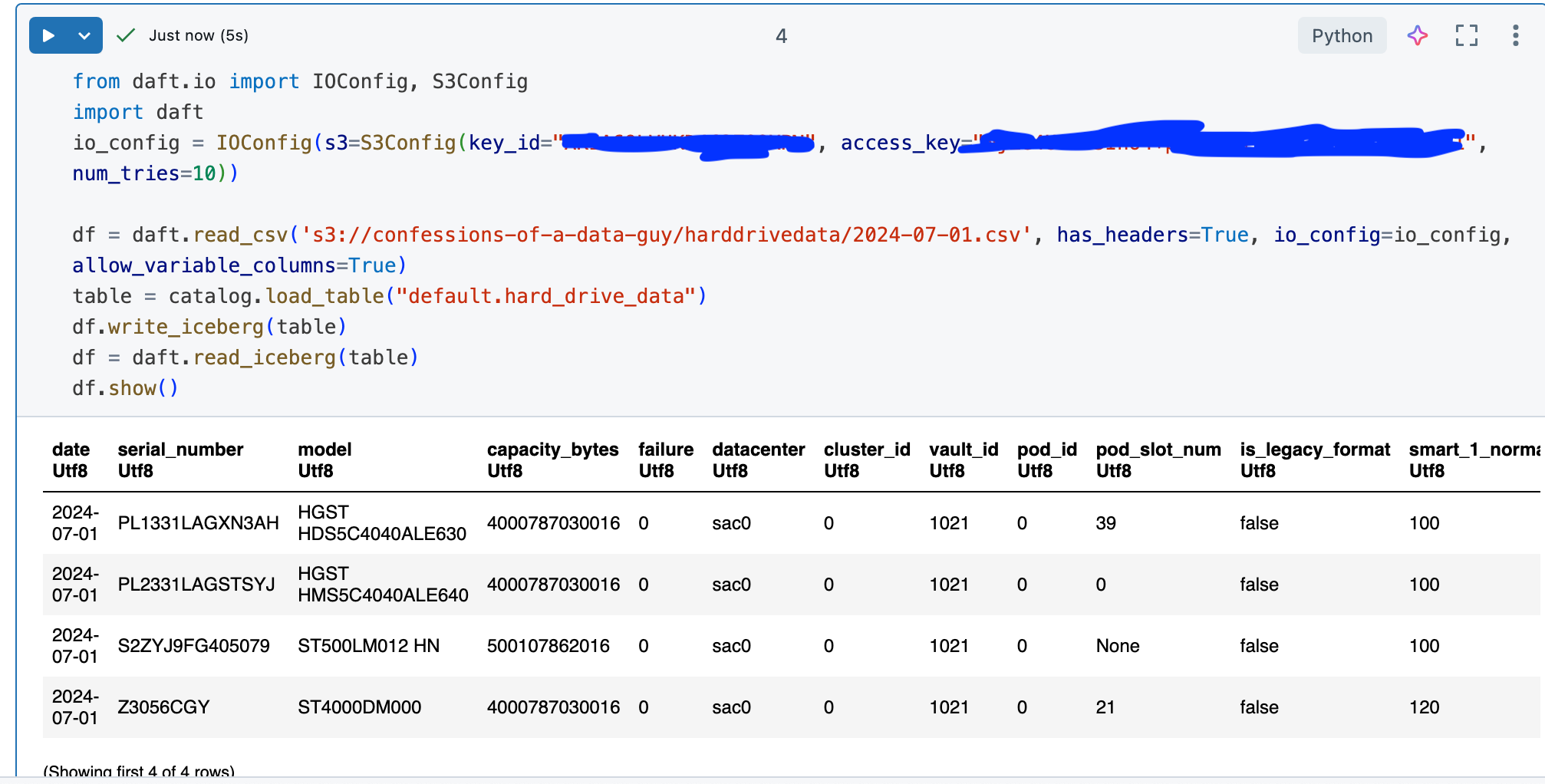
Smooth as butter my friend, that’s what I like to see (Almost as smooth as Delta Lake). I have to say Cloudflare’s R2 and their top-notch Apache Iceberg setup is the cream of the crop.
Pair it with something like Daft and you have production-ready Lake House just begging to be beat with queries.
I mean I wish I had more complicated code and fancy backflips to make me look smart and wise. Too bad Cloudflare did such a good job, made it too easy.
Thanks for running through this! I got really excited the day I saw the announcements. I don't think I yelled like you, but I did the equivalent — sending the links to a half a dozen people and a few Slack / Discord channels.
I saw "Iceberg REST" + "R2" + "FREE EGRESS" and had an immediate use case in mind.
Very cool. I know it’s in beta - did you run into any specific trouble or limitations?