

LLMs for {PDF} Data Pipelines
a Brave New World


I was recently in conversation with some people about AI, its use cases, the good and the bad, where it fits, and where it doesn’t. It was brought up in the context of reading random PDFs and generating JSON files from their contents.
This got me thinking.
Can you, should you, and what will happen, if we use LLMs not just to puke out the next code snippet … but what if we use an LLM mixed with a little Agentic AI, to actually to BE the data pipeline????
It is a strange thought. I’m sure people are doing it. Maybe. It’s one thing for an LLM to spit out code for a Data Pipeline; it's another for an LLM to be the data pipeline, or at least part of it.
I want to try it. What say you?
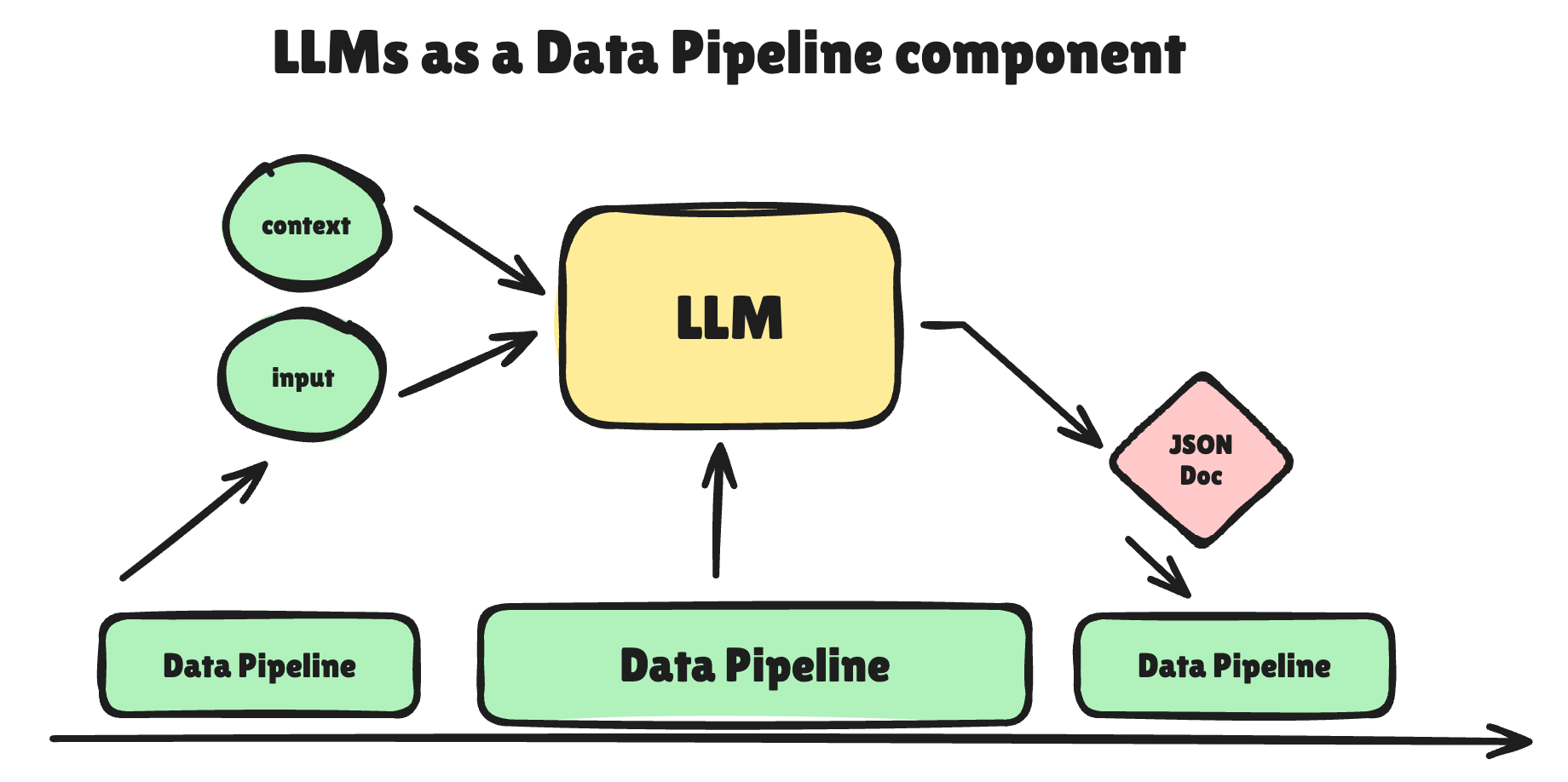
Inserting LLMs into Data Pipelines
I’ve built my fair share of RAGs, vector stores, Chat this Chat that bots … whatever. I also use Cursor on a semi-regular basis, maybe a few times a week, either as something to bounce ideas off of or to generate some mindless code.
One thing I’ve never done is try to use an LLM in the loop or stage of a data pipeline.
This will be new for me, as it is for you, and I am going to list out loud some of the questions I have at large about doing this sort of work. At this point, I have no idea how it will work out.
Some questions I’m asking myself.
I think it’s one thing for me to play around and force an LLM to do a thing by using coercion, glue, and string to make something happen, vs. an actual workflow that could be used in production.
Here’s what’s on my mind.
A small local LLM or a remote API-based one?
Can we force an LLM model to do what we need, or do we need an Agent?
To actually write/place (JSON) files on disk
Are orchestration tools like Airflow starting to provide, say, OpenAI operators?
LLM output is non-deterministic; it can hallucinate at any time.
How do you rely on the output?
How fast or, most likely, slow is it going to be?
That’s enough worries for now, I think. Let’s get out some of that Elmer’s glue and a shoelace and see if we can start making something happen.
Finding an LLM model to use.
Ok, so our options for LLM models. I couldn't care less about flavors, only hobbits worry about that stuff.
Hosted LLM
OpenAI
Databricks Model Endpoint
Small enough local model to run on a machine.
I have had this happen a few times: Google something and get my own website(s) showing up in the results—strange feeling. Anywho, why not go with a local model that fits in the memory of commodity hardware instead of paying a bunch of money for hosting and endpoints, or forking over pennies to Sam Altman? I’m sure performance will be terrible with a local mode, but whatever.
Luckily, or unluckily, about two months ago, I wrote a post about running Llama 3.1.8 B locally, meaning it can fit and run in memory. No giant GPU cluster needed.

So, we will have the code to download and run this model locally. Let’s move on from that part and talk about the file generation problem we want this LLM to solve.
How about we have ChatGPT generate us a few PDFs of what would be insurance policy documents? This is what the job we will give the LLM: “Take these policy documents and extract these data points as a JSON file.”
This seems reasonable and actually helpful in the real world.
I had ChatGPT generate three different full-length, realistic insurance policy documents for me based on fictitious people.
Auto Insurance Policy – Robert L. Kendrick
❤️ Life Insurance Policy – Melissa A. Davenport
🏡 Homeowners Insurance Policy – Whitaker Residence

More or less, this is what they all look like.

I think, because I have no imagination, I'll have the LLM try to extract basic info from these PDFs …
What kind of policy document
Who it is for
How much is the coverage
Should be interesting.
Writing our AI Agent for PDF → JSON extraction.
This process is going to have to be an AI Agent approach, simply because calling an LLM back and forth is an exercise in tokens. Llama doesn’t know what a PDF file is; it only understands strings of tokens.
Oh, but don’t worry, AI will take our jobs.
Anywho, into the breach, my friends, let’s get coding. If you’re not using UV for Python projects, I’m going to call your mom and tell her.
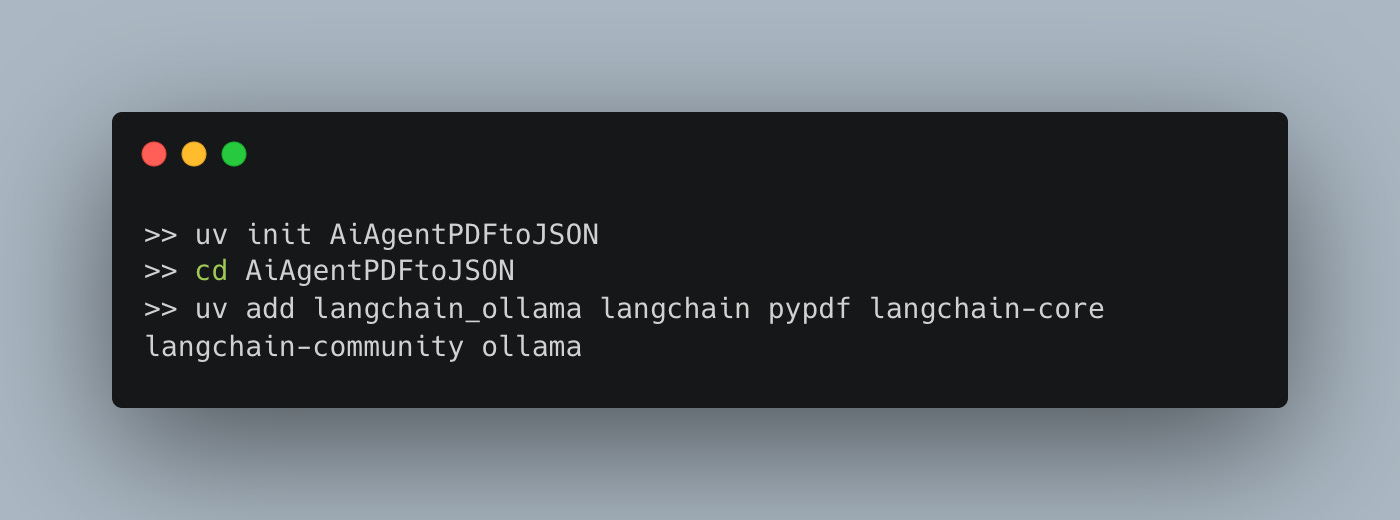
And to get ollama locally, read on.
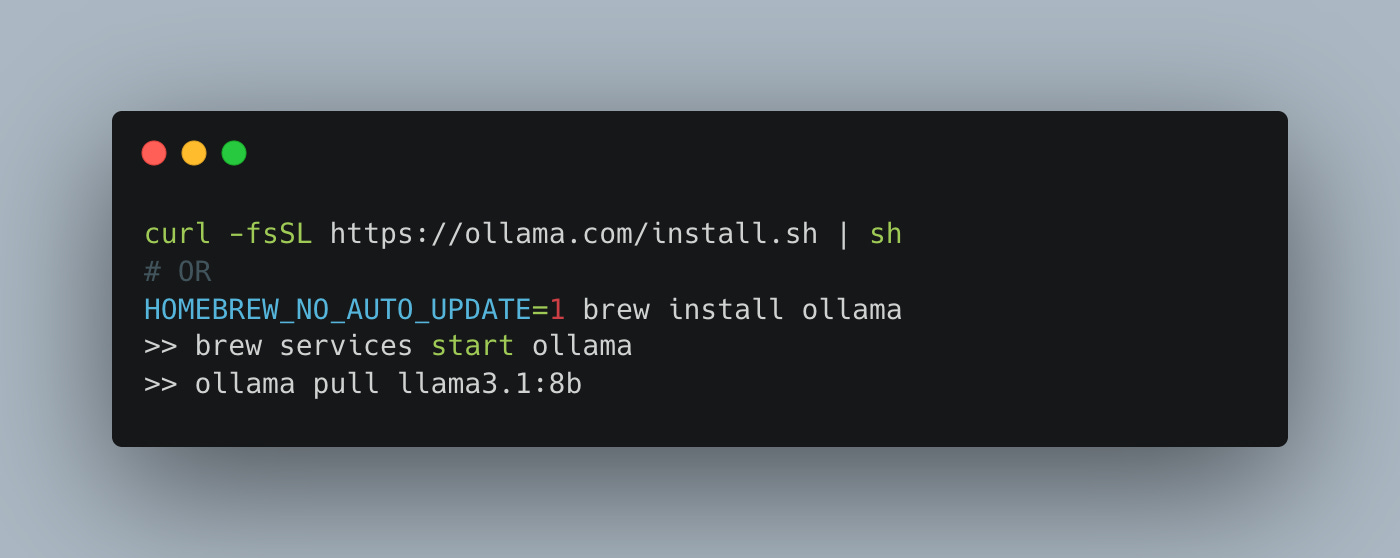
Blah, now to write code. At a high level, what do we need to do?
Iterate through the folder of PDF documents
Extract the text from the PDF
Send text to LLM with prompt
Get results
Write results to JSON file
Sounds like just another data pipeline. Maybe it is, and this is all for naught. Sounds boring.
Let’s try to make this as normal of a “data pipeline” as possible. Here is our main entry point, and a nice obvious list of functions to call that will get us from a folder of PDFs, to another of JSON files.
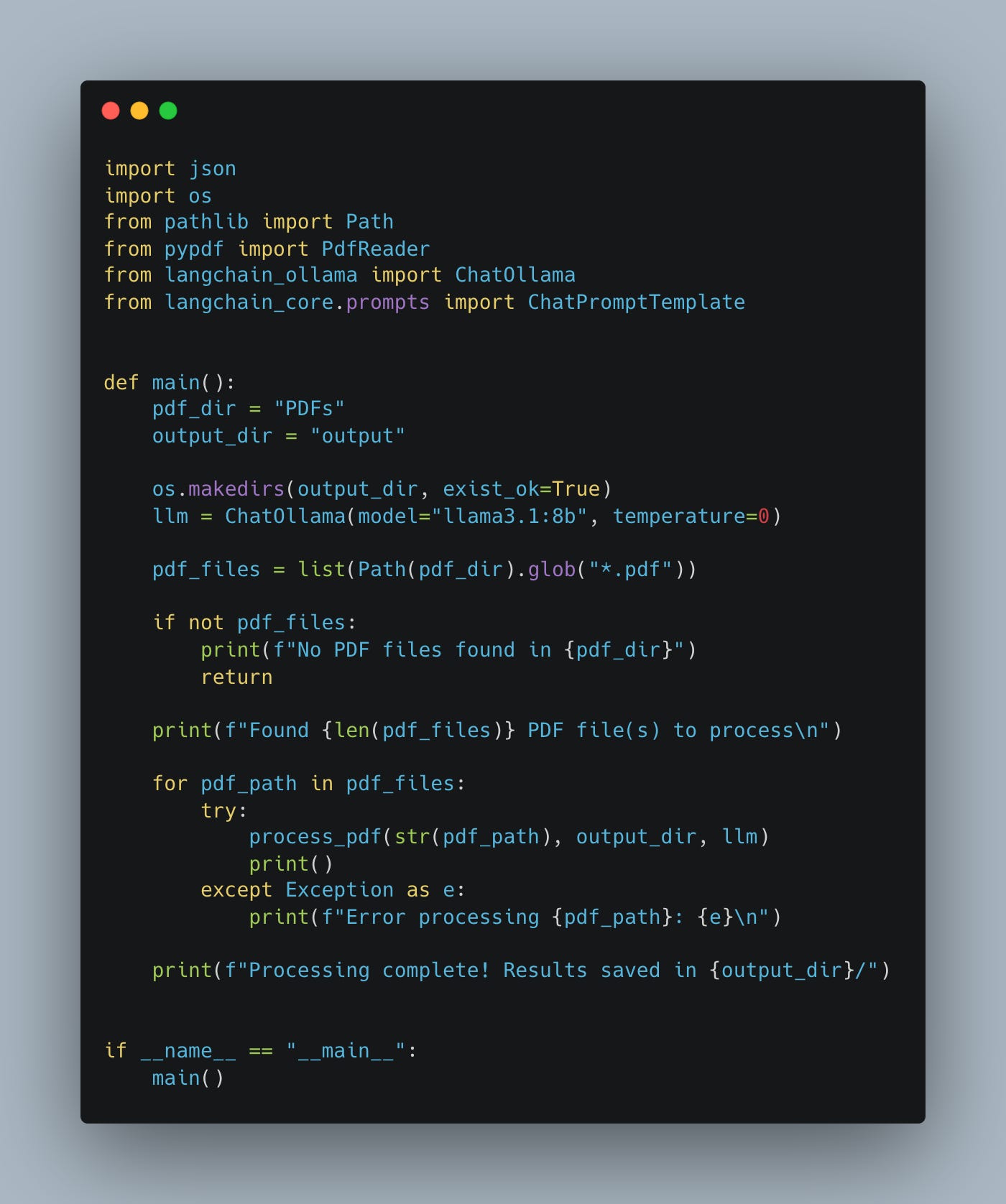
Told you this would be boring, iterate files … yay. Let’s crack open process_pdf() to see the what’s cracking. This is the part of the “Agent” (I don’t think I would call this an agent) that would be very specific to PDF processing.
The theory is, if this code as a whole worked well, we could obvuscate some of the functionality, and simply put it behind an API or Service where we could call it and say “here is a PDF, pull x, y, data as a JSON file.”
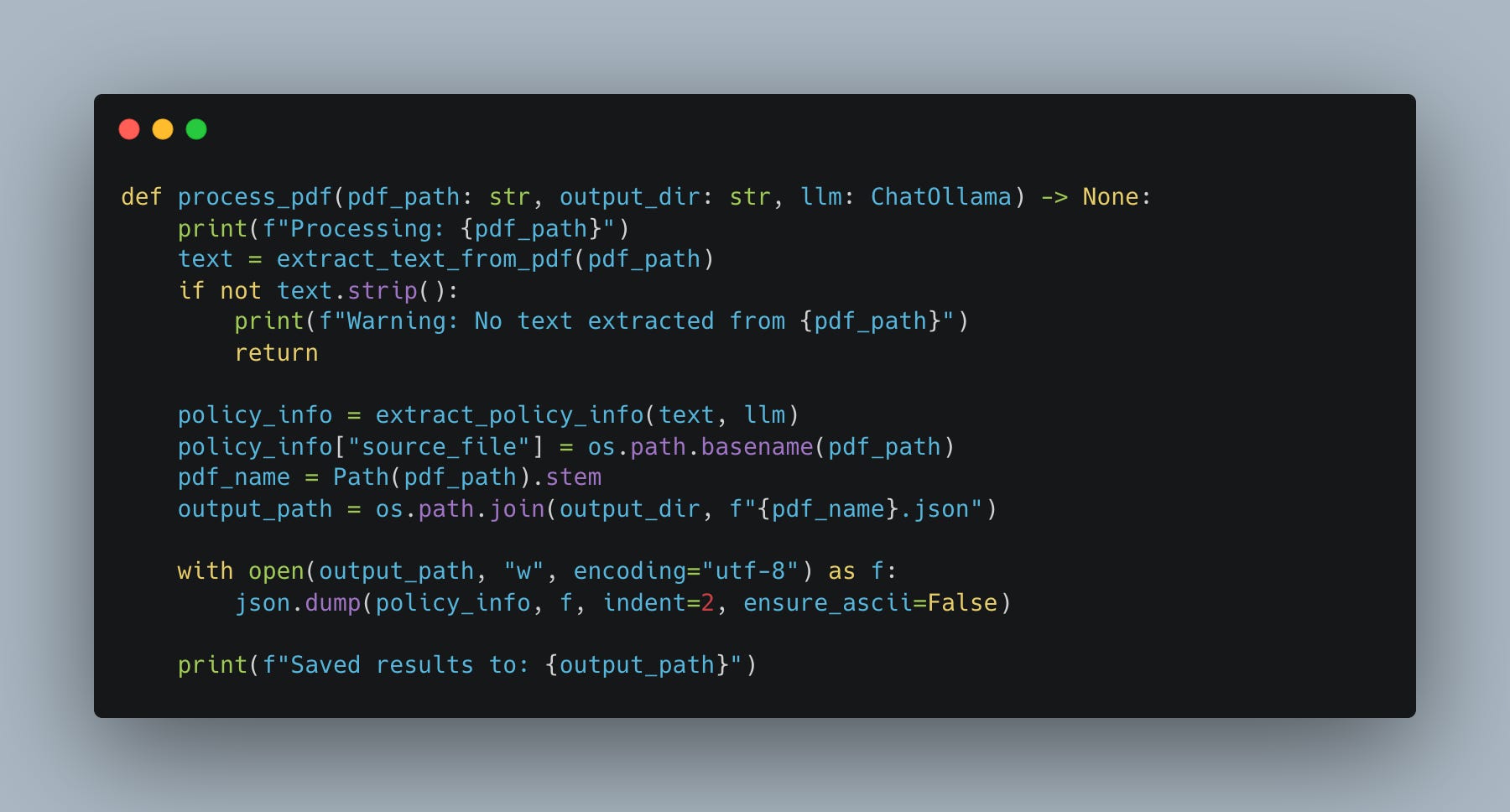
The extract text from PDF is just boring Python.
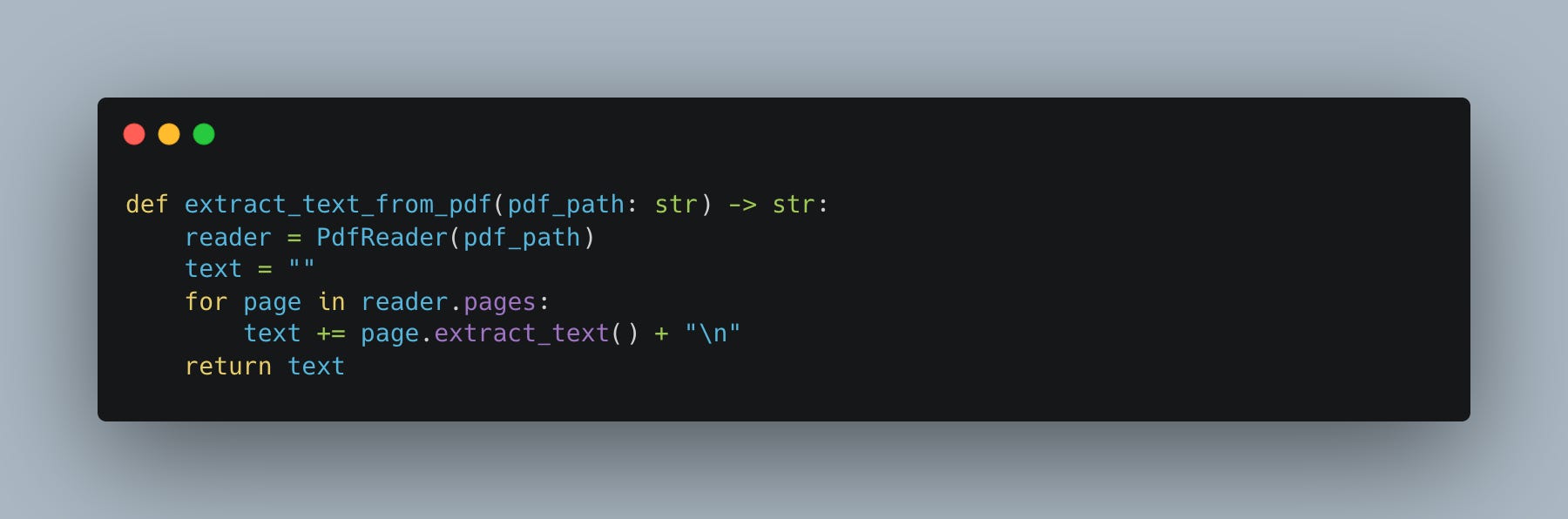
The next part is where we actually incoporate the LLM/AI into the mix of this data pipeline. Interesting indeed.
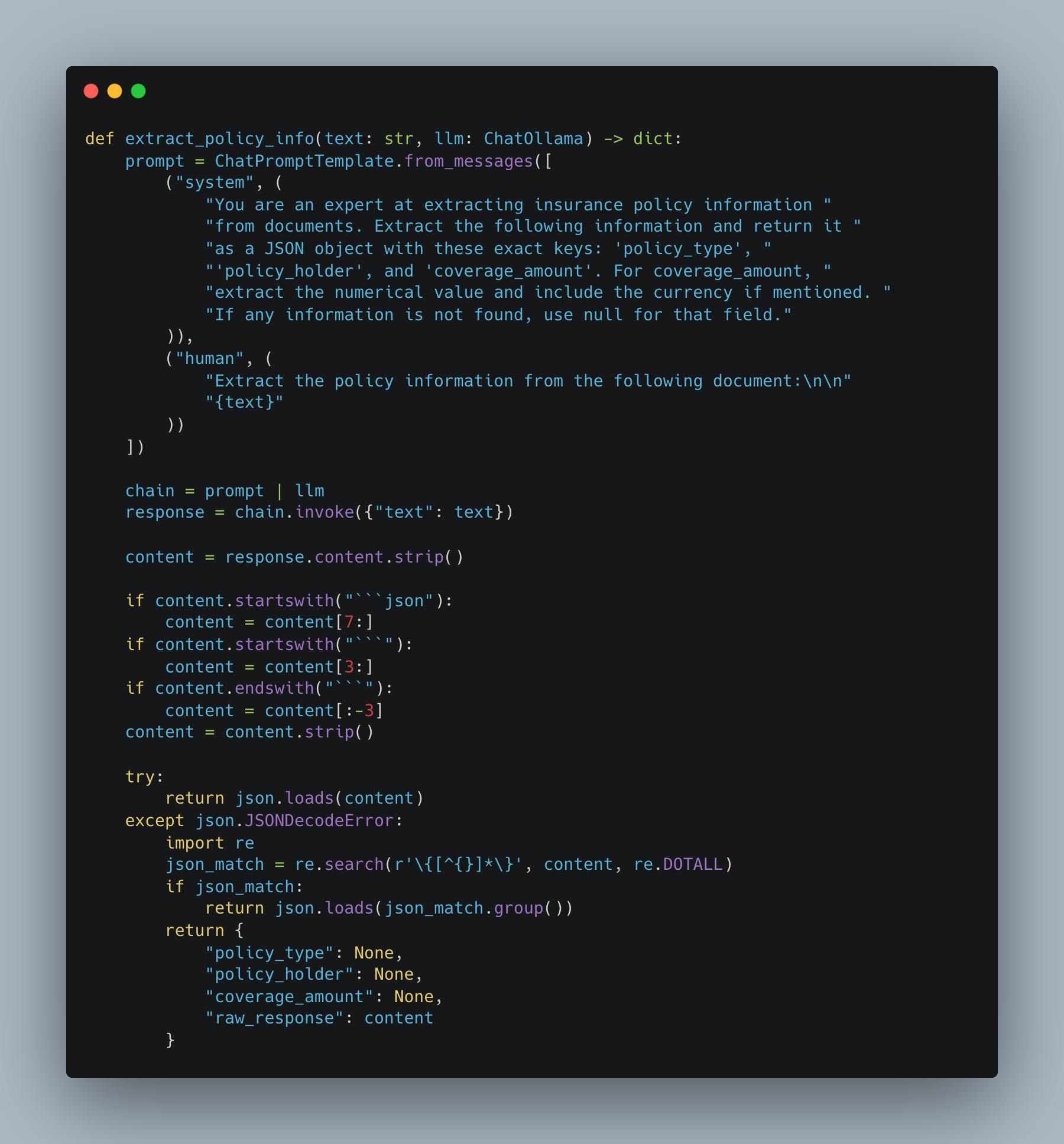
Strange mix of prompting the LLM, and then pulling what we need from that response, as JSON of course. The rest of the code, as per above, is just writing that JSON out to a file.
It’s slow, but works.
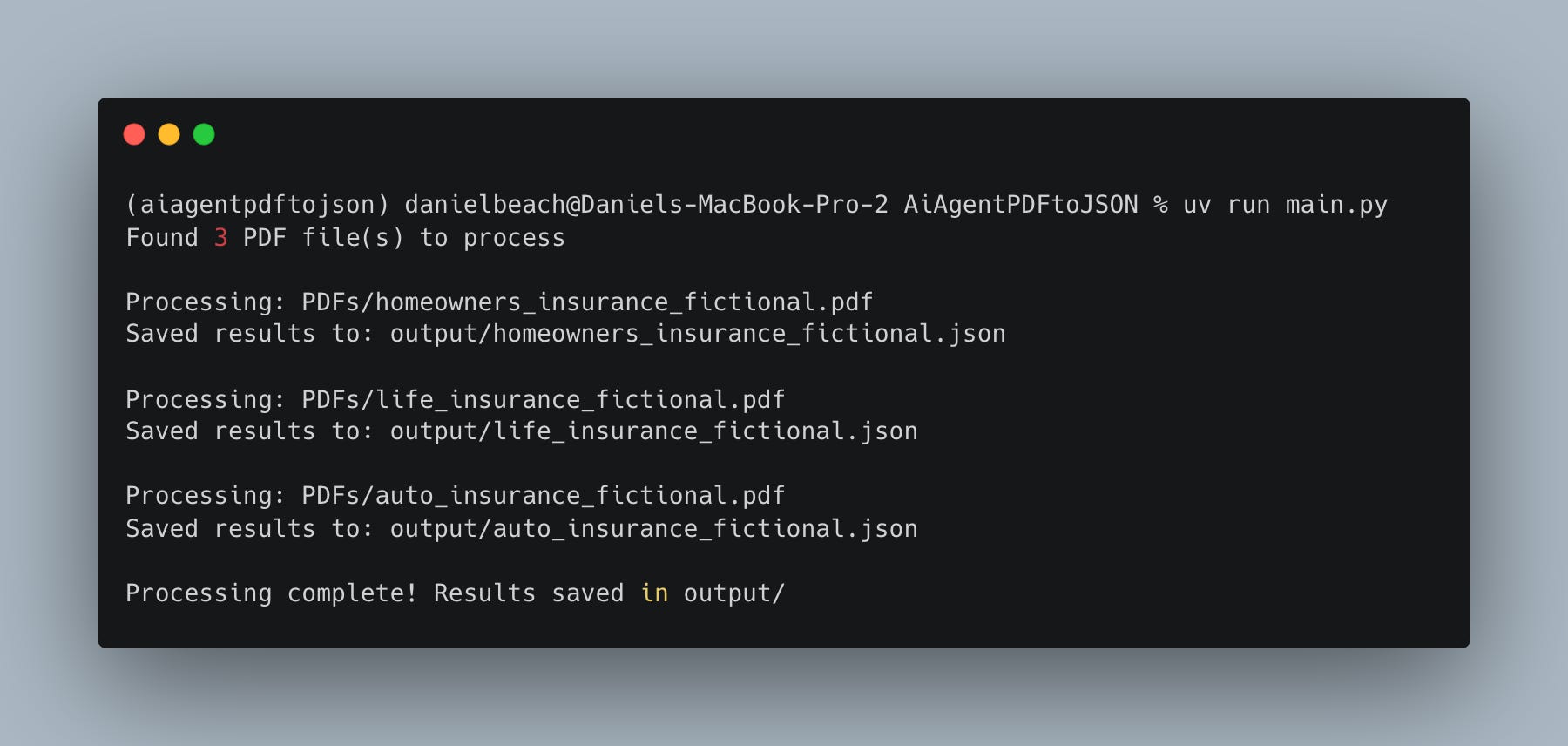

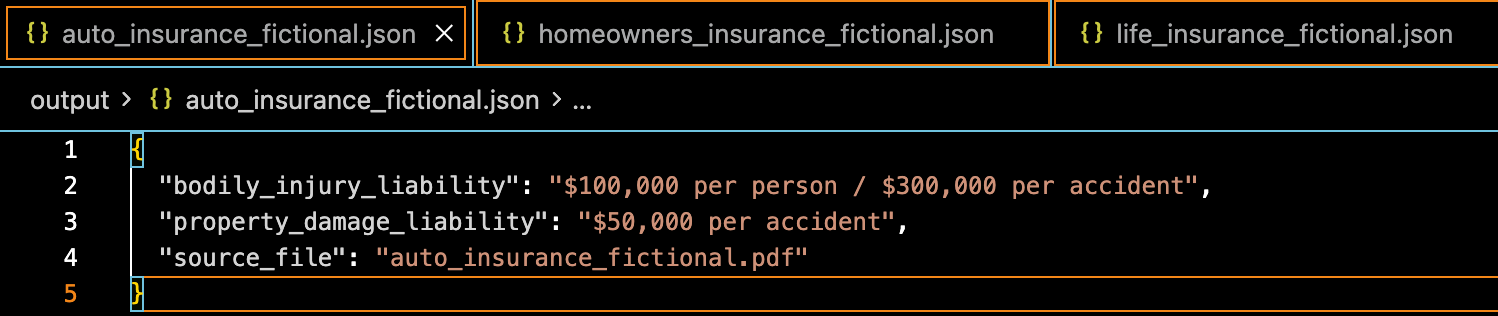
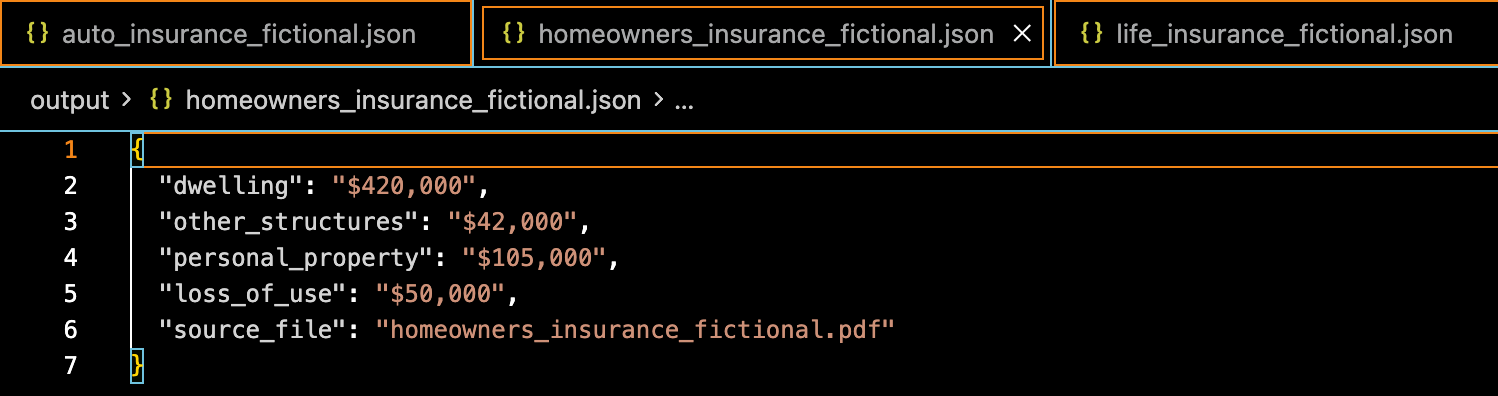
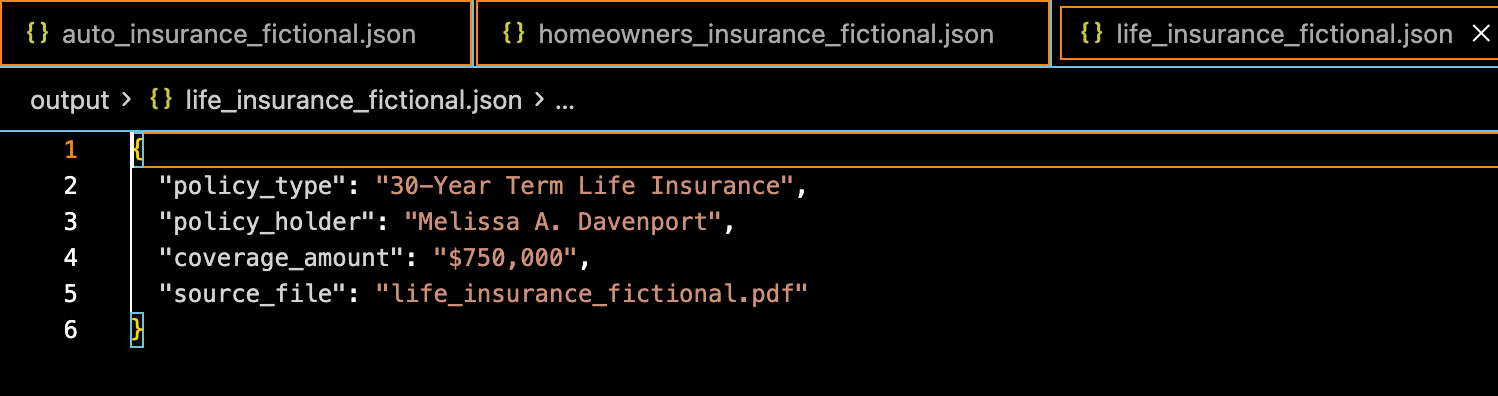
I mean, not sure what to say, seems to work fine enough. Of course this is a little play example, who knows how it would act in a more complicated situation, with more complicated documents, are more difficult things to find.
Running local LLMs is always slow, this was slow, but whatever.
But, at the end of the day, we did write a data pipeline incoporating AI into our workflow to do an important and helpful task.
If you want to play around with this, it’s all on GitHub.

Musing on AI/LLMs as PART of a data pipeline flow.
This was not what I expected at all, to be honest. I’ve a love hate relationship with AI, but it mostly as to do with finding GOOD use cases that are useful for whatever problem.
This went way better than I expected in the beginning, although I’m not sure why I expected to to be “bad".”
Call me whatever you want, this seems to me, to prove that AI and LLMs have a TON of room to grow in regards to sovling everyday, boring, systems automation and even as a way to reimagine workflows and data pipelines.
Of course there are all sorts of “problems,” or maybe issues that need to be overcome. How do we keep the hallucination and quality control in check for this data pipeline?
When we write “normal code” it is very structured and determinisic
LLMs seem to be very undeterminstic and “uncontrolable.”
But, if we don’t care if some of the PDFs go wierd, does it matter? Depends on the business context, if the LLM does great 99% of the time, the business might not care about the 1%.
It also gets me thinking more. What other kinds of things could we use LLMs for in a data context, besides just generating code. I mean this is the whole rise of AI Agents for everything under the sun. Just seems to me, many times, the use cases are sorta unhelpful and toyish, more than real value.
Processing millions of PDF documents to pull semi-structured data out with just a prompt. Well … that is going to be valuable to someone, that’s for sure.
Let me know what you think about this, AI in general, how you are using LLMs, found any fun use cases? Have you incorporated AI/LLMs into more workflows than just “give me code?”
Drop a comment below.
Very interesting article, thank you for it!
I strongly agree with the 99-1 per cent ration and how it still holds lot of value even when it makes mistakes. I mean, if I was just doing that few mistakes consistently, I would be happy with that :D.
Jokes aside, what bothers me as a programmer is the seemingly indeterministic results. What I mean by that is, I can live with the 99-1 rate, but I need to be able to constantly test it is only that small portion of mistakes and have the confidence to propagate my solution into a production grade environment.
Solid experiment on blending LLMs into acutal pipeline logic. The rlei nondeterministic output seems like the real blocker for prod workloads unless theres a validation layer after extraction. If the LLM hits 99% accuracy tho, thats probly good enough for most biz contexts where paying humans to manually extract PDFs would cost way more.