

Goodbye Spark. Hello Polars + Delta Lake.
Freeing Delta Lake from Spark.


Sometimes it’s the small things in life, we get so used to the same old same old, that we don’t know what we are missing. Such has been the case with Delta Lake and Spark. They’ve been one and the same, nearly impossible to distinguish between the two.
This inseparable tie between Delta Lake and Spark has had many benefits and is probably responsible for the meteoric rise of Delta Lake as the defacto Big Data storage API. But, this has had a somewhat unfortunate side effect. Not all data is created equal. Also, as a user of Spark for many years … I appreciate it, but I also want to be set free.
Thanks to Delta for sponsoring this newsletter! I personally use Delta Lake on a daily basis, and I believe this technology represents the future of Data Engineering. Check out their website below.

Delta Lake has grown in popularity and is used by organizations large and small, with data large and small. This presents a problem for Spark. Spark is for big data and comes with overhead and complexity. Many times Spark isn’t necessarily required for some Delta Lake operations. Spark was the only real option for easy interaction with Delta Lake for a long time, but no more.
Spark is too heavy for some use cases with Delta.
There haven’t been many production-level non-Spark Delta options.
Polars provide production-level light and easy Delta Lake access.
It’s time for us to break from Spark a little bit, our old friend Spark will be fine, always ready to support us when we need it. But we’ve got a new kid in town … Polars, and the new kid has a lot to offer.
Imagine a world where you can simply `pip` install on dependency and suddenly have access to Delta Lake on anything from a small lambda, Airflow worker, or a tiny Docker container. That’s powerful, that can save money, compute, and complexity. It’s a game-changer.
Enter Polars + Delta Lake.

This is what we’ve all been waiting for. A cheap, fast, and reliable way to do Dataframe and Analytics work with a Rust-based tool on top of a Python API. The potential to upset the throne of Spark is here.
Trying it out.
It’s one thing to talk about replacing something like Spark with Polars, especially when you are using a storage layer like Delta Lake. You can’t just be doing the classic “hello-world” examples, where you just read some local disk with local data.
It has to be real. So, in the spirit of realness, we are going to work on a sample problem with files based in s3, ingesting and transforming that data, depositing the results in a Delta Lake stored in s3.

A very simple, yet common data pipeline that is, in pretty much every case, built with Spark. I, like you, don’t know if this is going to work yet, some of it, or all of it. Who knows?
Setting up the Project
To get started, let’s build a custom Docker image that will contain all the tools and packages we need to execute the code we will be writing. Good DevOps practices are at the core of next-level Data Engineering.
In our case, we should need a fairly small set of tools. Since we’ve actually started yet, let’s just take a guess at what we will need.
Ubuntu Dockerfile
docker-compose
polars
delta-lake
pyarrow (because Polars sucks at s3 files)
some test data.
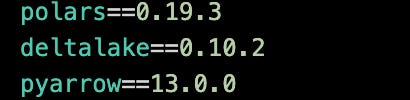
Maybe we will use them all, maybe not, we shall see. All code is available on GitHub here for your use or to ignore as you please.
First, our `requirements.txt` file.
Next, our simple `Dockerfile`

Of course, we will need some sample data, probably CSV. Divvy Bike trips is a free open-source data set, wonderful for little projects like this.
I downloaded 7 CSV files from 2023 into my personal s3 bucket.

This is what the data looks like.

The Polars data pipeline.
Let’s do a very simple pipeline in Polars. Something that is common and basic to every Data Engineering at some point in their life. Let’s pull some data, transform and cast data into the correct format, calculate some metrics, and deposit it into a data source, then read it back. In this case, our data source will be Delta Lake.
There are probably more Spark pipelines running through these steps than you can imagine, running just now, at this moment, burning money like there is no tomorrow.
Read CSV data
Transform/Analytics
Save to Delta Table.
Read back Delta Table.
What does this look like with Polars? Code available on GitHub.

Heck, as someone who’s been writing Spark pipelines for years … this Polars one really isn’t that much different. I would so the only major difference is that we have to mix in pyarrow into the mix with Polars is the only gotcha.
Polars doesn’t have the best support for reading remote directories of files on cloud storage, like s3 for example. In the future, I would like to see Polars make this functionally more seamless. This would only increase the usage of the tool.
This little extra work with pyarrow requires us to …
make a connection to s3 via S3FileSystem support in pyarrow.
scan the bucket and files creating a pyarrow dataset.
It really isn’t that much extra work, and once we are done at that point we can switch over to Polars, pointing it at the pyarrow dataset.
At that point, we can then use Polars SQL Context to do our dirty work, just like SparkSQL, very nice. Polars even has the ability to write back the results to a remote Delta Lake in s3. Not much to complain about there.
The pipeline is very straightforward and easy, and that’s the way it should be. Here you can see the metrics, as well as the Delta Lake files in my s3 folder.

and the actual Delta Lake files.

The future is now.
I’ve been working on Spark and Data Lakes for years, and I can honestly say this is a game-changing tech stack. There is serious potential for cost reduction and savings with Polars + Delta Lake.
Just recently at work, I put in a PR that was merged to do this exact thing. Read a Delta Lake outside of Spark … inside Apache Airflow as a matter of fact.
Spark is for Big Data and a lot of pipelines need Big Data tools. But, there are lots of workloads that don’t necessarily need a whole Spark Cluster, and all the added costs of Databricks to solve the problem.
We just use Spark because it’s convenient and easy to use … we’ve never really had another real option. I mean Pandas is junk. Well, that has all changed now. Polars is here, and paired with pyarrow not even s3 buckets are safe from us now. No excuses.
Polars has been all the rage and talk for 2023, but now is the time for actual execution. Let’s put Polars into production.
And Polars just got Iceberg support: https://github.com/pola-rs/polars/pull/10375
Further supporting your argument that the future has a heavier focus on developer experience.
Loving Polars and Delta Lake - but not sure I was say "goodbye" to Spark as there are still a lot of scenarios that benefit massively from it. But then again, I am a tad biased, eh?! :)