

Exploring NULL(s)
The little data devils


Is there anything more insidious roaming about the world of Data Engineering than those little buggers … the NULLs? I mean who even thinks about NULLs? We have much bigger problems to solve, more important things you know? We have pipelines to build, SQL to write, Python to wrangle, and Sprints to finish.
NULLs. Pissh. Who cares about NULLs?
I have this feeling down deep in my tummy that NULLs are probably one of the first things you stumble over when starting your Data journey, and also one of the last things you stub your toe on before you blackout at the end of your Data career and are carried off into the great blue yonder.
So simple, yet not so simple.
Thanks to Delta for sponsoring this newsletter! I personally use Delta Lake on a daily basis, and I believe this technology represents the future of Data Engineering. Check out their website below.

I think it’s high time we take these little NULL devils behind the woodshed and give ‘em the what for.
Exploring NULLs with Delta Lake and PySpark
It’s hard to know where to start when thinking about a topic like NULLs, since they have become the thing of everyday commonplace in the data landscape, I mean you hardly even notice them anymore.
Yet NULLs are important, if ignored they can cause things to go bump in the night. How we think about them, how to treat them, and coding with the acknowledgment of their existence.
I think it’s also true that learning what we can about dealing with NULLs is a plate best served piping hot. Piping hot PySpark that is.
So today that is what we shall do, simply serve a platter of NULLs to the hungry and veracious appetite of our PySpark monsters, let them chomp and crunch, see what comes out the other side.
NULLs in data.
Sometimes I wander around aimlessly looking for something new and exciting, if I don’t find something, I just pick up something old and blow the dust off it. See what I’ve forgotten and what sparks my interest.
Let’s just write some Spark … with Delta Lake involved and see what happens, shall we?
Maybe we are working on a hobbits project.

In the high volume of data age we live in, it’s super common to end up with random NULLs from incoming data. In our case, we have a name that is NULL, as well as a home.
So, the question is, are NULLs a problem? I guess the answer to that depends on what we try to do with the data, and how the NULLs will affect those operations.
What if we want to count the number of hobbits by home?

Interesting, that might be nice depending on your perspective, but it also shows the sneakiness of NULLS and the WHERE and WHAT you are acting on.
Because we GROUPED BY home, it’s nice we didn’t lose that NULL record.
But, you will notice we DID LOSE (depending on how you deal with NULL) one record from the Shire, because the name was NULL.
This isn’t unexpected if you think about it, you can’t count NULL.
It does make you wonder though, how many people actually think that hard about their operations if what would happen with NULLs? Very few.
NULL with aggregations.
To be more clear, and depending on how familiar you are with NULLs in different types of aggregations, take a look at this code.

Here are the results of the two Dataframes.

SUM: The
sumfunction ignoresNULLvalues and only sums the non-NULL values.AVG: The
avgfunction calculates the average only based on the non-NULL values.COUNT: The
countfunction with a column argument only counts non-NULL values, whilecount("*")counts all rows, including those withNULLvalues.
This last piece of information with how COUNT() reacts to nulls depending on your input, and what you are trying to do, can surprise many unsuspecting Data Engineers.
Nulls in methods and functions.
Of course, aggregations aren’t the only things that can be affected by NULLs when doing Data Engineering, your nice little methods you write and unit test, which you sprinkle throughout your ETL code are not impervious either.
In your precious PySpark for example, when functions are applied to
NULLvalues, they CANreturnNULL. We can see this in the following example using theconcatfunction.


It might be obvious what happened while we are talking about NULLs, but when you are in the middle of the Sprint, pumping out some code, and you aren’t even thinking about NULLs … when they probably exist, you should code defensively.
And it gets worse.
NULLs with filters.
Just when you thought you were safe, pumping out some dataset real quicklike for someone because you said in standup that would be no problem and super easy … then you end up looking like a hobbit because you didn’t think about NULLs.
Let's see how standard equality (==) in PySpark reacts when NULL values are involved in comparisons. Specifically, we'll see that comparing NULL with any value using == does not return TRUE or FALSE, but rather NULL.
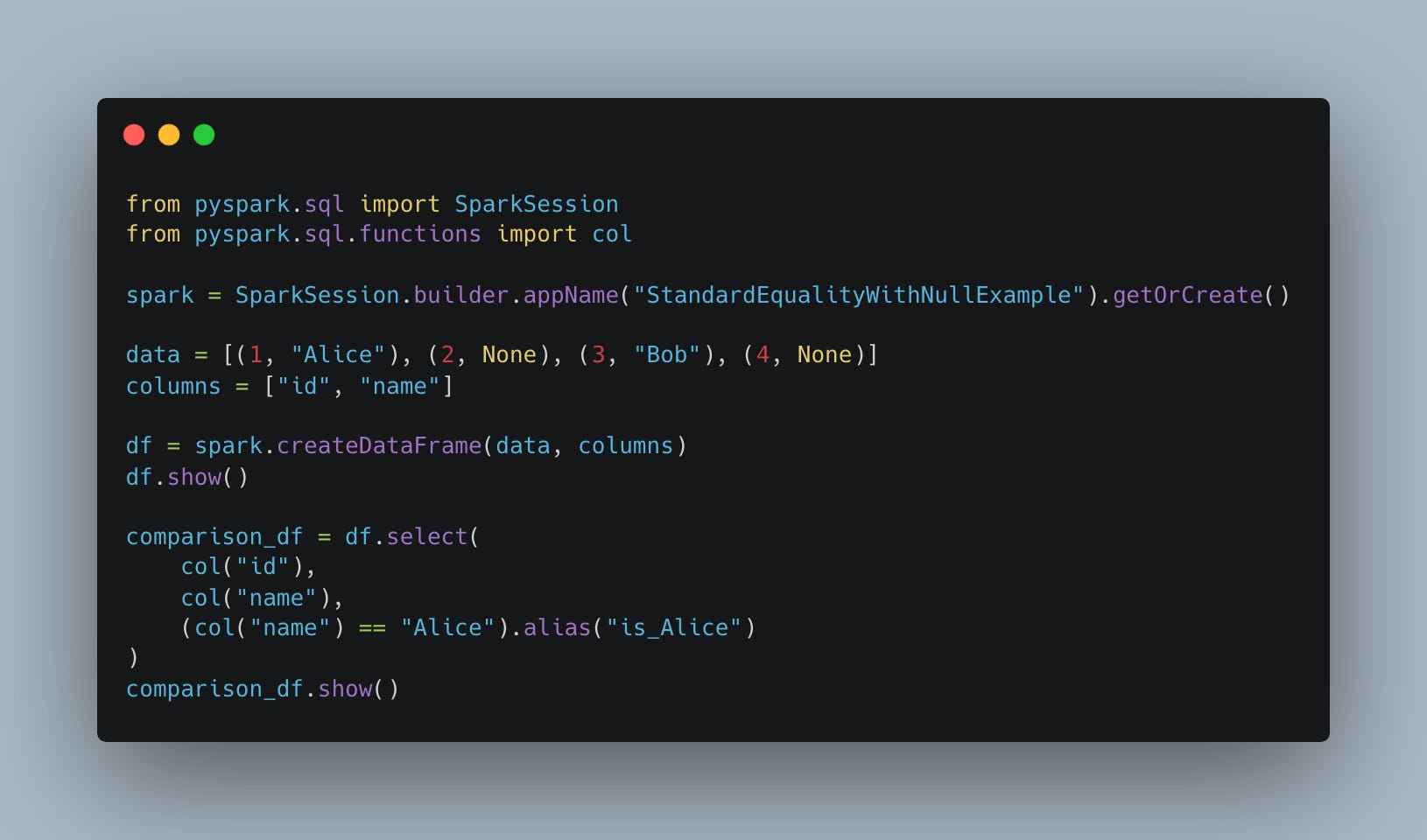

Interesting if you’re not looking for it. Notice how the is_Alice comparison results in some NULL values, NOT false … like some might expect.
Conclusion.
I don’t know about you, but I rarely deal with NULLs like I should … upfront … knowing they are littered through all the datasets we touch, with rare exceptions.
It can feel tedious and boring to pretend and DEFEND against NULLs in all the data we deal with … it almost feels overkill. Yet, we have to acknowledge the reality of not dealing with them … not thinking about the consequences.
Maybe we should deal with them when someone yells at us about some result not being correct, realizing our sins, and then fixing it. Oh well.