



Some days I want to throw my hands up in the error and give up. I’m not a young man anymore. I feel my age. Can an old dog learn new tricks? He probably can … but does he want to?
One of the biggest challenges of being a Data Engineer is keeping up with all the new features and shiny rocks that are pushing and shoving for their moment in the spotlight. How do you keep on top of it all?
I will be the first to raise my hand and say “focus on the basics first,” but at some point, you become obsolete if you don’t know which way the market and the tools are moving. At the risk of making my readers mad … oh what the heck … do you really want to be a Redshift expert for the next decade, or should you move on to Snowflake and Databricks?
Thanks to Delta for sponsoring this newsletter! I personally use Delta Lake on a daily basis, and I believe this technology represents the future of Data Engineering. Check out their website below.

How do I keep up with it all? Well, I read … a lot. What other way is there? I watch r/dataengineering, Linkedin, and various and sundry blog posts. I attempt to keep tabs on what new features or tools are released, and at least have a cursory understanding of what’s available and becoming a thing.
Hench, I’m writing about Liquid Clustering for Delta Tables.
Liquid Clustering in Real Life
Today I want to give a cursory introduction to myself, because I know nothing about it yet, of Liquid Clustering. I also want to do some testing, and some benchmarking on Liquid Clustering vs classic Partitioning of Delta Tables.

Mostly because I have some outstanding questions about how Liquid Clustering works, in the beginning, and over time.
I pray, give me a moment to avail myself of my own misgivings, much like anything else when I run across something new to me. I’m always going on witch hunts, and I’m never satisfied until I’ve burned something or other, even if just a token.
So you know about Partitions right? Right? Right?
It could be hard to understand or reason about Liquid Clustering if you are not familiar with “classic” data partitioning, like Hive-style partitions.
If you have a million parquet files holding a few TBs of data … and you need something from that data … what do you do? Read all million files to find what you want. Not a good idea. This is where partitions come in. They help you “narrow in” on what you’re looking for.

For classic data partitions, say when you’re making a new Delta Table you have to sit down and think for a while. You have to figure out what your major query patterns are, and how the data is laid out physically. Then base your partitions on this information.
Maybe you working with time-series data so you partition by year, month, and day. Maybe it’s by the customer. Maybe something else.
It can be half-art and have science, trying to divine all the use cases beforehand. And, you have to understand how the data is physically laid out and its volumes. Otherwise, you get “skew,” that is all the data in 1 or 2 partitions, and none in some others. This will kill query performance.
Liquid Clustering “solves” all these problems.
So, back to our new Liquid Clustering kid on the block. It appears Databricks is going all on in on this one. They recommend all new tables use Liquid Clustering and are very “broad” when listing their use cases, which is pretty much every use case.
“Delta Lake liquid clustering replaces table partitioning and
ZORDERto simplify data layout decisions and optimize query performance.”
What are some things you should know about Liquid Clustering?
You need a fairly new version of DBR runtime to do all read/write stuff with Liquid Clustered Delta Tables.
Only up to 4 columns can be clustered.
Only columns that have statistics collected can be clustered.
Not all DML (merge, etc) clusters data on write … so OPTIMIZE frequently.
What questions do I have about Liquid Clustering?
So, it’s all rainbows and glitter falling from the sky? I doubt it. I find there is a dark side to every new feature, especially the ones that are trying to do us the most good. You have to be careful not to shoot yourself in the foot.
Test everything carefully, trust nothing. That is a good rule when it comes to production.
The problem is that all our use cases are different and you don’t know how yours will react without testing things out first.
Should we OPTIMIZE more frequently with Clustered tables?
How quickly does data shift to and fro from clustering keys based on usage?
Some guidance on this would be super helpful from Databricks.
If you have a day or two with some specific one-off queries, will data be clustered differently, and then next week’s first pipelines will grind to a halt because of this?
I’m mostly concerned about performance. Partitions and data locality have a major impact on Big Data workloads and performance. Call me old school, but that’s why I like to have control.
Do I want every SELECT statement run on Production data by every Analyst and Data Scientist to affect my workloads that run all week long? Just because they happened to run some query a few times and a OPTIMIZE happened to kick off that ended up clustering data in such a way that will kill the next production workload?
I’m sure someone will tell me it’s all too smart for that … mmmhmmm. Heard that before. They told me Photon was going to solve all my problems too. Forgot to mention availability and the effects on cost they did.
Sometimes the real world is different from the ideal one.
Let’s try some Clustered tables out vs Partitioned tables.
To do this test we are going to use the free Community Version of Databricks which provides a free 2-core and 15 GB Spark cluster, along with a Workspace and Notebooks.

This will be perfect for our testing. Of course, we need data and can use the open-source Landsat (satellite) data hosted on AWS s3. There is a csv.gz file that lists all the “scenes” taken by the Landsat satellite as it circles this world of ours.
The truth is we probably need a few TBs of data to do a true test, but whatever, we do what we can these days.


Let’s create two Delta Tables, one with Liquid Clustering, and the other with normal partitions, heck, maybe one with no partitions or clustering at all. Just to see how it goes.
Here are the normal partitions as we are used to, lo, these many years.

We will also OPTIMZE and ZORDER this above table by entityId.
And another for the Liquid Clustering.

and just a plain ol’ table.

And now there is nothing for it except to get our data loaded into these Delta Tables and run our OPTIMIZE commands, along with the ZORDER for the partitioned table. (note I only ran OPTIMIZE a single time on each table)

Of course, I ran this code for the other two tables, the no partitions and the Liquid Clustering Delta tables.
Now I’m just going to run a query doing some stuff per year and month. I will run the query 5 times on each table. On the Liquid Clustering table, I will run an OPTIMIZE command after each query.
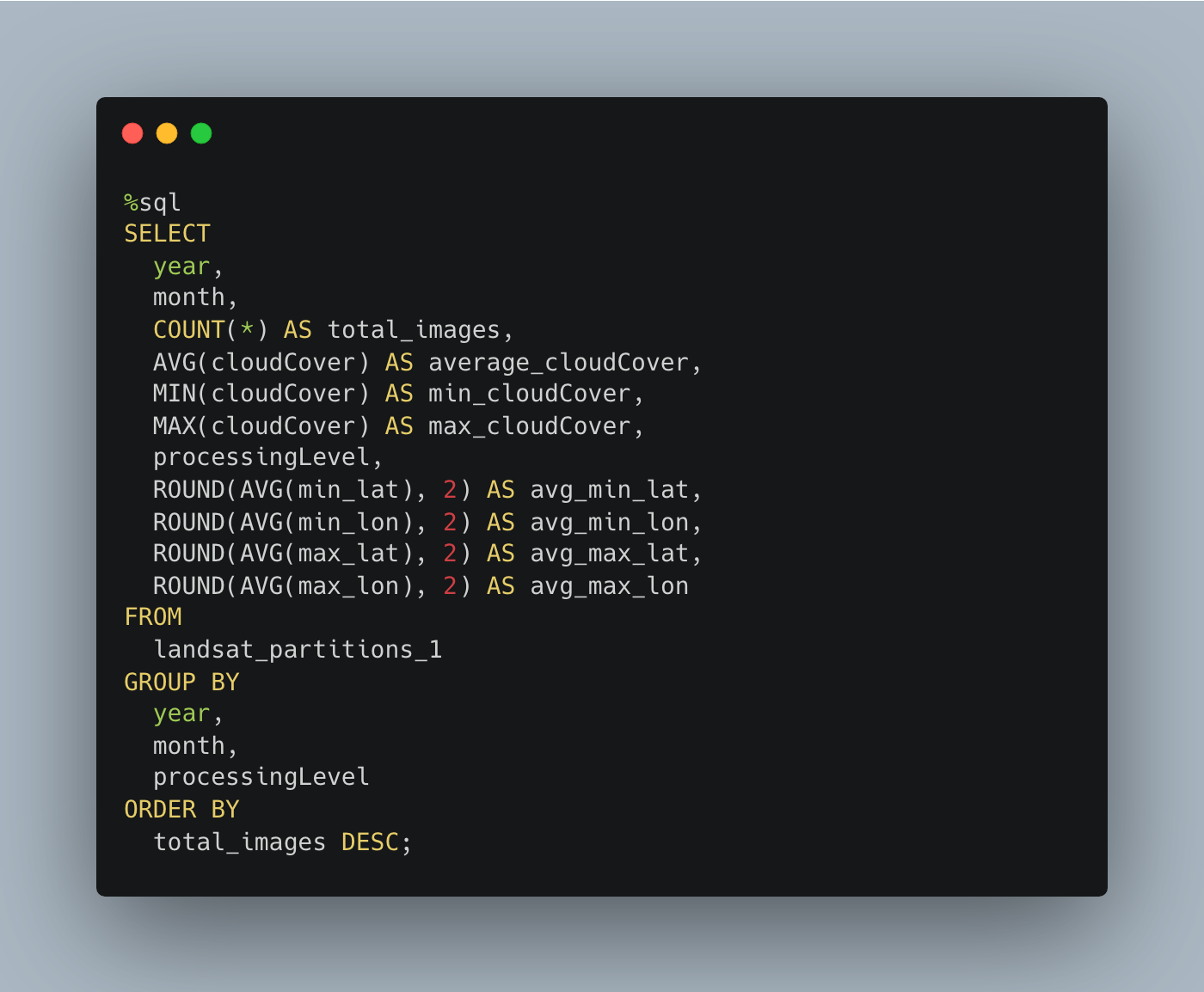
This is probably the most unscientific testing we could do, but it will still be interesting to see what we see. I’m hoping by running each query 5 times in a row we can sort of throw any weird caching out the window and get an idea of what is going to happen.
run query
optimize (for liquid table)
repeat 5 times
I would expect that the partitions table would stay the same through the runs, notwithstanding caching of data and the like, if that is happening on the Databricks side.
I would also expect the Liquid Clustering to be slow in the beginning and faster for each query and optimize that is run.
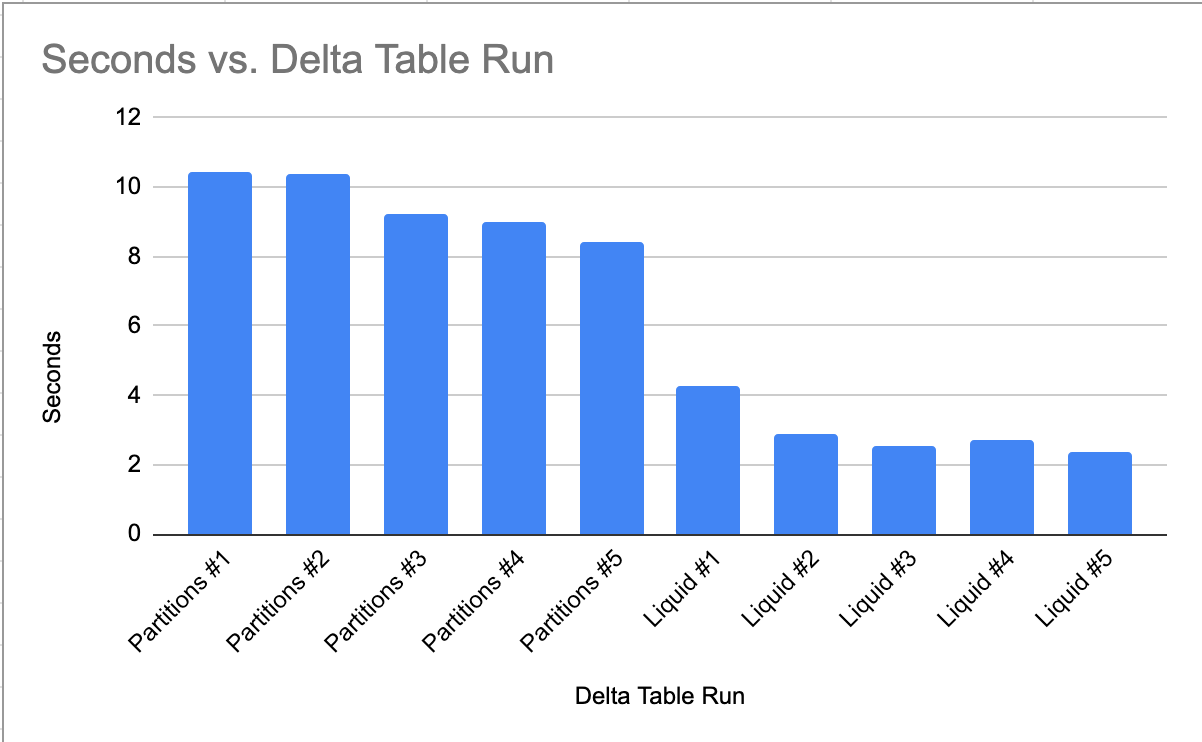
Well, now I am very curious indeed! I wonder if these results will scale with the data!! The Liquid Clustering tables are twice as fast to query as the manual Partitions table!
It’s hard to say why, other than that Liquid Clustering combined with the Databricks Runtime is just been designed to be magical together. I mean it’s hard to say at this small scale if this not scientific test really means anything or not.
But, we must give credit where credit is due. Begrudgingly even. I guess I have no excuse now but I must upgrade the DBR and Delta Table versions and try this in a production environment!
Did you try this at scale? What about the insert / merge performance? I'm curious to know the differences as well because I'm of the same mind that a measure of control on your partitions is usually preferred over letting a machine figure it out dynamically all the time
(also - it's cheaper as we don't have to pay to constantly optimize our data).
While your test is arbitrary and not necessarily demonstrating a real-world use-case and performance comparison, I think if the scale is indicative of anything, I could argue that nobody queries "the whole table" like this and that, in fact, they do so on very specific time-ranges of interest (i.e. the last 7/14/30 days). if one were to argue that the real-world query volumes are 10% or less of the total volume, a linear performance profile would result in manually partitioned and liquid clustered performances reaching negligible ranges (i.e. 8 seconds * 10% = 0.8 seconds and 4 seconds * 10% = 0.4 seconds).
One type of value one might get from data being organized in their own partition scheme is that they could can more cheaply and effectively manage archival and migration tasks and with cheaper tools / technologies ! (Azure Functions vs Synapse Serverless SQL vs Presto vs Databricks)
I might have missed that in the article but why are we optimizing the liquid partitioned table after every run?