

Clustering vs Partitions - Pick your poison.
... for the Lake House


Now that the Lake House has taken over the known world and become the new SQL Server of the old (I lived them) days of the Data Warehouse … things have changed. One topic that is mainly ignored yet at the core of our data processing is partitioning … and, more recently, clustering.
Today, I plan to ramble on about these topics in the context of the Lake House … specifically Delta Lake and Apache Iceberg.
It isn’t a deep dive under the hood of partitioning and clustering in these two tools but more of a discussion about where we have come from (Hive-style partitioning), where we are today (confused), and what matters at the end of the day.
__________________________________________________________________
Please take a moment to check out this article’s sponsor, OpenXData conference 2025, without them this content would be possible. Please click the links below to support this Newsletter.

The data infrastructure event of the season is here → OpenXData conference 2025
A free virtual event on open data architectures - Iceberg, Hudi, lakehouses, query engines and more. Talks from Netflix, dbt Labs, Databricks, Microsoft, Google, Meta, Peloton and other open data geeks.
May 21st. 9am - 3pm PDT. No fluff. Just solid content, good vibes, and a live giveaway if you tune in!
__________________________________________________________________
What IS data partitioning, and why does it matter?
We should probably start at the dawn of time when dinosaurs roamed the earth. What is called “Hive-style” partitioning was, and in many places still is, the go-to way to store big data.
This may be obvious to some, but if you are new to the data world and big data, the idea is that you can’t, or shouldn’t, randomly store data in files (at scale) … without context (liquid clustering or invisible partitioning).
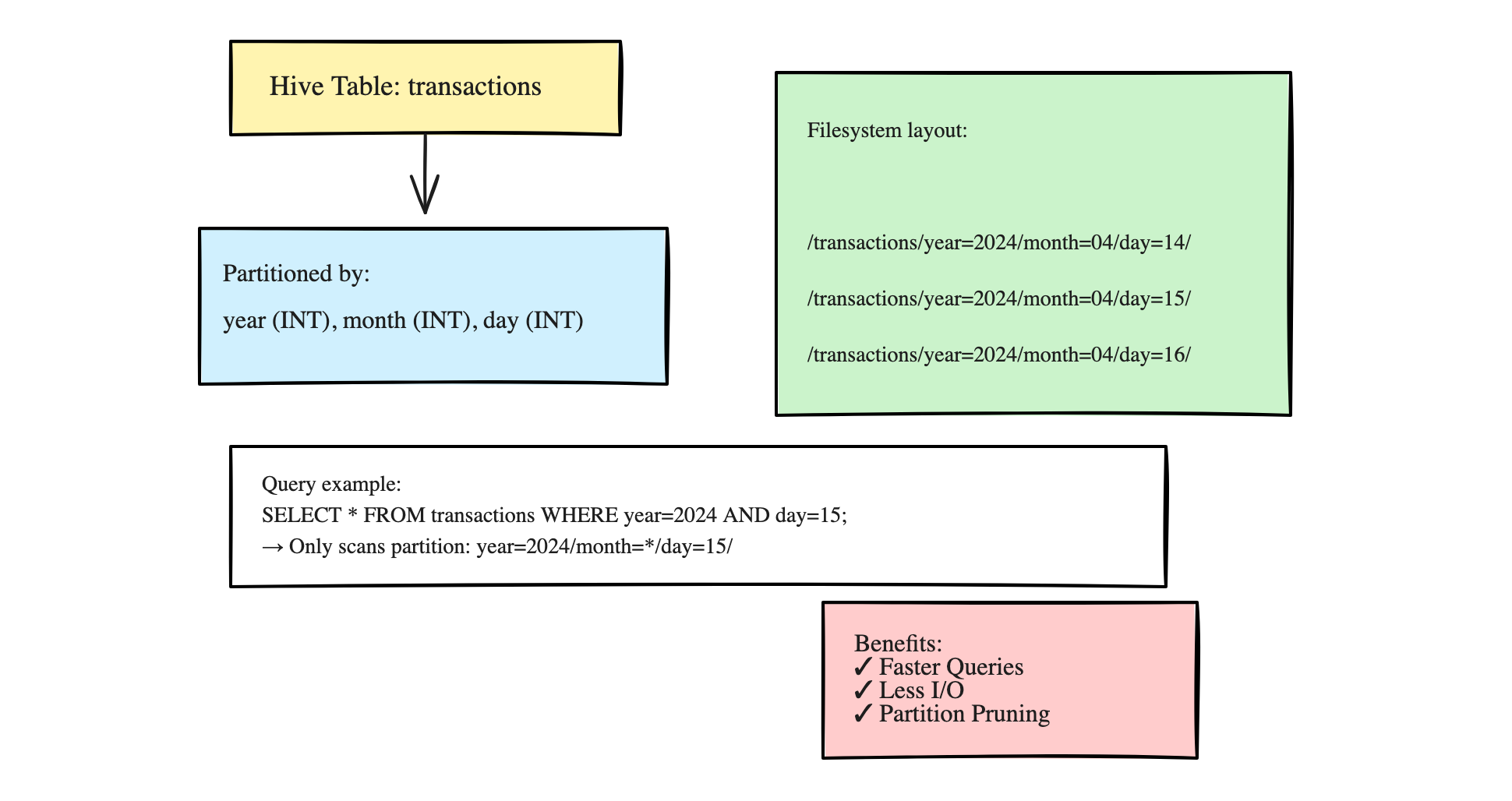
If you need to read a data set and find where date = ‘2025-04-16‘, you have to…
read the entire dataset (files) to find all instances of date = ‘2025-04-16‘
or use some partitioning and jump to the files where that data is stored.
Before we continue, I want to make a point.
No matter what new fancy technology is used or created in the future, understanding at a fundamental level WHY data layout and partitioning are important is key to being a good Data Engineer.
This concept is at the core of data layouts and partitioning, the idea of physically colocating similar data together in files. For example, like above, files with today’s date are stored together.
Context is key.
Never forget that in all situations of data layout, from old-school Hive-style partitions to the new fancy liquid clustering (we will talk about that later), the query patterns on the data itself should and do drive how data is referenced and/or stored.

It’s sorta a catch-22, so to speak. You want your data partition strategy to cover 80%+ of your use cases, but it’s virtually impossible to cover all use cases.
As you can probably already tell from the examples, this sort of partitioning is very “rigid” in nature. Once data has been written into files and partitioned … the ship has sailed. This is fine if you are smart and query patterns don’t change … which does exist, but if things changed, you could be in trouble (need to re-write data, etc.)
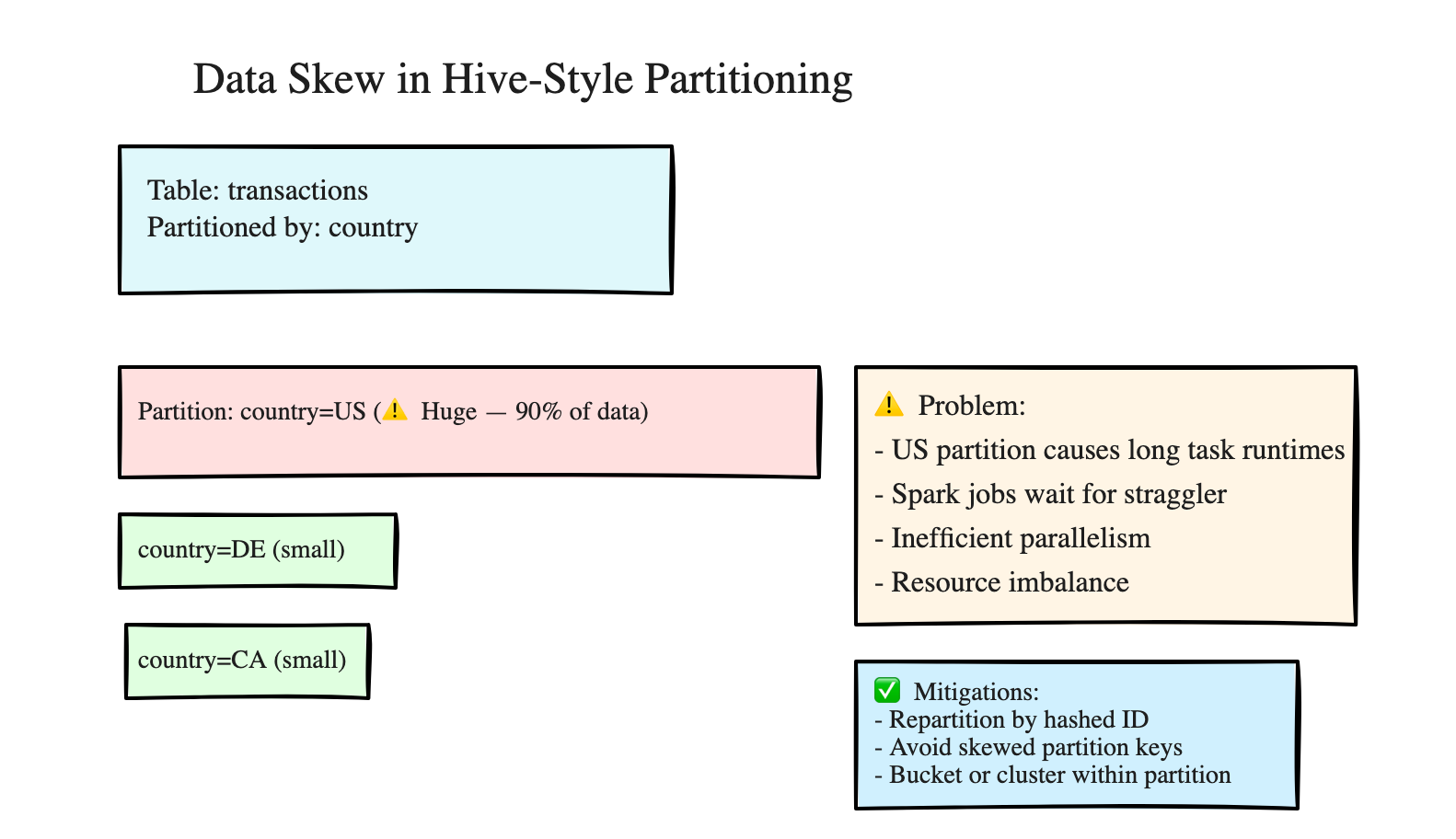
Also, such rigid “Hive-style” partitioning is highly susceptible to “data skew” and partition imbalance.
some partitions have lots of data
some have very little data
Things started to change.
Today, “Hive-style” partitioning is still in full swing, and it is used in many places. Heck, I use it. Why?
it’s conceptually simple
easy to use (via queries)
works well for data and query patterns that never change
You can still use this partitioning style if you know what you are doing, and it will bring you great success. But, of course, things started to change in the Lake House world with more complex queries, requirements, and business needs.
Features like Z-Order and OPTIMIZE (compaction) with Delta Lake and Databricks started to become integral to running a Lake House.
“In Databricks with Delta Lake, Z-ordering is a technique that helps to colocate related data within the same set of files, enabling efficient data skipping during queries.”

Again, I’m not trying to teach you these concepts from scratch; go read about them yourself if you are unfamiliar with them, but what I’m trying to show is how technology and engineers have changed how partitioning is done to meet the ever-increasing demand for faster and better performance.
Liquid Clustering and Invisible Partitions … a new Era!
All this demand for ever faster and more flexible data layouts to support high-performance has lead to a new era of data layouts that are now more “automatic” and “flexible,” relying less on humans and more on computers.
I am far from an expert in these new technologies, and I’m sure someone can spot something wrong below, but here is a high level take on this new style you will see across the Lake House landscape.
🧊 Apache Iceberg – Hidden Partitioning
Traditional partitioning (like Hive) exposes partition columns in the table schema (e.g. year=2024/month=04).
Iceberg uses hidden partitioning:
Partition columns are defined at the metadata level, not exposed in the schema.
Partition transforms like
bucket(id, 16),truncate(name, 4), orday(timestamp)are common.
Benefits:
Cleaner table schemas.
More flexibility for optimizers to choose how to layout the data without leaking internals.
You can change partitioning without changing the schema or breaking queries.
🌊 Delta Lake – Liquid Clustering (Databricks proprietary)
Liquid Clustering replaces static partition columns with dynamic clustering keys (e.g.
user_id,event_type).Files are physically laid out (and Z-Ordered) based on clustering keys, but no directory structure or partition columns are exposed.
Think of it as "continuous optimization" without static partitions.
OPTIMIZE TABLE ... CLUSTER BY (...)is used to maintain clustering.Benefits:
No need to pick rigid partitions.
Avoids the cost of re-writing partitions.
More granular, Z-order-style layout and skipping.

Where does that put us today? I don’t know, somewhere in the middle I suppose. Partitioning, like everything else in tech, is starting to be abstracted away from the average Lake House user. This is both a good and a bad thing.
In one sense, a newcomer to the Lake House world may have never heard of or used Hive-style or rigid partitions. Maybe us old dogs just have a hard time letting go.
I’ve seen major speedups in query speeds in Delta Lake moving to Liquid Clustering. Even an old dog has to admit that the new dogs have beat them at their own game.

I still enjoy to teach about partitions, and encourage those newer to the Lake House world to learn about them, try them out, get familiar. Why?
It’s always better to know HOW and WHY something works
Sure, liquid clustering and hidden partitions are the new norm, and I’m sure those will be replaced and updated over time. At the end of the day understanding how data is laid out inside files, how query patterns are affected by such things … this sort of knowledge is a golden key that unlocks all sorts of things.
Delta Lake Video on when to use which approach. This webinar provides a practical guide to engineers looking to harness the best of both liquid clustering and classic hive-style partitioning driven from the perspective of common data engineering problems and solutions.
https://www.youtube.com/live/0Gbq3B1FI-8?si=rmcK6jmoFDnxWuX9
Delta Lake Video on that topic https://www.youtube.com/live/l8CEyXgi7y4?si=C3g2ukOvkrODbVZ3