

Databricks Workflows vs Apache Airflow
... or both?

I’m such a cheerful guy, I figured I would try to write a positive and inspiring post while comparing two tools. Just kidding. I guess we will see how it goes. Who knows, we'll just see where it leads us, I suppose.
There are very few areas where technology battles are still being played out, such as orchestration tools. With the recent infamous Astronomer happenings, Apache Airflow has been back in the conversation again.
As recently as this spring, I wrote an honest review of the data orchestration landscape.

What sparked this post comparing Apache Airflow and Databricks Workflows was something my Databricks Account Manager told my boss. Something to the effect of “You should replace your Apache Airflow with Workflows, trust me, it will be great.”
There have been a few times I wanted to reach across the digital landscape and throw a bit or byte into someone’s eye, but that was one of them.
Instead of making you read to the end to give you the TDLR, I’m going to say it up front.
I use BOTH Apache Airflow and Databricks Workflow in production today. These tools complement each other and are not mutually exclusive. Picking one over the other is a bad decision; using them both, in combination, gives you the best of both worlds.There you have it.
Thanks to Delta for sponsoring this newsletter! I personally use Delta Lake on a daily basis, and I believe this technology represents the future of Data Engineering. Content like this would not be possible without their support. Check out their website below.

Apache Airflow vs Databricks Workflows.
Before we dive too deeply into these orchestration tools, let’s take a look at what I think is an obvious aspect of data orchestration: the what and why.
If we were to consider the top reasons for using an orchestration tool, or, in other words, what features do we look for in those tools, this might help us evaluate both Apache Airflow and Databricks Workflows.
data flow visualization
complex task dependency support
basic retry support
top-notch error monitoring and handling
top-tier and broad connections and integrations
straightforward development
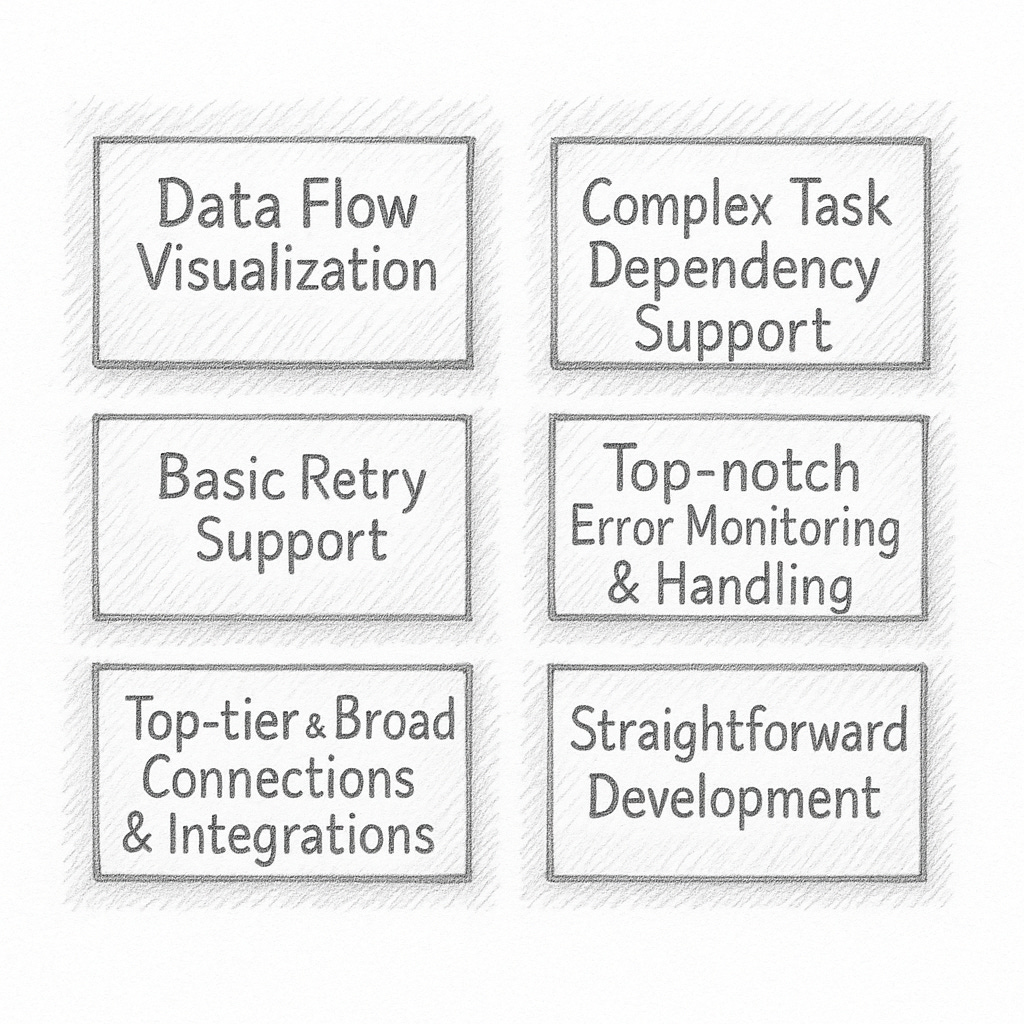
We could go on to list 1,000 things, but let’s try to keep it straightforward and simple. If a person can check off the above items, regardless of the tool, it’s most likely that things will work out well.
Data Flow Visualization
I’m not sure we really need to discuss data visualization with Apache Airflow, but, for the sake of argument and in the off-chance we have some small, little data hobbits, let’s just go through the motions. This will make it easier to compare to Databricks Workflows anyway.
setting things up.
To get started, and if you'd like to follow along, I suggest installing the Astro CLI. This little beauty makes creating and running Airflow locally a breeze.

Run these few commands, and you are on your way to glory.
Once you have done that, you will get a localhost Airflow that should pop up automatically in your browser; otherwise, localhost:8080 should do the job.
So, at this point, let’s just write an example DAG and workflow that we will end up creating in Databricks Workflows as well. What the pipeline does itself isn’t that important, as much as what it is like to write it, and how it looks.
Here is our example Airflow DAG.
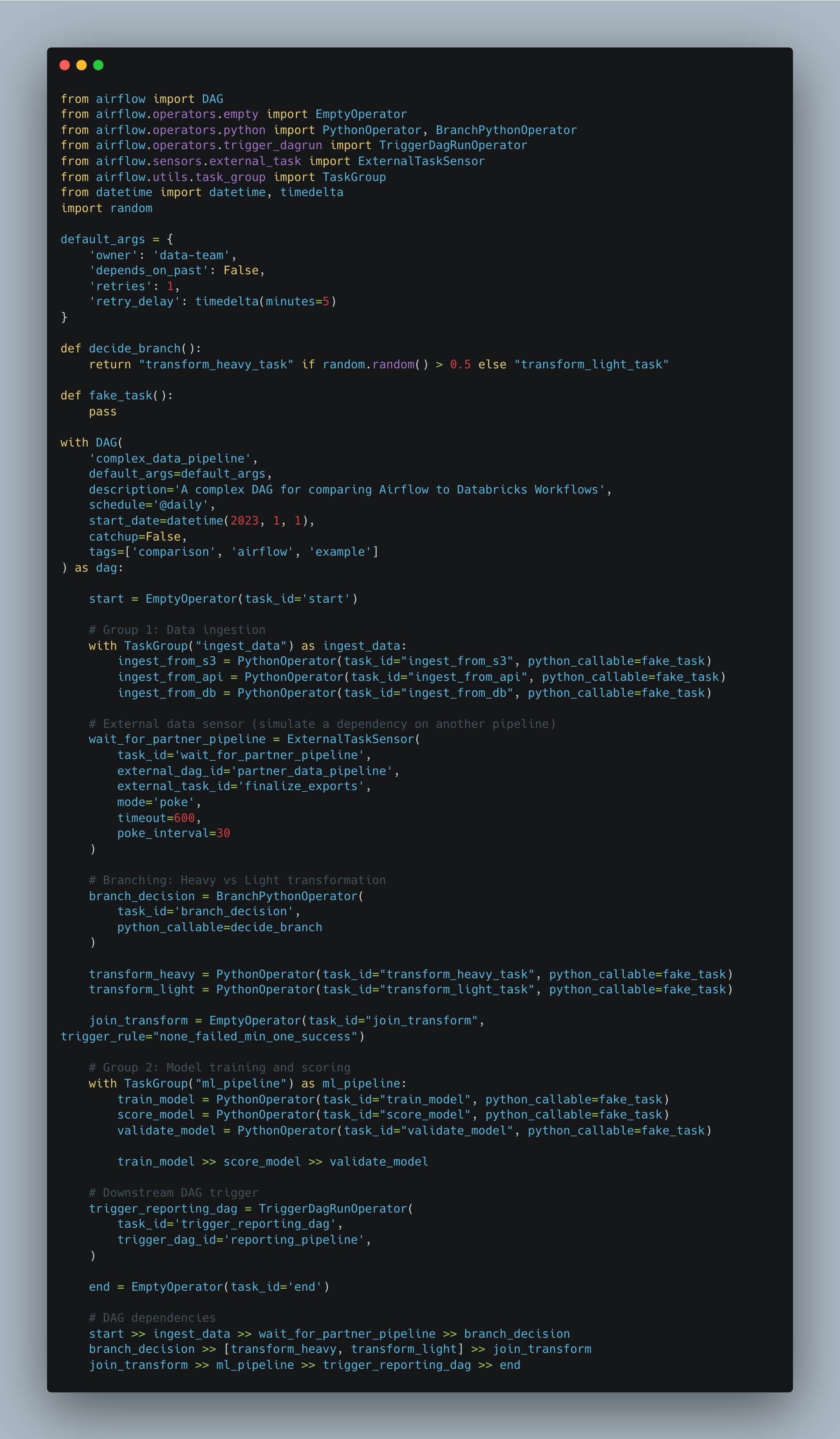
So, here is a summary of what is happening in this example workflow.
Start
- Dummy entry point
Data Ingestion (ingest_data Task Group)
- ingest_from_s3: Pull from S3
- ingest_from_api: Fetch from API
- ingest_from_db: Extract from database
External Dependency
- wait_for_partner_pipeline: Waits on external DAG/task
Conditional Transformation
- branch_decision: Randomly selects:
- transform_heavy_task: Intensive processing
- transform_light_task: Lightweight processing
- join_transform: Merges transformation paths
ML Workflow (ml_pipeline Task Group)
- train_model: Train model
- score_model: Generate predictions
- validate_model: Evaluate model performance
Downstream Trigger
- trigger_reporting_dag: Kicks off another DAG
End
- Dummy terminal taskFor what we are discussing now, we need to look at in the UI to see visually how it shows up. So in our command line, inside our astro projects, we would `cd dags`, and place this example DAG there.
If you have problems with the DAG showing up in the UI, run the following …
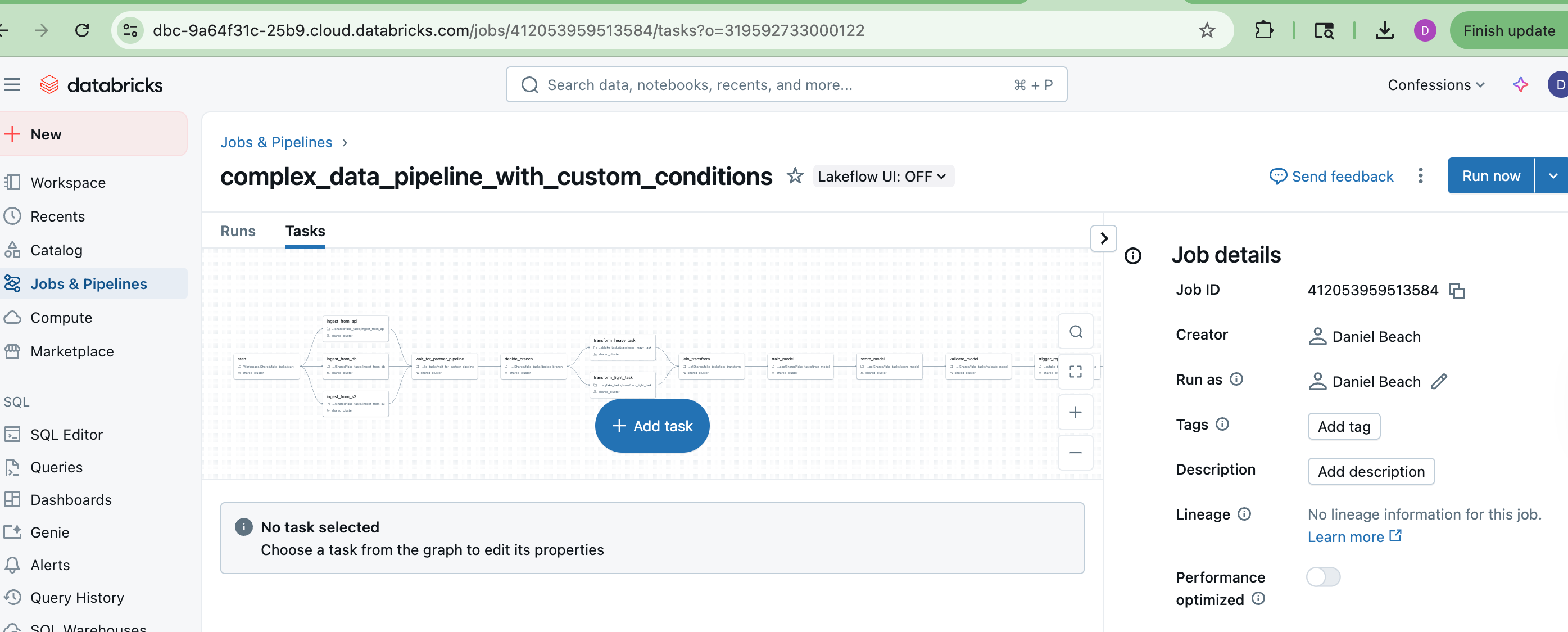
astro dev restartBelow we can see our pipeline in the Airflow UI.
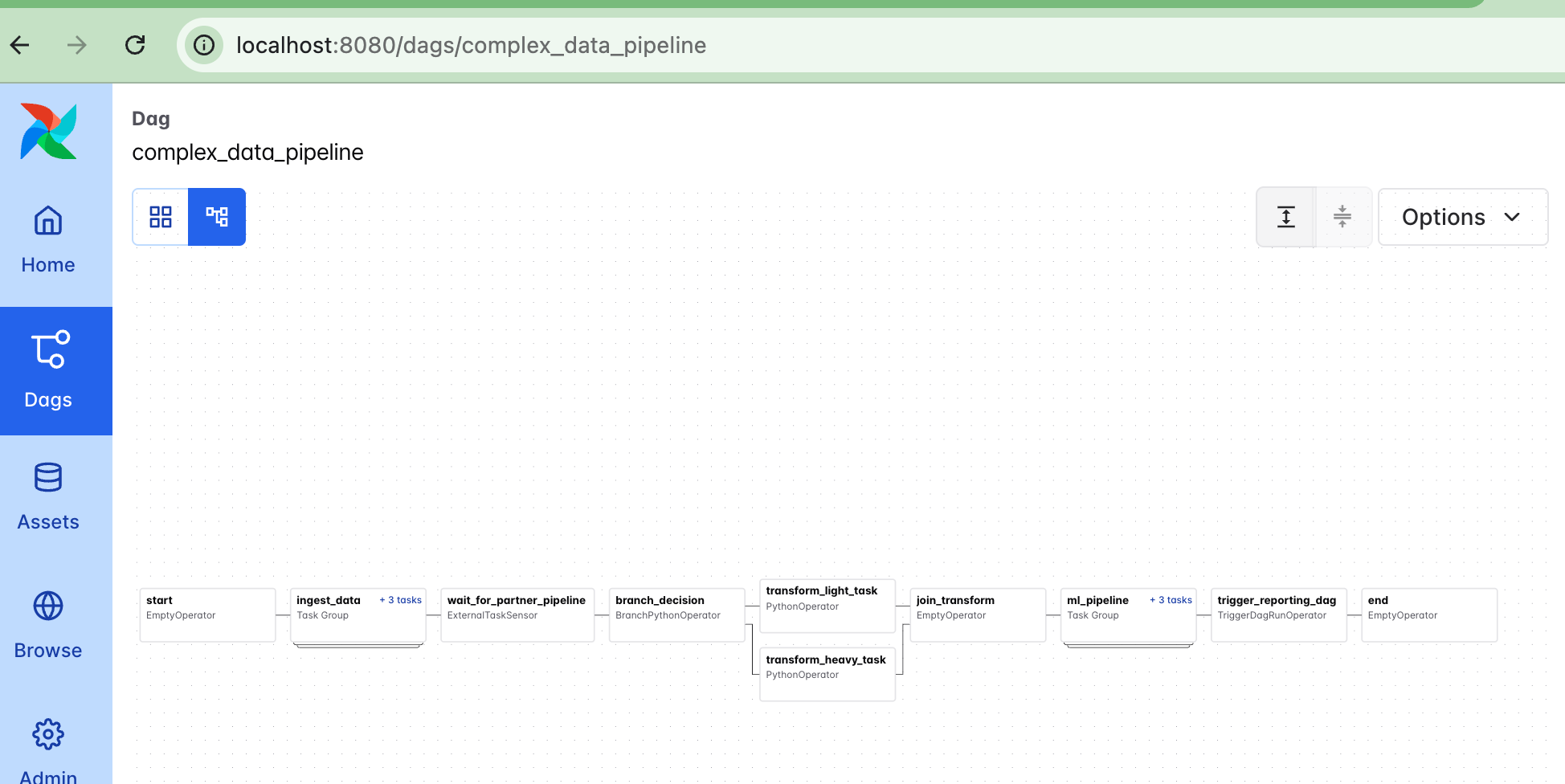
And of course, Airflow provides a plethora of other information readily about runs, failed or not. In other words, Apache Airflow has tier-1 level support for visualization.
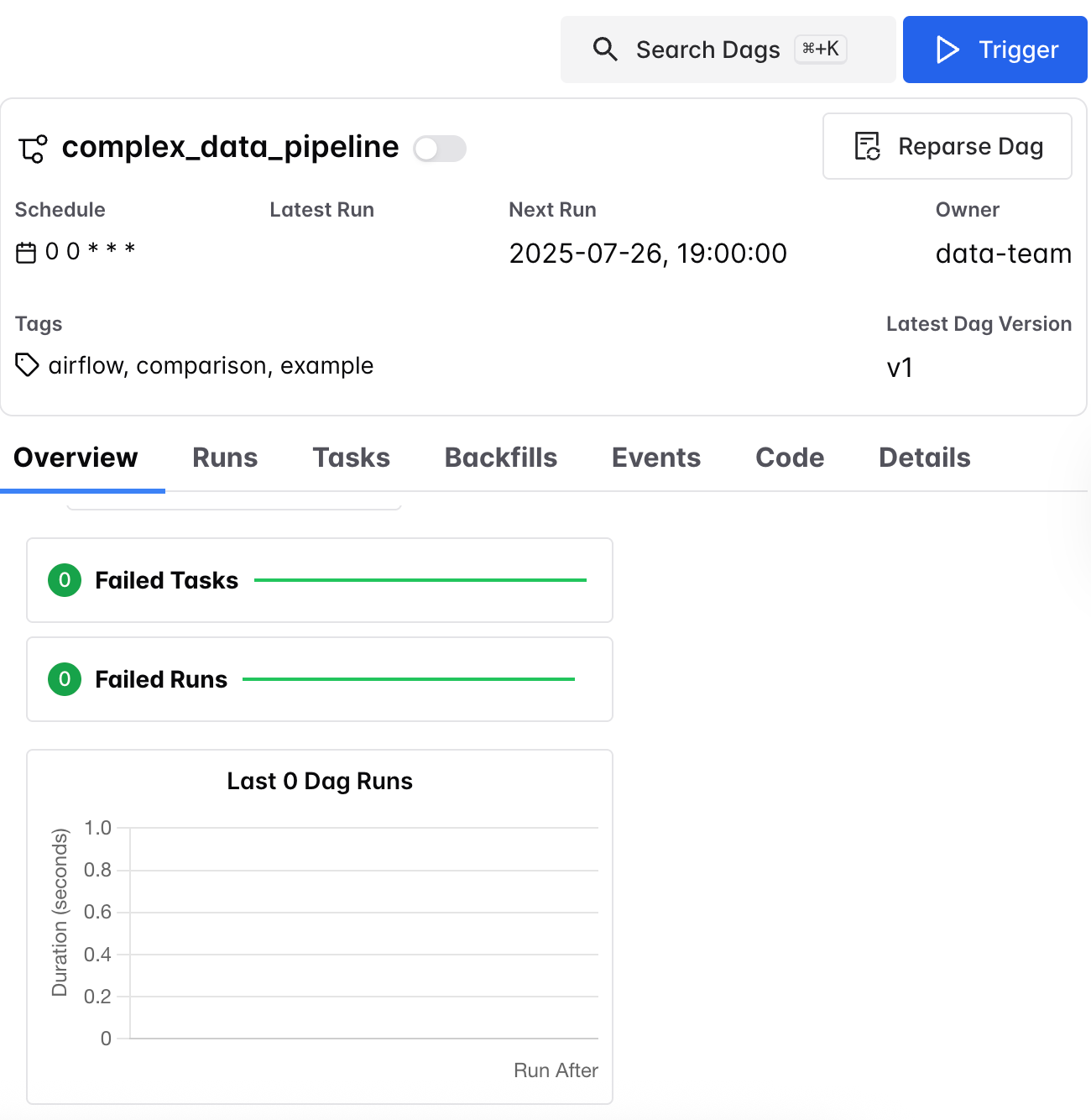
Sure, some people might argue that tier-1 level, but whatever. The truth is a lot of people use Apache Airflow every day, and while sometimes it leaves some things to be desired, it’s easy to move around the UI, click on a pipeline, see what has failed or not, and visually inspect WHAT a pipeline does.
Of course, some of this is dependent on the person writing the DAG not being a ninny.
Databricks Workflows visualization.
Ok, so while everything is fresh from our Airflow DAG and what this pipeline looks like. Let’s build on in Databricks Workflows and see what gives.
Now, I’m not going to lie, better hold your breath for this one. Look, I can say confidently I’m a bigger Databricks fan than you, big time, but this kinda stuff makes my toes curl.
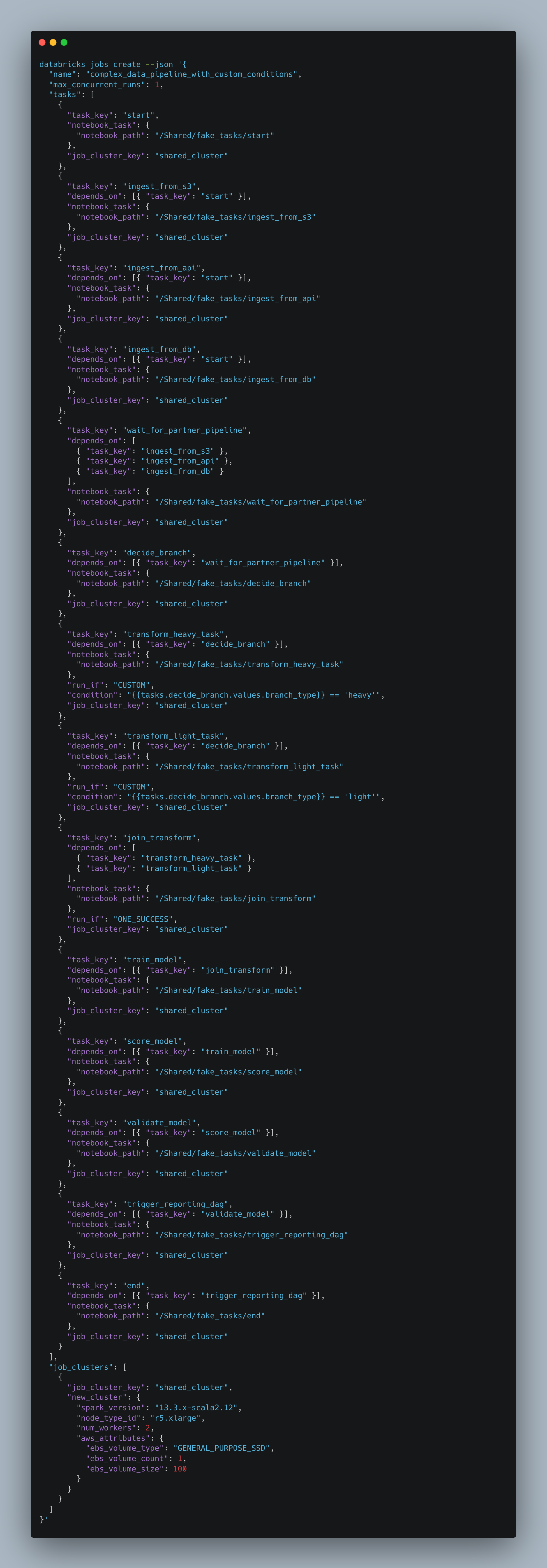
I mean visually, there is really not that much difference between the two. Other than the fact that Apache Airflow has been around WAY longer than Databricks Workflows, and therefore the fine details are always going tip in the favor of Airflow.
I do want to make some other comments while these code examples, and visuals are fresh in our minds.
First, it might be my opinion, but Databricks Workflows kinda suck to write. Not the worst, but not the best. They simply don’t flow off the finger tips like an Airflow DAG does.
Heck, even looking at the JSON used to define them visually just looks like a giant jumble of … JSON.
Second, beauty is in the eye of beholder, that’s why your significant other is with you right? I mean just like us, Databricks Workflows and Apache Airflow are going to have their visual UI “things” that either attract or repel people.
That’s ok.
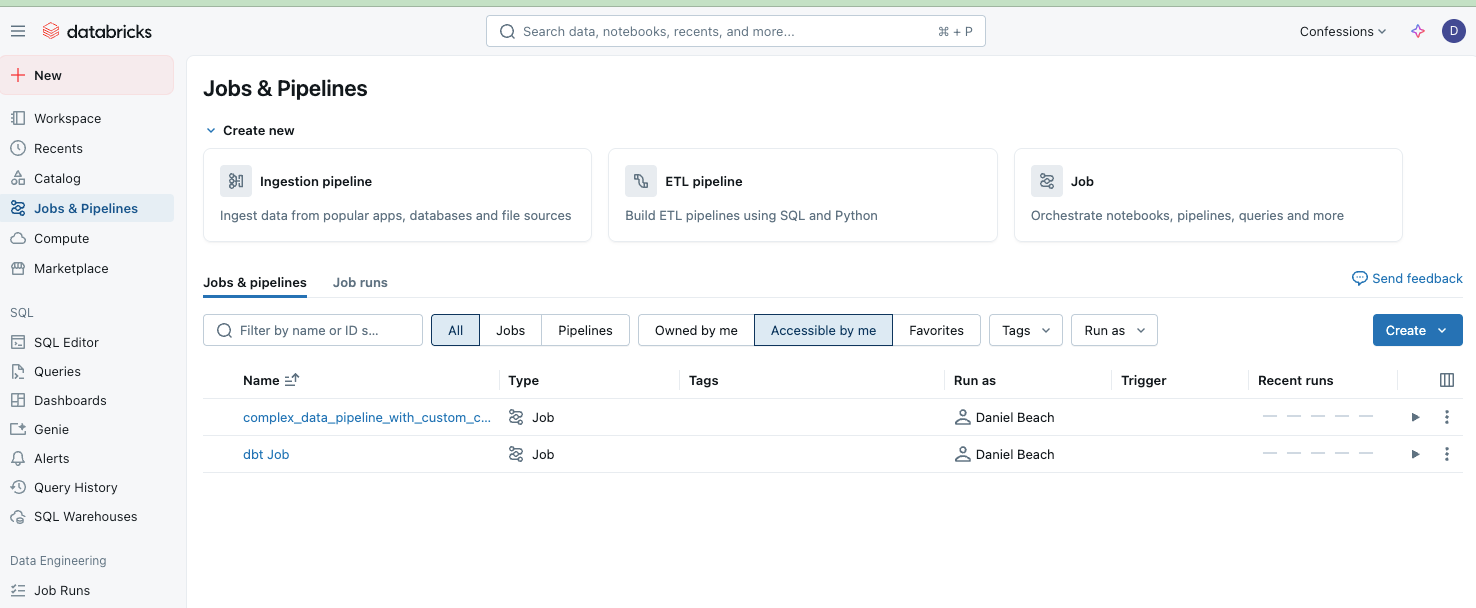
I mean look at the home UI for both Airflow and Workflows. They are similar, and again, besides little things, who’s to say one is better than the other. It’s preference.
Anywho, let’s move on.
Complex Task Dependency Support.
I’m just going to get straight to the point here. Most common Production like scenarios and pipelines in real life will have a number of oddities and complexities that won’t fit the easy and perfect mold all the time.
When it comes to choosing an orchestration tool, we don’t want to have to fight it when it comes to defining things that are simple like conditional logic and branching.
The truth is that even in the simple example I used, I had to move from `if-else` nested logic to Notebooks … simply because Databricks Workflows fall apart a little when things get tricky.
Before you send me angry emails … I get it. Yes, anyone given enough time and enough grit can easily “make it work,” find workarounds and solutions to any problem. Sure, you can do complex things in Databricks Workflows, but it simply won’t be as straight forward as doing that thing with Apache Airflow. Get over it.
1. Task Limits per Job
- A single Databricks job supports up to 1,000 tasks only
- For highly intricate pipelines, you may need to chain multiple jobs.
2. Simplified Conditional Logic
- Native branching (if/else) is available, but each condition task only handles a binary branch (“true” vs “false”) via the visual UI, and lacks support for more than two outcomes without nesting multiple tasks
- There's no built-in “router” task for multi-way branching—so tasks like A / B / C would require separate condition tasks or logic embedded in notebooks
3. Limited “Run If” Conditions
- Databricks offers limited run‑if options like ALL_SUCCEEDED, AT_LEAST_ONE_SUCCEEDED, CUSTOM, etc., but you can’t combine or nest them flexibly like Airflow’s branching or trigger rules
- Merging branches often requires setting run_if: ONE_SUCCESS, which can lead to skewed behavior—tasks marked “skipped” still count as success, affecting downstream flow.
4. Scheduling Constraints in Continuous Mode
- Workflows using continuous schedule mode (polling, streaming) cannot include task dependencies within the same job, unlike Airflow. Many users report frustration that you can’t build dependency chains in those cases
5. No Looping or Dynamic Task Generation via API
- While Databricks UI supports a For Each loop over static arrays, programmatic dynamic task creation or looping via REST API isn’t supported. Complex dependency graphs may require orchestrating by spawning jobs via notebook logic or API externally
6. Orchestration Granularity
- For deeply nested DAGs or highly conditional logic (many forks), you often need to break the pipeline across multiple Jobs, connecting them via trigger tasks (run_job), impacting transparency and manageability.I know Databricks Workflows is changing fast, Databricks is the GOAT and half of what I say might be already out of date, or soon be.
Retry Support with Airflow and Databricks Workflows
People never think about this, or give it the time of day it deserves, the super tier-1 support for various and complex retry support at all levels of a data pipeline mean the difference between a janky tool and one that beats your pipelines into submission.
Pipelines fail. They always will.
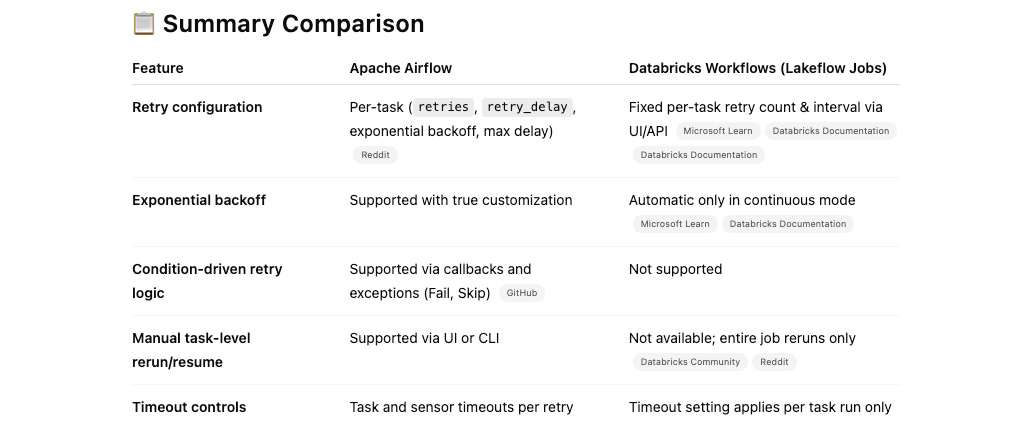
🔄 Apache Airflow: Rich and Flexible Retry Support
Per-task retry configuration: Each task can define its own
retries,retry_delay,retry_exponential_backoff, andmax_retry_delay—or you can set defaults viadefault_argsin the DAG context.Exponential backoff: Supported by enabling
retry_exponential_backoff=True, with optional bounding viamax_retry_delay.Execution and Sensor timeouts: You can set
execution_timeout, and for sensors in reschedule mode, atimeout. Retries happen on recoverable problems but don’t reset timeout windows.Custom retry logic: Use callbacks like
on_retry_callback, or raiseAirflowSkipException/AirflowFailExceptionto override retry behavior programmatically.Manual and UI rerun: The Airflow UI and CLI support clearing failed tasks to rerun them manually or backfill past DAG runs.
🔁 Databricks Workflows: Basic Retry Support Per Task
Retry policy configuration via UI/API: For each task in a Lakeflow job, you can specify a fixed number of retries and a retry interval. By default, tasks do not retry unless configured.
Continuous job mode: In continuous trigger mode, Databricks applies automatic exponential-backoff retries to tasks by default.
Single retry config per task: There’s no support for per-attempt custom delays, exponential backoff toggles, or different retry behavior for different types of failures.
No programmatic retry logic: Unlike Airflow, you cannot dynamically alter retry behavior using callbacks or exception handling within notebook code.
No manual rerun to resume: While you can re-trigger a whole job run, there is no granular UI support to resume failed tasks in-place—CLI/API reruns start entire job runs.
Again, take what I say with a grain of salt. You spend your weekend trying to figure this all out. Good luck you hobbit.
Top-tier and Broad Connections and Integrations
This is another one where I will be honest with you, Databricks Workflows is going to fall into pieces and Airflow is going to step into the light shining down from heaven.
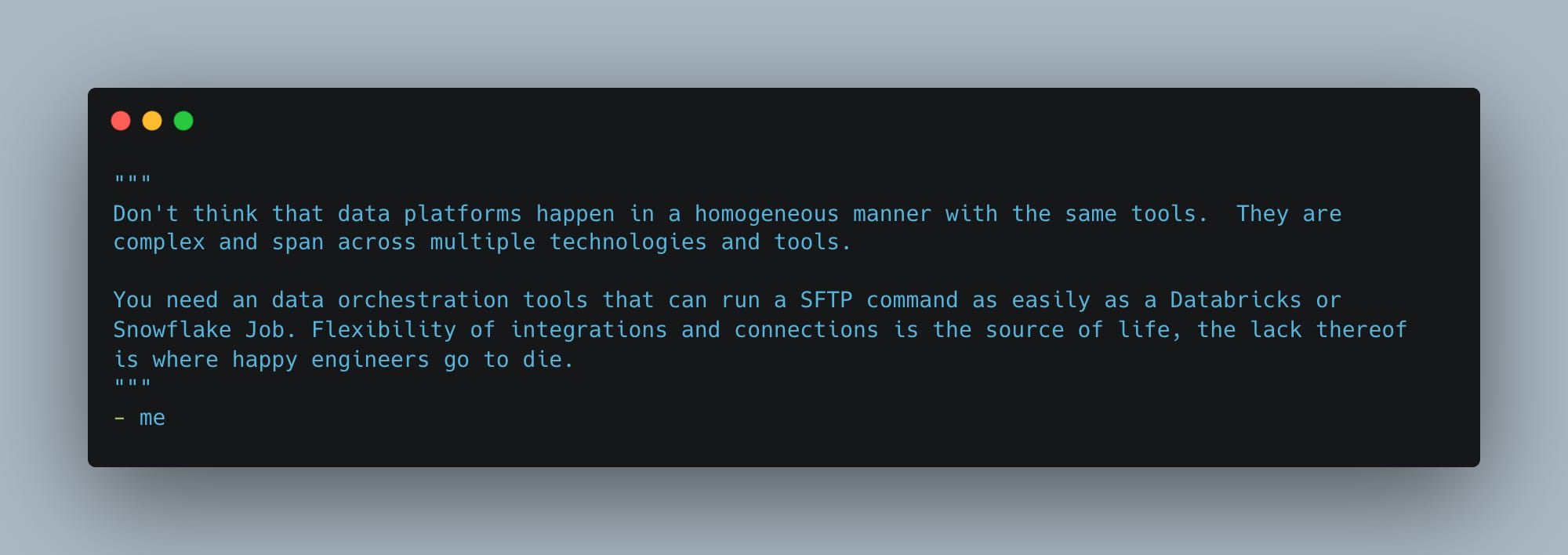
The obvious answer is that Databricks Workflows were made for and have first support for all things Databricks. Anything else? Not so much.
External System Triggers (Limited)
Webhook Triggering: You can trigger a Databricks Workflow via an external system (CI/CD, Airflow, GitHub Actions, etc.) using the Jobs API.
Job-to-Job Triggering: A task in one Databricks job can trigger another Databricks job using the
run_jobtask type.
This enables chaining, but only between Databricks jobs.
On the other hand, Apache Airflow’s ecosystem was made to bring everyone else to their knees. It’s simply unparalleled and not even comparable to Workflows.

I mean sure, you could write all the custom Python code you want and to trigger this and that, but that’s a giant waste of engineering time and is a sure sign of poor architecture and decisions on someone’s part.
Development with Apache Airflow vs Databricks Workflows
This is one area with Databricks is going to win hands down. Surprised? You shouldn’t be. Know one can lay a hand on Databricks when it comes to developer experience and the options they give you for developing things like Workflows, or anything else for that matter.
Databricks Asset Bundles (DABs) – CLI‑Friendly, CI/CD‑Ready
Smart packaging: Define notebooks, jobs, cluster configs, and parameters all in declarative YAML—bundled as a versioned unit for promotion across environments
CLI support: Use
databricks bundle init,bundle validate,bundle deploy, andbundle runvia Databricks CLI to iterate locally and promote between dev, staging, and prodGitOps-style workflows: Combine with GitHub Actions or other CI/CD tooling to manage deployments and workflows in a structured, observable manner
🧰 Other Tooling Options
Databricks CLI: Manage workspaces, jobs, clusters, secrets, and more programmatically.
Databricks REST API: Create/update jobs, trigger runs, fetch metadata—all consumable via SDKs (Python, Java) or HTTP.
SDKs and Terraform: Use official SDKs or Terraform providers for infrastructure-as-code deployments.
dbx (now deprecated): A CLI tool for local project builds and deployment; Databricks now recommends transitioning to DABs
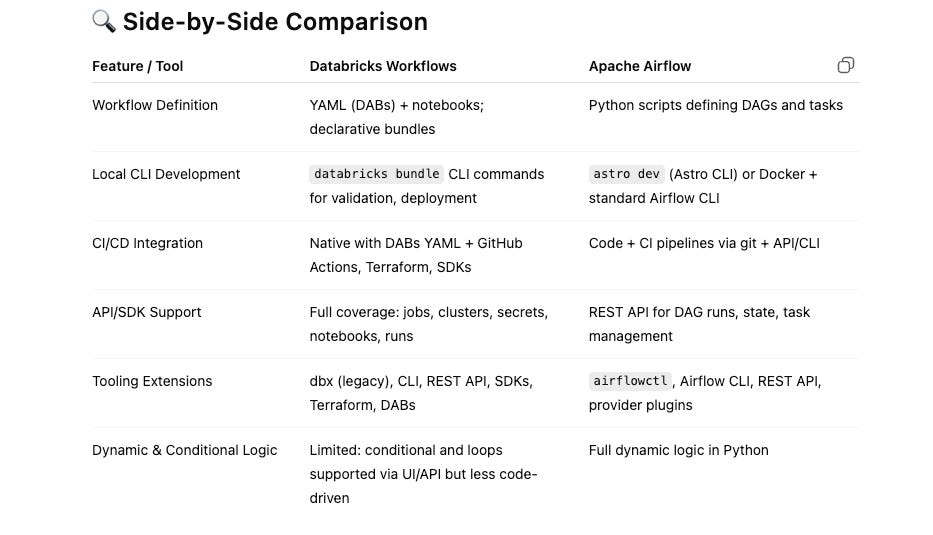
The truth is that Airflow does support some CLI stuff and does have a REST, but no one uses them and they suck for the most part. It’s simply NOT how most people use Airflow.
Databricks on the other hand has first class support for all these things AND they are widely used.
People write Python DAGs with Airflow, that’s 99% of people, like it or not.
TL;DR: Apache Airflow vs. Databricks Workflows
Use both — don’t pick one over the other. They complement each other in real-world production data platforms.
I mean, I use both Databricks Workflows and Apache Airflow DAGs in the same DAGs a lot. They are the perfect pairing, you can use Databricks Workflows to easily wrap together Databricks compute tasks, and then using other Airflow Operators, tie in numerous other OUTSIDE Databricks Tasks.
Do you really want to pay Databricks compute costs to run some Python requests hitting a REST API? That’s what you call a bad idea and waste of money.
Nice post we see the same pattern with Orchestra ontop of Databricks workflows, Data Factory, Matillion, Snowflake Tasks, dbt etc. It is crazy to me that often people think just because in theory two things do the same thing = "Have some overlap" they can only use one or the other (and not both).