

Escaping the Agentic Token Tax: Replacing Claude Code or Copilot with OpenCode
opencode + ollama for the win.


I’m going to tell your mom. I’m going to do it. You can’t stop me. And you, Grandma, for that matter. I’m calling them right now, like now. You’re an addict; you have to stop. Someone has to stop you. Might as well be me.
It started out harmless, didn’t it?
But now things have changed, you’re hooked on The Vibes. They got their claws in you. Look at yourself. You should be ashamed. Sitting high on your Macbook Tower all these years, God’s programming gift to humankind, those LLMs came along, you were enamored, Gastown and all, those tasty token morsels.
More tokens, bro, just a few more tokens, and you will finally become Neo and enter the Matrix.

Ok, on a serious note, if I have one in my body, what’s the big deal? Why are the token addicts crying foul and howling at the moon?
Well, the signs are there; people from Fortune to LinkedIn are complaining about it.


What I’m still trying to figure out is how the collective “we” didn’t see this coming. Is there anything more classic in the marketing of drugs and AI, since the beginning of time, than to get ‘em hooked and then do the old bait and switch on pricing?
Heck, I don’t know if the pricing increases even matter. I mean, if the C-Suite wants to invest in AI, then who really knows whether the whole pricing strategy and increase are a big deal? It’s hard to turn the ship around once it has sailed.
Thanks to Delta for sponsoring this newsletter! I use Delta Lake daily, and I believe it represents the future of Data Engineering. Content like this would not be possible without their support. Check out their website below.

If you live under a rock and don’t know what I’m talking about, basically …
The era of heavily subsidized, flat-rate AI pricing has ended as both GitHub Copilot
and Anthropic transition to token-based or usage-based billing.
Users are facing significant bill increases and credit depletion due to the
high token cost of long, autonomous coding tasks.There are probably multiple factors behind the “why” folk are having second thoughts about token prices.
Cost
Risk (general)
Lock-In
The future
Good judgement
Privacy
Freedom
The same leaders who’ve been proud of escaping “vendor lock-in” and other sorts of evils are the ones who recently woke up to the news that their dev token costs/bills might go through the roof, and are now crying wolf. Ironic.
I mean, hindsight is 20-20, but it wasn’t rocket science to figure out that something funny was going to happen at some point. Once you have the masses drinking from the AI teats, money talks ya know.
Also, I’m saying you have to abandon, or should abandon, tools like CoPilot or Claude Code because you’re scared, and overreact. There are many obvious, viable ways to reduce token usage that require little to no effort.
Review CLAUDE.MD files and context
Implement tools like Caveman
Get better at prompting
Adjust context
The truth is, I have great faith in the indelible human spirit. We find solutions to most problems, including AI token maxxing. Everyone has been sloppy because we were allowed to be. If we “have to” be more judicious, we can be.
Open-source alternatives to break free from token prison.
All that being said, in the classic white hat hacker, open source spirit that never dies … there is, and has been for a while, a strong undercurrent to have total control, total free control. The question is, can it be reasonably achieved?
Can we find open-source alternatives we can run locally on our machines that deliver reasonable output and performance?
Most people are not going to go buy a Mac mini just to run a model for themselves. They will just pay the money to the SaaS Lords and move on. There are also other important questions to ask.
Once we’re used to Claude Code and Anthropic speeds (from prompt to result), can we achieve them locally with any setup, or anything even close?
We used to handroll code a few years ago. Can we be patient enough to wait 30 seconds to a minute for a response?
Something tells me that in the Instagram and Amazon life we live, once we’ve tasted that token fruit upon our digital tongues, it’s hard to find something else “good enough,” when it actually is good enough.
Will the code or systems design output meet our expectations? Will it take 30 seconds longer than we want, making it feel like years by comparison? Is the setup and installation overly burdensome?
As much as I would like to believe the best, the truth is humans are fairly predictable.
Starting with OpenCode.
So, let’s start our possibly long and forelorn journey down the winding road of token freedom. Like Beowulf of old, we seek new lands and are ready to battle new monsters. I don’t expect this adventure to be free from heartache, but I’m sure we will learn something along the way.
First things first.
I’m going to simplify my approach to this and break it up into two different logical pieces.
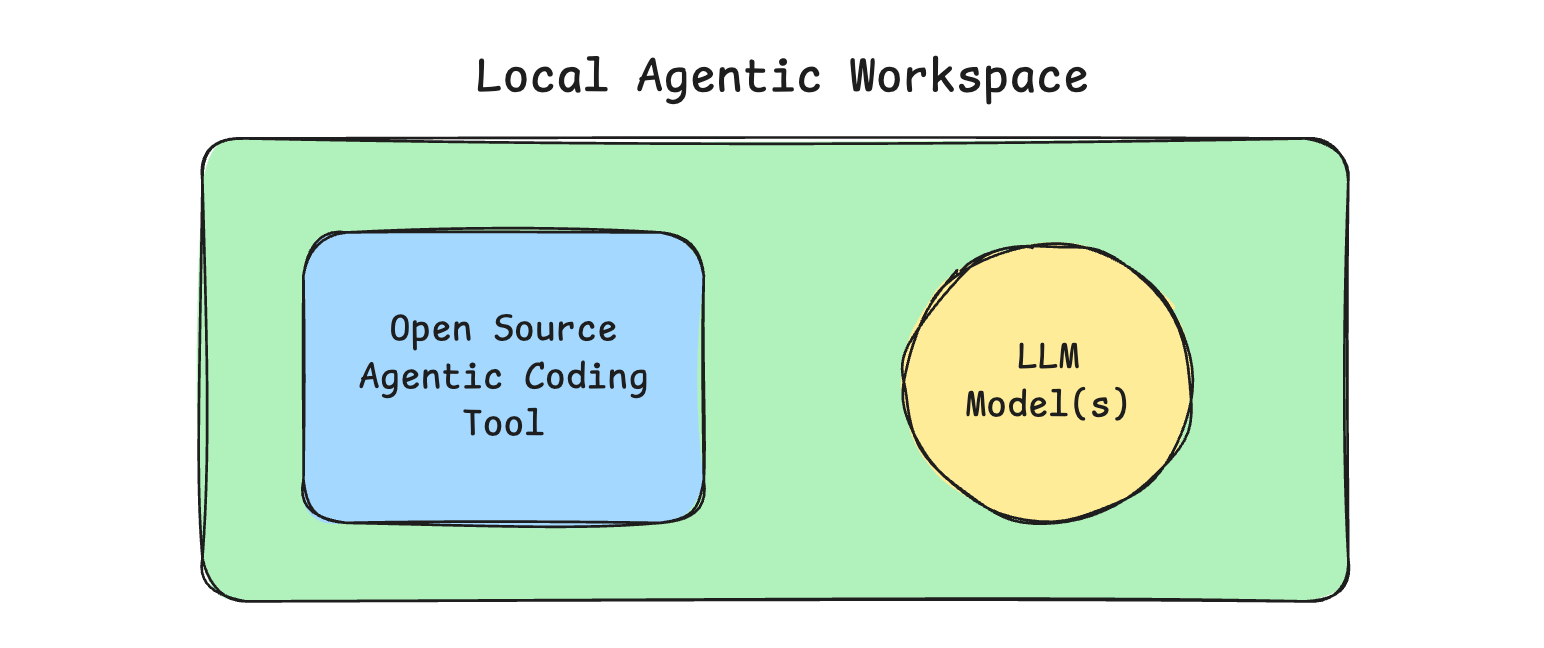
Think about it like your Claude Code or GitHub CoPilot setup. You have some “agentic tool” on your machine that you probably interact with. Then, you are using some remote LLM model via some API from Anthropic, OpenAI, whatever… these two pieces combined allow you to Gastown your way to glory.
You can use what you want, but let’s pick the cream of the crop in open source, that is, OpenCode.

“What is OpenCode? OpenCode is an open source agent that helps you write code in your terminal, IDE, or desktop.” - source
So, let’s get to it. Easy enough. Find installation instructions for yourself here.
The rest is smooth enough, you’ll probably wonder why you didn’t do this a year ago.
Ok, so this is kind of deceptive up front. You’ve only fought half the battle at this point. By default, OpenCode will just look at your environment and find whatever default model it can find that you’re probably already using, things like OPENAI_API_KEY, ANTHROPIC_API_KEY.
Sure, we are now using an open-source coding agent/tool, but if we are trying to break free from our token addictions… then we still need to find a small, runnable, local model to wire into OpenCode.
If you want to understand more about using different LLMs with OpenCode, you can read their docs on the subject here.
Small language models for coding tasks.
Enter the Rabbit Hole. What hole? The hole of the endless Reddit threads on what is the best “small language model” you can use locally for decent results. This is where personality traits and life outlook come into play.
Everyone works on different tasks, cares about different things, and will find some models better than others for various reasons.


I’m not here to jump into this debate on which SLM is the best for coding. It changes all the time and will continue to change, hopefully getting better and better as time goes on. It’s simply hard to compete with companies like OpenAI or Anthropic, backed by the Deep State, Bigfoot, Aliens, and billions of dollars.
So, I want to find something that is “good enough” in basic coding tasks. The idea being, in the real world, we could mix this setup with our Token Masters, say start out with OpenCode and some SLM, get the grunt work done, and maybe fine-tune with OpenAI or Anthropic.
Back to the problem at hand, let’s pick an SLM and get it hooked up to our local OpenCode.
Ok, so in a somewhat satirical twist of fate, the once “don’t be evil” Google, according to the internet, is going to save our bacon on this one.

“Gemma is Google’s family of free and open small language models (SLMs). They’re built from the same technology as the Gemini family of large language models (LLMs) and are considered “lightweight” versions of Gemini.” - source
It just so happens those little blighters fine-tuned a coding-specific version.

So, I think we just give this CodeGemma 7B a try, wire it up to OpenCode, and let ‘er rip.
This might seem a little strange, but the easiest way to get CodeGemma onto our local machine and running is to use Ollama. I’ve used Ollama plenty in the past. It’s easy to get.
ollama run codegemmaSo we have CodeGemma on our machine, thanks to Ollama. Don’t you love open source? Now we can hopefully configure our OpenCode to run CodeGemma and see whether we shed tears of joy or sorrow.
Next, we need a little JSON config magic to point our OpenCode to our Ollama Gemma model. Mouthfull.
Next, we do a little vim’ing.
>> ~/.config/opencode/opencode.json
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"ollama": {
"npm": "@ai-sdk/openai-compatible",
"options": {
"baseURL": "http://localhost:11434/v1"
},
"models": {
"codegemma:7b": {
"name": "CodeGemma 7B"
}
}
}
},
"model": "ollama/codegemma:7b"
}Now we can double-check what model OpenCode is using.
opencode
/modelDoing a thing.
Well, we've done what we set out to do today. Who do you feel? Freedom? Anarchy? Rebel? Rich? Wow, a little bit of work and swimming against the stream, we have unshackled ourselves from the token mongers. Better sleep with one eye open tonight.
I mean, the real question is … will it perform?
Beauty is in the eye of the beholder. I have no idea; maybe it will be too slow or just produce horrible output. Maybe it can’t do specific Data Engineering tasks. I don’t know.
Let’s just do something simplistic.
Have it read an open-source Divvy Bike Trip CSV file, and use maybe DuckDB or Polars to do some analytics, maybe a simple groupBy and aggregate.
Here we go.
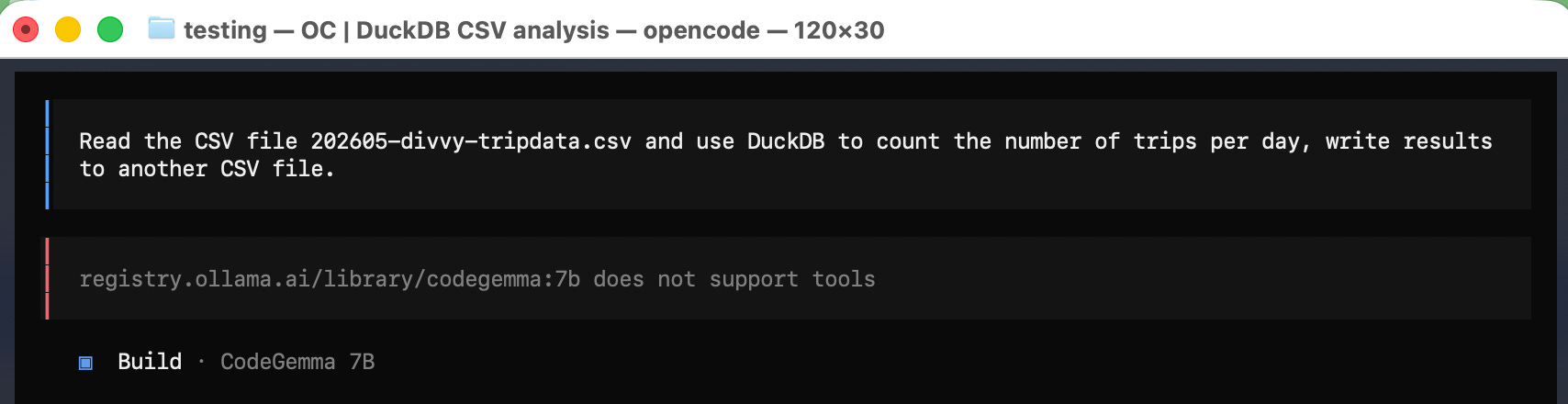
So, we are learning something: one, we can fail immediately; two, apparently, all free open-source models are not created equal. I’m no savant of running local models; apparently, this GemmaCode doesn’t support tool calling, aka doesn’t expose the methods that OpenCode would need for integration.
Maybe that is something we could figure out and tweak, but look, I’m approaching this from a caveman perspective. I want an easy setup that anyone can tackle.
Anywho, I am cornfeed and Midwest-raised, and I don’t quit easily. Onto the next model. Qwen, my love.
ollama pull qwen2.5-coder:7b-instructOf course, we need to update that config file.
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"ollama": {
"npm": "@ai-sdk/openai-compatible",
"options": {
"baseURL": "http://localhost:11434/v1"
},
"models": {
"qwen2.5-coder:7b-instruct": {
"name": "Qwen 2.5 Coder 7B"
}
}
}
},
"model": "ollama/qwen2.5-coder:7b-instruct"
}Ok, let’s try that data pipeline again with Qwen.
Make a Python file that uses DuckDB to read the CSV file
202605-divvy-tripdata.csv, count the number of trips per day,
write results to another CSV file. So count the
column ride_id and group by started_at cast to a date.Then I left and had supper with the family. Why not. Isn’t that the point of Agentic Coding? You just tell the Agent to do a thing, leave and do other things, then come back later to check on that thing?
All I know is when I got back from supper, it still wasn’t done. Ain’t not Anthropic, told you so. Look, that little stinker is burning 30% of my CPU.

I mean, I’m using what I consider a pretty standard MacBook.

What in Thor’s Beard? 33 Minutes for that task. That ain’t going to work, but I guess if you’re like Tiny Tim peddling the streets for tokens, time is of little importance.
Also, what do I know about tools and OpenCode? It didn’t actually write the file. I just spit the Python out.
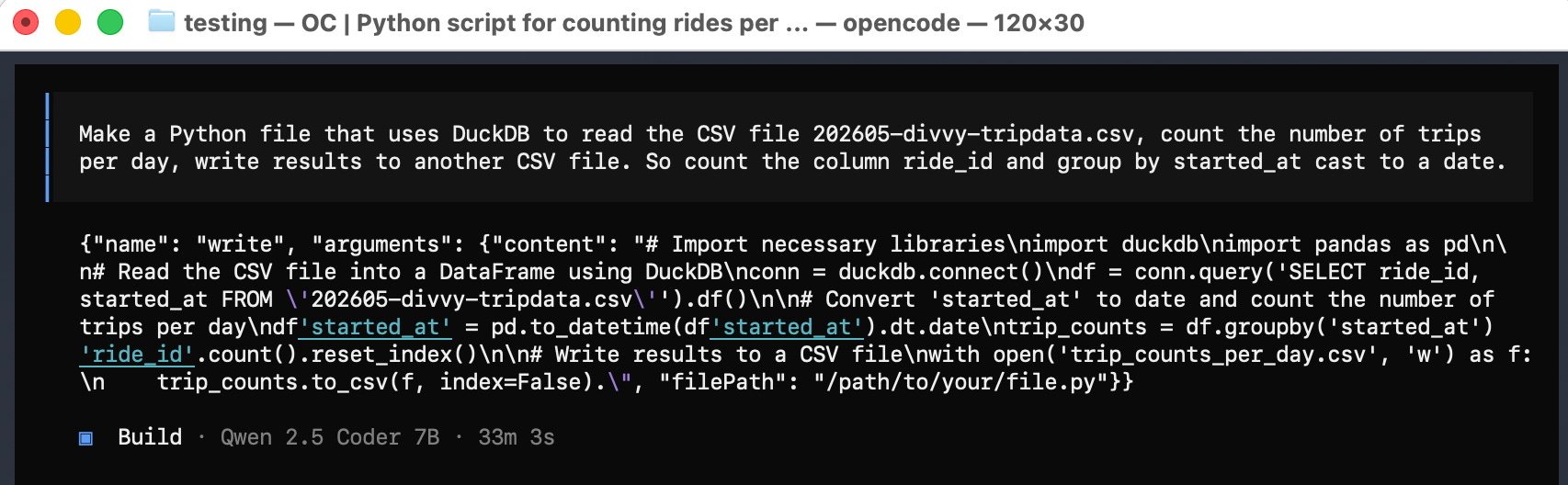
Before I start complaining about how crap this all is, let’s see if this code actually works. We will put it into a Python file ourselves and run it. Clearly, it’s tool calling ability, you can see it trying to write a Python file … is a little wonky, maybe stuff you can get working?
Off the bat, I can see its Python skills are a little sub-par.
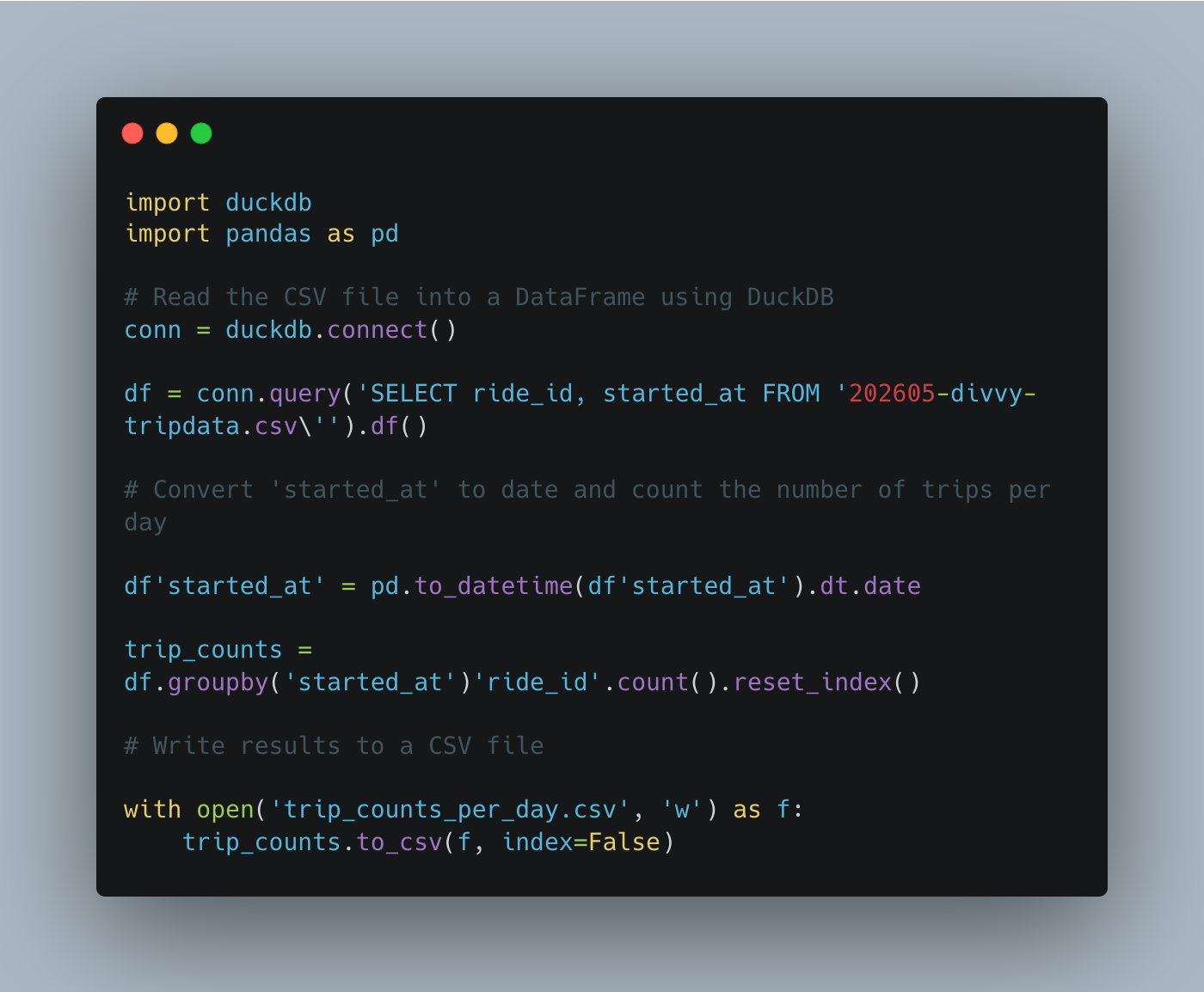
What’s that saying your Grandma was always carrying on about? You get what you pay for??
SQL query has wrong “ vs ‘
df column referenced incorrectly, needs [] in a few spots
Fixed code, by myself, that is, looks like this and runs great, outputs as I asked.
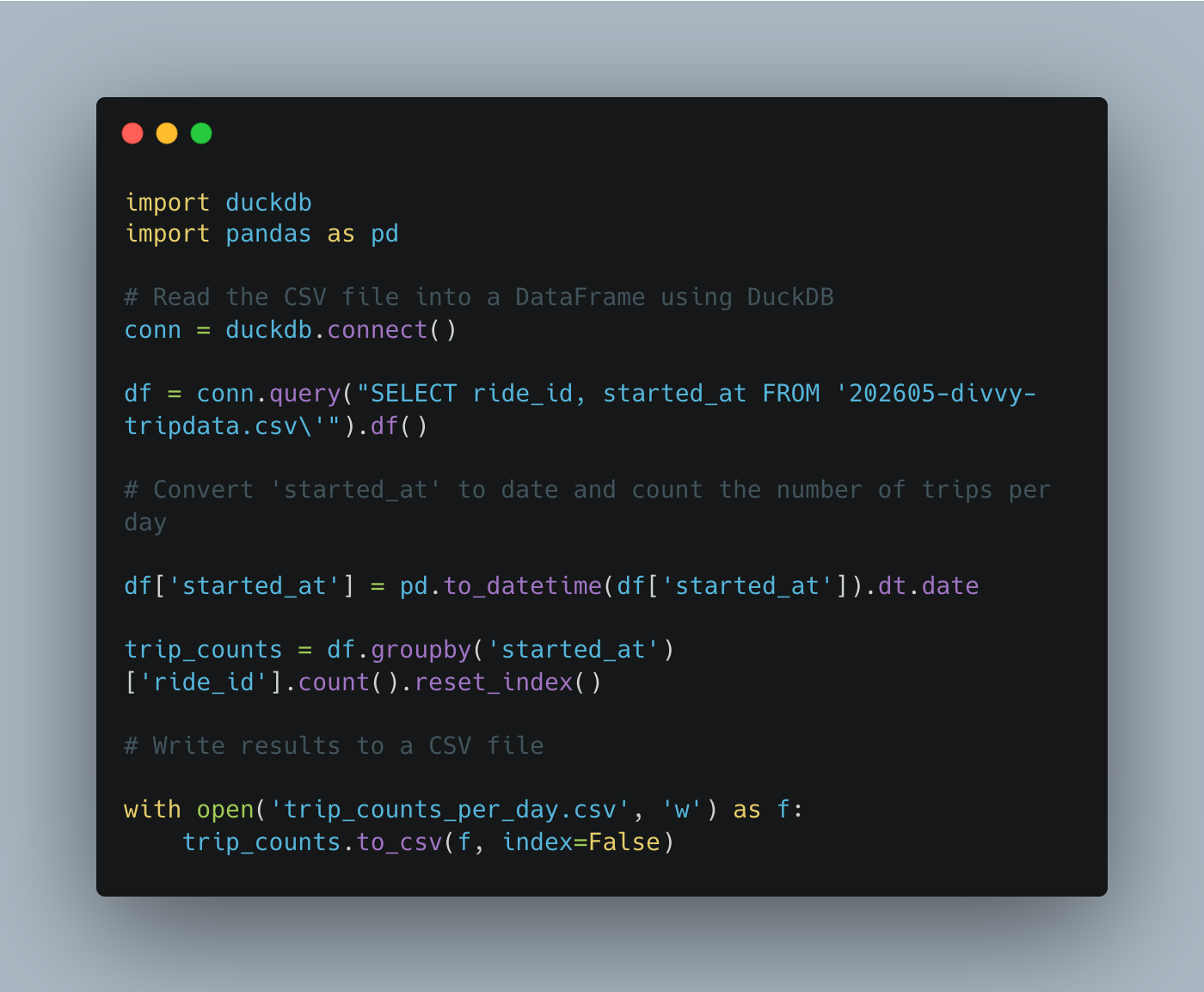
Results.
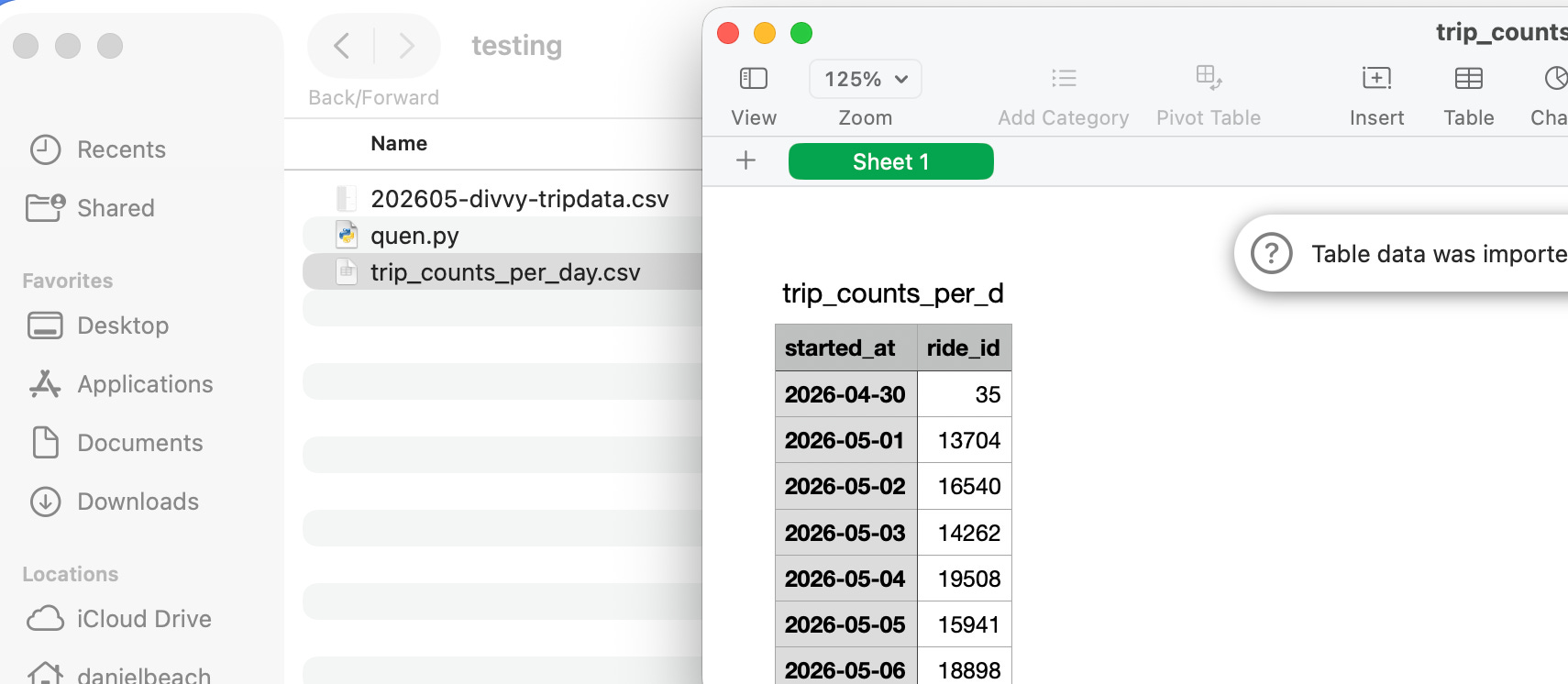
Ok, so clearly, while my local model is mostly, well, only using CPU to solve these problems, this thing is going to crawl. Now you know why crypto bros have been ordering GPUs for years now. Also, you now know why things like Claude Code, combined with some Anthropic model behind an API, are so compelling, and also why those companies…
Hire smart people
Burn a lot of cash
Suck up all our groundwater into data centers
Use all our electricity
Takes some of that there “gumption” like we call it around here, for you to send some massive context over the wire and across the country, and get back over that same wire … a correct answer.
So … yeah …
To be honest, I’m running out of gumption. Don’t tell anyone. Just give me my basket of nice hot tokens and let me snack on Claude Code. If you want me to reduce token costs, I will just sprinkle some caveman on it, improve my prompts, and cut out all unnecessary context that is hidden around here and there.
Give em’ the money, give me my tokens.
See, what did I tell you? I figured we could get something working, break free from the rest of the lemmings running over the AI cliff. Pretend we are rebels and run our own local model.
Life isn’t a movie; you haven’t figured that out yet? No free lunch? Never heard of that either?
I’m sure there are 16 things I did wrong that I'll be told about; the Reddit rabble will probably figure it out. All you have to do is meet them under the old oak tree at midnight and sign your name in blood with a stick. Who knows.
More hardware, more GPU, better configs, I don’t know.
Just Google it a little, and you will see what I mean. There are already a million YouTube videos and other articles telling you they have cracked the code for the perfect, snappy model that performs best.
Good luck.
This is something I want to return to, maybe in a Part 2, do a little experimenting and research, see if we can find a model that gives good results on a decent-sized machine like this. Maybe it isn’t possible yet, who knows.
Yeah, I know we can solve lots of compute problems with more RAM, CPU, GPU … but not only did I want to see if it was/is possible to break free from the token tax, which, yes, it is possible, but what is it like for the average Dev who wants to do that?
It appears not to be THAT easy. Yeah, I didn’t spend much time on it, or trying to solve it yet, that can come later, I just wanted to dip my toes in the water and see what the world had in store for me.
Hey Dan! Really cool to see you trying out local AI. I was lucky enough to see the writing on the wall about a month ago, so I’ve been tinkering with local for a little bit.
First, if I’m not mistaken about your MacBook specs, you probably have unified memory, meaning you can definitely be using a larger model. Google actually released the Gemma 4 family of models a couple months back, which includes a 12B, 26B, and 31B variant. The whole family can call tools, and they do okay at coding, but not amazing. They’re also Apache 2.0 licensed.
Second recommendation is to try a larger Qwen model, if you can. I use 3.6 35B A3B, but that may be a bit large for a 24 GB memory size.
Speaking of size — use quantization to let you run more models. You can quantize from full model weights down to Q8 with almost no quality loss. Most local users quantize down to Q4 (myself included — that’s how I run the 35B A3B model in my 24 GB GPU). Google actually released versions of their Gemma 4 models that handle quantization a bit better just this week — “Quantization Aware Training”, or QAT. Worth considering.
Lots of other ways to approach this depending on how in depth you want to go: choose a model serving backend that allows more configuration of model parameters than Ollama, leaner coding agent frameworks (e.g., Pi, at pi.dev; more control over system prompt than opencode, but far less “batteries included”), context management tools, more guardrails to optimize the performance of these smaller models, the list goes on. And of course, leverage agent skills, rules, etc.
Definitely not saying it will match cloud models by any means — good to stay realistic! Happy to talk more if you’d like.