

Cost Savings for Databricks Users
Finding those pennies


It comes to this point eventually, no matter who we are are what platform we are working on. It’s a vicious cycle. We drink the Kool-aid like maddened and crazed cult followers, frothing at the mouth we plow our mind and energies into our Tool Savior until there is nothing left to give.
You should check out Prefect, the sponsor of the newsletter this week! Prefect is a workflow orchestration tool that gives you observability across all of your data pipelines. Deploy your Python code in minutes with Prefect Cloud.

Then one day our bosses show up and slap us backside the head and ask “What’s the matter with you? Have you seen this bill lately? Do something about it!”
Then it’s a mad rush of Googling and piddling. Where can we cut costs?
Today we will list some basic cost-saving measures for Databricks workloads and environments. Nothing fancy, just plain old common sense, no snake oil being sold here.
It's not uncommon for people to think that there is some special sauce or unicorn glitter that you can sprinkle on your Databricks setup resulting in %80 cost savings.
Dream on. Real cost savings are typically boring and revolve around good Engineering principles.
Let's get started. These are in no particular order.
First, we have two maintenance commands that are specific to Delta Lake, both should probably be run on a daily basis, depending on the volume of incoming data and updates in said Delta Tables.
OPTIMIZE
Compact small files into the perfect size. One of the most common performance problems encountered in Spark, when reading files (parquet … even Delta Lake) is the “small file problem.”
For extra cost savings, on large tables (many TBs+) you don’t need to OPTIMIZE the entire table every time/day. Use Partition Pruning to OPTIMIZE a subset (say recent) part(s) of your Delta Lake tables.
VACUUM
Remove unused and delete … aka unreferenced files.
For extra juice, look into the Delta Lakes transaction log and default retention (7 days).
Another small but easy win is to make sure you are not building up technical debt in the sense of not upgrading your systems. One simple change a lot of folks forget about is the DBR (Databricks Runtime version) version.
Upgrade DBR versions
Many speed improvements (say to MERGE statements) happen in newer DBR releases, keep your clusters (both Job and All Purpose) on some sort of upgrade schedule to take advantage of new features and performance improvements.
Try out Photon
Photon is a quiet hero of Databricks, it’s not much talked about but can lead to wonderful speedups in Job performance. Of course, test everything carefully yourself.
“Photon is a high-performance Databricks-native vectorized query engine that runs your SQL workloads and DataFrame API calls faster to reduce your total cost per workload.”
It’s important on Databricks to at least attempt to keep up with the new features being released like hornets from a nest you just threw water on. They pump ‘em out fast and it can be hard to keep up. Liquid Clustering is one of those new features you might have missed.
Things like Liquid Clustering are low-hanging fruit and will save you query performance … aka Compute Dollars at the bottom line. Do it.
Liquid Clustering
“Delta Lake liquid clustering replaces table partitioning and
ZORDERto simplify data layout decisions and optimize query performance.” Read more here where I did a test and got massive query performance improvements on Delta Lake tables with LQ.
Tune Cluster Sizes
Another obvious way to save a serious amount of pennies is to simply review all your Jobs and code running on every cluster you have. Many times when new pipelines are released it’s the ‘ol spit in the air and test the wind for choosing Cluster node sizes.
Look at your Logs Monitor your Jobs, and tune cluster sizes to ensure you aren’t wasting resources, there’s a 90% chance you probably are right now.
It might be small changes, but across a lot of Jobs you can affect the bottom line very easily.
Reduce All-Purpose Cluster Usage
This one is so obvious most people don’t think about it or never consider it. It’s well known (or should be) that All-Purpose compute on Databricks is a good +50% more expensive than Job Compute. Do something about it.
Not everyone needs their own personal All-Purpose Cluster to play around in Notebooks all day. Share one. Also, teach people to Develop locally before moving to a Notebook.
The next two tips are just general Big Data and Spark optimization ideas, probably the hardest ones to deal with … aka it’s going to make you learn and grow. Not a bad thing.
Tune Spark Jobs
Start with the basics, and use the 80/20 rule. Find your long-running jobs and figure out what’s going on with them. Use best practices like cache(), broadcast joins, filtering, reducing skew, etc.
Use correct Data Types in Delta Lake
Another not though of much problem in Databricks with Big Data workloads (multiple TBs+) are the data types selected for Delta Lake schemas. Things like joining on Strings instead of Integers, for example, can have a big impact on performance. Incorrect Data Types can also lead to storage bloat.
Some things are so obvious they are just hard to see.
Lower Cluster Inactivity Shutdown timeout
I would be willing to put forth that there is many a dollar (millions) being spent on Databricks every day by Clusters not being used that just sit because someone leaves them on and doesn’t even think about turning them off after playing in a Notebook. Dare I tell you what the default timeout is on an All-Purpose cluster? Enough to curl your toes.
The next step of cost savings have to do with understanding how Notebooks development, although the easy path, might not be the best for the wallet.
Migrate Workloads to Job Clusters
This is again, yet another obvious one. Don’t run Production Workloads on Notebooks tied to All-Purpose compute. Just not a good idea unless you really enjoy literally burning money. Move to a better Development cycle, use Jobs.
Reduce data size for Notebook R&D
Closely related to the prior discussion on Notebooks, while great for R&D, if you have a Data Science team or Analysts who seem only to be able to use a Notebook to do EVERYTHING … then coach them on proper development … aka start small and work up.
If someone is testing an idea or doing analysis code. Tell them to start with a few thousand rows. You don’t need 3TBs of data to test an idea and some code.
Replace Notebook Development with Local Development
Again, since we just talked about this, a quick way to save real money is to ensure all Engineers (and Non-Engineers where possible) are using a correct Development lifecycle. That means building Data Pipelines on Databricks can and should start in a local IDE with Unit Tests etc. Only once the first pass is done should Development move into live environments.
If you have a whole team of Engineers, Scientists, and Analysts … this will add up to real money if they are all using Notebooks + All Purpose compute to do ALL development.
Move to Fleet Clusters
Another great new feature on Databricks and AWS that no one talks about is the use of Fleet Clusters. “Databricks fleet clusters enable customers to launch clusters using EC2 Spot instances while adopting EC2 Spot best practices by using diversified node types.” This is a no-brainer to save compute.
Reduce Cluster Disk Sizes
Anytime you are setting up Spark Clusters you can get caught in the same old hum-drum and not put your thinking cap on. Do you really need 1TB of storage attached to all your Spark Nodes? Probably not. Think about it.
SPOT with Fallback for Clusters
Here is one that sneaks by most people. SPOT vs On-Demand can make a big impact. Set your Driver node to be Spot with Fallback and Spot for the rest. Or at least play with it. Use as many SPOT instances as you can get away with.
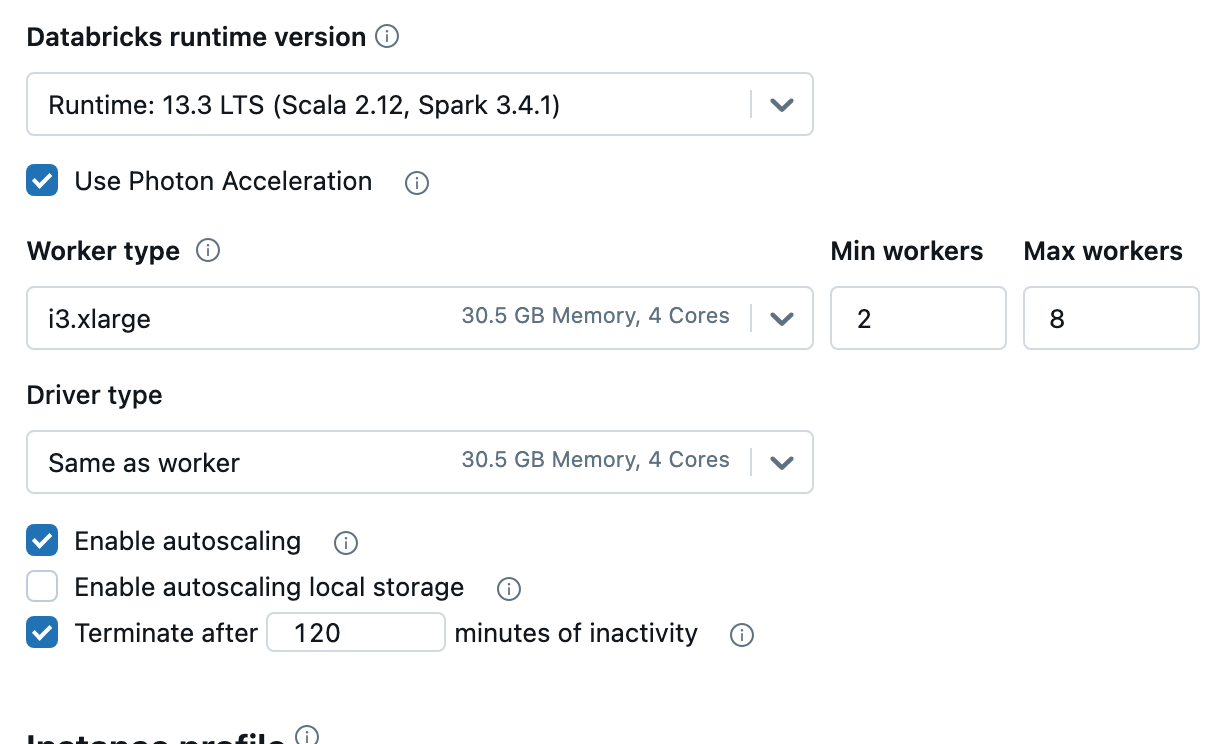
Autoscaling Clusters
If you aren’t sure what kinda of resources you will be using on some new Job(s), make sure to use Auto-Scaling clusters and set your minimum and max workers accordingly … aka set your min number of workers pretty low at the start.
I could probably keep going but that should keep anyone busy for a little bit at least. Note, there is no rocket science buried in here anywhere, it’s mostly about paying attention to detail and ensuring best practices are followed.
It’s easy on a beautiful platform like Databricks to get enamored and start pumping out pipelines left and right, which is all find and dandy but take the time to think about things first, you can probably make a real dent in your bill simply by following good practices.
Rarely is there a silver bullet that will cut your costs in half, unless you really doing some terrible things in the beginning … cost savings don’t have to be some big complex problem, something new rocket juice thingymabob to save you.
Before you throw your hands up in the air and say “I don’t know,” go through that above list. Focus on the basics, that’s where most Data Platforms go off the rails … right from the start.
Two-hour Cluster Timeout/Shutdowns? Easy fix. Everyone running their own giant All-Purpose cluster? Easy, tell everyone to share like in kindergarten.
These are solid tips.
A few more:
Use single node clusters where spark is not being used or for smaller workloads.
Also, use Databricks jobs for multistage jobs and share the cluster across the tasks/notebooks. Job will finish faster and you won’t pay for the startup time.
In Azure, VM reservations can also reduce cost significantly for regular workloads.