

Gzip. CSV. Python. S3. (Polars vs DuckDB)
headaches ya' know?


In my never ending quest to replace every bit of Spark possible with something … else … you do run into problems that make you realize why PySpark is the go-to tool for the Modern Data Engineer. It’s hard letting those old loves go, like that first date in high school … they keep their claws in ya.
It’s the small things in life that add up to big headaches. Don’t we all strive for simplicity? I do. Every single line of code is a liability. A sure sign of someone who’s been writing code for more than a decade.
Some of these nuances become clear when doing seemingly insignificant data engineering “things.”
I’m not saying these things are deal breakers, but you do notice them when moving from a well matured Big Data tooling, to the new kids on the block. Things I will be thinking about …
what nuances are worth the tradeoff?
compression matters in a S3 bucket world (cost).
do newish frameworks work well with compression?
complexity vs simplicity tradeoffs.
Doing stuff.
This article is going to be more of a simple musing style, I have no plan for where it’s going, just examining a seemingly simple workflow, and talking about complexity, tooling, and the maturing of products and frameworks.
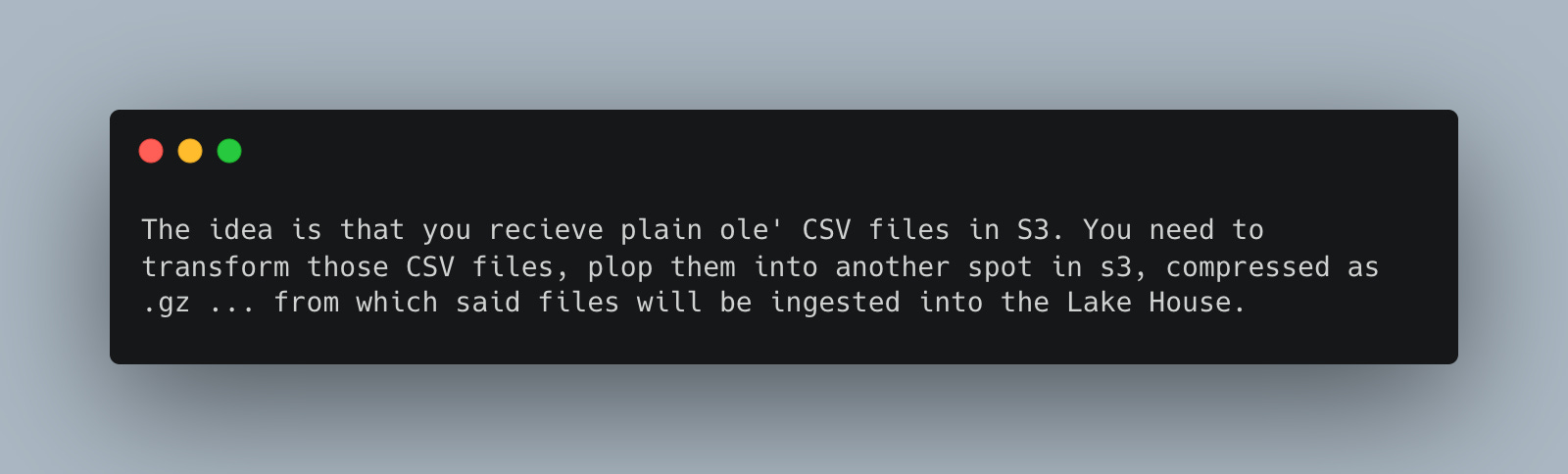
This is a common data ingestion pattern is it not? Life’s never perfect and neither is data.
we get data that MUST be pre-processed before ingestion
cost matters, storage is cheap, but not that cheap
we don’t want write complex code to do simple things
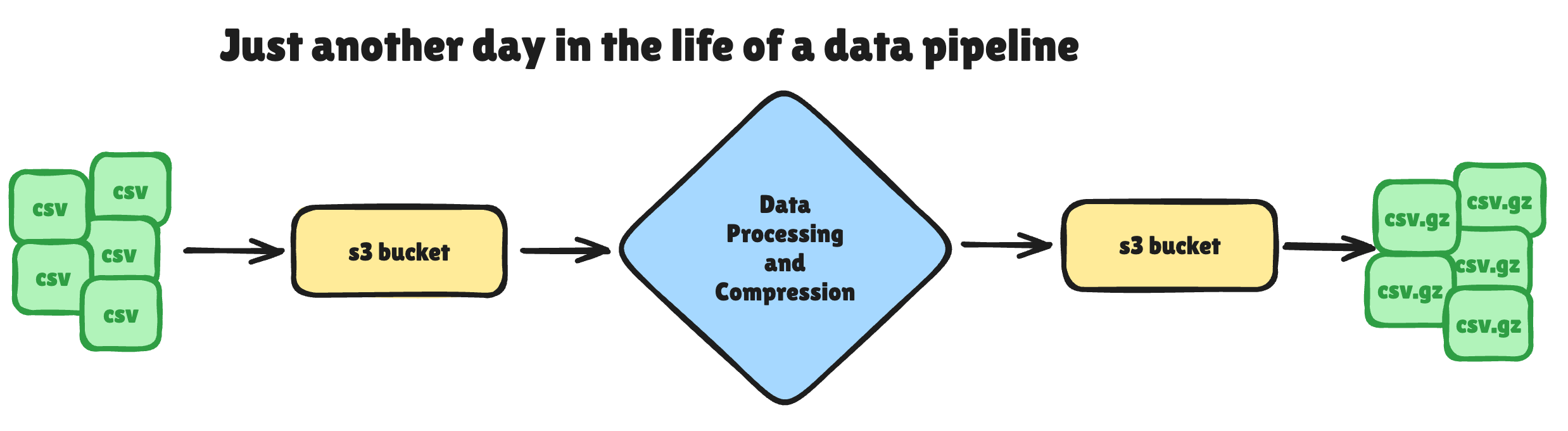
That’s just life ain’t it? Let’s say we have a Lake House running on Databricks and PySpark … that the workhorse of our Data Platform. But, there is just dirty data and some things Spark isn’t good at.
We have to do pre-processing of files.
Some X and Y transformations
Compress the files to .gz
These are very real and very common problems. S3 cost can add up, storage cost does matter, it’s money off the bottom line. Why store CSV files when we can store .csv.gz ?
Many tools, including Spark, can deal with .gz in a transparent manner.
Let’s do this with Polars, an obvious option for CSV files.
Transform and compress CSV files with Polars.
So, let’s just reach for one of the obvious choices to do some simple CSV processing, like Polars. Why not. In theory maybe this code is running inside an AWS Lambda that is triggered of another S3 bucket where the raw CSV files land.
One would assume that …
reading and writing S3 CSV files should be easy.
compressing CSV files seamlessly should be easy?
I mean every time we add another import to Python code, adding more lines, etc, is just more bugs and things that have to be maintained.
Does Polars support CSV with file compression?
Yes. And No.
Simple to test eh?
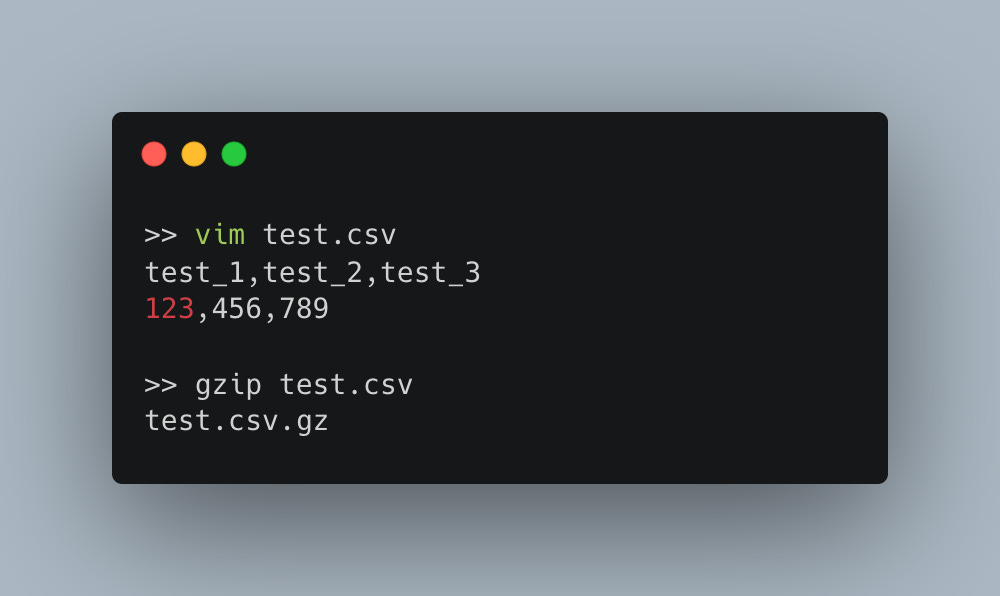
Now, can we read with Polars? Well this is nice, we can read .gz CSV files seamlessly with Polars, this is a nice feature.
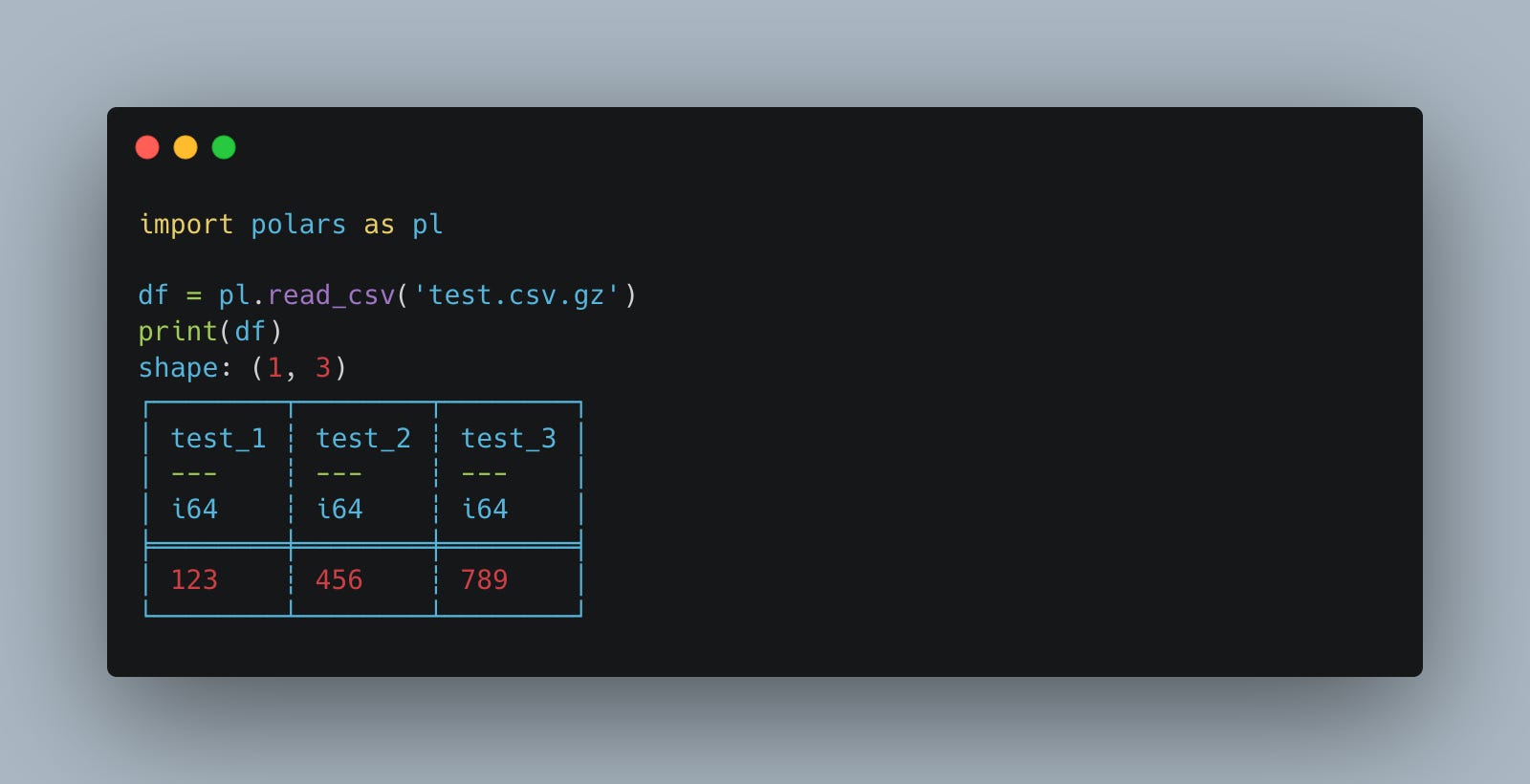
But, it’s only half the battle right? We need both read and write compression options.
Polars does not offer this.
So, IF want to use Polars, we will have to start adding more code to make this happen, maybe add some vanilla Python code to make Polars write a .csv.gz file.
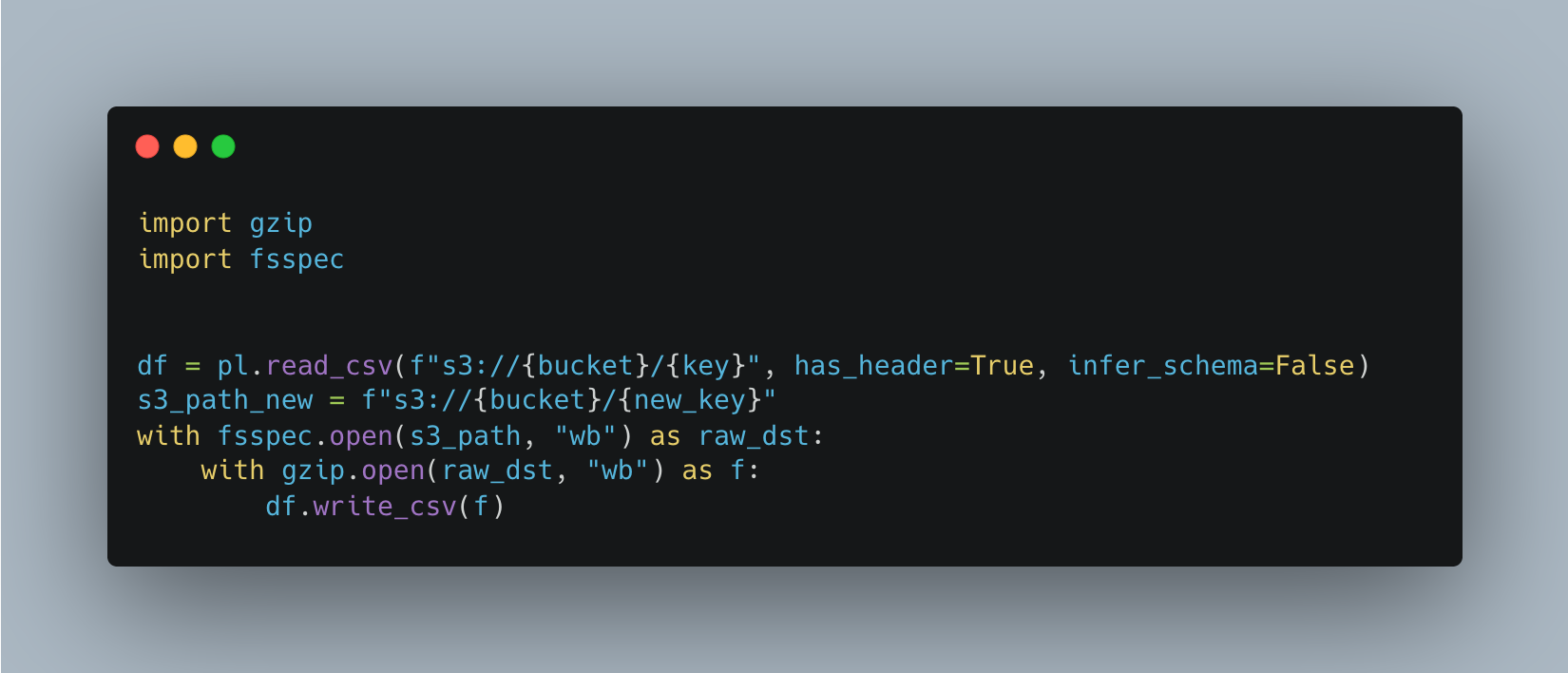
I guess this isn’t horrible. Just two more packages. The gzip package itself doesn’t support s3 paths, so we had to add s3fs/fsspec so we are able to get access into s3 for the write.
Of course in real life we are doing some transformation in between reading and writing, maybe removing headers and footers, or forward filling NULL values.
Hold the phone. What about DuckDB?
Ok, so one could argue that the Polars + Python code isn’t really that bad. Depends on your OCD and lines you draw in the sand. Are you pragmatic or hardcore?
What about DuckDB?
DuckDB has long impressed me with their ability to drive features that top-notch, and they are seemingly obsessed with providing the best developer experience to the most mundane or minute features.
(DuckDB has never paid me a dime, I simply say it how I see it).
They are not going to disappoint us this time either.

Look at that would you. DuckDB provides compression as a CSV option. @#!$@# they good. Those little buggers think of everything.
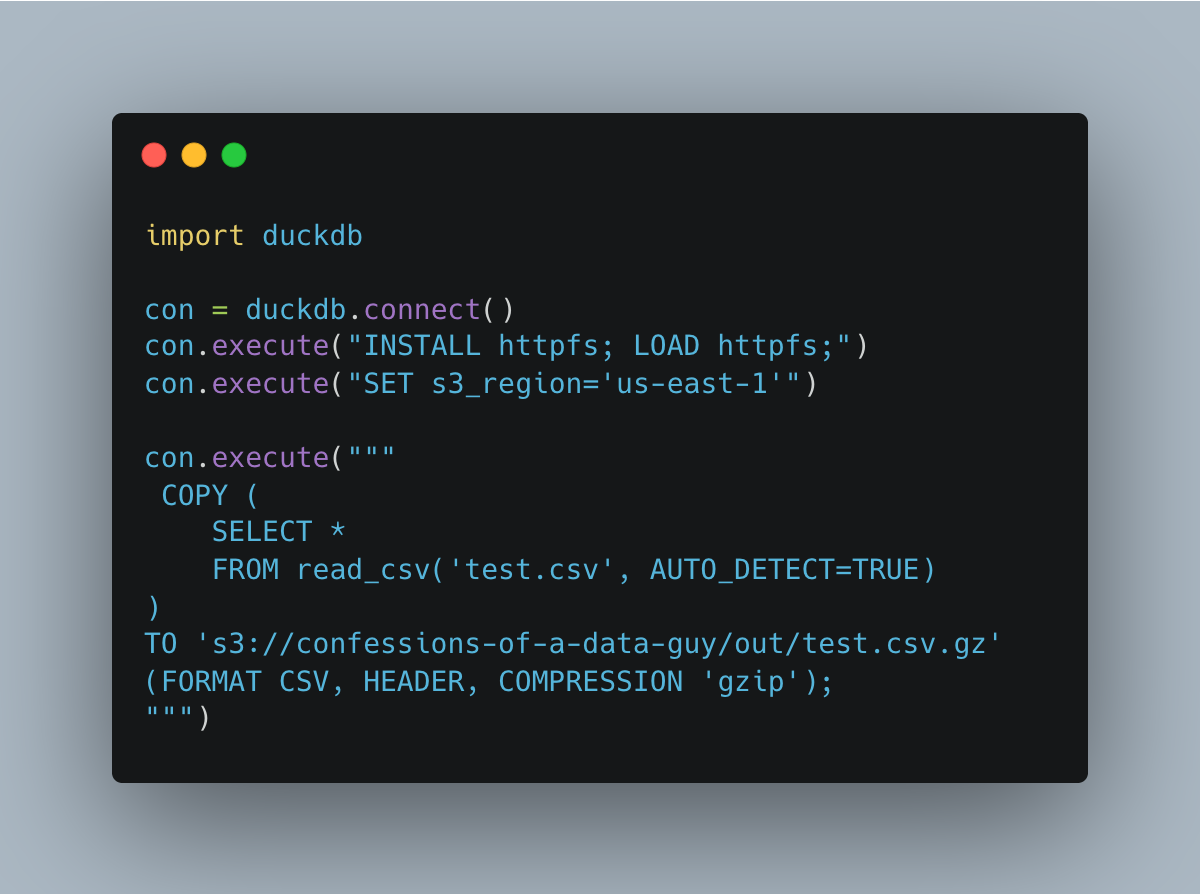
Much more concise with the DuckDB, which we can all appreciate. Less things to break eh?
Musings on simplicity and every day pipelines.
You know, when you spend your days thinking and planning about big projects, making sure the wheels don’t fall off this or that, it can be a breath of fresh air to poke and feel around some day to day data pipelines.
What we talked about today is what you can start to loose track of if you don’t keep your fingers in the mix, and try new things, and think. Thinking … something that is is every so foreign now in the day of AI and Cursor.
“But, you say, why does it matter? It’s code, just a little here and a little there. We can get the job done one way or another. What’s the big deal?”
Maybe there is no deal to worry about. Either way, the day to day building and low level operations of a Data Platform do add up to something don’t they?
Decisions at a high, architectural level of “We will build with this tool” seem to trickle down to the mundane pipeline of the day. How the code looks, how much code there is, how many hoops have to be jumped through, developer happiness.
Everyday around this world, similar decisions are being made by engineers.
The code we write matters in the end, all those data pipelines add up and work together to produce an experience and a way of development and day to day processing.
Yes, there are times to get the job done, it depends on the context.
Great read! I also try to get out of the PySpark train when possible, specially when data can easily in RAM.
Only comment for me is that in this particular case, I'd go with Polars! I love DuckDB, but what I love even more is integration tests. The way DuckDB manages the connection to AWS doesn't allow me to use Moto3 for mocking the AWS services, which is painful.