

Databricks Zerobus - Event Streams + Lake House (be gone Kafka)
it's always something you know


I hadn’t thought about it much lately, but depending on your point of view, Kafka is either at the height of its rise or on a slow downward spiral. Maybe both? We do live in the age of abstraction; businesses at large seem to be less willing to pay hordes of Platform Engineers to babysit complex architecture.
But, with the rise of the Vibe Engineer, solving your streaming problems is only one god prompt away.
The (streaming) complexity is seen as chink in the old armor by many a SaaS vendor, Databricks included. That’s how the world turns. Someone sees a “problem” and says, “Hey, I can do better. Come on over here, my friend, the water is fine.”
Can you blame ‘em?
Just like Spark getting it’s heels nipped at by annoying puppies (DuckDB, Daft, Polars, etc), the streaming world has seen its share of upstarts trying to make streaming easier and less complex.
Then along came a little birdie and whispered sweet nothings into my lonely ear, something mysterious and wonderful … words like … “Databricks … Streaming … gRPC … Delta Lake.” That was enough to pique my curiosity and make me want to find out more. Some people know my weakness(es).

Thanks to Delta for sponsoring this newsletter! I use Delta Lake daily, and I believe it represents the future of Data Engineering. Content like this would not be possible without their support. Check out their website below.

I want to take a gander at Zerobus from Databricks, generally how we can think about it and compare it to streaming tech like Kafka, why it exists, and then the actual reality of trying to play with it.
What is it
How do you use it
Real-life playtime
The truth often lies somewhere in between what we believe. Once you read the documentation and try things for yourself, you may find that things aren’t what they seem, or maybe they are.
You can’t know until you put your hand to the plow.
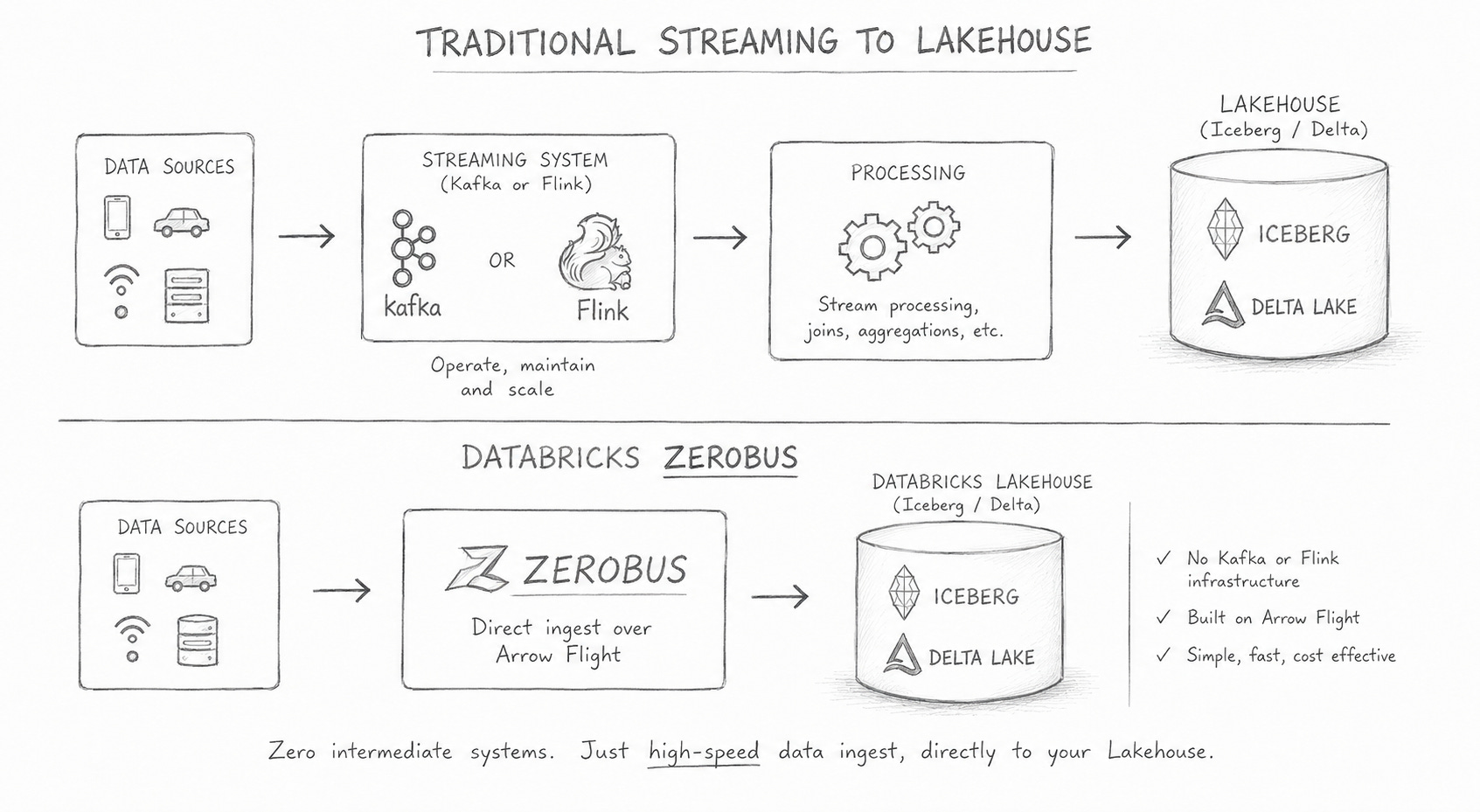
Streaming + Lake House
So, we need to have a talk about overhead and complexity. But we can also talk about the truth. Streaming and near-realtime systems are becoming increasingly mainstream in data culture. It also goes without saying that, in the current economic and business climate, not everyone is willing to overlook the costs and labor intensity of infrastructure or long-running streaming clusters.
One can argue that Kafka is going nowhere, and that is true. That’s like saying DuckDB or Polars will kill Spark. No, they are not. They just eat at the edges. This is the relationship of Zerobus to Kafka. At least for now.
The fact that Databricks probably spent an ungodly amount of time and money building Zerobus, when streaming has been around forever, and the market is full of offerings … tells you something.
LakeHouse architecture is here to stay.
It’s the data layer of choice for modern orgs
Streaming to a LakeHouse is problematic.
Zerobus makes it easy?
With all that as a way of introduction, let’s dive in.
What is Zerobus?

This is an interesting take on streaming data, eh? If you come from a world where the streaming platform is handled by a legion of engineers, or a few zealots, where most of the time is spent tuning, configuring, dealing, maintenance, upgrades, etc.
Well, then this probably sounds like black magic. One would assume, in Databricks fashion, that is the point. It’s rare the Databricks does something at %50 effort, or just does the next boring thing.
You can expect Databricks to introduce any new product or feature that tries to flip the script and become a serious contender in whatever space it enters.
No doubt there are plenty of large enterprise customers of Databricks who did nothing but complain about the complexity and brittleness of large-scale streaming into their Lake House (probably a Delta-style lakehouse).
What better way to solve streaming in the context of a Lake House than…
API interface
gRPC
REST
OpenTelemetry
Serverless
Push Only

Again, this is about the simplicity of ingesting streaming data directly into a Lake House, without the need for expensive, complex third-party tools to operate and maintain.
Yet another simplification of the Modern Data Stack.
Learn by doing.
We could spend more time pontificating about the concepts and finer details of Zerobus, but I think it would be best to select an extremely simple use case, try it out, and discuss what we see as we go.
Before we begin, we need to identify just a few pieces of information.
Our Zerobus Databricks Endpoint
Create a target Delta Lake table.
Set up Auth and permissions
Choose Client SDK and write code.
Define your endpoint.
To get our Databricks Zerobus endpoint, you only need your Workspace ID and URL. Mine is something like this …
SERVER_ENDPOINT = "https://319592733000122.zerobus.us-west-2.cloud.databricks.com" # Workspace ID
DATABRICKS_WORKSPACE_URL = "https://dbc-9a64f31c-25b9.cloud.databricks.com/" # Workspace URLEasy enough.
Define your service principal, OAuth secrets, and permissions.
Next, you will need, or should use, a service principal with secrets and proper permissions to said table. Maybe something like this delta-streaming
… OAuth Secrets and Permissions …
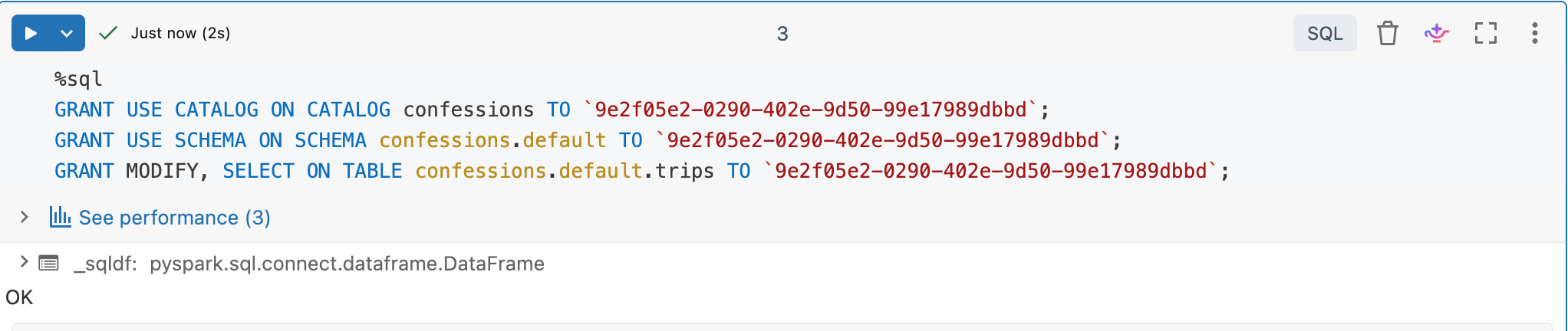
And now we have our OAuth thingys, we have everything we need to start writing the code.

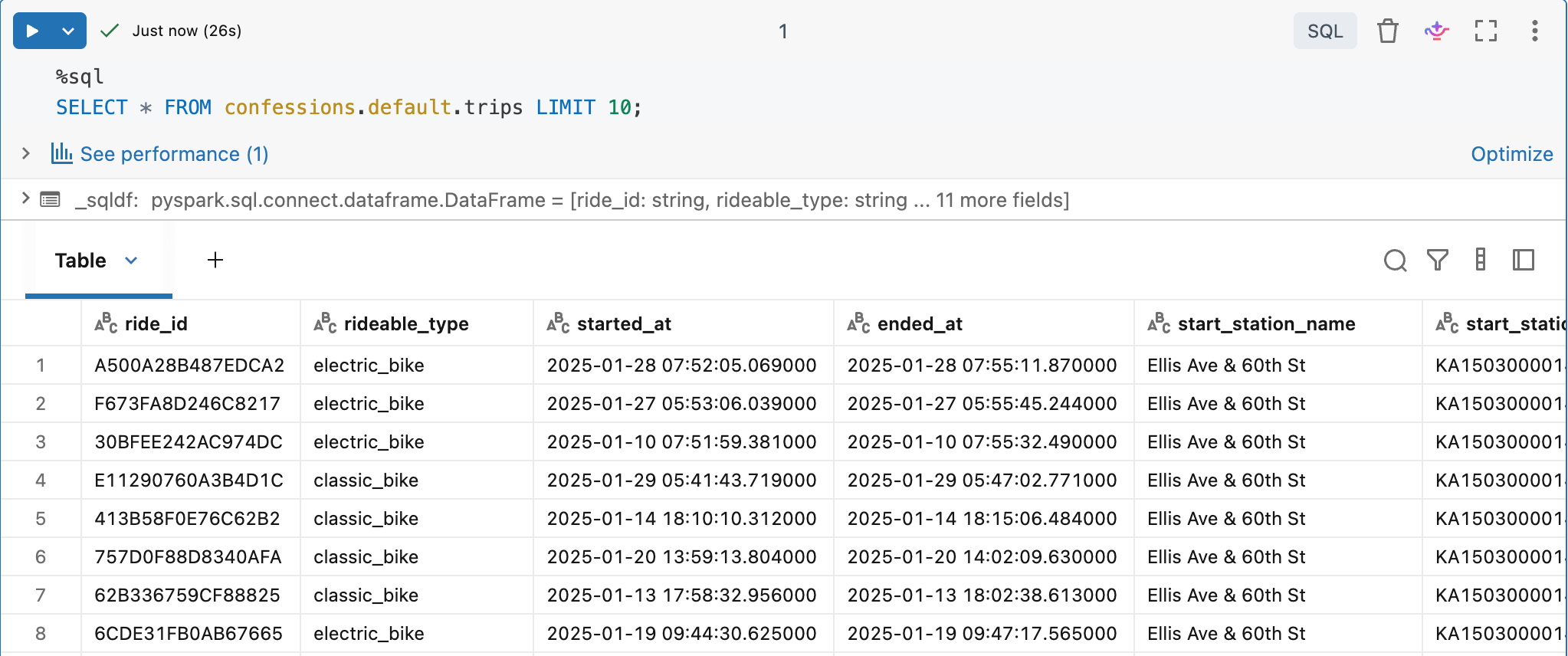
Prep your Delta Table, or make one.
We will use the Divvy Bike trips open-source dataset, just because it’s easy and accessible. I’ve already set up a Delta Table for this dataset, so we'll use it as our target table.
Write the Zerobus Client.
Ok, so now we are at the point where we can actually get to using Zerobus, and they give you a few different SDK options to interact with Zerobus, depending on whether you are a fake data engineer, a power user like me, or maybe more of a real data engineer, like Scott.
Oh, I almost forgot that dreaded pip install.

We are going to be combining Zerobus with PyArrow, aka Apache Arrow, because Arrow is the next big thing, you ninny.
Prep our Arrow schema.
schema = pa.schema([
("ride_id", pa.string()),
("rideable_type", pa.string()),
("started_at", pa.timestamp("ms")),
("ended_at", pa.timestamp("ms")),
("start_station_name", pa.string()),
("start_station_id", pa.string()),
("end_station_name", pa.string()),
("end_station_id", pa.string()),
("start_lat", pa.float64()),
("start_lng", pa.float64()),
("end_lat", pa.float64()),
("end_lng", pa.float64()),
("member_casual", pa.string()),
])Anywho, next we write the rest of the code.
Create Stream
Read dataset
Push batches to Stream
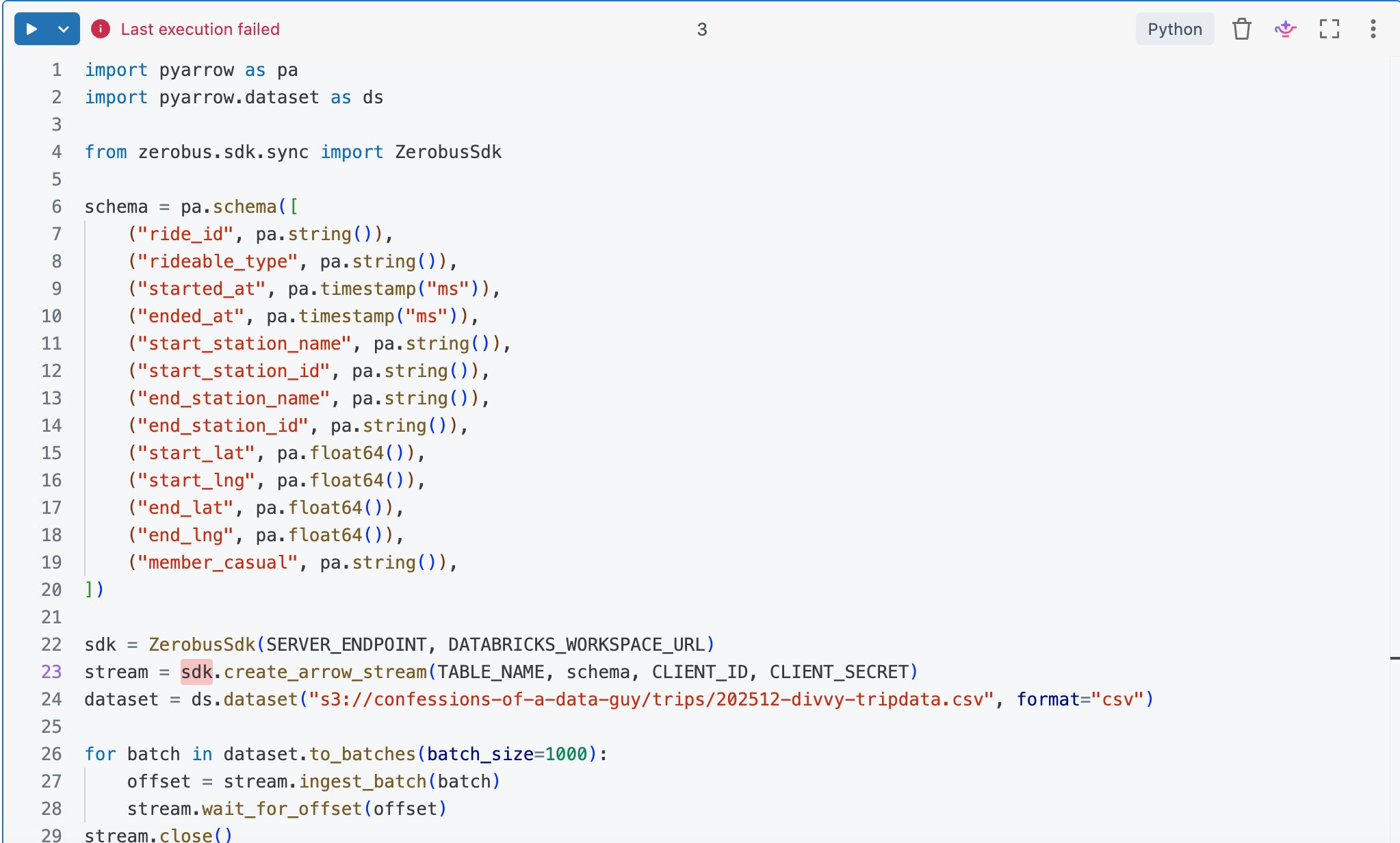
Y’all knew as well as me it wasn’t going to work the first time. I never lie to you, my fair-weathered friends. Call me Honest Abe.

I see no mention in the docs about not being able to use Serverless. Basically, I can’t even hit that Zerobus endpoint from my Notebook/Serverless. Not much to do besides attempt the same code on an All Purpose cluster and see what’s crack’en.
Ah ha! So we get farther when we don’t use Serverless, maybe that’s not an option, and they don’t tell you.
Using an All-Purpose Cluster, we get an actual error about our Schema from our Zerobus SDK, so that’s a good sign.
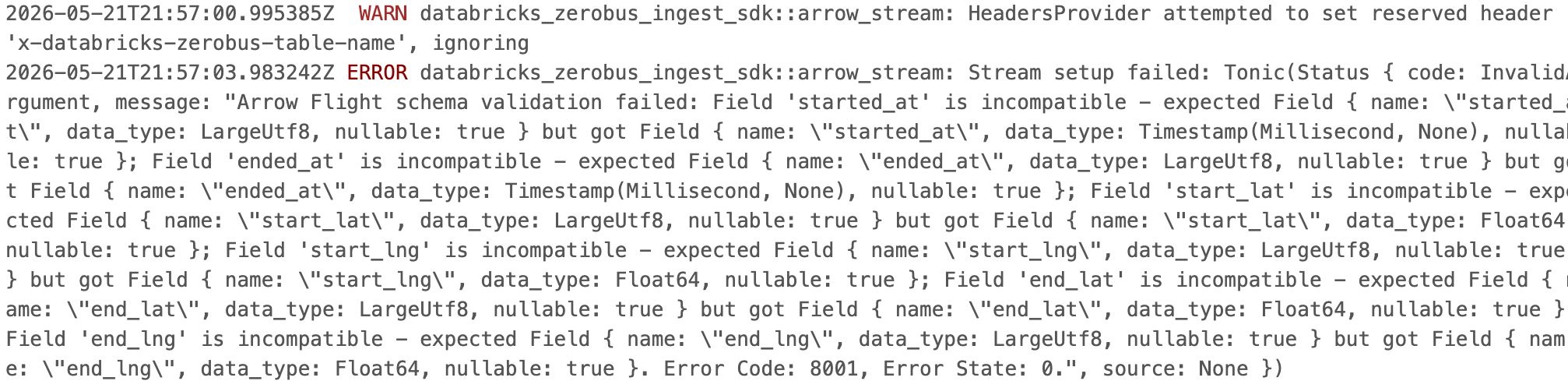
I got any easy for this Sunny Jim. Just make all the fields STRING, we gotta break out our inner Junior Dev mindset here. Channel the vibes.
Ok, Ok, we are moving on down the Error list, this is a good sign. I can see messages that the Zerobus SDK created a new Arrow Flight stream connection to our table.

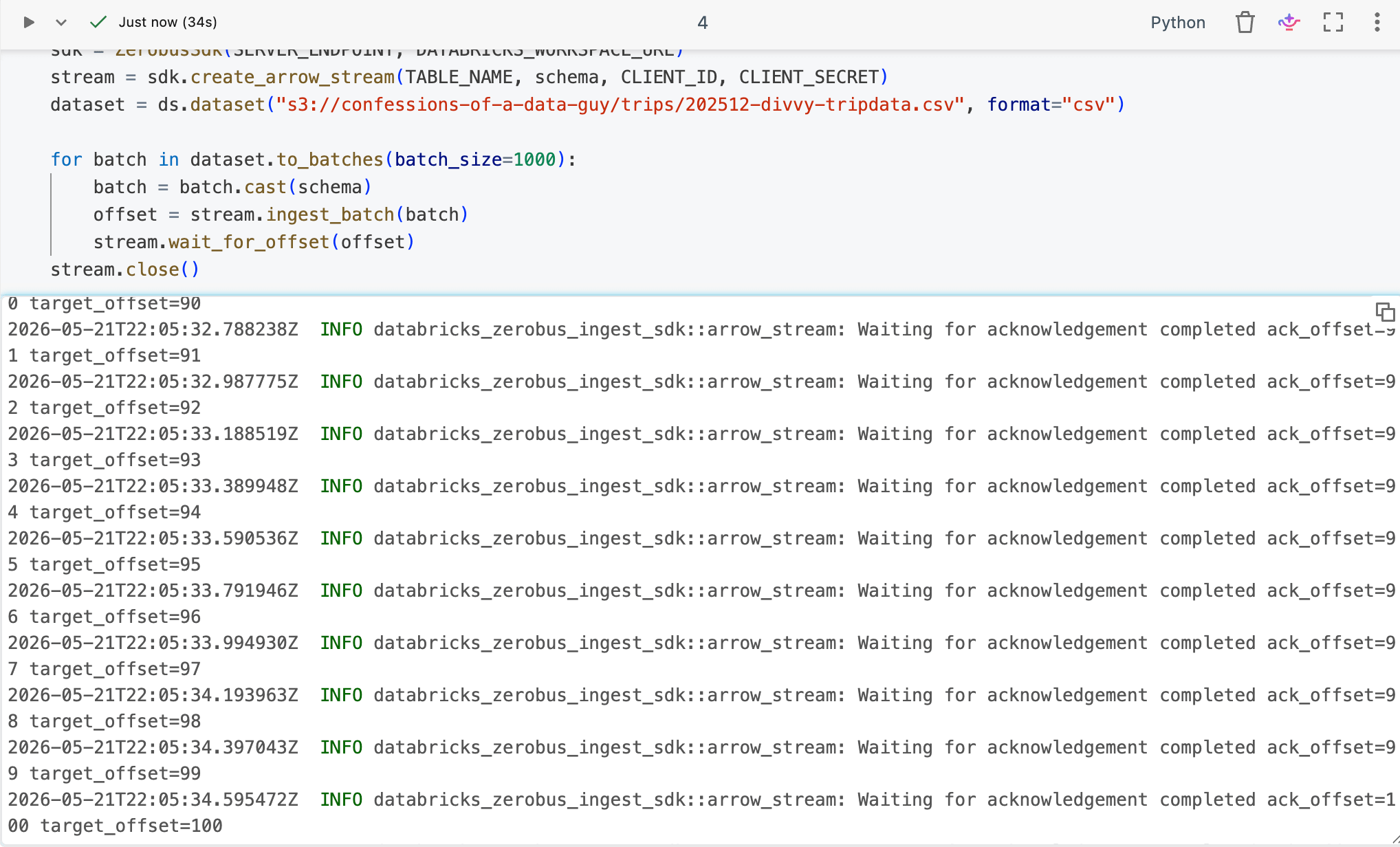
Dang, add a little Arrow batch.cast , and we are off to the races! It works!
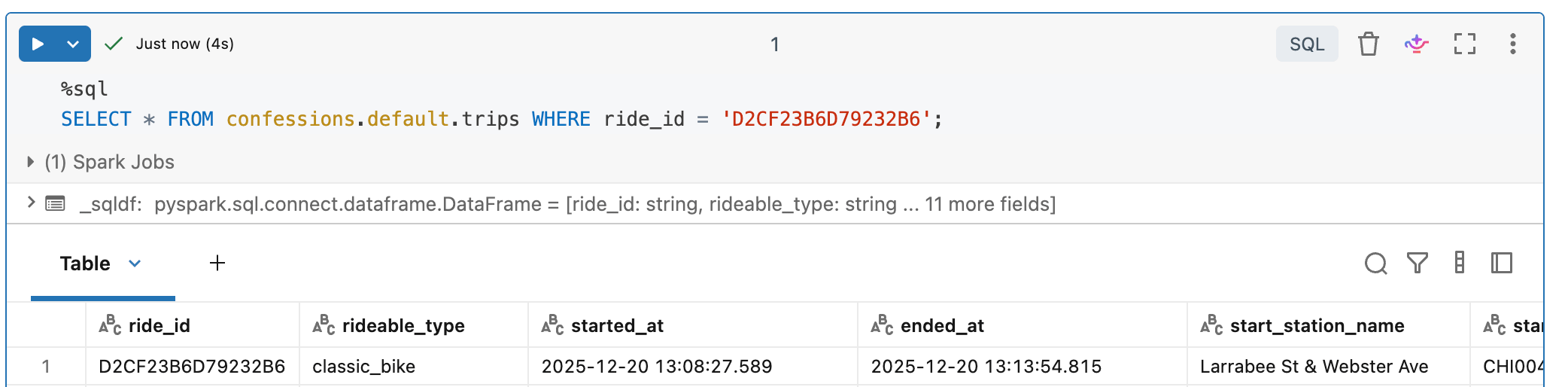
Let’s take one of the 140,000 records we just streamed to our Delta Table with Zerobus and see if we can find it. Hot Dog, ain’t it a beauty?
Thinking about things.
There are a few things I’m mildly curious about. Namely, you have to imagine that the number of parquet files created will be a little crazy, depending on your settings, so you'd better manage that whole OPTIMIZE crap or your streaming batches.
Also, just in case you think I’m lying to you, here is the History of that table. You can see the Zerobus ingestion there.
Here we have 8 files in this Delta Table after the streaming job, but before OPTIMIZE.
Afterward, that is OPTIMIZE, we are down to a single parquet file backing up the Delta Table, not 8. One can use one's imagination to consider how carefully one would have to manage real-time, high-volume streaming ingestion into a Lake House.
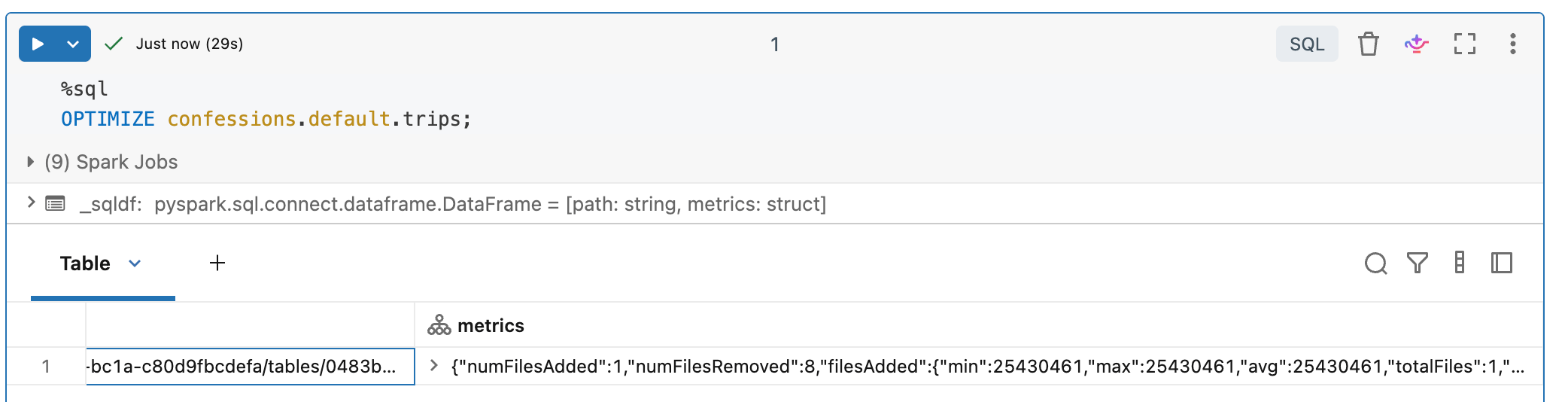
Again, at the production scale, many hundreds of TBs or more, this would require some serious thinking.
Closing Comments.
I just want to spend a minute now that we’ve done a little dirty work, talking about what we’ve learned, and questions we might have about streaming to the Lake House with Zerobus from Databricks.
Firstly, we must admit two things that have been happening at large in the data world …
Streaming has become popular
The Lake House is the new data architecture of choice
Also, we would all have to admit that streaming is probably one of the most complicated and complex tasks one can tackle in Data Engineering. It’s a whole different animal than batch. Also, many companies and tools seem interested in simplifying streaming, bringing it to the masses, and lowering the barriers to entry.
Yeah, I know we just played with a toy example, but one has to admit, Zerobus is pretty slick.
No big infrastructure to maintain and tune
SDKs are simple and straightforward
Integration into the Lake House is a breeze
Methinks that this streaming complexity problem, previously requiring bespoke and custom setups via Kafka and Spark Streaming were just a little much for some folks.

I mean, it does add a lot of complexity and breakpoints.
Anywho, now we have a new and wonderful option in Zerobus if we are interested in Lake House streams.
Based on our preliminary playing around, it appears to be a very serious contender, heck, they even have support for Arrow! That was a pleasant surprise.
If you have any experience streaming to a Lake House, drop a comment below and tell us about your setup!
I like your writing style, smooth with a sense of humor… it has has a nice “flow”… :-)