


This is another classic, isn't it? Some data questions have had folk spitting and fighting for nearly a few decades now. Funny, how nothing really changes, even in the age of AI.
Technology has undergone significant shifts from the days of SSIS to DBT. But, I still see the exact same topics being discussed and poked at all these years later. And I mean literally the same topics.
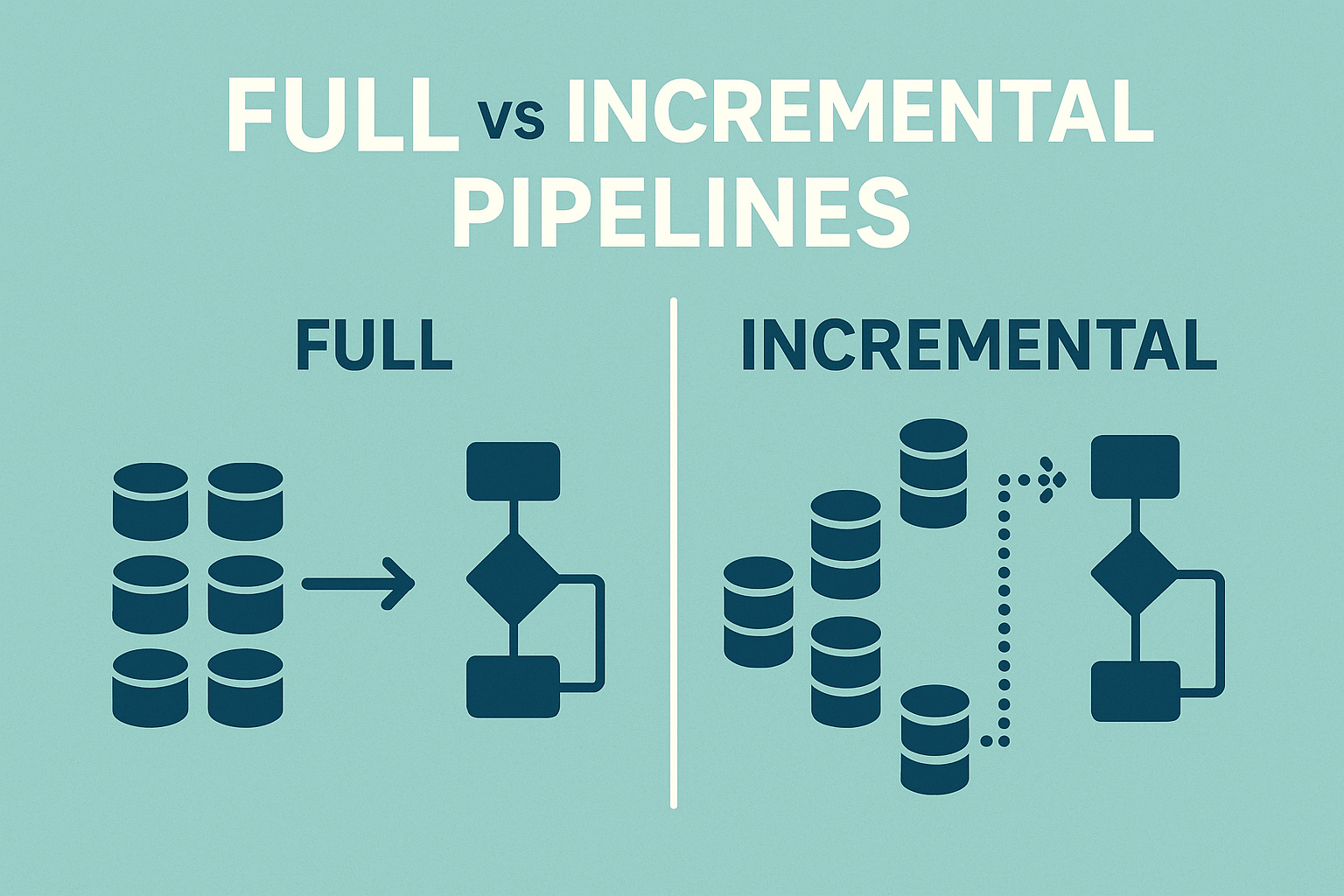
Today, we shall peel back the rotting old onion 🧅 and talk about Full vs Incremental data loads.
This topic can come in various forms, often under the guise of full historical loads vs something else, such as smaller incremental loads.
TDLR: Full historical loads (done well) can be the norm under medium-sized data sizes. At scale, separate pipelines will be required.
Thanks to Delta for sponsoring this newsletter! I personally use Delta Lake on a daily basis, and I believe this technology represents the future of Data Engineering. Content like this would not be possible without their support. Check out their website below.

Concepts of Full vs Incremental Loads.
I know there are probably some avocado toast-eating Gen-Z suckers out there who are Data Engineering script kiddies, so we should probably go back to kindergarten and learn the basics.
When writing data pipelines that contain data loads of some sort, you really have two options, whether you know it or not.
- Full Historical loads
- Incremental (recent) loads(This begs the question of what is CDC (change data capture) … full or incremental, or does this depend on the implementation??)
There really is no in-between. Sure, you might use a tool, a SaaS thingy-ma-bob to obfuscate the complexity. But that doesn't change the fact that you're doing one of the two things above.
Consider this: it's a very annoying problem to deal with because the proper answer is highly dependent on the business and other outside factors.
How do you process only new records?
How far do you “look back?”
Can you afford the do full historical loads?
What are the performance implications?
The cost?
How does the data source act?These are questions and answers that change with every single data pipeline.
We have data sources and data sinks. This never changes. What changed is HOW we sync those two separate data sets.
Is the data “fact” like in nature? Does it ever change, or is it set in stone? Perhaps the data is “dimensional” in nature and changes slowly or quickly.
These different use cases require totally different approaches, and sometimes different tools. CDC vendors have been hawking their wares in the open air for a few decades now, yet we still write data pipelines manually to push and pull data between systems.
Why is that?
Clearly, the topic is more complex than simply “plug in this connector,” and the data will not magically sync perfectly between the systems without further manipulation.
If it were that easy, Data Engineers wouldn’t exist.
Example. Concepts in action.
While this topic is fresh on the mind, let's just do a simple example of a full and incremental pipeline, so we can explore these ideas more.
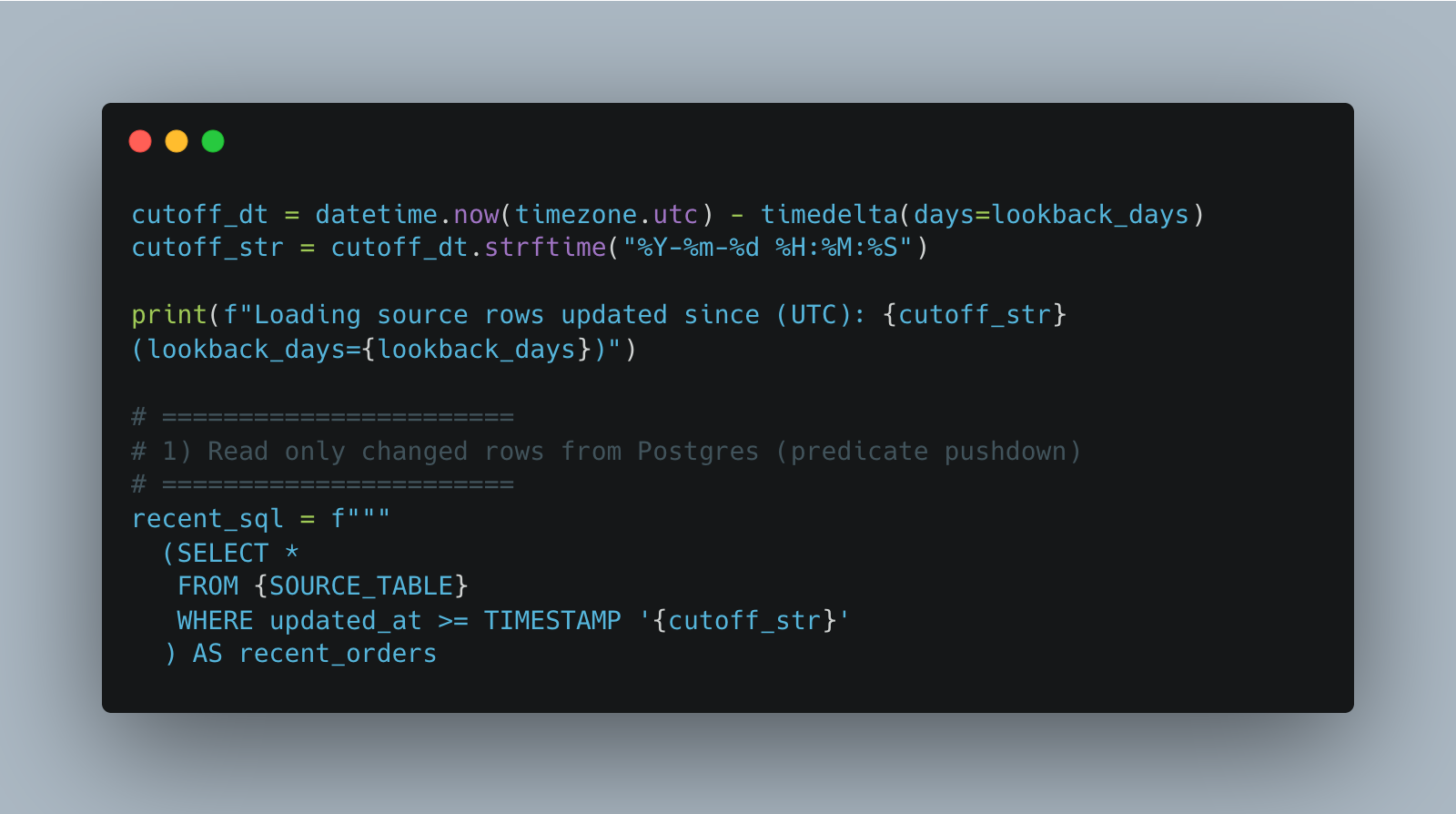
Here’s a straightforward PySpark + Delta Lake example that pulls only the last 2 days of updated orders from Postgres and upserts them into a Delta table with MERGE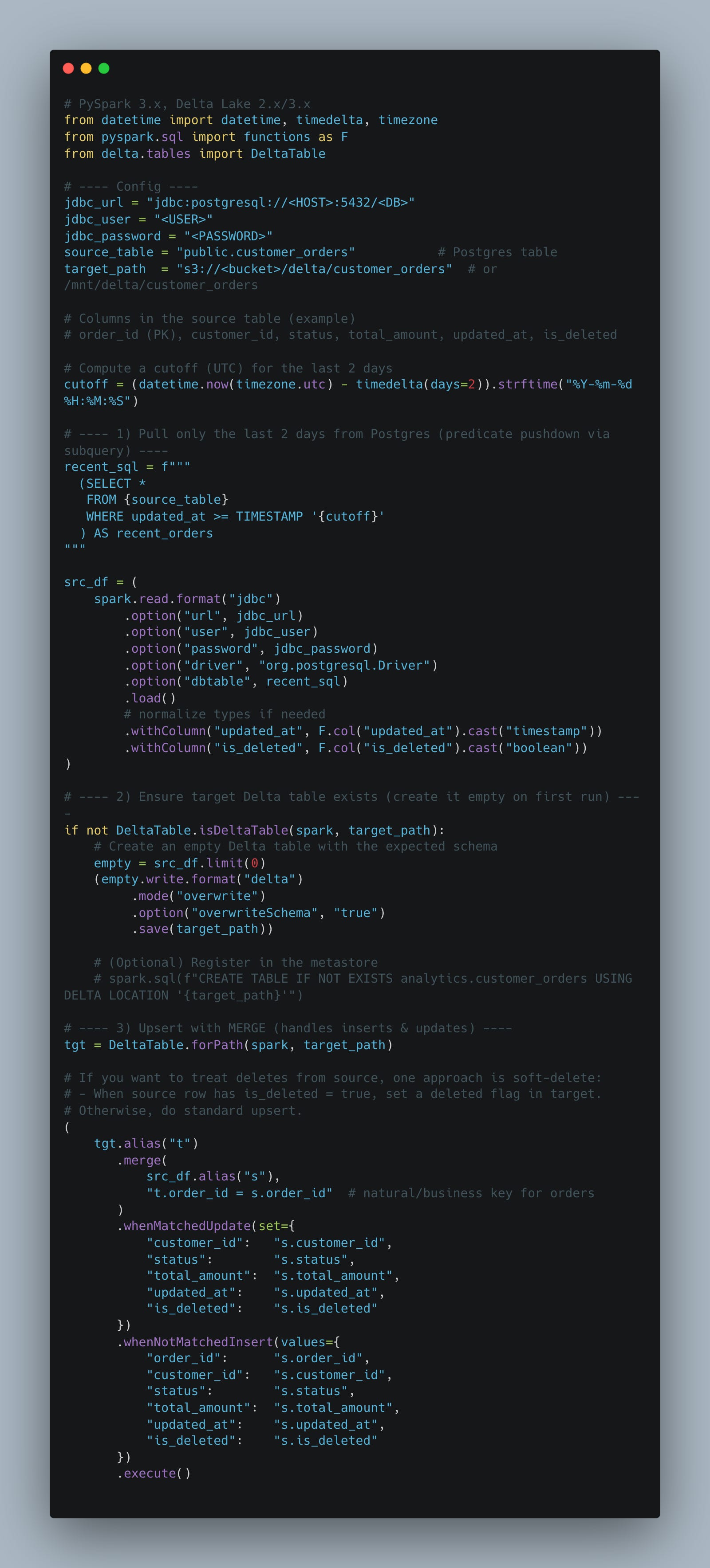
I would call this a very standard practice for an incremental load, which probably has been writing a million times over the last 10 years by a million different people.
Yet, clearly, for those in the know, what looks on the surface to be totally normal has a wide variety of gotcha’s and holes.
What if the pipeline itself doesn’t run (for whatever reason) for a few days?
What if someone asks for a historical load?
What if the source blips without us knowing because of an upgrade or problem and we aren’t notified?
What if the source gets a dump of data?
For the 95% of the time, this query and pipeline would probably do the job just fine, it’s the other 5% of the time that causes the problems and wreaks havoc on data teams and downstream consumers that depend on this information.
Whats the answer?
We can’t always simply default to full historical loads every single time. Or can we?
I mean in theory, no matter the technology, it is easy enough in most cases to simply gulp down all the data and do a pump and dump from the source into the target.
Of course, depending on situation, the pipeline will slow to a crawl and the costs will skyrocket.
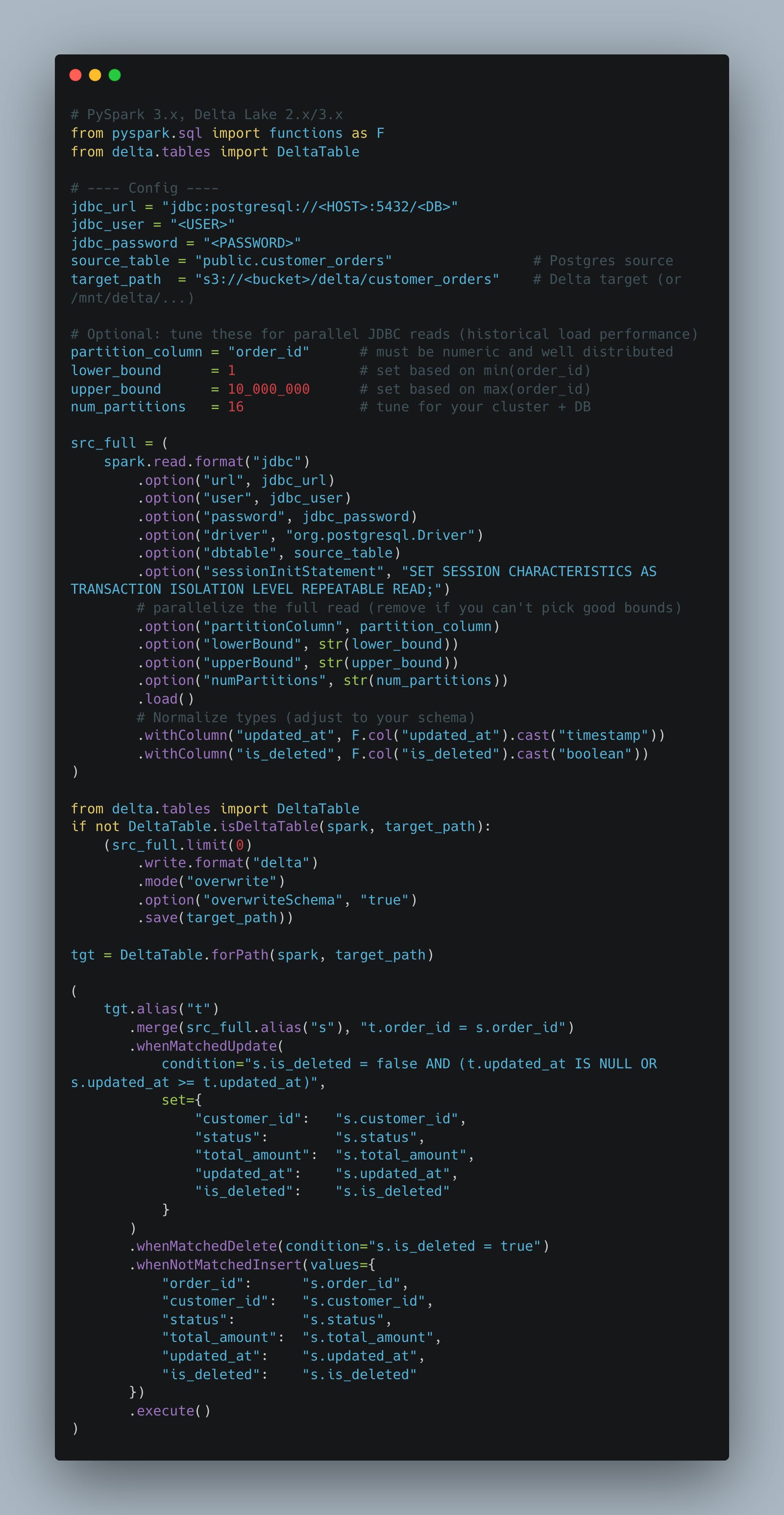
If we are running Spark and the data is less than a TB, it probably wouldn’t make much difference, but it does feel kinda icky doesn’t it?
I mean if our boss got mad at us and told us to stop doing that, only load the new records and stop spending all that money, we could do something equally as acky, but would do what they asked.
Simply get ALL the primary keys from each table and compare, pulling only new records in.
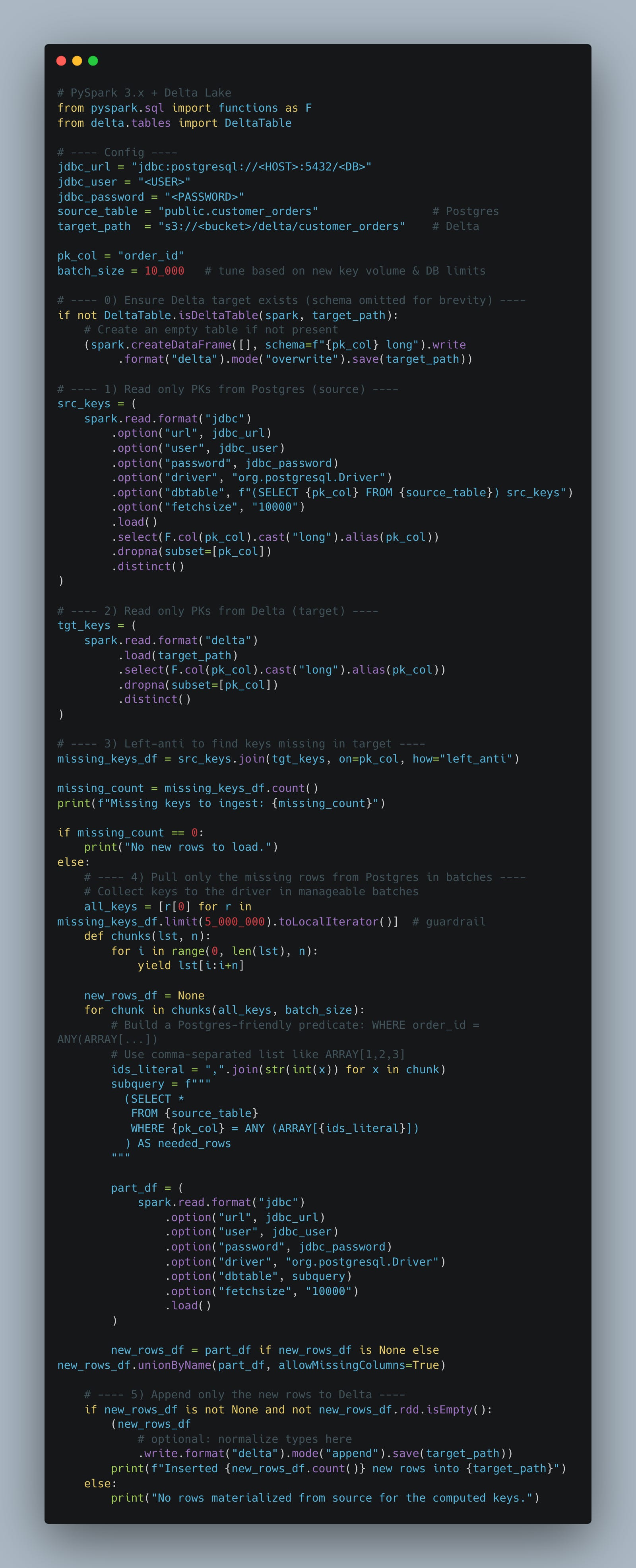
You tell me, are we just picking between a few bad options, maybe there is no good options. We should just buy some SaaS data connector that obfuscates the entire thing for us, black magic could be the path to walk down after all.
Could we find what works best for us?
Maybe, the best answer is to just to understand our data sources better, and strike a balance where our pipeline doesn’t incremental loads, but gives us some configurational option to pull pass amounts of data as needed.
It could be the best option, no?
Herein lays the question that has plagued us for decades, and indicates why Data Engineers still write pipelines for syncing data between source and target, after all these decades and promises of magic SaaS that will sync all the data for us.I guess we could update our original 2 day pull with the following configuration and move on with life. Maybe we go talk the business or data source owner and ask the worst case scenario they’ve had for late data arrival or something along those lines.
I wish the answers were simple, but we live in a messy data world and it just never works that way.
Some datasets maybe are small enough we do historical pulls every day.
Some datasets are too large and get a 7 day pull at most
Some are massive and only get a day or two
I’ve even seen circumstances and large datasets (50 million records a day), where maybe a 3-6 day pull is done to ensure no missing records, and a separate once a week pipeline runs to do a 30 day comparison of primary keys to pull in any missing records.
It probably depends on a number of factors.
The business appetite for completeness
The business appetite for spending money on compute
How reliable the data source is
How much the pipelines break and go stale
Should we give in to the SaaS?
Heck, maybe we should stop fighting and kicking against the goad like Paul. Databricks gives us “auto cdc” with tools like DLT.

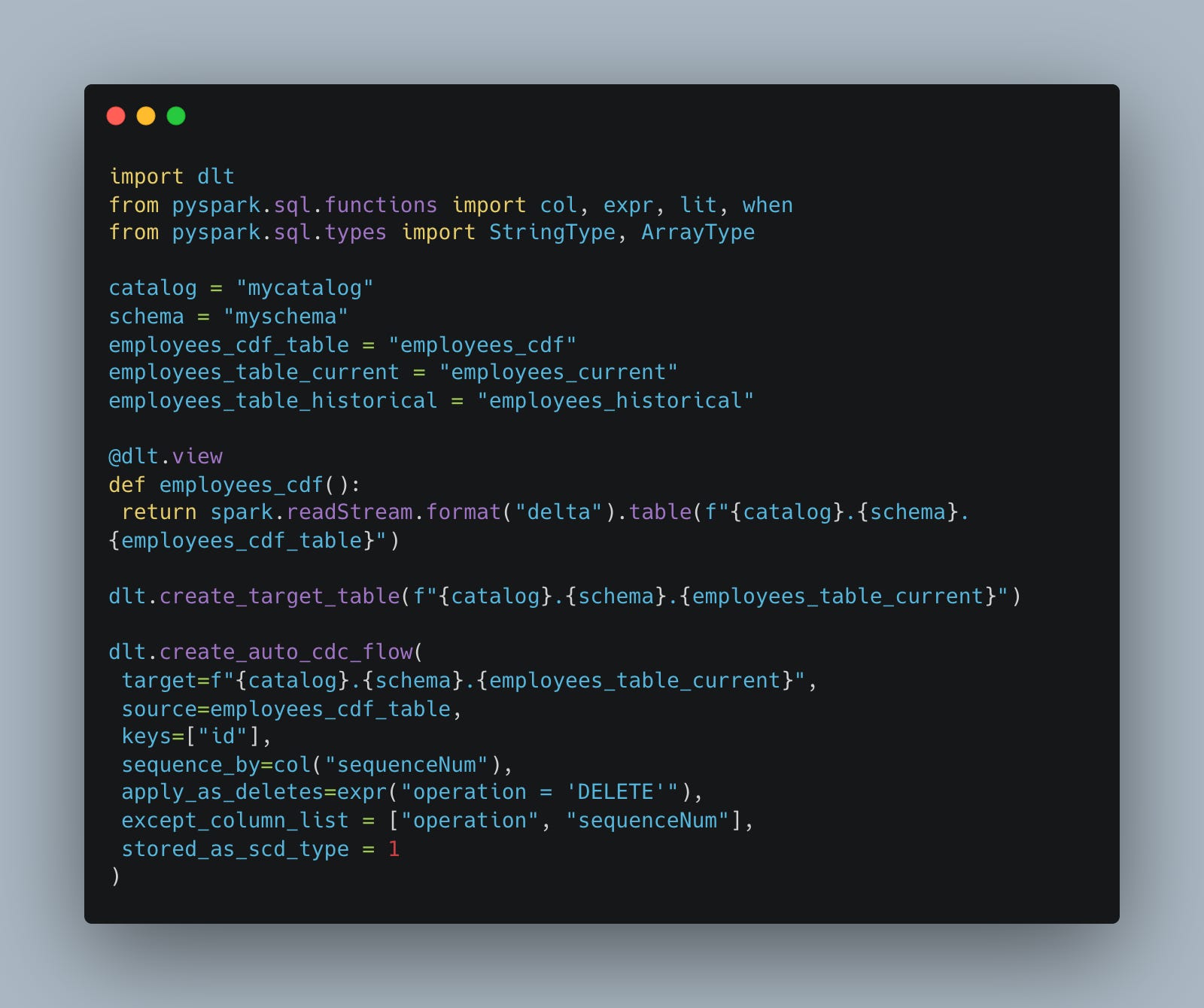
I mean, who is going to argue with that little bit of code?? The longer one writes code, the more one can appreciate tools that make a complicated thing very easy. There is a beauty in less code.
But, then reality strikes and we know there is no free lunch. Everything comes at a price. Literally, or figuratively.
What do you do when it comes to full vs incremental loads, historical loads and daily loads in the same script?? Leave a comment and let us know!