

Databricks Lakeflow vs Apache Airflow
an honest take


Every day I go out and do the Lord’s work for y’all. On an average evening or weekend, you can find me setting up cloud instances, generating data, deploying code, and running tests. I don’t answer to anyone. I write what I please and what I find. The simple approach: poke things, turn over rocks, ruffle the feathers of many powerful people.
Ain’t nothing better, my friend.
The world is full of wonderful data products and smart people, me, just an average engineer, giving an opinion and perspective to help enlighten you and bring knowledge, shining a light on the good and the bad.
Today, I want to discuss something that is probably close to some folks’ hearts. Databricks Lakeflow Jobs vs Apache Airflow for data pipeline orchestration.
This isn’t the first time I’ve written on the subject; I did it maybe 6 months ago, roughly. But, I’ve been wanting to return to this recently because there’s been a clear push from some Databricks voices that, more or less, you’re a dummy if you’re using Airflow to run Databricks Workloads.

Of course, we can be honest with each other, you and me, that pretty much everyone who talks about this subject has some axe to grind and money on the line.
That’s ok, it’s the world we live in, right?

But all the noise can make it hard for the average fella to really know what we should do. Databricks is the GOAT of Data Platforms, no question about it. It’s clear they are the winners and can build incredible products.
Is Lakeflow one of them? Should you abandon that pillar of data orchestration, Apache Airflow?
I simply do not know the answer to that question; I doubt you do either. It’s complicated, it depends, like your mother used to say. If you’ve been around tech for any length of time, you know that the right choice for someone might be flipped 180 degrees for someone else.
Context matters.
We should try to Steel-Man both sides of this argument, if you will, look at the pros and cons of each approach, remind ourselves of the fundamentals, and hopefully come out the other side with a clear picture, at least clearer than when we started.
Starting from the top.
Ok, we have to start somewhere, so let’s just jump in. Clearly, Apache Airflow is the 800lb gorilla in the room. It’s the one everyone is always lobbing grenades at, for good reason.
According to a very scientific poll I conducted, when reviewing the orchestration landscape, Airflow accounts for the vast majority of market share.

So, let’s just list two important and obvious facts.
Airflow is the orchestrator to beat.
Databricks wants you on their data platform (end-to-end)
That doesn’t make Databricks Lakeflow the “bad guy” of this discussion, far from it. In fact, Databricks is just doing what it's always done … providing top-notch products to its users, making it the leader in Data and AI.
If Databricks didn't provide a rock-solid orchestration tool, we would probably wonder what the matter with them was.
We also have to state a few other obvious points.
There is a wide range of data team sizes
There is a small subset that runs at a massive scale.
One could argue about how many data pipelines are running in Production and how this fits into the overall discussion of Airflow vs. Lakeflow. Does the number of pipelines you have running matter?
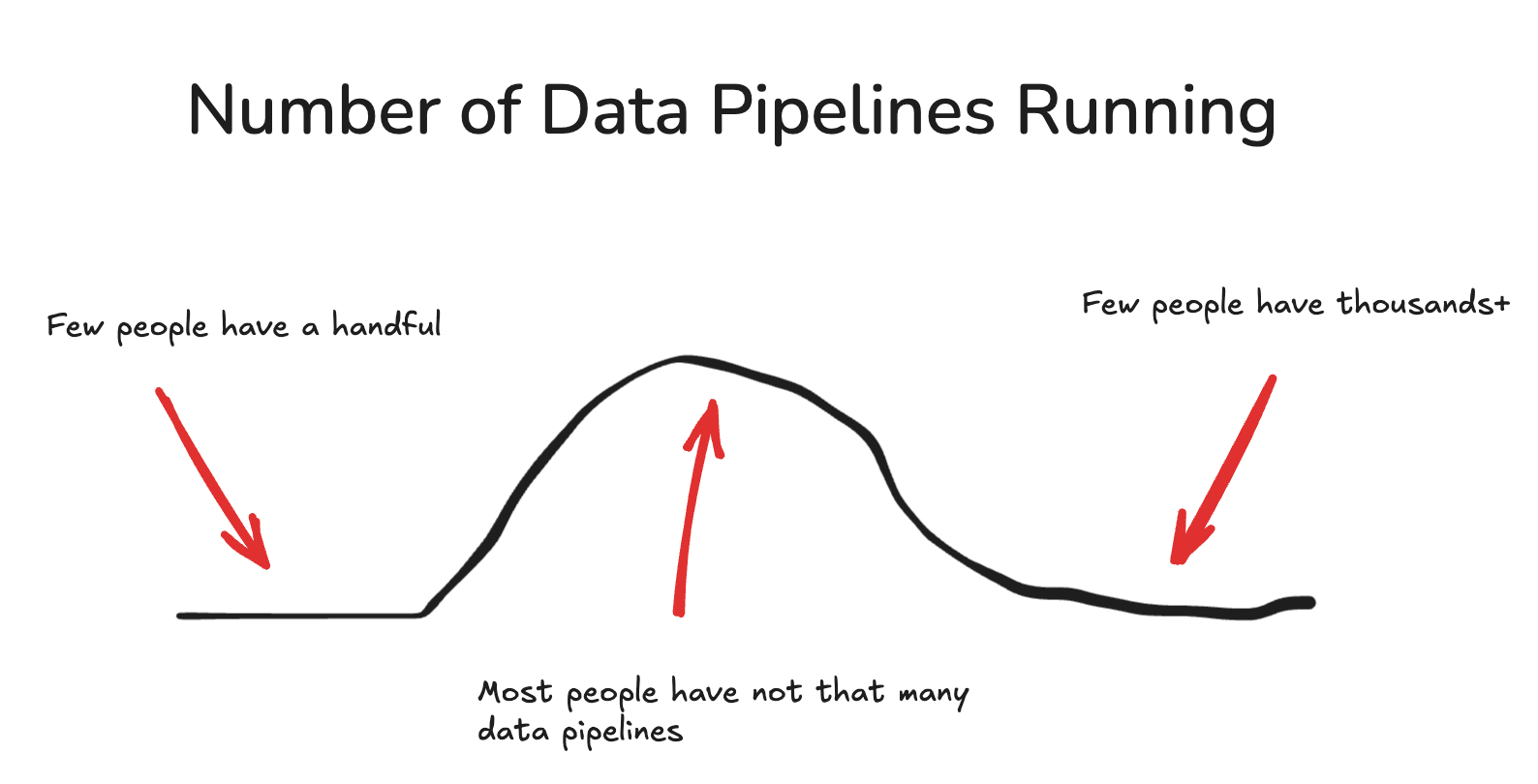
An Apache Airflow survey from 2022, which isn’t that long ago, indicates that 75% of Airflow users have 250 or fewer DAGs running. This is pretty much what common sense would tell us.

While you might think it matters how many data pipelines you are dealing with, on the surface, because both Airflow and Lakeflow can “do the same things,” you might be missing something important.
As Engineers and data practitioners, we sometimes leave the obvious things lying on the floor while we examine the minute technical details and the shiny ones. We miss what’s right in front of our faces.
This will be my first strike against Lakeflow (as compared to Airflow).
Like it or not, our orchestration tool of choice gives everyone, including sometimes non-technical folk like CTOs, a first-pass glance at the health of the data pipelines.
Here is a screenshot from Databricks, on their own page about Monitoring and Observability for Lakeflow.

And here is a screenshot from the average Apache Airflow UI. Airflow has made significant strides in recent releases to improve its UI.


It’s a master class in understanding the pipeline and data platform state at a glance. To be fair, they’ve had a long time and a lot of users to tell them what to do and what not to do. And it shows.
Heck, even the “old” Airflow UI at a glance gives someone “the lay of the land” better than Databricks Lakeflow.
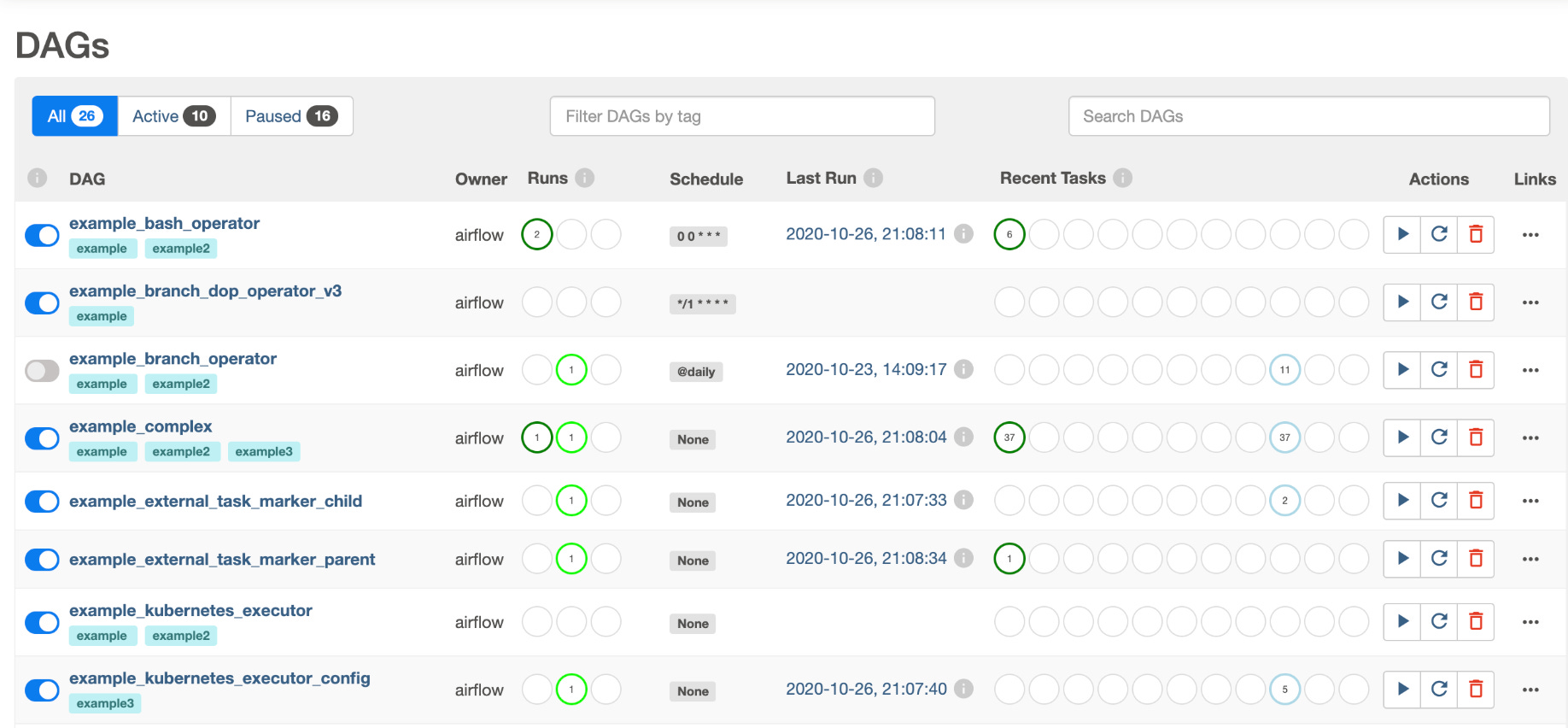
One could argue all day about semantics, who likes what UI better, this, that, whatever … beauty is in the eye of the beholder. Either way, whatever UI you prefer, remember that for the average Data Team, the orchestration UI is their gateway into the Data Pipelines as a whole and individually.
Humans are visual creatures.
Slicing and dicing what’s happening overall, when things are going bump in the night, is extremely important. We don’t want to dig, guess, search, or wonder in the back of your mind if all is well. You want to SEE with your own two buggly eyes that all is well.
When you are choosing between Airflow and Lakeflow, make sure that you stop and smell the roses, which one from a UI perspective fits you and your data team better? What would you want to use everyday, what would make you frustrated?
What are we orchestrating?
The next question that we should ask ourselves, but again gets left dusty in the corner in a classic manner, is the WHAT part of data pipeline orchestration. “What, exactly, are we doing in all those pipelines.
What does this matter?
Well, one could argue that this answer is the most important part of the entire equation when evaluating Apache Airflow vs Databricks Lakeflow. If we pick the wrong (but nice) tool for the job, we’ve done no one a favor.
Apache Airflow was made to do EVERYTHING.
Lakeflow was built for Databricks, but recently started supporting External “stuff.”
We don’t need to really cover Airflow Operators and the plethora of options for chaining different services, from every source under the sun, into a single data pipeline. This is why Airflow is the OG of orchestration: you can simply stitch anything and everything together.
The Apache Airflow 2024 survey shows that you can use any Cloud with Airflow.

The truth is, most Data Teams operate in a Cloud environment where data and tools are spread across multiple systems. Even if you find yourself in the rare instance of using only AWS, GCP, or Azure, chances are you need to interact with multiple services as part of your data platform.
That’s just life.
We need data orchestration tools that treat ALL external systems as first class systems.
Let’s look, as best we can, at a high level at how Databricks Lakeflow can solve this “external problem.” If they want us to use it, it must be flexible and usable in real life.

The CEO of Databricks recently called out “External Orchestration” and mentioned non-Databricks options like EC2 or “scripts.” Ok, let’s put that to the test. If they say it, I’m going to hold their feet to the fire and make them prove it.
What happens if we Google “Databricks Lakeflow External Orchestration”? Truth is, I get a whole lotta nothing. I mean we do get a link to this bold claim and spicy blog post from Databricks.

None of the links show any documentation of examples of how to do this, External Orchestration, nothing. How’s a bruv supposed to do it if no one shows me the way of truth? Gotta throw a data engineer some bones here and there.
It took me some digging, but finally I found it. External calls via API/script tasks.

The only problem is that it’s nearly impossible to find or search for ANYTHING related to this type of External task use. I mean, the CEO said we could orchestrate EC2 instances for crying out loud. Why can I not find any documentation or examples of this?

Interestingly enough, on Reddit, we can find people asking about general orchestration in Lakeflow (Databricks), often compared to Airflow.
Basically, the official response from Databricks is: write some Python in a Notebook or file and just use it in a Task. I’m guessing this is NOT what people want.

I mean, the point is taken, we can just write whatever Python file we want and loop it into a Job as a Task and run it in our Lakeflow orchestration. The problem is, people are lazy.
To be honest with you, and I’m always honest, what bothers me the most is that we have the highest of the highest person at Databricks telling us we can do all sorts of External stuff in Lakeflow … but it’s basically impossible to find out how, it’s almost as if the truth is hidden.
One would have to assume the scripts they are talking about are Python script tasks for jobs.

The only other thing I can guess at is that Lakeflow Connect might be some of what is being discussed and referred to? It’s hard to divine the different nomenclature between the tools, and it’s hard to know where Lakeflow as an orchestrator stops, and Jobs and ETL Pipelines in Databricks pick up.

And I suppose this is the point after all: Databricks is a single-source-of-truth Data Platform where all components are tightly coupled and integrated. So it makes sense we have a hard time separating what is what.
This ingestion doc for Lakeflow Connect indicates some common connectors (external) …
Cloud Storage
SFTP Servers
Kafka
Kenesis
Pub/Sub
Pulsar
Impressive but far from all-encompassing. The quote from the CEO mentioned Snowflake and EC2 instances. I haven't seen that in the documentation yet, and I’m looking. Am I just missing something obvious?
Maybe the Snowflake reference was just to the Lakehouse Federation and to the ability to run queries on Snowflake data in Databricks.
How does this all work into a single data pipeline at the end of the day? I have no idea. Many data pipelines touch multiple services and do many things, not just run Spark jobs … can it truly be stitched together in what we call Lakeflow inside a single Job?
Probably, if you make use of Python Scripts and tasks, but as for the plug-and-play connectors for everything under the sun, like Airflow, with all the work done, just an import required in a DAG … it does not appear to be a thing in Lakeflow.
I’m not saying one approach is better than another; it depends on your use case, you decide.
But you should know upfront, eh?
Databricks has clearly, and maybe intentionally, blurred the lines between the classic orchestration tool and orchestration + actual jobs.
For example, how do you alert on problems with Databricks Lakeflow? You can find references to email alerts for pipelines, kinda as an afterthought.

It appears alerting is more of a concept on a Job. Where you can configure Slack alerts, etc, etc. More fine-grained at the Job level, rather than at the orchestration level.
I don’t know what is right and what is wrong, it’s just different, you know? I’m not here to say one is better than the other; they are just different tools. I’m simply writing theoretically about Apache Airflow and Databricks Lakeflow as orchestration tools and how they approach things … many times the same, many times differently.
Databricks is doing to orchestration and Airflow what they did to OLTP and Postgres. They are reimagining the entire thought process and architecture, and breaking down barriers. They are saying, “You don’t need separate architecture boundaries and boxes for data pipelines and orchestration … they should be one and the same. Ala Lakebase.
On to the next topic.
The case for Lakeflow as an orchestration tool.
Now, this might surprise you after all that, but I’m just going to come out and say it. I think you should use Lakeflow for pipeline orchestration whenever possible. Let me make the case to you and give you fair warnings, which I've laid out above in a roundabout way if you’re paying attention.
I’m going to give you the list of reasons that are very important reasons to use Lakeflow instead of Apache Airflow in many instances.
Architecture complexity reduction
Major cost reductions
Code simplicity
Platform integration
No upgrades or migrations necessary
Paradigm shift from schedule-driven to data/event-driven
Governance is first-class and built in
Of course, this only makes sense if you are already using the “Databricks” platform for the majority of your workloads; it wouldn’t otherwise.
What I listed above is not just some fly-by-night wish in the sky list. It’s real and has major impacts on the bottom line and the everyday workflows of the entire Data Platform.
Running and paying for Apache Airflow, either yourself … which is stupid because of the overhead and maintenance, or via a Saas vendor … Astronomer, MWAA, Composer … is NOT CHEAP!
There is an entire industry built around collecting money by providing orchestration-as-a-service.

That means a lot of money is involved; running Airflow ain’t free, bruv. Databricks says… we won’t charge you a dime, more or less … at the very least, it’s a fraction of the cost of managed orchestrators. Let alone even thinking about “managing” the managed service. Which is a thing, FYI.
This brings me to architectural reduction.
I can’t believe I even have to bring it up, but some of y’all forget the real world, maybe because someone else does everything for you, who knows, but even SaaS Apache Airflow comes with its headaches.
Upgrades, complexity, migrations, just another system that can go bump in the night.
The more boxes we put into your architectural diagrams, the more problems we have. The interaction between systems always breeds problems of some sort, risks, we could say.
Lakeflow being inside and virtually indistinguishable from Jobs, Pipelines, and Databricks itself is something. A big something.
Of course, we haven’t really gotten into using Lakeflow on Databricks at a technical level, but I can assure you it is markedly different from Airflow in subtle ways. Lakeflow is just an extension of Jobs, which are deeply integrated with every other part of Databricks … things like Lakehouse tables, governance, etc.
That comes with obvious benefits.
Databricks, with eternal foresight, much like Lakebase and Postgres, saw orchestration as a separate, and very large, box ripe for the picking. Indeed, such a “heavy” view of orchestration is a relic of the past. Bound to be redone at somepoint.
Unification, I say, has been there right before your eyes for some time.

Time to embrace the future.
Great article! Funny how "external orchestration" always boils down to someone writing a notebook in python to handle auth, errors, triggering, polling, gathering metadata, alerts.... it is a wonder we don't see more python orientated services also claiming to be external orchestrators!
Lakeflow is still missing many essential features. It lacks basic orchestration capabilities such as global workflow timeouts, task prioritization, and the ability to control or assign job pools. In addition, monitoring is very limited—there is no reliable way to track real-time workflow execution status because Databricks does not provide real-time logging for Lakeflow workflows.