

Honest Review of Polars Cloud
from honest Abe


Well, we all knew it was coming, don’t lie, it’s how the open source and SaaS (can you tell the difference) world works these days. Some hot new tool comes along, DuckDB, Polars, etc, then shortly thereafter some SaaS offering pops up and the drama begins.
But, here we are whether we like it or not. Nothing left for it, but to step into the breach.
Today, we are going to do an honest review of Polars Cloud. We are are familiar with that Rust based Polars, the self-proclaimed Pandas killer.
It may be exciting, it might be boring, it will be what it is. Let’s just poke at it and see what happens.
Polars Cloud
So, one could ask, what is Polars Cloud and what problems does it solve, why does it exist?
I mean, it clearly has something to do with Spark, (it always does), and the budgetary fatigue of the Mt. Olympus of data processing, namely, Databricks and Snowflake.
This is the way of the data world, it happened with SQL Server, and it’s happening right now with Databricks. Things get expensive, a veritable data processing monopoly happens, then enterprising Startups envision the ability to hack off corners of the marketshare.
Lest you think I’m lying, here from the front page of Polars Cloud, is their comparison of speed and cost to Glue (Spark on AWS).

There argument is, “We can process data faster and cheaper than You Know Who.”
Thanks to Delta for sponsoring this newsletter! I personally use Delta Lake on a daily basis, and I believe this technology represents the future of Data Engineering. Content like this would not be possible without their support. Check out their website below.

What about pricing?
I mean it’s never all about the money, but it’s always about the money ain’t it? Making those greenbacks sing and yell. That’s what makes those CTOs happy.
Many times the “Save money by processing faster < insert SaaS > tool have a small but valid point. But, Polars seems to be doubling down not only on speed, but on cheap price per compute hour.

Not bad eh? .05 cents per vCPU/h.
That is surely a strike at the achilles heal of Snowflake and Databricks.
I mean this is interesting when you think about it.
same price per CPU/h across whatever compute you choose. (so choose wisely)
I mean compare that to Databricks DBU per hour costs of $0.55 for All Purpose Compute to $0.15 for Job Compute. Of course, you are getting A LOT of bang for your buck with the Databricks platform. Way more than just fast compute.
Unity Catalog + a plethora of top tier features, clearly you pay a premium for those things. You get what you pay for in a sense.

Let’s try out Polars Cloud.
I know you’re probably tired of me pontificating now, so let’s just get to it, we can’t know what we are dealing with until we crack it open and give it a try.
First, let’s register for Polars Cloud.

After I verified my email, logging in for the first time, I am asked for my Organization Name, I will try to keep it all above board, but you know it’s tempting.
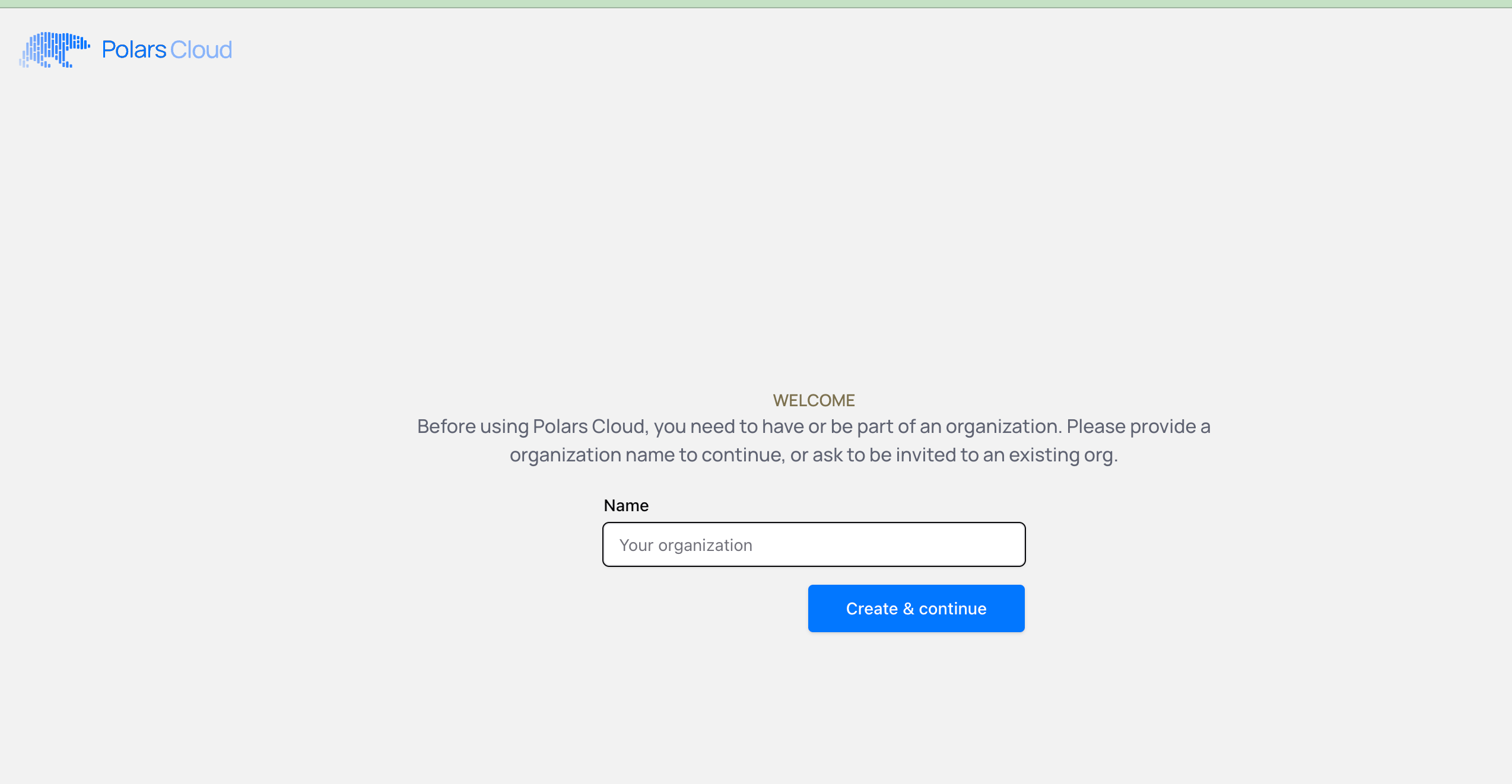
This is where I ran into my first error. Makes, no sense to me.
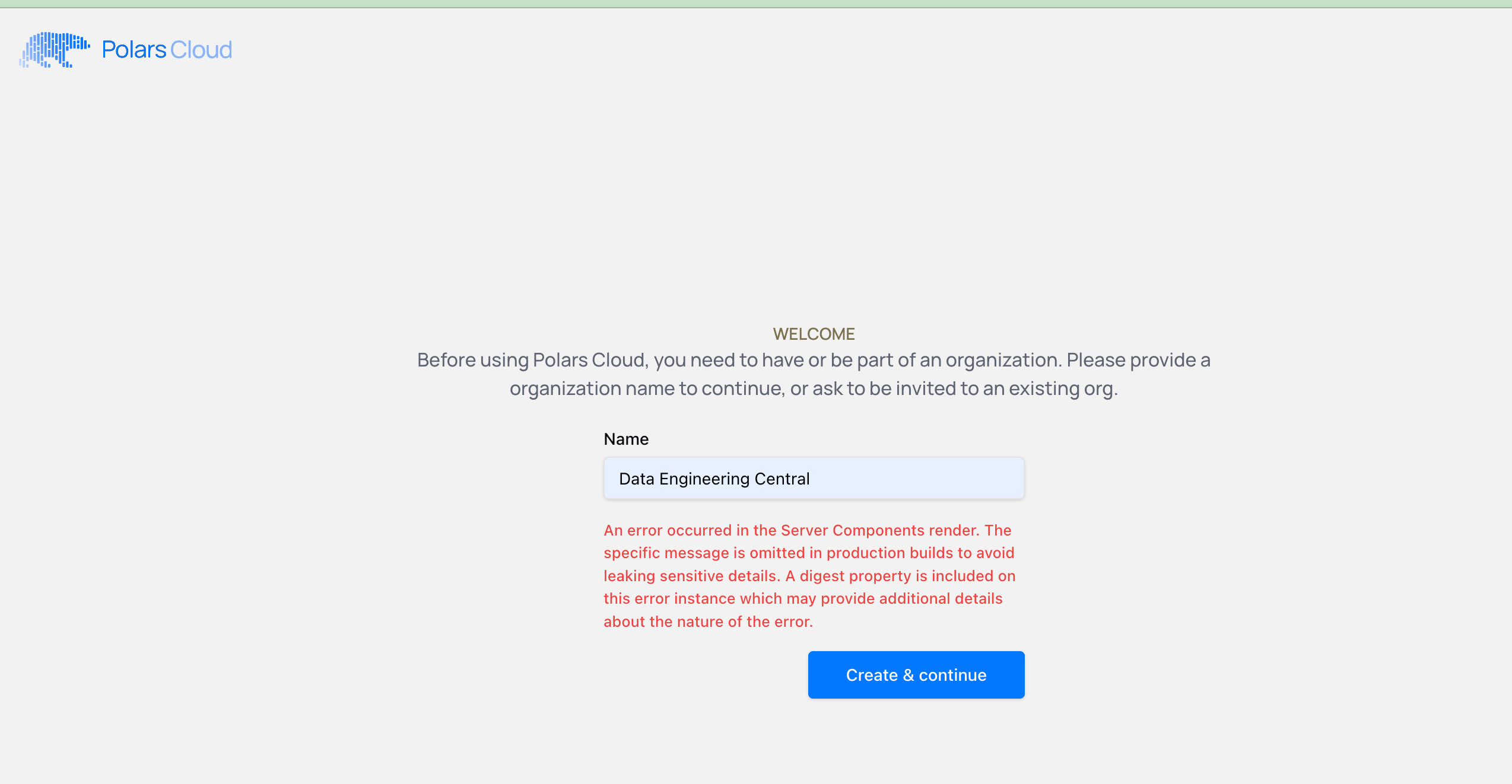
This is not a good sign. Hey, I tried not to be silly with the Org name, but maybe I should try something like PickleBob since it isn’t planing nice.
All I ended up doing was entering “Daniel” and finally that worked? I have no idea what the deal and message is around this “Organization” part of the setup is. It wouldn’t take my other names I input and made up. No idea if it had to do with spaces in the name or something too long. Zero idea.
Ok, at this point I am inside a Workspace, which I can see from the URL routing. Next, we are going to lick on Begin Setup and see what happens.
I entered a Workspace name and click Deploy for AWS.
At this point we are routed to AWS to login.
At this point we are prompted to create a new Stack (Cloud Formation) inside AWS for Polars.
Next, we just sit around waiting for that to be done. Once that create is complete, I went ahead and refreshed that strange login page about the Workspace in Polars Cloud, and acutally got something that looks legit.
(I have to be honest here, the whole onboarding process is strange and you’re not sure if it’s going to work, with strange errors included)
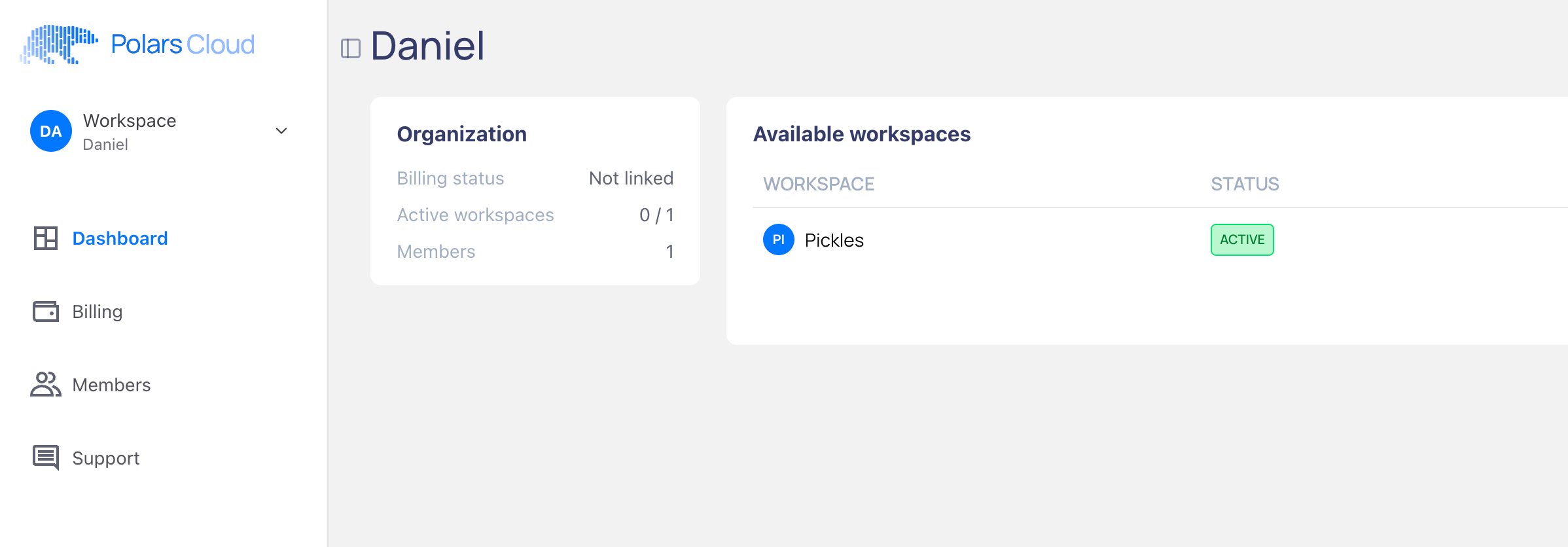
At this point, there is no popup telling me what to do next, no workflow or anything. So your guess is as good as mine.
Funny enough, if I click on Dashboard in the left, I get this same page. But if I click on the ellipses on the right, I get another dropdown that says Dashboard.
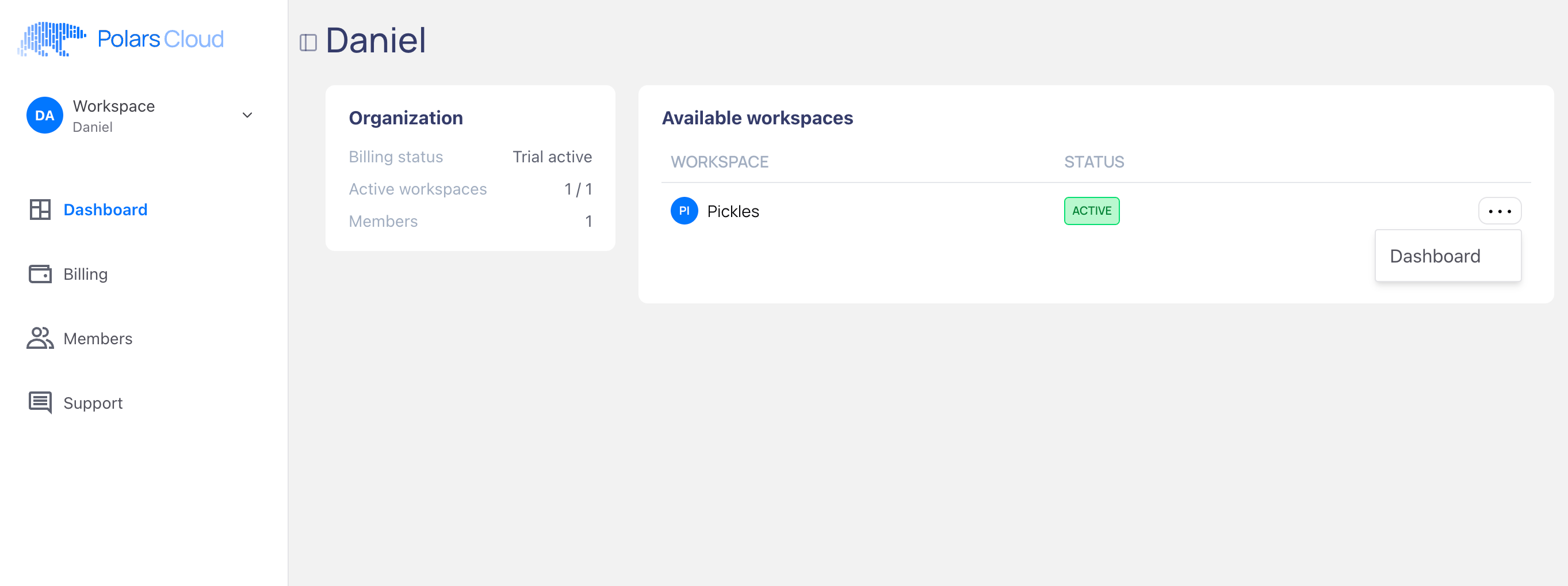
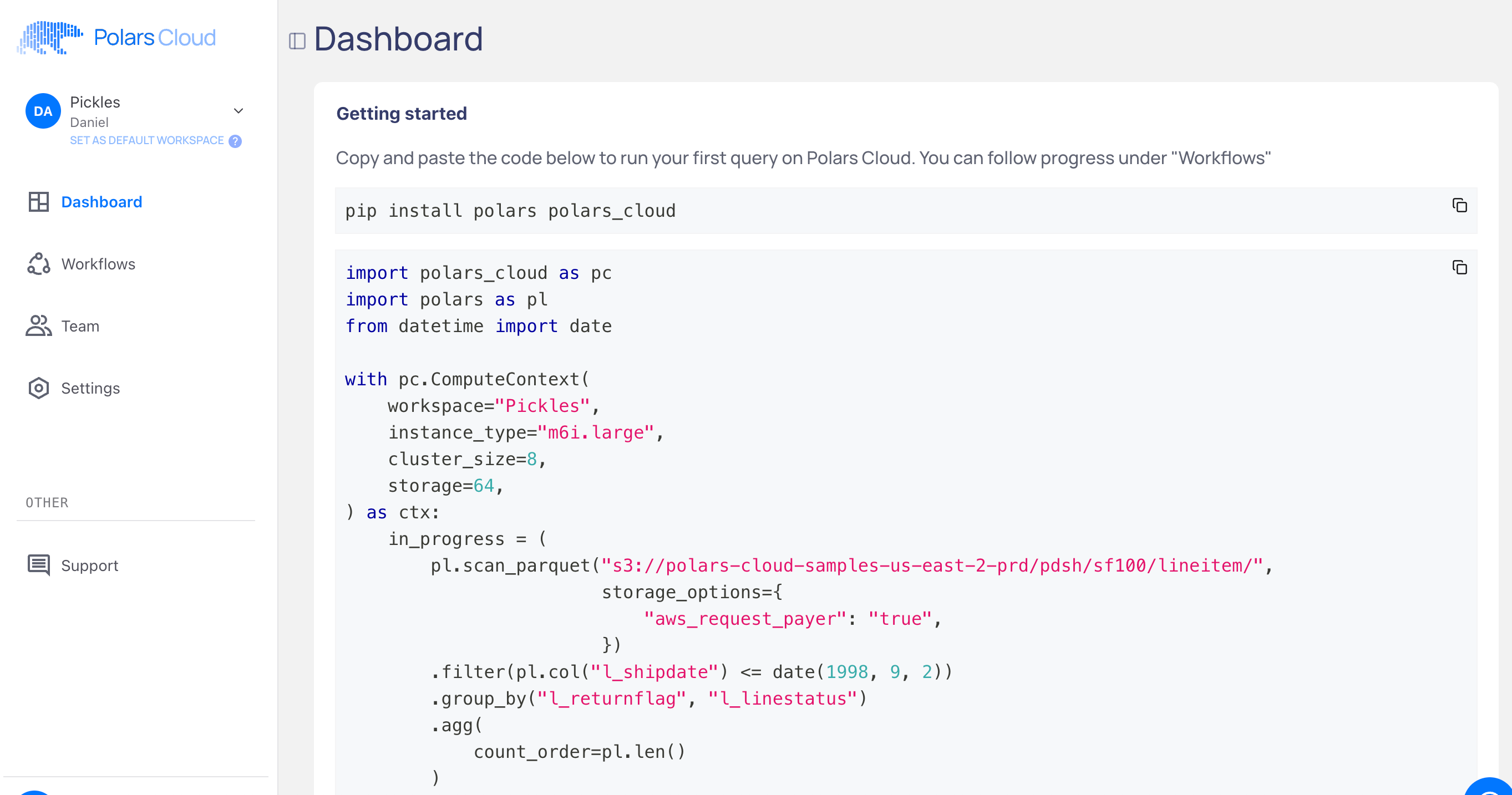
After that I get something that looks like a Notebook with code.
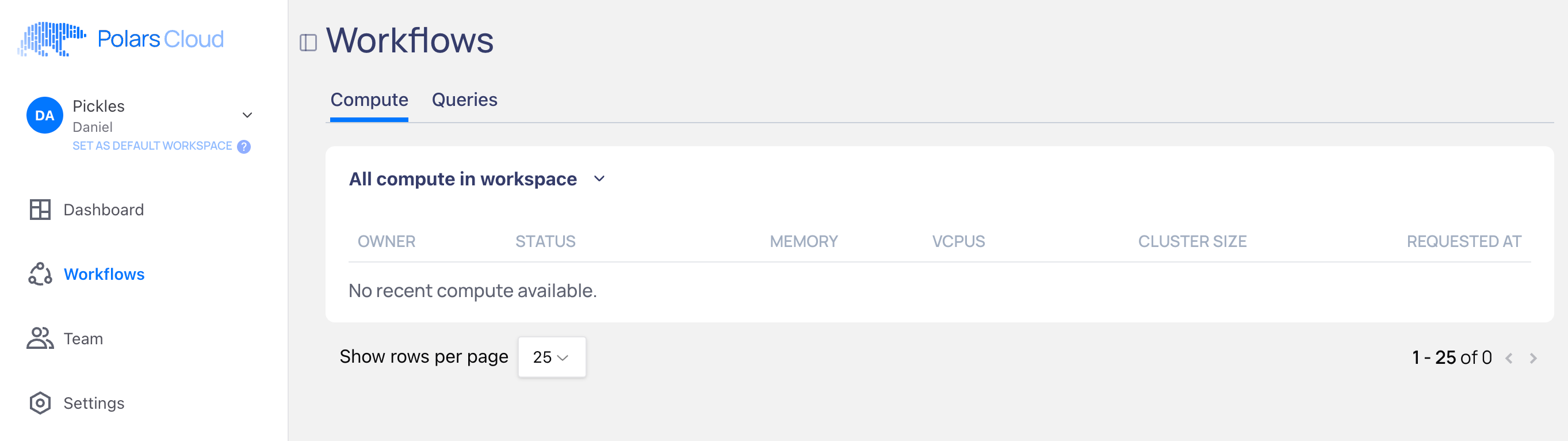
If I click on Workflows on the left, I get a blank page. Not sure what’s supposed to be there.
At this point, I wish the docs had a high level Concepts page or something to pull everything together, but no such luck. You can see the docs here.

This is what I’m most interested in from their docs.
"Any Environment: Start a remote query from a notebook on your machine, Airflow DAG, AWS Lambda, or your server. Get the flexibility to embed Polars Cloud in any environment."
- PolarsI mean, to be honest, I’m clicking around the documentation and would love to see an example of connecting Airflow to this environment so I can see a production example of running a workflow.
Not happening.
We gotta get the concepts down.
At this point, I’m a little at a loss, because I don’t want to necessarily just run Polars Cloud code locally, which I will probably just end up doing. I think to best suit us, since they (Polars Cloud) don’t give us a straight forward Concepts page, we (meaning me) are going to have to spend some time reading the docs and finding the core concepts out on our own.
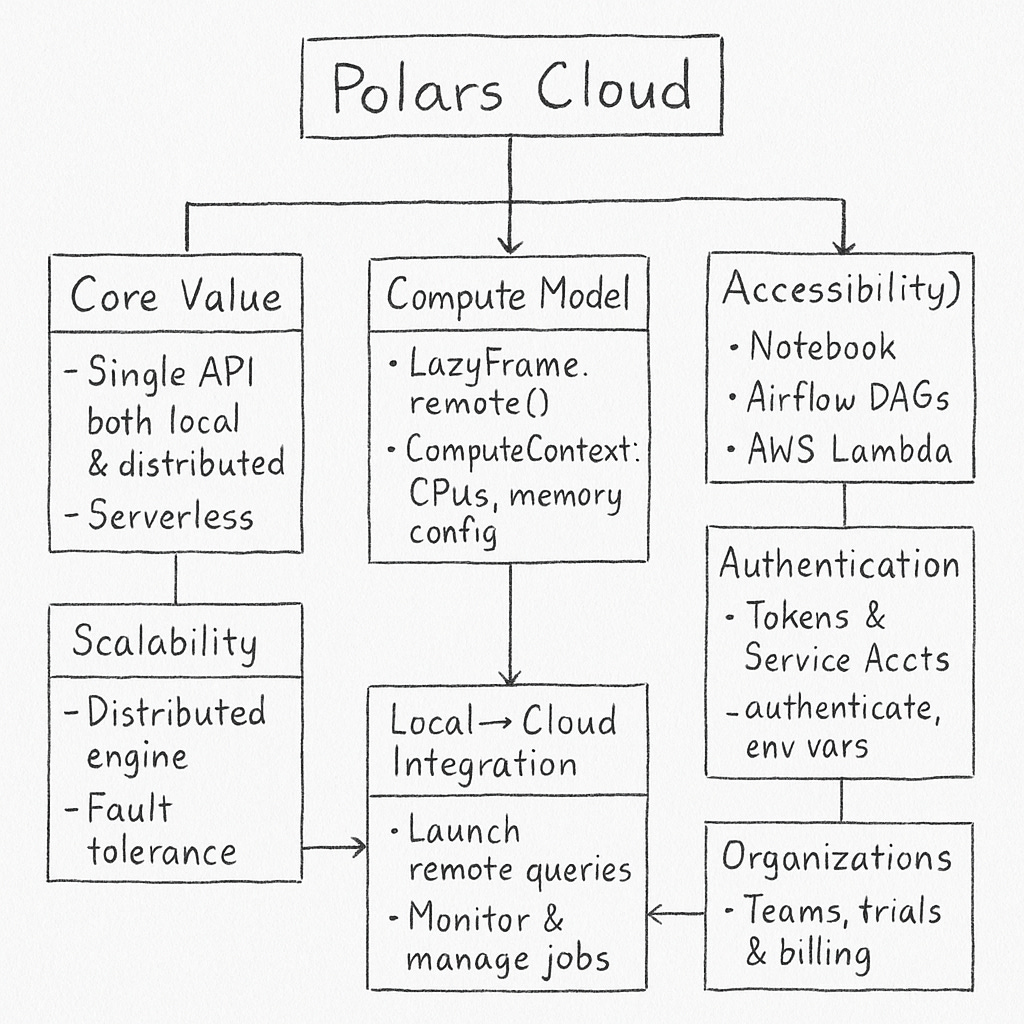
1. Unified API & Serverless Compute
- Same API for local and cloud: Write Polars DataFrame code once; run it locally or remotely via LazyFrame.remote().
- Serverless engine: Automatically scale compute on CPU (GPU support coming soon), no infrastructure setup required.
2. Compute Context + Remote Execution
- Use ComputeContext(workspace=..., cpus=..., memory=...) to define compute environment.
- Chain .remote(context=ctx) to your LazyFrame to execute in cloud, then .sink_parquet(...) to store output.
3. Cloud Accessibility: "Run Anywhere"
- Execute from notebooks, Airflow DAGs, AWS Lambda, or your server—flexible integration options.
4. Scalability, Resilience & Monitoring
- Distributed engine supports horizontal scaling for heavy workloads, with built-in fault tolerance.
- Provides monitoring and analytics tools to assess query performance and resource utilization.
5. Authentication Methods
- Supports short-lived access tokens, environment variables, service account credentials.
Workflow:
- authenticate() attempts cached or env var tokens (or browser login if needed).
- login() always opens browser for fresh login.
- For automation, use service accounts.
6. Organizational Features & Billing
- Multi-user org support: manage members, set up trial, billing, workspaces, teams.
- Flexible “pay-as-you-go” pricing model: pay per vCPU per hour plus AWS infra costs; scales to zero when idle.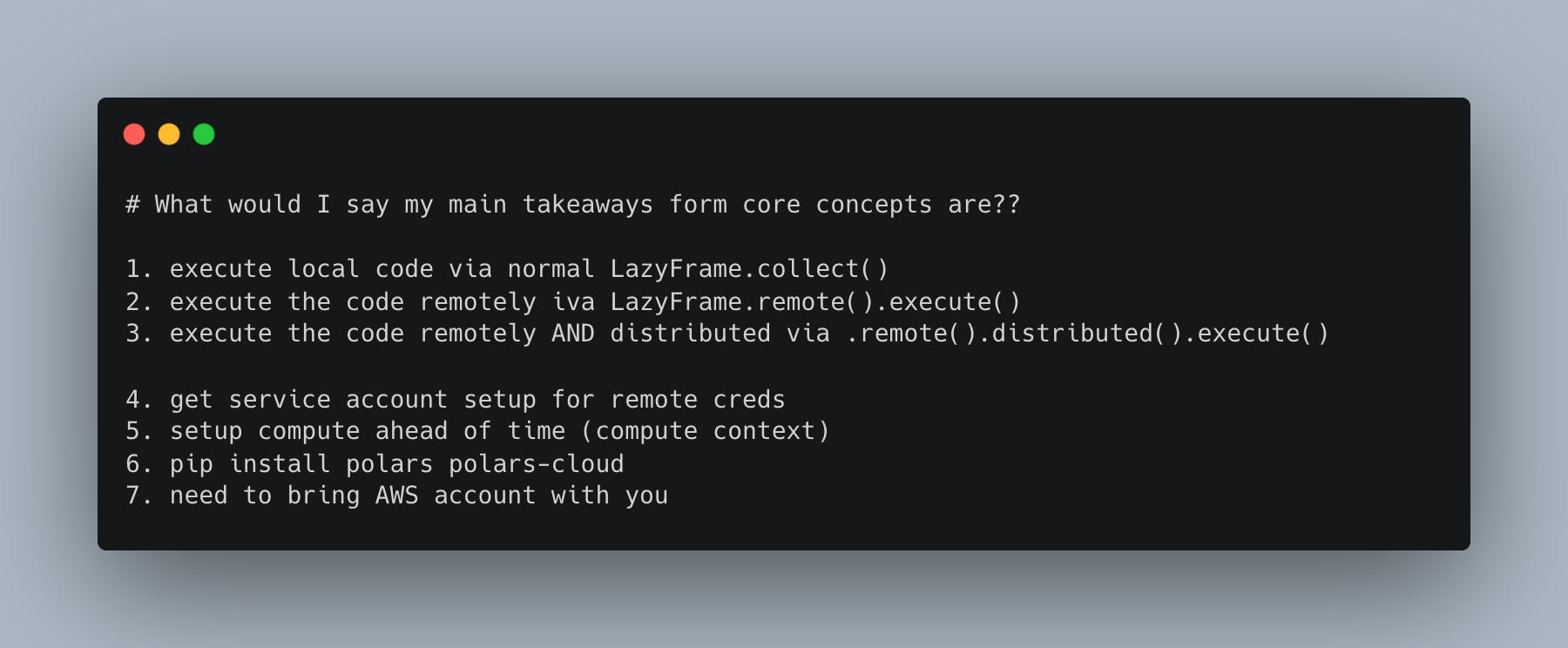
Dang, that’s a lot to take in.
Well, there’s nothing we can do about that, when we get a new SaaS tool, there’s always going to be some learning curve and confusion as we relate to other tools.
If you click on Settings on the left menu, we get a few good options that were mentioned nowhere else.
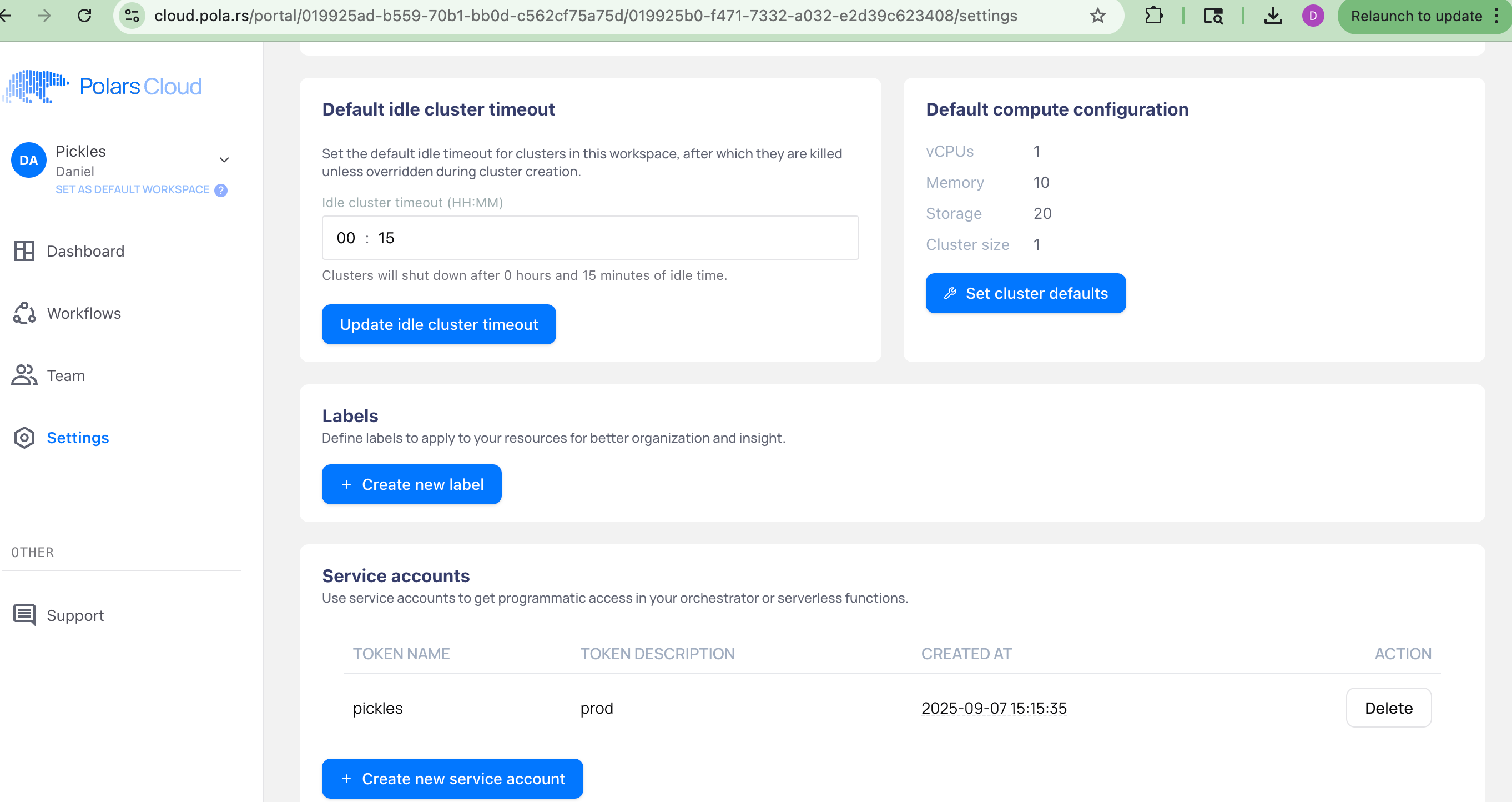
default cluster timeout (set to 1 hour by default)
ability to create service accounts
set default compute configuration
I’m going to lower the default cluster timeout to 15 minutes, set a small cluster as default, and create a new service account and get the creds from that setup.
Let’s make a pipeline.
There’s nothing for it now but to try and make a pipeline and see what happens. Hopefully nothing strange.
We will use Divvy Bike Trip’s open source dataset, getting all of 2025 data.
Also, let’s use the astro CLI to get a local Airflow environment for which we can write a small DAG, so we can at least get an idea of generally what a Production Ready setup might look like.
So, running some Astro CLI init commands, adding polars and polars-cloud the requirements.txt … blah, blah, blah. I came up with this first past DAG and Python code. Not pretty, I tried to follow their example they give in the docs.
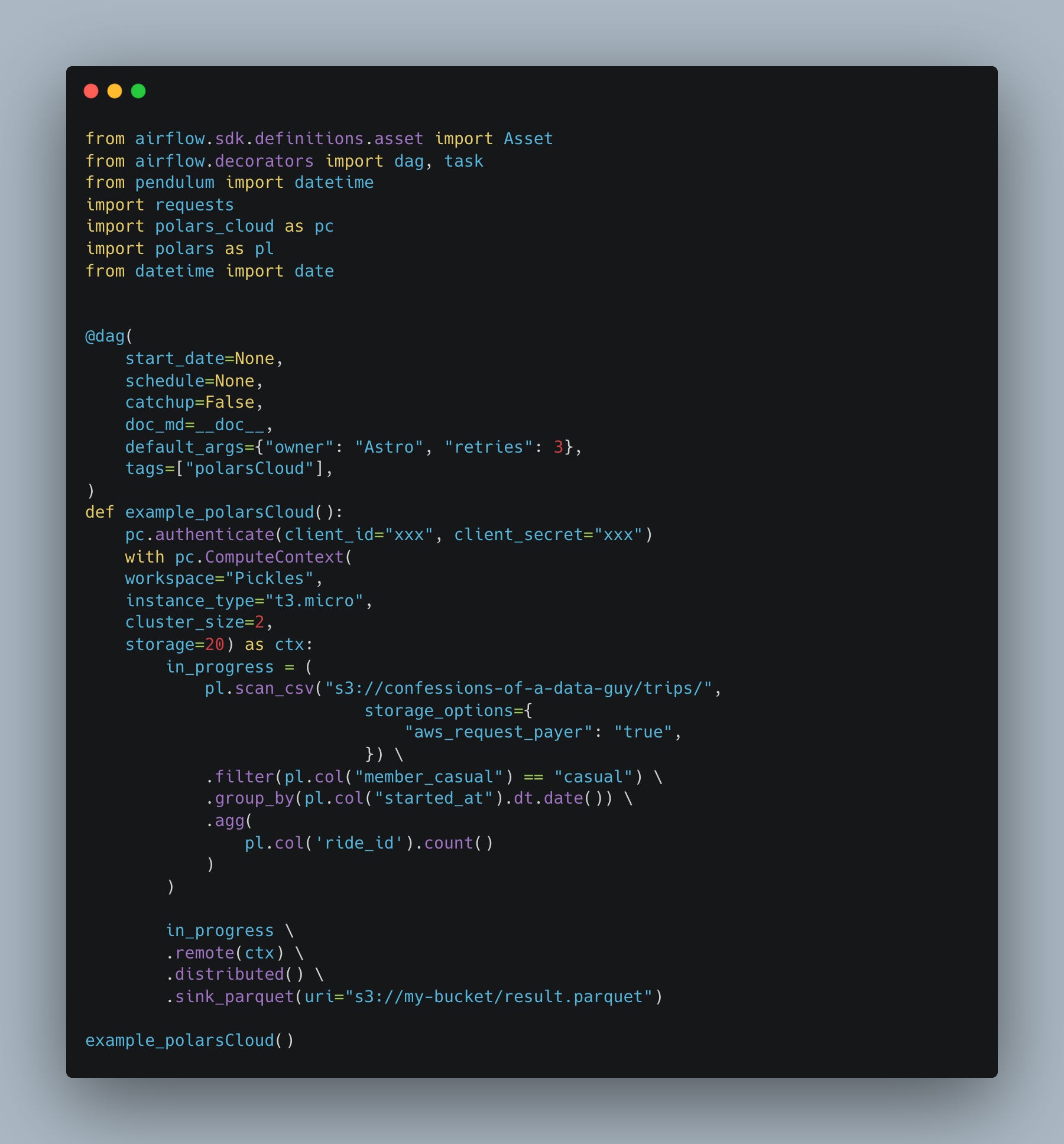
Honestly, the Polars code is pretty low-key, and the Polars Cloud part is only a few extra additions.
Well, all we need to do is run the DAG now, but honestly, we can get a good idea now of what we are dealing with when it comes to Polars Cloud, albeit a quick look.
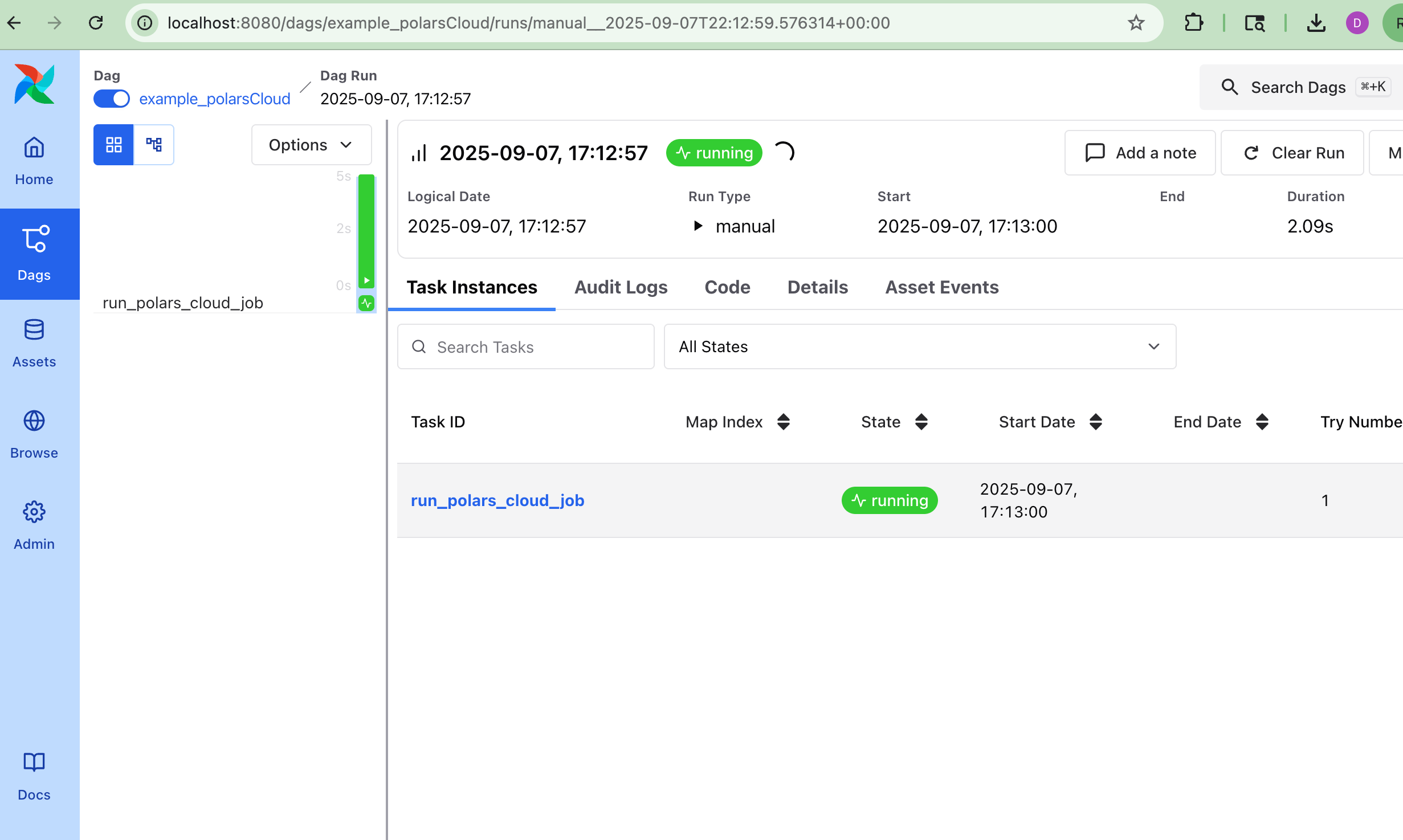
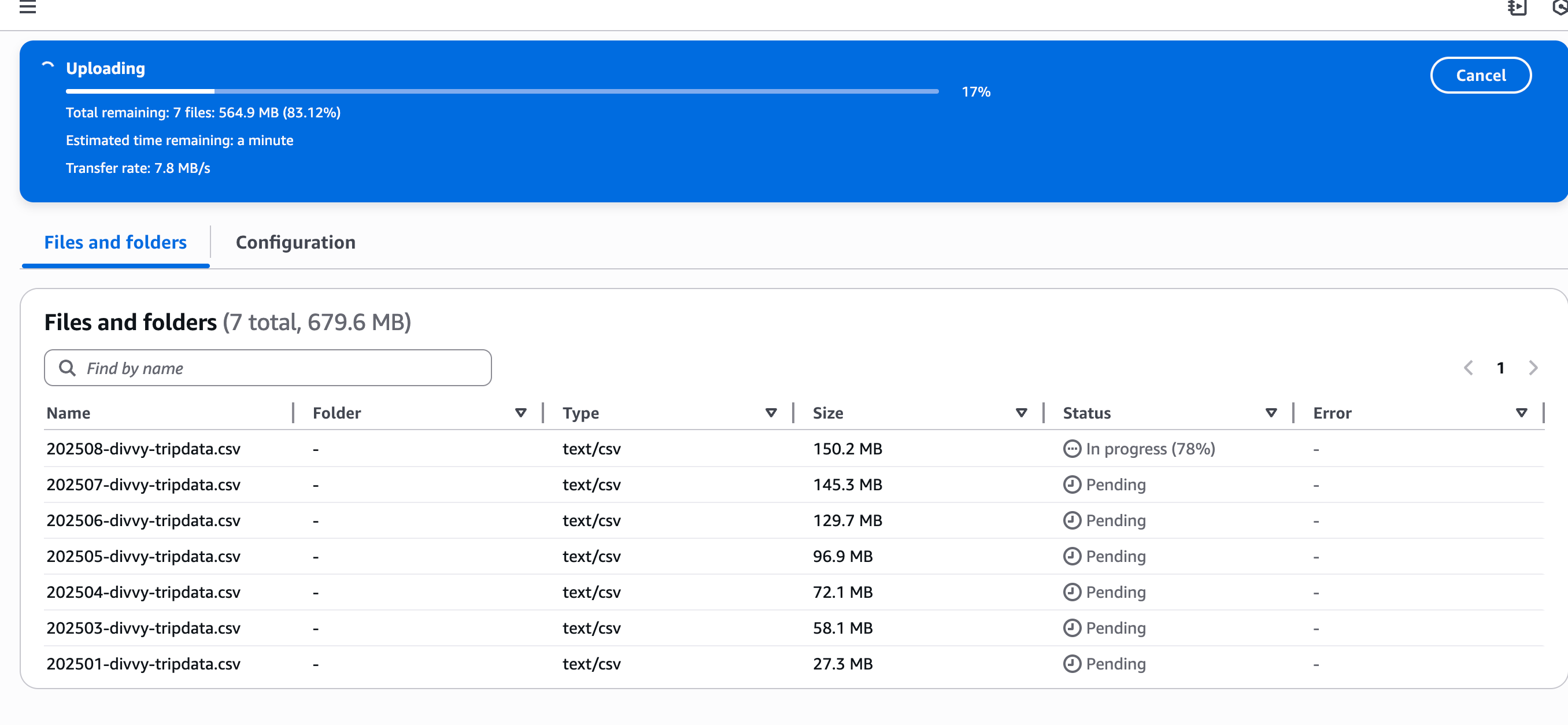
Except it didnt’ work. Also, when I checked the Workflows UI in Polars Cloud, I got nervous.
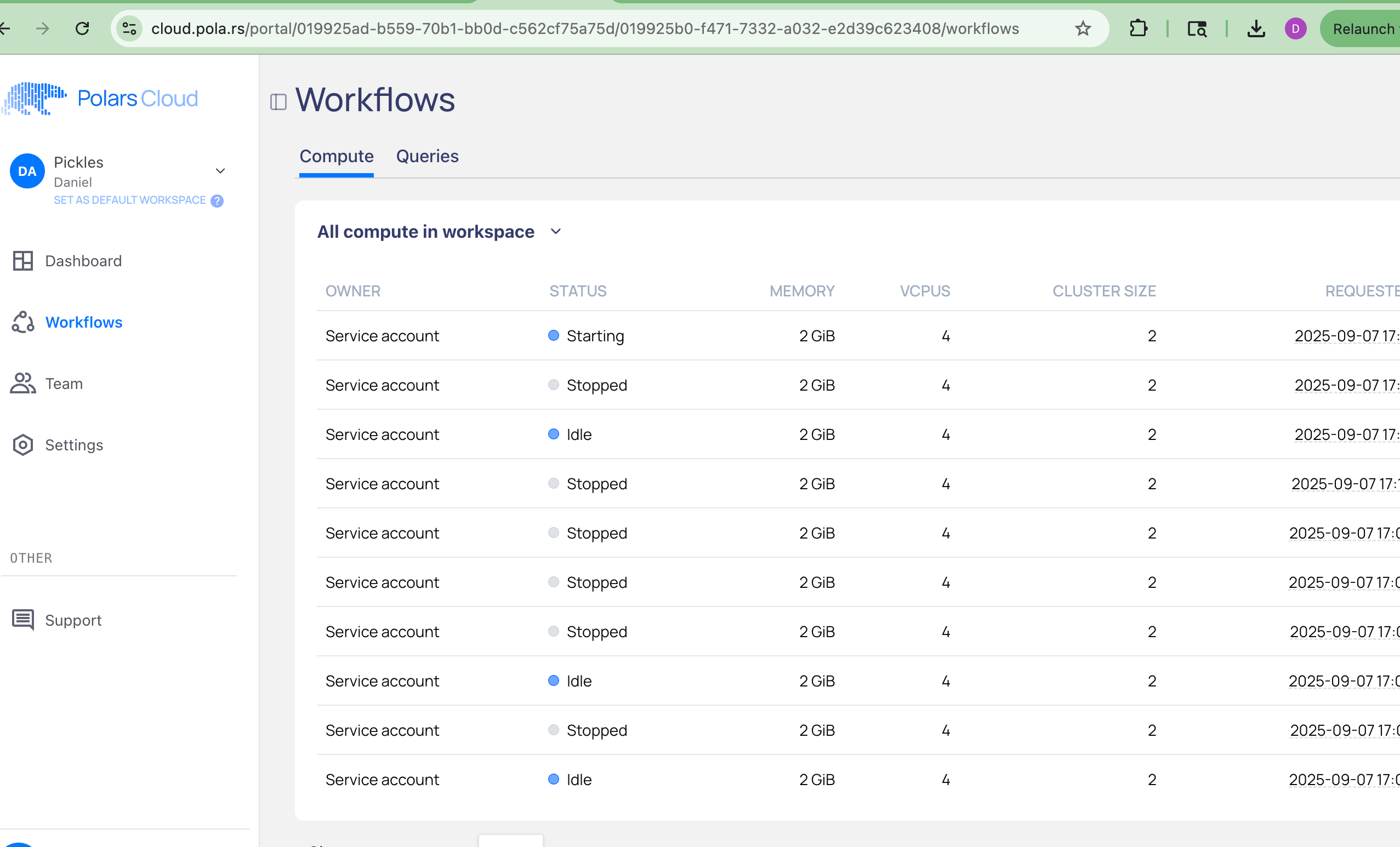
Someone tell me how a 3 retry DAG + Polars Cloud caused this many Clusters to be started. Good Lord, watch your wallet.
Either way, it failed, and here is the errors.
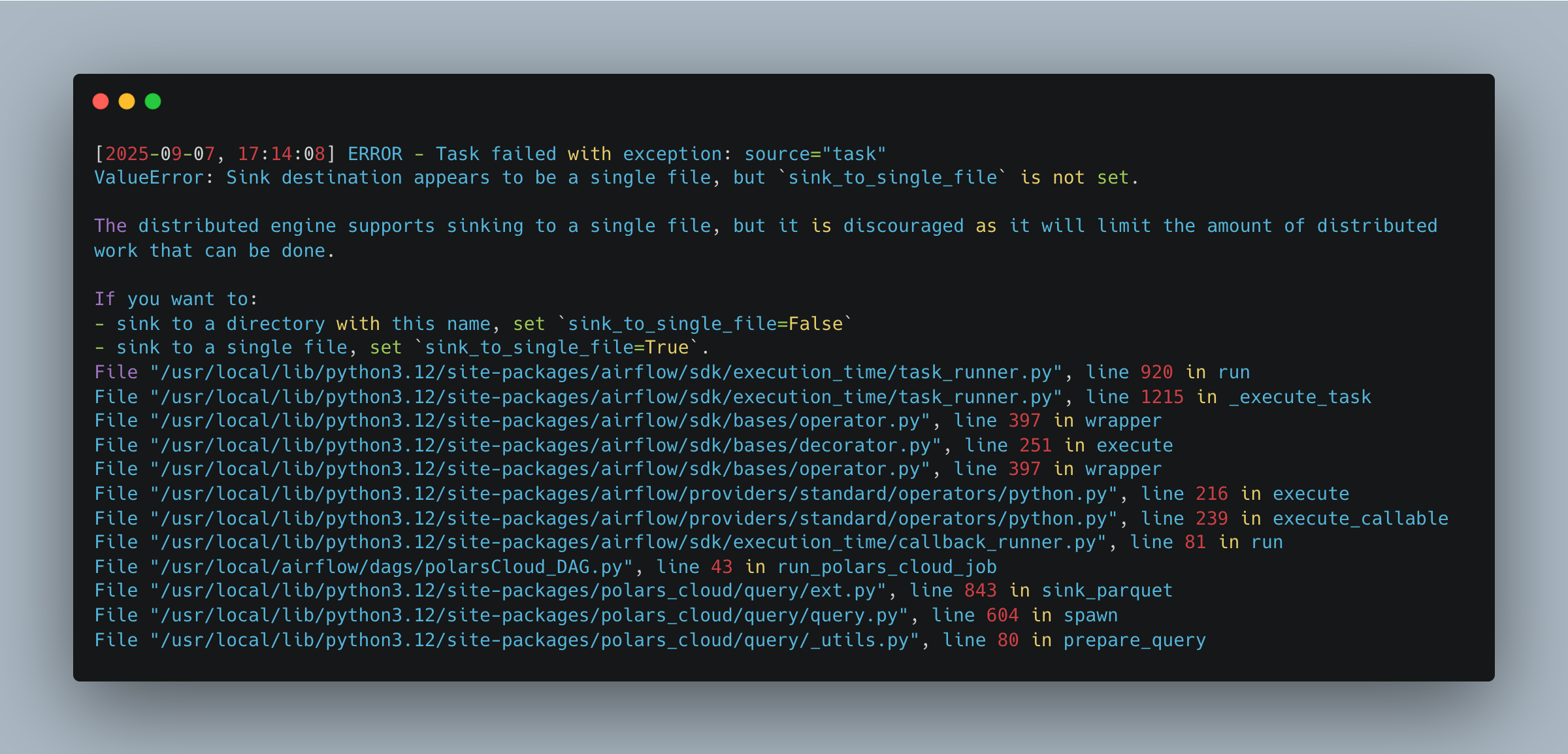
On the positive side, we got it work pretty easy. Anywho, looking at the code, it’s obvious what I did wrong. Updated this line to be more accurate.
.sink_parquet(uri="s3://confessions-of-a-data-guy/results")This time the DAG finished, but way too quick.
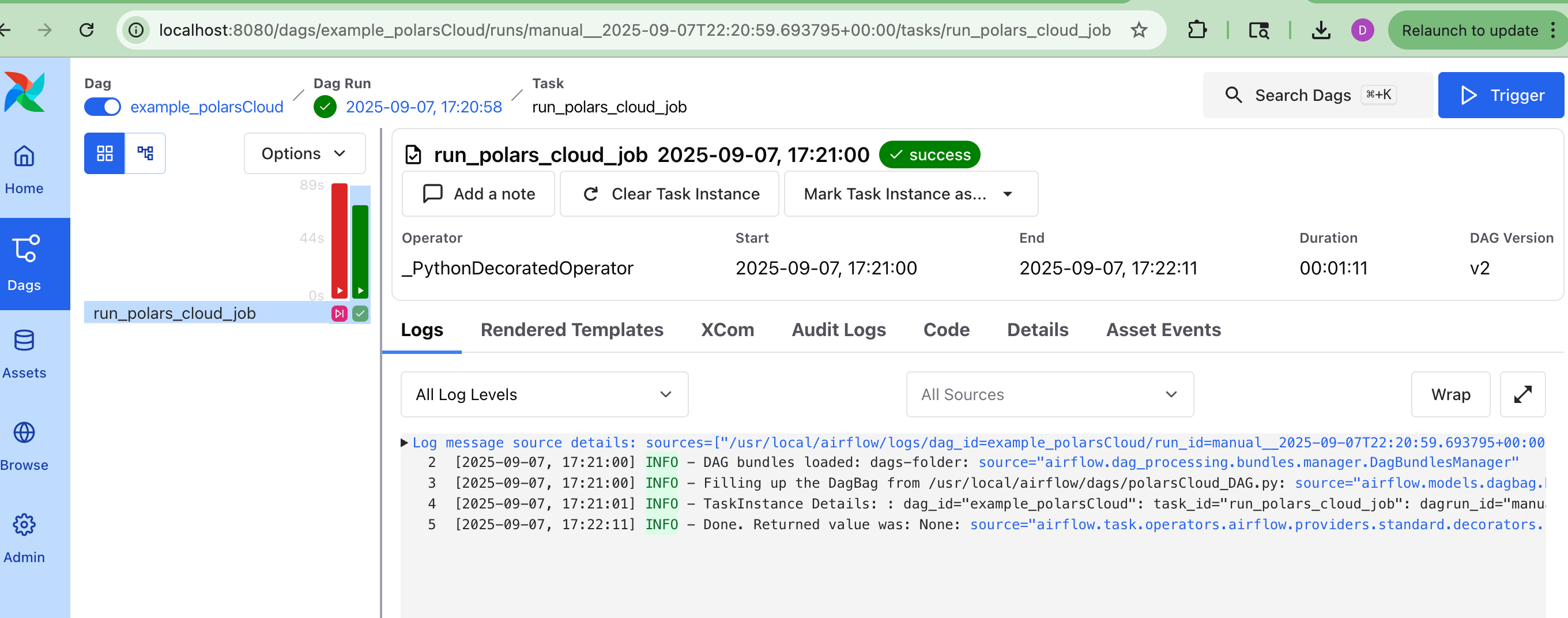
Looking at S3, clearly the results did not write, but there were no errors with Task. Also, the compute in the Workflows tab of the Polars Cloud UI shows what queries ran on that compute.
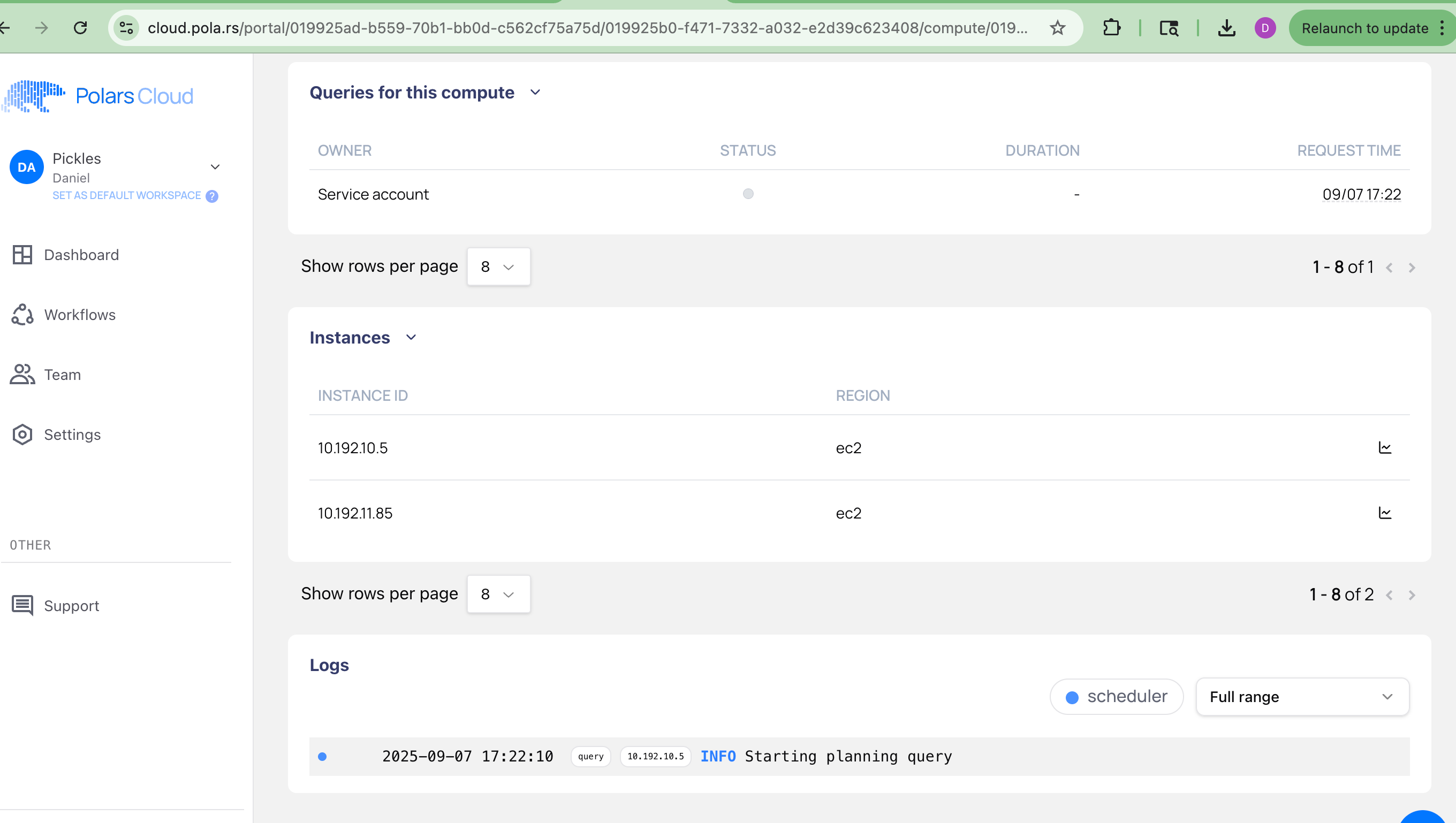
The only thing it dhows is “Starting planning query.”
No idea what happened, what’s a guy to do? No errors from the polars-cloud Python package. The UI in Polars Cloud appears to have no logs that tell me anything.
I mean as far as I can tell, the calls are making it to Polars Cloud to run the code, since this is showing up in the UI, but as to what is going wrong? No idea.
No logs or errors for me to look at mean I can’t debug anything.
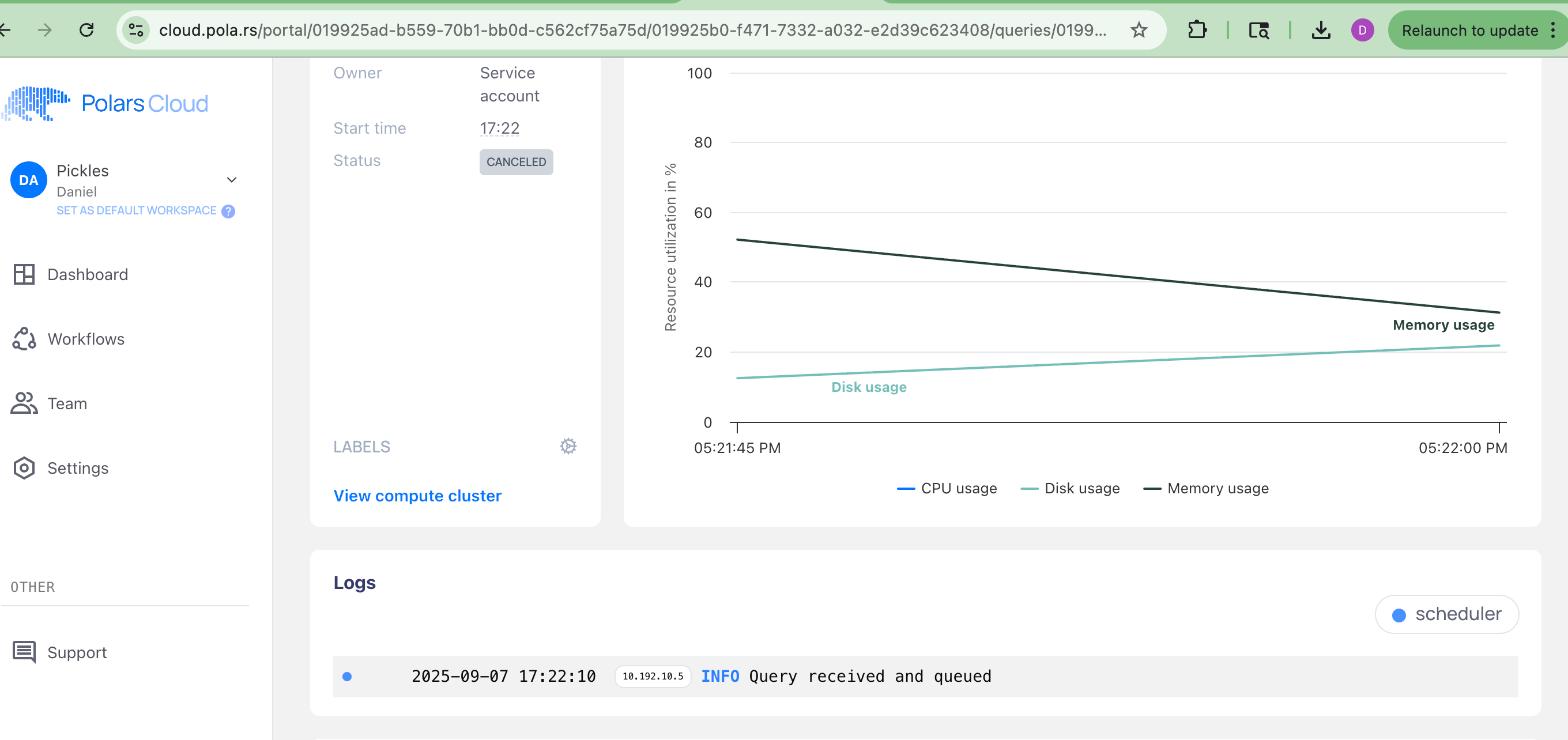
It says “Query received and queued”, but nothing more.
The only thing left for me to try is to get rid of the “distributed” mode and simply try the single node processing remotely on Polars Cloud.
I can do this by simply removing the distributed() call.
in_progress \
.remote(ctx) \
#.distributed() \ <-- remove this
.sink_parquet(uri="s3://confessions-of-a-data-guy/results")Again, the DAG runs, but no results. This time I get two lines indicating query received and planning.

Part of me is wondering if it is because I’m not calling .execute(), I sort of assumed that calling a .sink_parquet() would force the computation.
in_progress \
.remote(ctx) \
.distributed() \
.execute() \
.sink_parquet(uri="s3://confessions-of-a-data-guy/results")This is a no go.
I mean the Polars docs shows two examples, both of which I’m using verbatim.
result = (
lf.remote()
.distributed()
.execute()
)
result = (
query.remote(pc.ComputeContext(cpus=16, memory=64, cluster_size=32))
.distributed()
.sink_parquet("s3://output/result.parquet")
)Ok, I’m ready to just move on.
Thinking out loud about Polars Cloud
Ok, that was alot to go through, but there really is no other way to actually kick the tires on something without going through the motions of trying something out.
It’s one thing to read the docs and get an idea, it always looks like sparkles and rainbows on the surface, until you try to do a thing.
Overall, I think I was expecting a little more out of Polars Cloud, but I’m not sure why I say that. Probably as someone who’s used to using Databricks and UI’s like Airflow, you come to simply expect a baseline level interacting with things.
My Pros and Cons.
Here goes nothing. Let the complainers complain.
Pros.
- Easy to setup
- Easy to integrate with AWS
- Code is fairly straight forward
- Simple, not a lot of features to confuse you
Cons.
- Janky workflow when setting up
- UI is very underwhelming
- Documentation needs better "Concepts" section
- Couldn't make it work or fail (no logs, errors etc)That’s pretty much my takeaway after playing with it for a few hours.
The truth of the matter is that in the age we live in, we’ve been piddling around with Airflow, Databricks, and Snowflake UI for many a year now. We’ve come to expect a certain thing.
My personal opinion is that, although I might not care about a fiddly underwhelming UI, a lot of data people will. Data people are visual by nature.
If you decide to provide a lack luster UI, you’re going to pay the price in the eyes of the average data user. They are going to assume that sort of fly-by-night approach applies to the rest of the project.
And, in defense of this standpoint, as you saw above, I SORTA got the tool to work. What I mean by that is that I got everything wired up and set to work, but it didn’t actually work. Everything said it ran, but no errors or logs for me to review.
Sure, I’m new to it, but so is every single other person, and first impressions matter.
Hey, before you yell at me, I’m a Polars user. I brought Polars into PRODUCTION in my current workplace years ago. It’s a great tool. I use it a lot. So, I’m writing this as a fan of Polars.
They need to work it, from both a UI and Developer experience. How can they teach someone new like me, to use the remote() and distributed() modes of Polars Cloud NOT IN A HELLO WORLD MANNER!
The remote() and distributed() nature of this tool is supposed to be the whole selling point. It should work in a way that is bullet proof, and dummy proof for dummies like me.
I would love to see a follow-up to this post in a couple of months. I strongly believe that Ritchie and Polars' team will iron the rough edges out, we just need some time.
Looks like still very beta. Thanks for kicking the tires. I have no doubt that Richie and the polar team will figure this stuff out quickly.