

Lance for Embeddings (vector database)
in the age of AI


I recently played around with the newish Lance file format, more to examine the claims it made vs Parquet. Clearly, it was not made for tabular workloads, but for AI-related… “stuff.”
One of the most common AI usages for Lance is to store embeddings, at least from what I read. In a twist of fate, or something else, I had the joy of spending time looking into some vector options. Truth be told, I wanted something EASY.
Doing some prototyping, MVP, and POC work… I don’t always want to pick up a heavy tool. Complexity is a killer; I don’t want overly complicated architecture and costs. Sometimes you want something that works, works now, and can be dealt with later.
I’ve used Databricks Vector search, indexes, and endpoints a few times over the last few years. Heavy, expensive, complex, and super slow. Usually not a trait for Databricks, but they dropped the ball on vectors for sure.
Big thanks to today’s sponsor, Astronomer. Make sure to check out their links below, as it helps support this Substack!
Astronomer analyzed 5.8k+ responses from data engineers on how they are navigating Airflow today, and the findings might surprise you.
You’ll learn:
How early adopters are using Airflow 3 features in production
Which teams are bringing AI into production, and what’s holding others back
94% believe that Airflow is beneficial to their career
Download the State of Airflow 2026 Report

At some point, I just wanted something “easy,” heck, I didn’t even want a “database” … just a flipping simple and easy to use vector and embedding storage option.
Easy
Low Complexity
Integrates into a larger data ecosystem.
This might be boring for some, but I find it useful. I find myself working on AI systems more often than I would like.
Yes, I could reach for those outrageously expensive options, some high-end SaaS managed Vector Database that eats money for a living.
Sometimes you simply have to try things for yourself if looking for the perfect solution.
Nothing for it but to give it a try.
This isn’t really a post about Lance itself; it positions itself as a “LakeHouse” format, much like everyone else these days. That’s fine and all, I’m not here to pontificate upon what that means.
What I really want to do is find out whether I can easily store embeddings in Lance with minimal effort.

This part is what interests me.
"Lance enables powerful hybrid search combining vector similarity, full-text search, and SQL analytics on the same dataset. All query types are accelerated by corresponding secondary indexes as part of the Lance specification."
- Lance docsNot only do we get a nice storage layer for embeddings, but it also appears to have some SDK/APIs that support similarity search, etc. What’s a good, real-life use case we can use to figure out this Lance thing?
Easy, how about taking an export of every single post I’ve written on this Substack?
It could be useful to keep a embedded dataset on all my blog posts, maybe wire it up to a personal agent for myself, after all the writing I do, it might be nice to simply ask “What have I written about on this topic before?”
So this will be our workflow …
Obtain news article data set
Figure how to read it
Figure how to convert text to embeddings
Figure how to store embeddings into Lance
Write a LangChain AI Agent with access to Lance
(RAG)
Ask it some questions about what I’ve written about
I think this will be a good exercise to see how Lance performs, what it’s like to work with, egenomics, how it integrates into the larger AI/Agent/LLM world, because that’s what it claims to be good at.
Prepping the Data Set
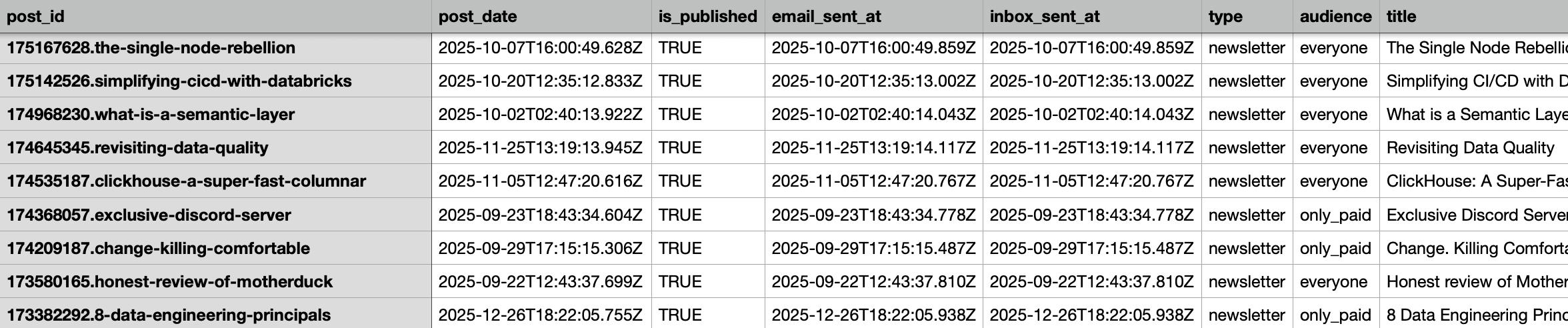
First step, here we go. This is what the exported data from Substack looks like. A CSV file that is a high-level overview of every single post.

Also, a folder with all the actual content of the posts.
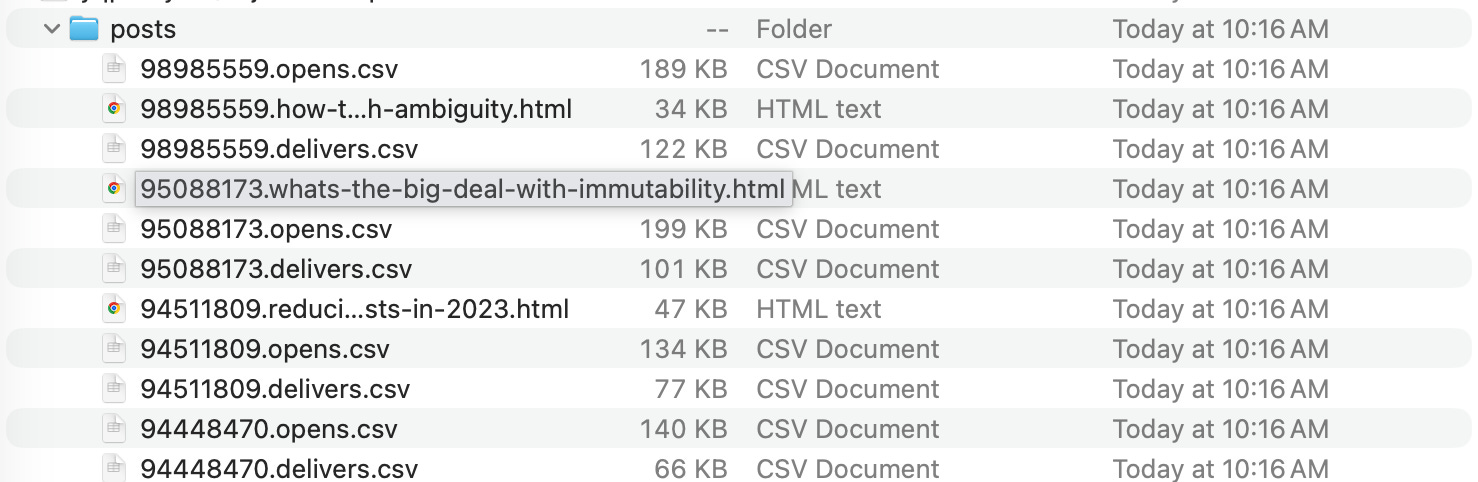
The actual content is in HTML files. This should be fun. So what do we need to do?
Open the CSV file with some tool, filter to published posts.
Get the number from the post_id column of the CSV and map it to that HTML file.
Get our text out of the HTML files.
So in the end I want something like …
post_id | title | sub_title | post_date | blog_textOnce I have things to that point, we can move on to embedding and using Lance to store the data.
Side Note:
Isn’t it interesting that probably the most time consuming and hard part of building an AI Agent with embeddings is actually just normal data engineering?
Here goes nothing, a few utility functions around dealing with all the HTML and Text from the posts.
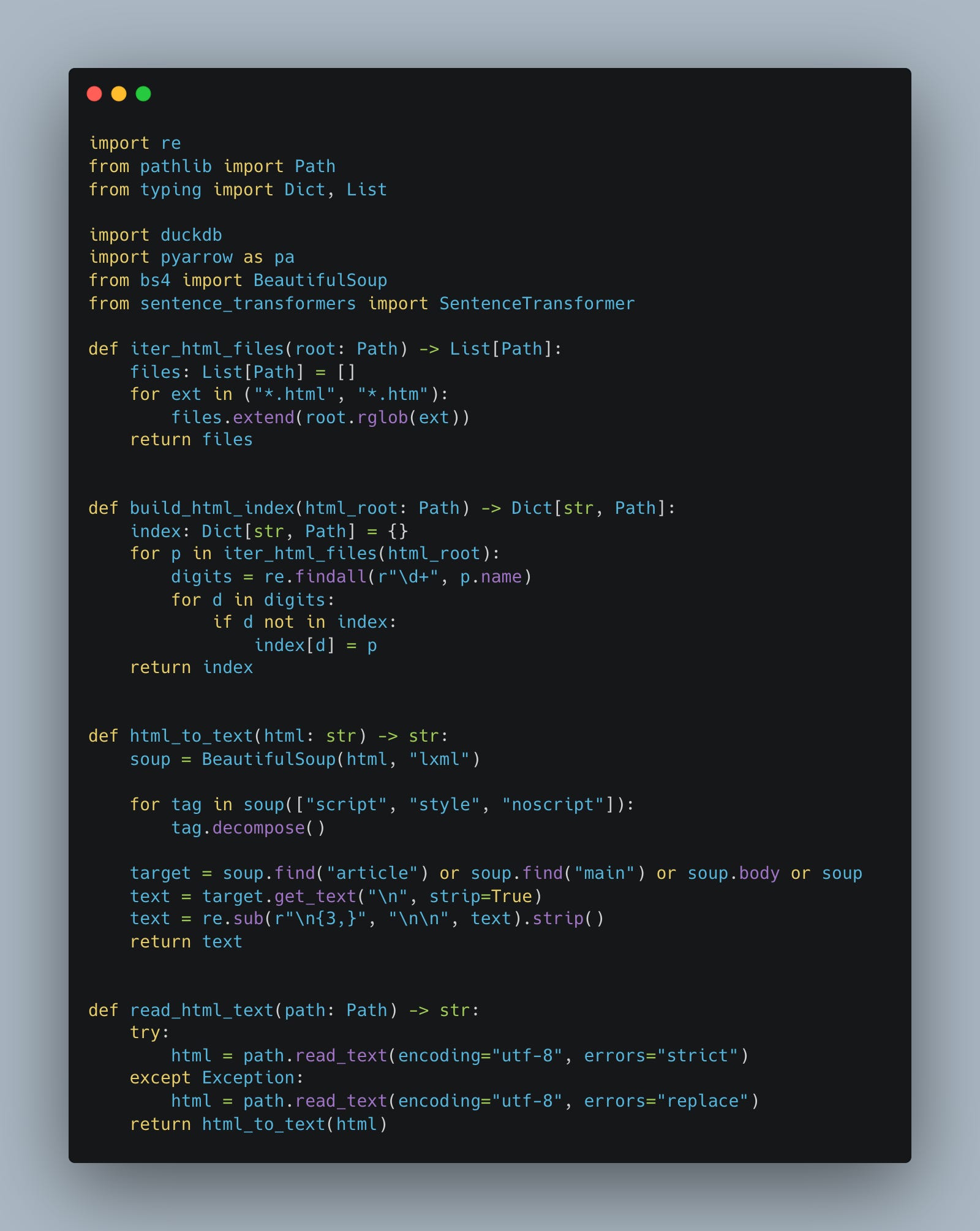
Next, we walk through all the posts and HTML files using DuckDB to build our dataset, which we need to embed.
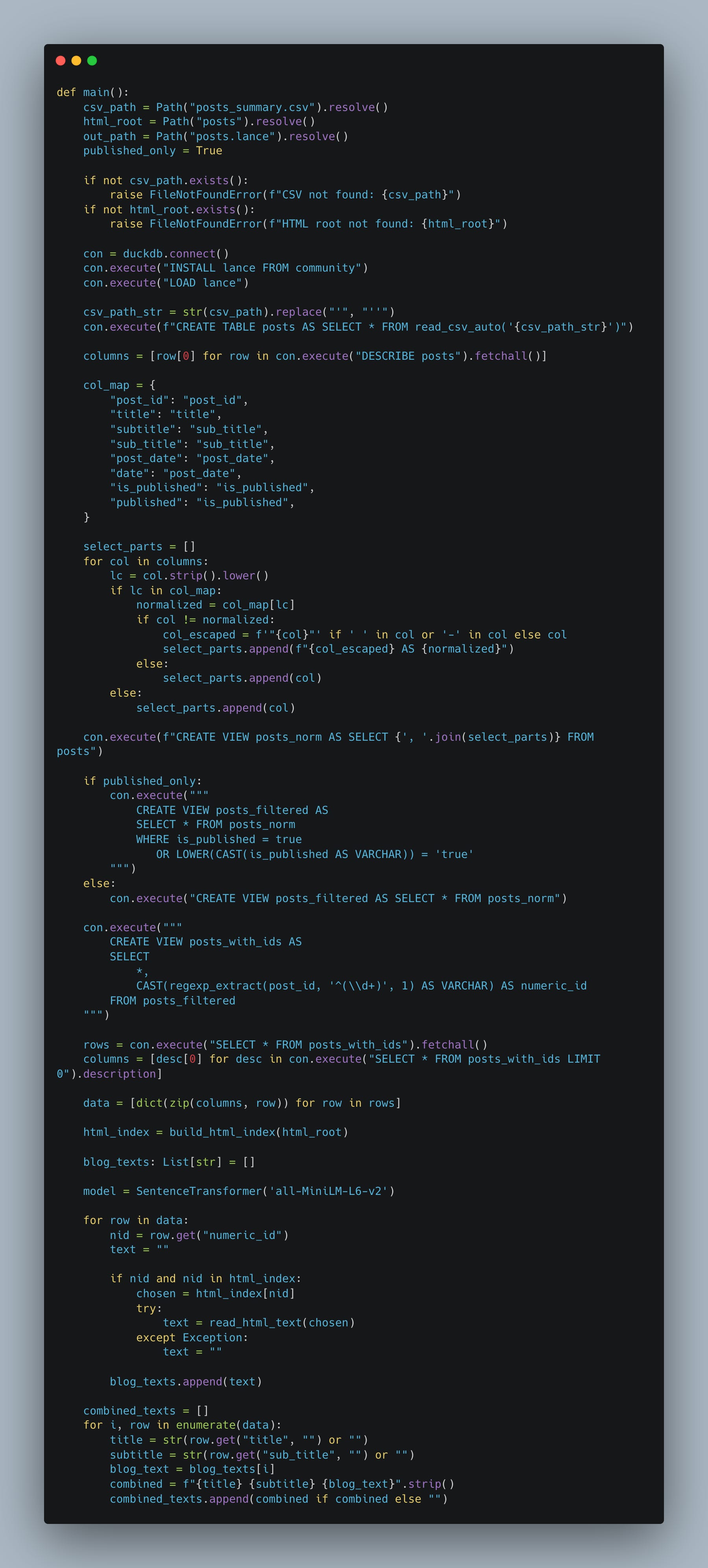
So now we are at the point where we have actually extracted all the text fields into a dataframe, and can start iterating and finally convert the text to embeddings and hopefully store them in Lance.
There is a real reason I'm showing you all this code and minute steps and details to get to this point. Most of the talking heads simply SKIP all this crap.
The actual real Data Engineering, that has to happen at scale, in production, to get the point where you can actually start to embed text into vectors and do something useful with.
You simply don't jump straight from an idea to some AI Agent or RAG that works magically.Here is the part that matters. Lance + embedings.
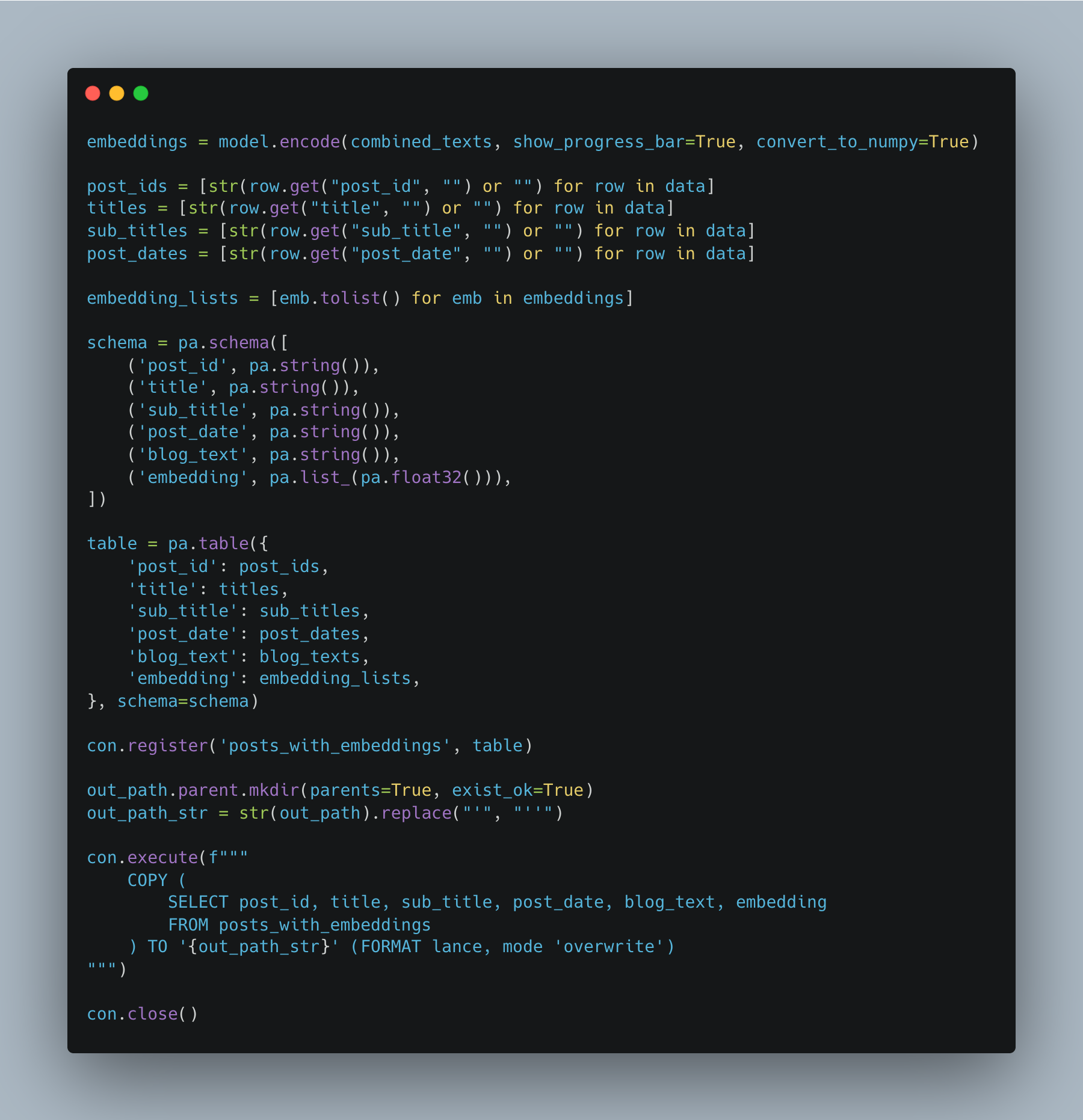
Remember, you can get the full code for this project on GitHub.
Also, I added some timers to the Python code for the embedding + writing to Lance. This, in my experience, is where things start take longer than you can imagine at scale. We are only embedding 290 blog posts, in the grand scheme, not much, and it still takes a few seconds.
Embedding generation took 2.82 seconds
Writing to Lance dataset...
Writing to Lance took 2.77 secondsOn the left side of this screenshot, you can see the Lance dataset.
Just for your sake, here is a script that can inspect our Lance dataset, including the embedded text column from our blogs.
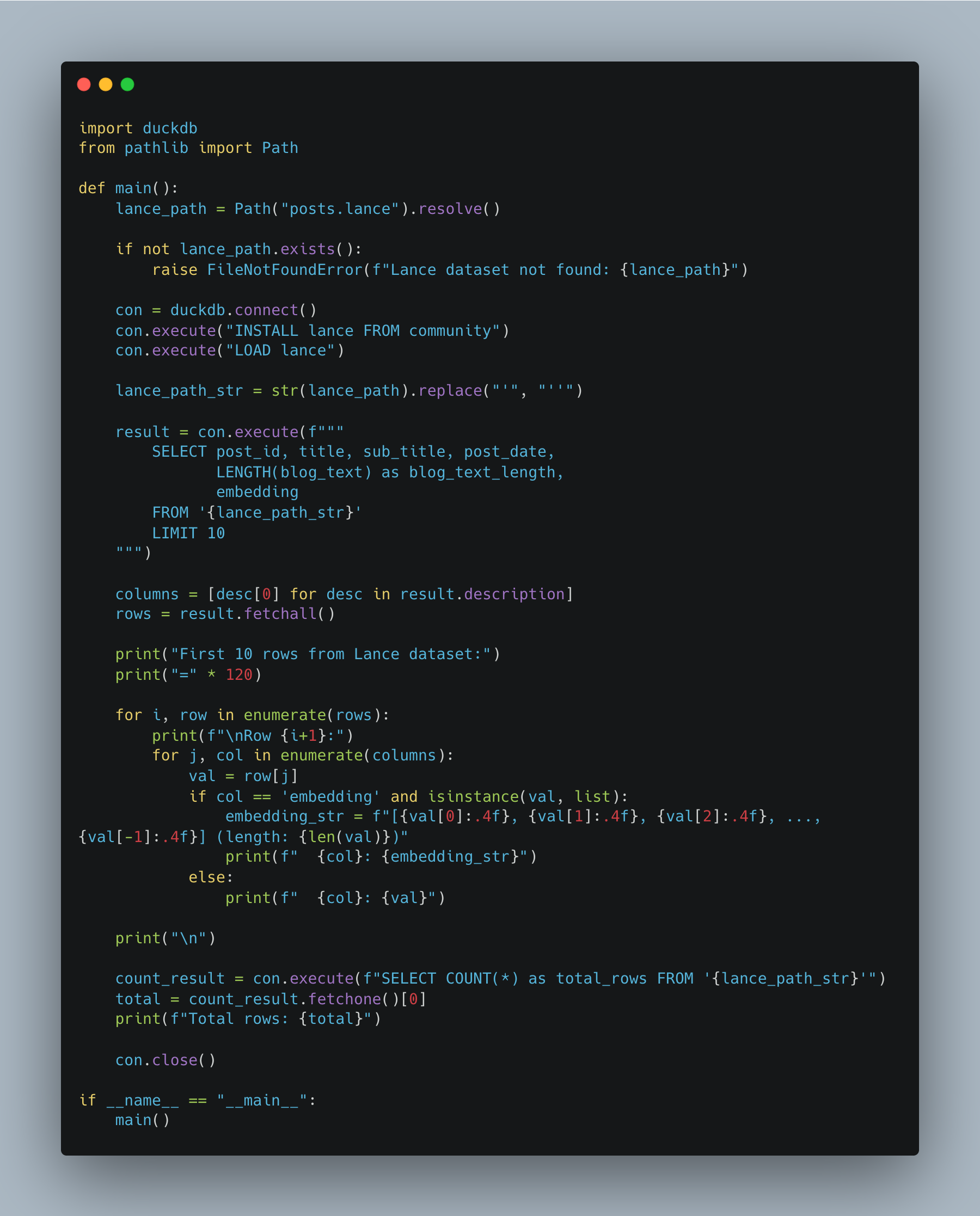
There ya be.
So, now we have something we can work with. Also, I want to stop here for a moment and say that working with Lance for embeddings has been a pleasure so far.
Simple pip install
No heavy architecture or tooling
Works with tools like DuckDB
It just flipping works, no database to host, no nothing. Just acts like a “storage layer,” though I know it offers more than that. I wanted something simple, and I got simple.
Simple tools, simple architecture, it cuts down on complexity, overhead, and bugs.
Building an AI Agent for my blog posts.
I mean, it’s not really an agent, more like a Chatbot with RAG, whatever, the lines get blurred these days. I just want a little command line helper I can chat with and ask … “Have I written anything about this before?”
Stuff like that.
The key is, I want to use my Lance embeddings for context and RAG in this system.
I prefer to use LangChain because it’s the best.

Lo and behold, LangChain does have tools for Lance (including LanceDB cloud option).
(FYI, to run this, you will need an OPEN_AI_KEY yourself)

Heck, not bad for a little this little that, pulling a rabbit out of a hat. It finds my Databricks and Excel post I wrote easily enough. You can check out the full Chat code here on GitHub, nothing special.
Here is the Lance portion of the Chatbot that integrates with LangChain to make the embeddings available. It was quick, clearly no issues.
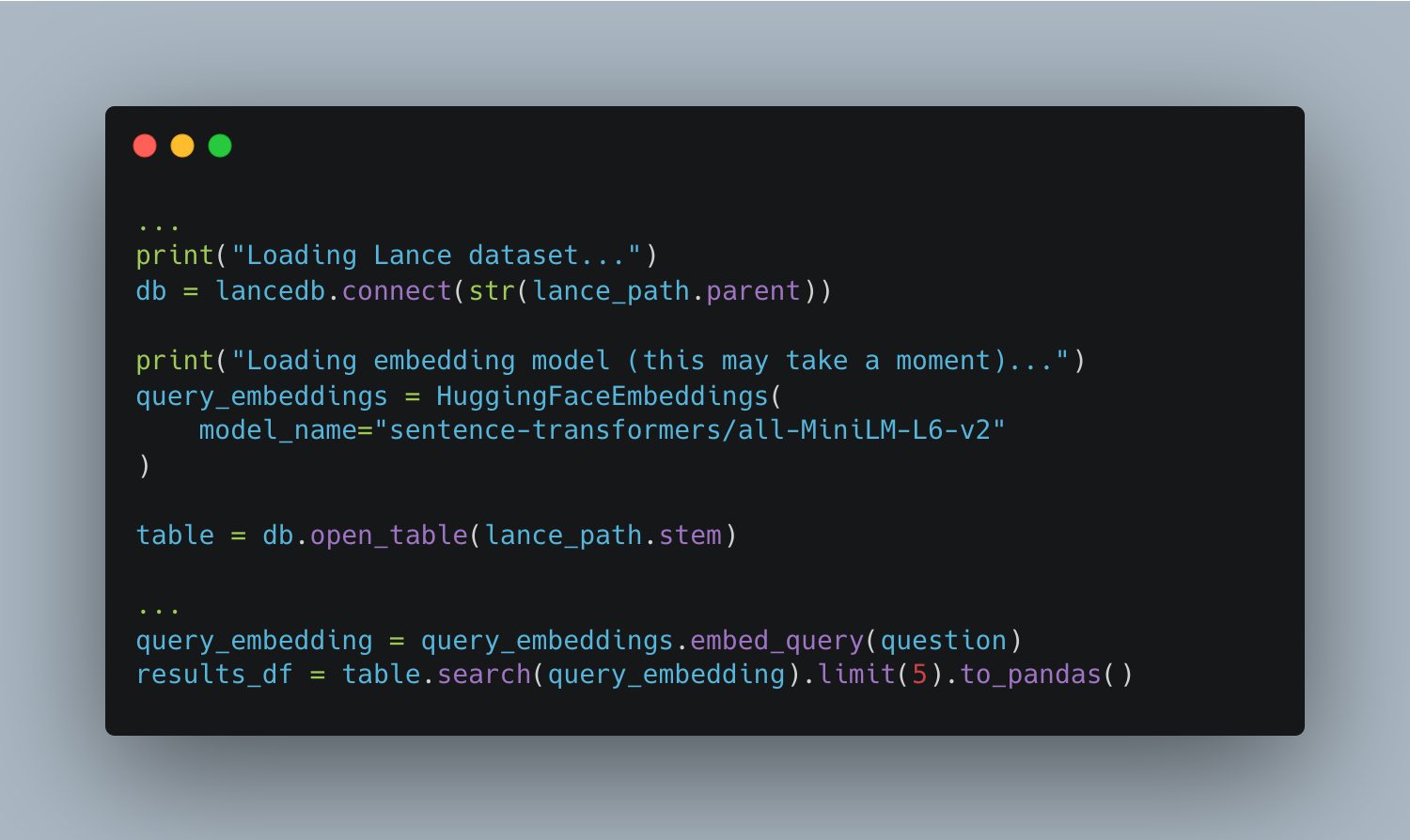
I know we weren’t building a production-grade system here, but this isn’t bad and gives us a great option for using a simple storage-based file layer as a vector and embedding database for our LLM and AI use cases, even similarity search and other use cases.

General Thoughts
I enjoyed my little playtime with Lance! I’m looking forward to finding some production use cases for this simple-to-use file format. I know that Lance is a “Lake House format,” which means it can handle more complex tasks.
I get it.
The problem is that I’ve used way too many heavy and expensive vector databases that turn out to be a big pain to manage, deal with, and pay for. Simply put, the juice was not worth the squeeze.
I simply have to plug LanceDB, even their managed SaaS version. No, I’ve not been paid to say that, just saying, stuff works, ya know?
Give credit where credit is due.

I can’t get enough of simple architecture and tools that just work well and integrate into the wider data community. Lance is a no-brainer.
simple to install
conceptually easy to use
low-key architecture
integrates with data tools like DuckDB
works well in AI workloads with the likes of LangChain
Three huzzahs for Lance.
It's interesting how you articulated the need for something easy for embeddings; I completely resonate with that sentiment, especially when just trying out new AI concepts. While prototying definitely benefits from simplicity, it sometimes feels like the "heavy" tools are designed for a future scale that we're not even close to yet, which is a bit of a hurdle for iterative work!