



Sometimes you have to take your own medicine, eat your own words, and swallow that bitter pill. I keep wondering if I’m going to have to do that with my DuckDB takes. I mean if you watch talking heads at Databricks Data and AI Summit … it looks like DuckDB is really going mainstream.
Probably not that big of a surprise with an SQL tool. Data Engineers are like drug addicts when it comes to SQL, they don’t even ask questions, they just use.
Either way, I’m going to kick at the ole’ tires of DuckDB once again. See what’s what. There is a feature or two that I’m very interested in.
What I’ve written about DuckDB in the past.
Lest you think I had behind the pillars of the interwebs flinging stones at unsuspecting software (ok, I do sometimes do that), let me list all the different DuckDB articles I’ve written low these many years.
By George, I do seem like ye old Gandalf Storm Crow don’t I?? Cry me a river, I will mark it down in my book.
What I’m Watching with DuckDB Right Now
So, I’m not an expert in DuckDB since I mostly spend my time trying to break it every time I use it … I’m going to give you my take on the announcement of DuckDB 1.0.0 … and what I’m paying attention to.
DuckDB has its own custom-built data storage format (that is now stable)
DuckDB now has first-class Delta Lake support. (link)
Have they fixed the OOM errors??
Mother Duck (serverless compute in the cloud)
I’m probably most interested in talking about the DuckDB storage format, testing Delta Lake reads, and writes to remote tables in s3, and checking out OOM memory problems again.
It appears DuckDB has a free 30-day trial for Mother Duck which we will have to poke at again in a separate article. I’m interested in seeing if I can get a rough calculation of cost savings using Mother Duck vs Databricks for some pipelines.
Diving In.
Let’s start by doing the easy one. We’ve tested DuckDB’s ability to handle larger-than-memory datasets out on the cloud, but it always blew up no matter what we tried.
Here’s another go at it. I’ve got a Linode with 4GB of RAM.

Next that data.

9.1GB of data for our 4GB machine, should be enough to see if our new DuckDB 1.0.0 has solved some of the prior OOM errors.
(duck) root@localhost:~# pip3 install duckdb
Collecting duckdb
Downloading duckdb-1.0.0-cp312-cp312-manylinux_2_17_x86_64.manylinux2014_x86_64.whl.metadata (762 bytes)
Downloading duckdb-1.0.0-cp312-cp312-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (18.5 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 18.5/18.5 MB 105.7 MB/s eta 0:00:00
Installing collected packages: duckdb
Successfully installed duckdb-1.0.0The Python we will be running is this …

Welp. I would say I’m totally surprised. But then I guess this wouldn’t be the first time some marketing fluff disappointed me.

From what I can tell I’m still not the only one with these problems, as recently as 2 days ago on Hacker News there were plenty of other people complaining about OOM errors.
The simple fact is that I’m not going to fight anymore with DuckDB and its OOM issues, I will simply use something like Polars that can do larger-than-memory execution without a hiccup. Why fight it?
Testing DuckDB’s Delta Lake Support.
Now I need something to cheer me up after the OOM failures, and another better to do that with than a little remote Delta Lake table reading and writing with DuckDB.
Just to get the full picture I think I will do the following …
read raw CSV’s in s3 with DuckDB
take the above results and write them back to a partitioned Delta Lake table on s3
do an analytical query against that s3 Delta Lake table.
This seems very straight forward and a common task any tool working with Delta Lake should be able to do without much problem. We will probably time each step as well, to get a baseline, and then have Polars do the same thing and compare results.
First, I wanted to ensure DuckDB could read my creds and talk to the raw data. Easy enough, it can connect to the raw CSV files on s3 and print them out no problem.

Next, let’s write a script to take that data and push it to an s3 Delta Table.
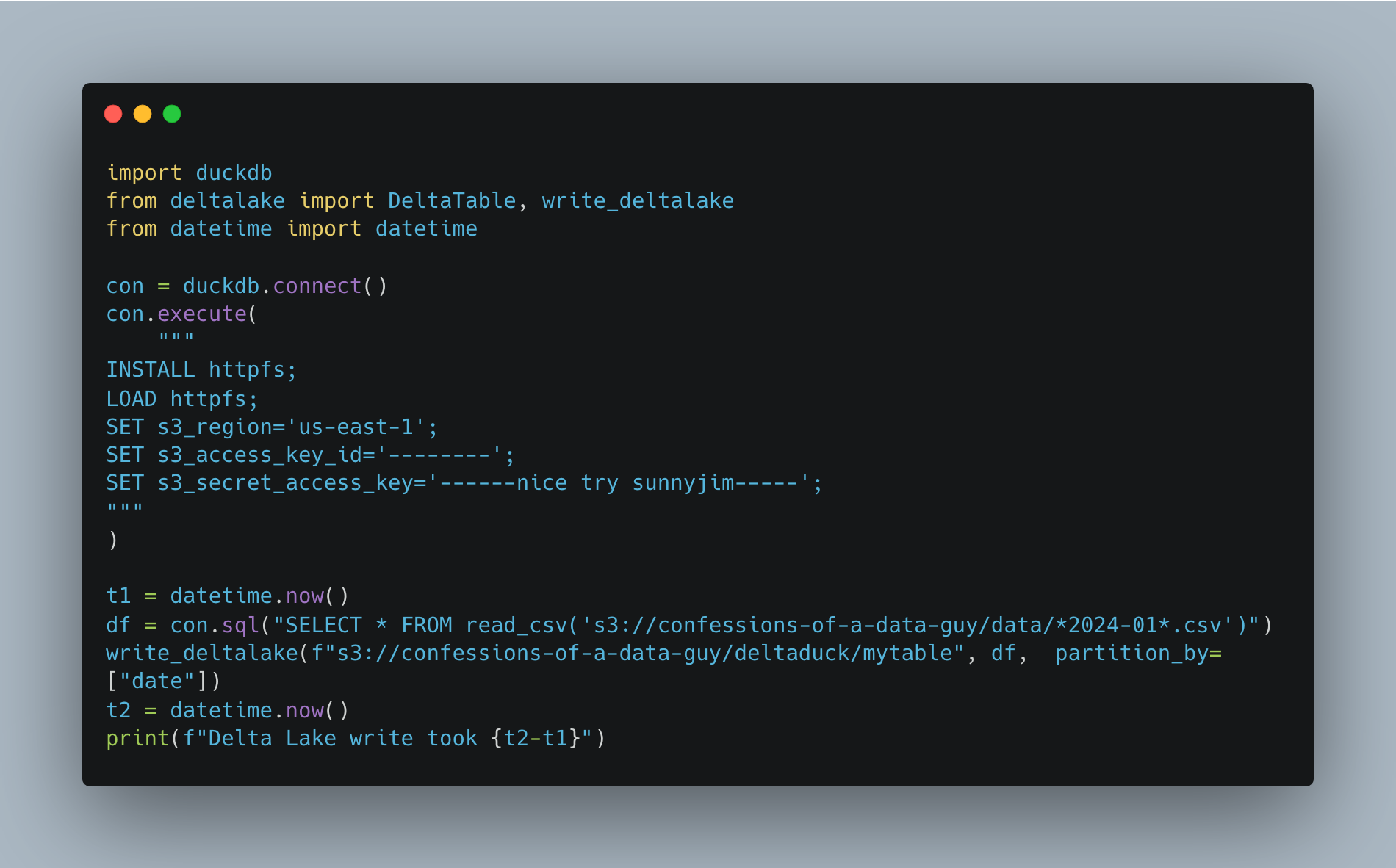
Again, I would say I’m surprised this failed, but at this point, I’m not. At least for me, nothing is as simple as it seems with DuckDB. This error is coming from the deltalake package, ….
you would think if DuckDB is lauding the native integration of duckdb and deltalake on their own blog they would make sure the integration is tight and not janky.

Since we have nothing better to do, and apparently Delta Lake and DuckDB don’t work THAT WELL together, let’s give Delta Lake the creds to s3 we already gave to DuckDB.

Well by George we got a little bit closer.
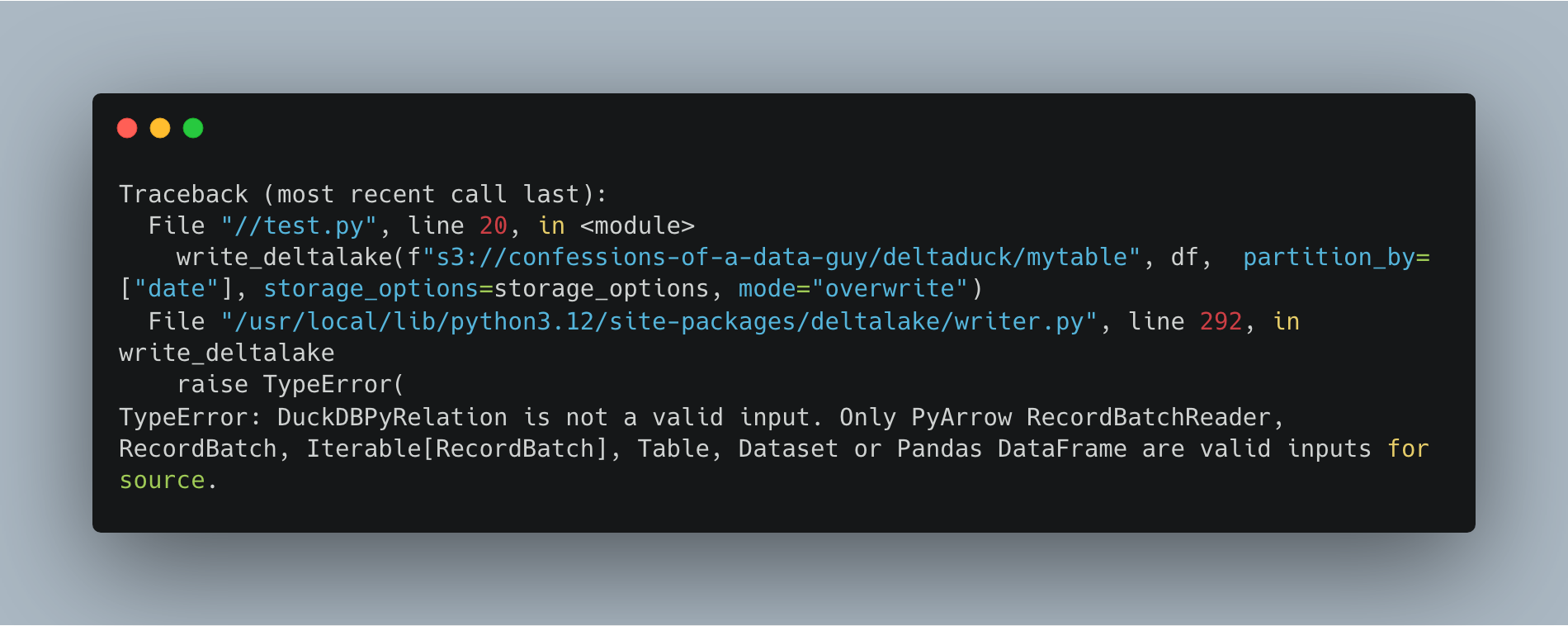
Apparently whatever DuckDB thingy I’m passing isn’t working. I know little about DuckDB but this seems easy enough to overcome.
Turns out in the examples they did a .df() when passing to Delta Lake … so …
write_deltalake(f"s3://confessions-of-a-data-guy/deltaduck/mytable", df.df(), partition_by=["date"], storage_options=storage_options, mode="overwrite")Try ‘er again.
This time it ran for about 15 minutes … AND THEN … died.

For context, we talking about 8,466,958 records in the dataset. 8 million, that’s it.

Ok, I promised myself I would not be such a Gandalf Storm Crow on this one, I said I would be nice and kind. But arggggg!
I get it that DuckDB is nice for some people who could get away with using Pandas for their datasets. Guess what? A lot of us don’t have that option.
Seriously? 8 million records and it chokes?!?!
(running on my Macbook with 16GB of memory)
How is this supposed to be a scalable and reliable toolset for Data Engineers to build products on top of? As for me and my house, it simply isn’t going to happen.
Writing a few GBs of data to an s3 location just blows up? There are simply too many other tool options out there like Spark, Polars, Datafusion, Daft … that DON’T have these types of problems out of the box.
I know at this point I had promised to look into the new DuckDB internal file storage format. I was planning to do some benchmarking vs say Parquet files for some datasets, but I’m just too depressed at this point to keep going.
I draw the line at the inability to work with small datasets on s3. If it can’t do that well I’ve got no time for it, and neither should you.
Your OOM example is running in in-memory mode. You're simultaneously cutting yourself off from using disk and constraining your memory limit. From the docs - "If DuckDB is running in in-memory mode, it cannot use disk to offload data if it does not fit into main memory." (https://duckdb.org/docs/guides/performance/how_to_tune_workloads#spilling-to-disk)
The Delta Lake example is uninformed. The support for Delta Lake is through a DuckDB extension which clearly states it's current limitations - no write support, for example. There's zero promise or expectation that the Python deltalake library will now accept an object from the duckdb Python library. The actual details can be found here (https://duckdb.org/2024/06/10/delta.html). You'll see the example in this article and what was actually released are drastically different things.