

How to write better PySpark code.
... do it or else


I hate to say it because it makes me feel old, but I’ve been writing PySpark code for … hmmm … I don't know, a long time. I mean, I was writing blogs about Spark back in 2018, it’s fair to say I was playing with it well before then.
Say, maybe 7-10 years or something? That’s long enough, and I still don’t consider myself a Spark expert by any stretch of the imagination, even if I have been writing it full-time for years and at the 100TB+ level. That should tell you something about yours truly.
Anywho, as much as I would love to teach you how to write Spark’s Execution Plans and how to solve every slow pipeline problem with one or two tweaks, that’s not what the real world is like.
I have nothing against the savants of our age who wave their Spark wands, throw a little dust on their terminal, and can peer into the deeps of the Catalyst Optimizer and make those bits scream.
Me, I’m a simple man.
I have found that the key to Spark happiness is simply to follow the well-worn and boring path of clean, concise, and well-thought-out code and data. Today, that will be my job: to lead you down the path of true Spark righteousness and help you find salvation for our data soul in the simplest place possible.
I have a number of random tips that have helped me over the years write good, clean Spark code that rarely breaks or grinds to a grinding halt. Although that does happen on occasion, that’s just life.
The following ideas are an unordered assortment of things that I have found generally helpful. I will give them to you upfront because I’m no snake salesman, and we can discuss them one by one.
Write modular and clean code
Break up complicated and long pipelines
Spend time data modeling (learn partitions, clustering, skew, etc)
Know when to cache() and Filter early and often
Starting with modular clean Spark code.
This first tip is the most straightforward and obvious approach to writing better PySpark, and sometimes, I feel funny even saying it. Yet, time and time again, I see the exact opposite, so I never take it for granted.
Most of the Spark I’ve run across in my life looks something like we see here below.

Just a giant Python file with a random collection of transformations directly in a large line that goes on and on until it’s impossible to make sense of what is happening.
hard coded crap
nothing is reusable or modular
it’s hard to read and follow after awhile
you lose track of what is happening where
Instead, we should strive to wring ALL PySpark code inside reusable and testable functions.

We can abstract away business logic, pass configurations in, and use the same method in multiple pipelines. This makes everything more readable and less error—and bug-prone.
Break up large pipelines into pieces.
Honestly, I can’t even count the number of times an oversized and way too complicated Spark pipeline has ground to a halt for no apparent reason. All of a sudden, the runtime goes from 40 minutes to 3 hours.
What do most people do? Start reading that nasty old Spark plan and waving wet Dogwood branches over a fire and saying incantations.
Do you know what the first thing you should do is? Give Spark a fighting chance to figure out what it actually needs to do (believe it or not, in my experience, the Spark internals gets buggered up easily). That chance is given by simply breaking up long and complicated pipelines into separate pieces were possible.
Even if it doesn’t solve your long runtimes (which it usually does), it makes the eventual feature additions, debugging, and general understanding of the codebase increase tenfold.
use multiple utility files broken up by logical units
break the pipeline physically from one into three different pipelines
Data Modeling is key.
This tip doesn’t immediately come to mind when people think about Spark, but it’s arguably the most important part of the code … even though it’s not the code. The code you write, how complicated it is, how well it works, what it looks like … it all depends on how the data is modeled.
Working with good datasets that are well modeled for the problems being solved reduces the computational burden of your Spark code, both mentally and physically.
You should become the master of …
Partitions and Data Clustering.
Data Skew and Shuffle
Joins and Data Types
etc
If you have crappy data models, then your code will most likely be slow and crappy as well. Here are some articles on the topic of data modeling in the context of Big Data.
The Data World Revolves around Partitioning
Delta Lake Liquid Clustering vs Partitions
Data Skew, a Gentle Introduction
Learn to model your data well, and your Spark pipelines will fly.
Cache() and Filtering
These last two tips are probably the simplest things you can do to improve Spark's performance. Just so you know, it is usually the simple things that work.
cache()
filter early and often
I feel like cache() is the secret superpower that 80% of Spark pipelines need, something that would save countless amounts of money and runtimes. The problem is that when introduced to Spark for the first time, many newcomers fail to realize the Lazy nature of Spark’s execution.
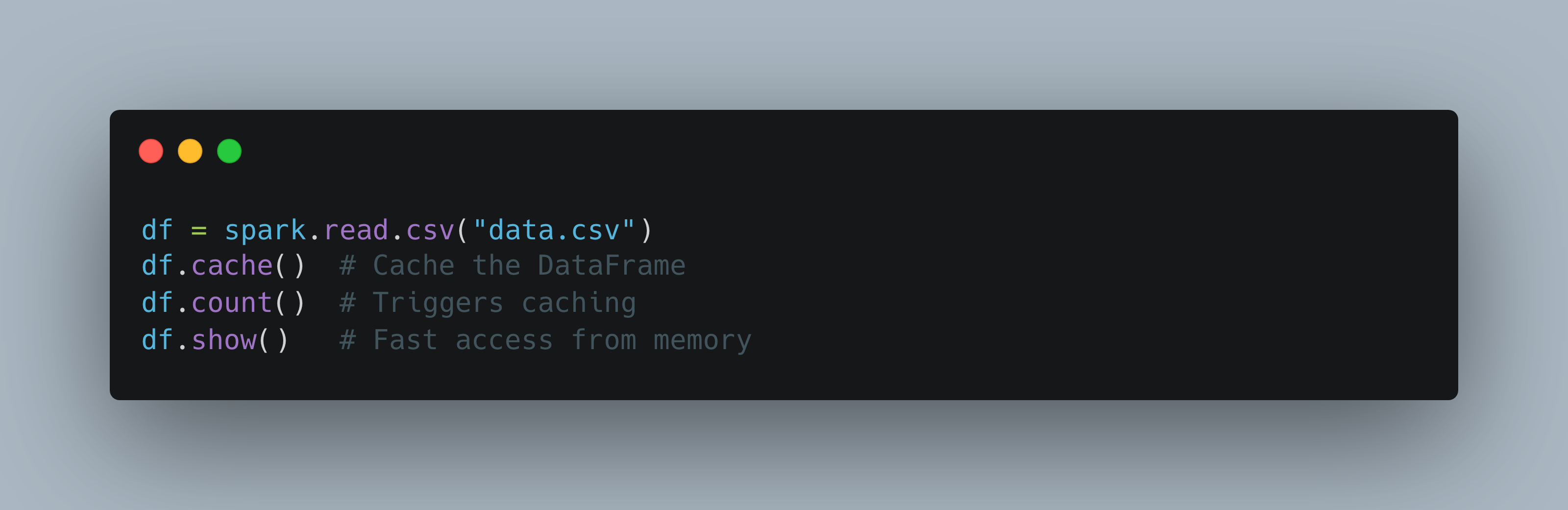
What is cache()?
cache() is a transformation in Apache Spark that persists the DataFrame, Dataset, or RDD in memory. It stores the data the first time an action is performed, avoiding re-computation for subsequent actions.
When it comes to filtering, I can hear all the pundits telling me that Spark will figure it … “I promise you, it will know … it will ALWAYS figure it out for you.”
Never take anything for granted, never assume that someone or something (Spark) will indeed do it perfectly and filter you data for you based on some piece of code 100 lines later.
The first thing you should always do when starting to write a new pipeline …
SELECT only the columns you want
add as much to the WHERE clause as possible
filter EVERY SINGLE data source
Never underestimate the power of cache() with SELECT and WHERE clauses to clean up your code. Not only will your pipelines run fast, but there will be no “hidden” logic that is just assumed. It will be obvious to everyone what the intent was.
Writing better Spark code.
I know these are the most boring Spark tips that anyone could possibly tell you. Sure, I could have told you to turn your spark.shuffle.partitions to be 1.5 times the number of cores on your cluster. But that’s not what I’ve seen day to day all these years.
You could spend your time trying to read and learn all the Spark internals, get confused, mess with things that shouldn’t be messed with, put in a PR, and break the pipeline.
I’m not saying never do those things; I think you should get there, but I think you should start out nice and easy, with the basics.
If your Spark code is not modular, reusable, and has no unit tests, you’re not ready for the Big Time. If you don’t have ANY cache() going on anywhere, than you probably need to start there. If you aren’t not filtering EVERY SINGLE data source with a WHERE and specific SELECT clause … then you need to start there.