

DuckDB inside Postgres!!??
... black magic


Maybe it’s my age, I’m not totally sure, but it’s getting harder and harder for this old guy to keep up with all the new things that come trickling out of the quagmire that is the Data Engineering space these days.
Some of the ideas that come into being simply boggle my mind, so obvious once you see them, so unintuitive that it would be a thing in someone’s mind and then come to be. Amazing.
One example of that is DuckDB INSIDE Postgres. I had to read that post on Linkedin twice to make sure I wasn’t hallucinating from whatever I ate for breakfast.

What a genius idea if I do say so myself.
This amalgamation of DuckDB and Postgres caught my eye for a few obvious reasons to anyone who’s working in Data Engineering for more than a year.
Postgres is ubiquitous across most Data Platforms
DuckDB is blazingly fast
Postgres starts to choke when supporting OLAP on datasets that are “large”
Don’t get me wrong, I love Postgres, it’s the GOAT of the RDMBS (relational database management system) world. It’s popular for a reason.
In the Lake House world, I find myself living in low these long and languid years, and even before that, I’ve frequently found myself annoyed with Postgres when it comes to query performance.
I get it.
Postgres shines in the OLTP world, OLAP these days requires either the scale of Databricks or Snowflake, or the speed of Polars, Duckdb, Daft etc. It was genius for someone to take DuckDB and put it INSIDE Postgres.
What does DuckDB say about itself, when they think it should be used in a Postgres context??
“PostgreSQL is often used for analytics, even though it's not specifically designed for that purpose. This is because the data is readily available, making it easy to start. However, as the data volume grows and more complex analytical queries involving aggregation and grouping are needed, users often encounter limitations. This is where an analytical database engine like DuckDB comes to the rescue.” - DuckDB
You can’t argue with them, we all know it’s true.
But, you know me, seeing is believing.
Testing out pg_duckdb … aka DuckDB inside Postgres for ourselves.
Either this is going to be wonderfully fun, or wonderfully boring, we will find out. But, we must test this out ourselves. Let’s do the obvious thing any Data Engineer would do when first finding out about pg_duckdb … give er’ the good old kick in the tires.
We will need two things only, well, maybe three.
Postgres with the DuckDB extension installed (pg_duckdb)
The ability to generate 50 million records and get that inside Postgres
An OLAP query to run against that dataset to test
old-school Postgres speed
DuckDB inside Postgres speed
Luckily, DuckDB has made this easy by providing us with a pre-built Docker image.(This is a breath of fresh air for a newish project, most people forget this important part, makes everyone’s life easier in the beginning)

So, that’s one problem we don’t have to solve. Next, we need to generate about 50 million records in a CSV format that we can dump into Postgres.
I found a Rust-based CSV and data file-generating repo on GitHub, but it was so slow and locked my computer up, that I decided to write my own.
Enter datahobbit.

Feel free to help contribute to this open-source codebase. I think there is of course a lot of room to improve it, turn it into a Python package etc, but that will be for another day.
Putting it all together.
So, as mentioned before, you can obtain the Postgres+DuckDB Docker image by running something like …
docker run -d -e POSTGRES_PASSWORD=duckdb pgduckdb/pgduckdb:17-v0.1.0This command will download the image if you don’t have it already. Next, we need to generate 50 million records for some sort of sample dataset we can push into a Postgres table to use as a test.
We are going to use my Rust-based CLI tool called datahobbit. This makes it easily to generate our sample CSV file. (of course you must clone the repo and and build the project first)
cargo build --release
./target/release/csv_generator schema.json output.csv --records 5000000050 million records is barley enough to put Postgres and DuckDB through the paces for a single query, but we shall see.
The schema I’m setting looks like this (datahobbdit requires a schema in JSON format to build the CSV) …
{
"columns": [
{ "name": "id", "type": "integer" },
{ "name": "first_name", "type": "first_name" },
{ "name": "last_name", "type": "last_name" },
{ "name": "email", "type": "email" },
{ "name": "phone_number", "type": "phone_number" },
{ "name": "age", "type": "integer" },
{ "name": "bio", "type": "sentence" },
{ "name": "is_active", "type": "boolean" }
]
}Getting the data into Postgres.
Next, we need to get all this data in CSV format, dumped into our Postgres+DuckDB image.
Create the container
docker run -it -d --name pg_duckdb -p 5432:5432 -e POSTGRES_HOST_AUTH_METHOD=trust pgduckdb/pgduckdb:17-v0.1.0Copy file(s) to the container (run this in the directory that has our CSV)
docker cp . pg_duckdb:/tmp/postgresConnect using psql to Postgres
docker start pg_duckdb docker exec -it pg_duckdb psqlCreate SQL Postgres table to match our schema. (the index will be to support our analytics query later that we will run for the benchmark)
CREATE TABLE data ( id INTEGER, first_name VARCHAR(50), last_name VARCHAR(50), email VARCHAR(100), phone_number VARCHAR(50), age INTEGER, bio TEXT, is_active BOOLEAN ); CREATE INDEX idx_data_age_is_active ON data (age, is_active);COPY that data (CSV) into the Postgres table.
COPY data FROM '/tmp/postgres/output.csv' DELIMITER ',' CSV HEADER;Run this query WITHOUT DuckDB and JUST Postgres.
EXPLAIN ANALYZE SELECT age, is_active, COUNT(*) AS user_count FROM data GROUP BY age, is_active;Results of plain ole’ Postgres
Planning Time: 0.617 ms JIT: Functions: 21 Options: Inlining true, Optimization true, Expressions true, Deforming true Timing: Generation 2.204 ms (Deform 0.786 ms), Inlining 101.451 ms, Optimization 108.949 ms, Emission 64.002 ms, Total 276.607 ms Execution Time: 3971.350 ms (3.97135 seconds) (22 rows)force Postgres to use DuckDB to execute SQL
SET duckdb.force_execution = true;Results of DuckDB
Custom Scan (DuckDBScan) (cost=0.00..0.00 rows=0 width=0) (actual time=7878.442..7878.541 rows=1 loops=1)
DuckDB Execution Plan:
┌─────────────────────────────────────┐
│┌───────────────────────────────────┐│
││ Query Profiling Information ││
│└───────────────────────────────────┘│
└─────────────────────────────────────┘
EXPLAIN ANALYZE SELECT age, is_active, count(*) AS user_count FROM pgduckdb.public.data GROUP BY age, is_active
┌────────────────────────────────────────────────┐
│┌──────────────────────────────────────────────┐│
││ Total Time: 5.85s ││
│└──────────────────────────────────────────────┘│
└────────────────────────────────────────────────┘
┌───────────────────────────┐
│ QUERY │
│ ──────────────────── │
│ 0 Rows │
│ (0.00s) │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ EXPLAIN_ANALYZE │
│ ──────────────────── │
│ 0 Rows │
│ (0.00s) │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ HASH_GROUP_BY │
│ ──────────────────── │
│ Groups: │
│ #0 │
│ #1 │
│ │
│ Aggregates: │
│ count_star() │
│ │
│ 2000 Rows │
│ (0.60s) │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ PROJECTION │
│ ──────────────────── │
│ age │
│ is_active │
│ │
│ 50000000 Rows │
│ (0.01s) │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ TABLE_SCAN │
│ ──────────────────── │
│ Function: │
│ POSTGRES_SEQ_SCAN │
│ │
│ Projections: │
│ age │
│ is_active │
│ │
│ 50000000 Rows │
│ (5.22s) │
└───────────────────────────┘
Planning Time: 113.380 ms
JIT:
Functions: 1
Options: Inlining true, Optimization true, Expressions true, Deforming true
Timing: Generation 0.270 ms (Deform 0.000 ms), Inlining 0.000 ms, Optimization 0.000 ms, Emission 0.000 ms, Total 0.270 ms
Execution Time: 7884.068 ms (7.884068 seconds)
(69 rows)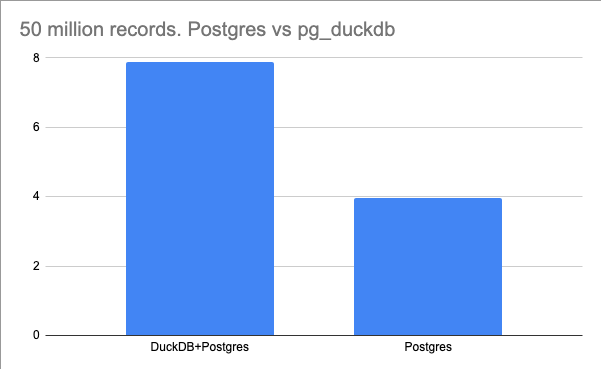
That’s not what I expected.
Interesting indeed, I honestly did not expect that, I thought DuckDB would be much quicker, I mean it is known for its quickness, but apparently the GOAT of databases called Postgres isn’t ready to be retired yet.
What’s going on here?
I wonder if we can close the gap with 100 million records maybe?? I went ahead and cleaned up the resources and started from scratch again, this time generating a 100 million record file with datahobbit.
Here we go again.
Raw Postgres.
Finalize GroupAggregate (cost=1912472.21..1912575.55 rows=400 width=13) (actual time=45861.045..45925.503 rows=2000 loops=1)
Group Key: age, is_active
-> Gather Merge (cost=1912472.21..1912565.55 rows=800 width=13) (actual time=45860.769..45924.410 rows=6000 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Sort (cost=1911472.19..1911473.19 rows=400 width=13) (actual time=45838.693..45838.920 rows=2000 loops=3)
Sort Key: age, is_active
Sort Method: quicksort Memory: 111kB
Worker 0: Sort Method: quicksort Memory: 111kB
Worker 1: Sort Method: quicksort Memory: 111kB
-> Partial HashAggregate (cost=1911450.90..1911454.90 rows=400 width=13) (actual time=45837.022..45837.267 rows=2000 loops=3)
Group Key: age, is_active
Batches: 1 Memory Usage: 241kB
Worker 0: Batches: 1 Memory Usage: 241kB
Worker 1: Batches: 1 Memory Usage: 241kB
-> Parallel Seq Scan on data (cost=0.00..1845538.80 rows=8788280 width=5) (actual time=0.232..40643.594 rows=33333333 loops=3)
Planning Time: 6.428 ms
JIT:
Functions: 21
Options: Inlining true, Optimization true, Expressions true, Deforming true
Timing: Generation 1.616 ms (Deform 0.444 ms), Inlining 266.226 ms, Optimization 89.928 ms, Emission 102.221 ms, Total 459.990 ms
Execution Time: 46156.029 ms (46.156029 seconds)
(22 rows)And here is pg_duckdb.
Custom Scan (DuckDBScan) (cost=0.00..0.00 rows=0 width=0) (actual time=64438.844..64440.117 rows=1 loops=1)
DuckDB Execution Plan:
┌─────────────────────────────────────┐
│┌───────────────────────────────────┐│
││ Query Profiling Information ││
│└───────────────────────────────────┘│
└─────────────────────────────────────┘
EXPLAIN ANALYZE SELECT age, is_active, count(*) AS user_count FROM pgduckdb.public.data GROUP BY age, is_active
┌────────────────────────────────────────────────┐
│┌──────────────────────────────────────────────┐│
││ Total Time: 75.96s ││
│└──────────────────────────────────────────────┘│
└────────────────────────────────────────────────┘
┌───────────────────────────┐
│ QUERY │
│ ──────────────────── │
│ 0 Rows │
│ (0.00s) │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ EXPLAIN_ANALYZE │
│ ──────────────────── │
│ 0 Rows │
│ (0.00s) │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ HASH_GROUP_BY │
│ ──────────────────── │
│ Groups: │
│ #0 │
│ #1 │
│ │
│ Aggregates: │
│ count_star() │
│ │
│ 2000 Rows │
│ (9.36s) │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ PROJECTION │
│ ──────────────────── │
│ age │
│ is_active │
│ │
│ 100000000 Rows │
│ (0.06s) │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ TABLE_SCAN │
│ ──────────────────── │
│ Function: │
│ POSTGRES_SEQ_SCAN │
│ │
│ Projections: │
│ age │
│ is_active │
│ │
│ 100000000 Rows │
│ (66.46s) │
└───────────────────────────┘
Planning Time: 33.035 ms
JIT:
Functions: 1
Options: Inlining true, Optimization true, Expressions true, Deforming true
Timing: Generation 2.204 ms (Deform 0.000 ms), Inlining 0.000 ms, Optimization 0.000 ms, Emission 0.000 ms, Total 2.204 ms
Execution Time: 72970.699 ms (72.970699 seconds)
Well, I guess that results were consistent anyway, even though it is surprising. I thought maybe the more records I added, the closer DuckDB would get to Postgres analytics query performance, not farther.
What’s going on here?
Well, I think before we poo poo on pg_duckdb too much, let’s step back a moment. I personally don’t think that simply running DuckDB queries inside Postgres is the most useful thing that pg_duckdb provides.
According to DuckDB blog announcing this release we can do all sorts of interesting DuckDB “things” INSIDE Postgres.
Install extensions and read datasets like Iceberg, for example.
Write back out to a Lake House or some other cloud storage location from inside DuckDB
Think about this for a moment. How do people normally run some query inside Postgres and then pump the results to some CSV file in s3?
Most likely add something like Python with a bunch of logic to do this.
This sort of feature, pg_duckdb that is, is about innovation. It allows Data Engineers to design novel new ways of combining and processing data. This is a big deal because ALOT of people use Postgres.
Why is pg_duckdb so much slower than raw Postgres?
This is a good question, and you can find the answer on Reddit.

What I find unsurprisingly obvious is that in the blog announcement by DuckDB, seen below, seems to indicate, with a contrived TPC benchmark, the opposite of what we saw, that pg_duckdb is much faster than just Postgres.
“With pg_duckdb, you can use the DuckDB execution engine within PostgreSQL to work with data already stored there, and for some queries, this can result in a dramatic performance improvement …” - DuckDB
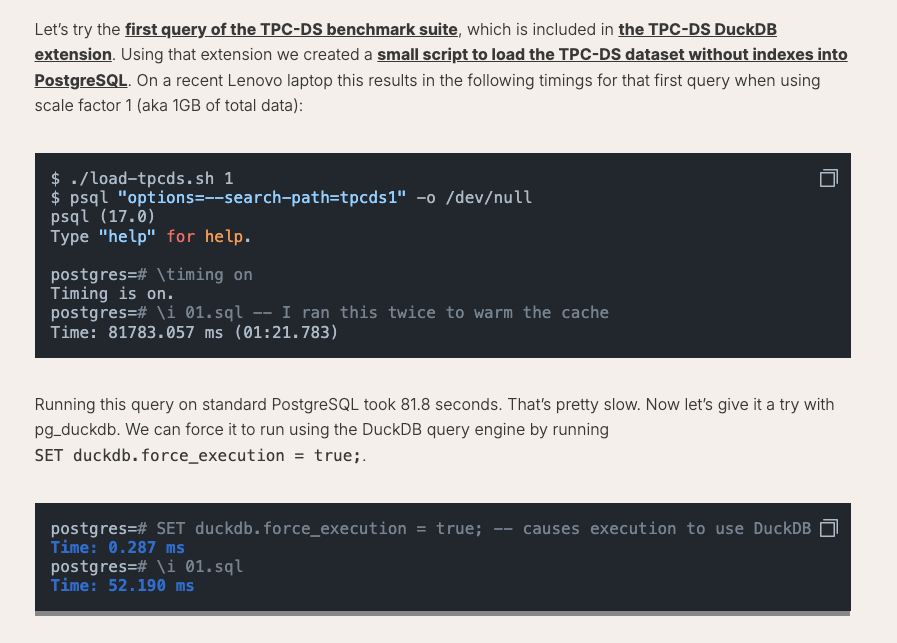
Notice something they mentioned? “ … without indexes …” Who the flip runs a TPC benchmark AGAINST Postgres and decides to do it with ZERO Postgres indexes?
Someone trying to cook the books, that’s who.
Don’t forget, DuckDB promised us something at the very beginning of their announcement.
“PostgreSQL is often used for analytics, even though it's not specifically designed for that purpose. This is because the data is readily available, making it easy to start. However, as the data volume grows and more complex analytical queries involving aggregation and grouping are needed, users often encounter limitations. This is where an analytical database engine like DuckDB comes to the rescue.” - MotherDuck
They literally told us that “as data volume grows” and “more complex analytical queries involving aggregation and grouping are needed” … “… this is where DuckDB comes to rescue.”
We saw the opposite. Sure, we could just have used DuckDB directly on our CSV dataset and got maybe a faster answer than Postgres. But remember, this commentary from DuckDB is INSIDE their announcement about pg_duckdb AND it gives the casual observer the impression that using DuckDB to query your Postgres data is MUCH FASTER than raw Postgres … which is clearly not the case.
What comes next?
Well, I can tell you what comes next, just like every other time I try to preach the truth to the misinformed and moldering masses. I can hear the hissing and spitting from here.
Doesn’t bother me. Been doing this long enough.
I see it as my calling to take the new and noteworthy, take them at their word, and then put their word through the wringer. See if they are telling us the WHOLE truth or maybe a few half-truths sprinkled in there.
Don’t get me wrong, pg_duckdb is an amazing creation that is going to breed some cool innovations and solutions in the future, no doubt about that.
But, you know, when everything is rainbows and glitter unicorns frolicking in the pastures, you can count on me to rain on that parade.
Thanks for the dedication to test the new shiny tool. We need people like you who is skeptical of enterprise blog posts and test yourself using your own platform. Im sure they are happy with the feedback and more people are aware of the new integration.
Awesome article, thoroughly enjoyed it. Thank you