

Data Deduplication for Dummies
you dummy


Hey dummy! Why did you get duplicates, you dummy?! What’s the matter with you??
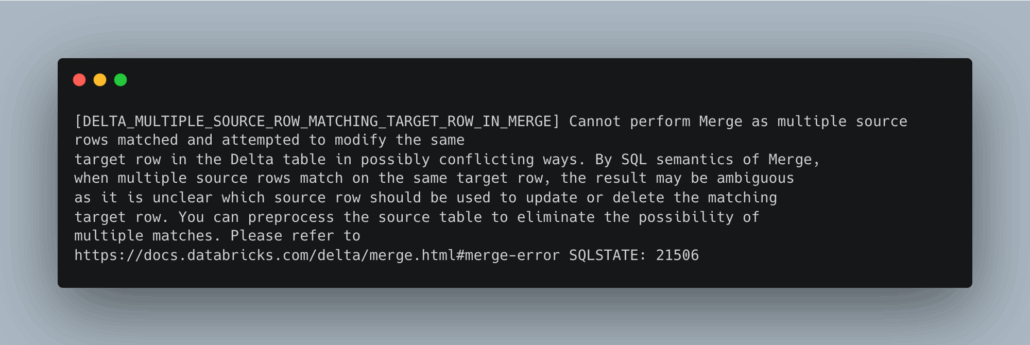
You know, after literally multiple decades in the data space, writing code and SQL, at some point along that arduous journey, one might think this problem would be solved by me, or the tooling ... yet alas, not to be.
Regardless of the industry or tools used, such as Pandas, Spark, or Postgres, duplicates are a common issue in pipelines, and SQL remains the most classic and iconic problem. Things just never change, and humans never learn their lessons, at least I don't.
