

Polars GPU Execution. (70% speed up)
to the moon


: TDLR
Just when you thought that Rust-based GOAT data processing tool known as Polars could not get any faster … they go and add GPU to the mix.
“One of the core philosophies of Polars is to utilize all available cores on your machine. One type of computation core that makes up a lot of the compute power is in Graphics Processing Units, or GPU.”
- Polars
So, this either means everything or nothing. Not sure. It’s hard to know when new stuff like this comes up if the masses are the target (the everyday Polars users), or some massive customers running AI and ML GPU workloads inside data centers.
The Polars GPU engine now supports datasets larger than GPU VRAM seamlessly using Unified Virtual Memory, thanks to smart memory management via RAPIDS’ RMM. You can process massive datasets that exceed VRAM, at only a moderate performance trade-off—especially when using pooling and prefetching. And it's all configurable with minimal code changes.I mostly care about PERFORMANCE in the context of a normal Polars user like me.
Can this GPU execution help workloads in general? Does it speed things up? Does it slow things down??

Join Beyond Analytics, a virtual DataOps conference presented by Astronomer, on September 16 for a half-day of virtual sessions where data leaders share how modern DataOps and orchestration are powering AI, ML, and production-grade data products beyond analytics.
What to expect:
Apache Airflow 3 Crash Course with Marc Lamberti to prep for the certification exam (includes live Q&A + $150 free exam code)
Hear from data leaders at Ramp, Laurel AI, Airbrx, and more on how orchestration is driving AI adoption, powering GenAI pipelines, and connecting data strategy directly to business outcomes
GPU processing with Polars?
This is going to be a little weird to test, and I’m no expert, just a boy in a cornfield playing around. I have an M4 MacBook that we can use for the first test. Depending on how that goes, we can also try spinning up some GPU resources on Linode and give it a test.
So, this whole GPU processing thing appears to be super straightforward with Polars, as far as I can tell. Well, simply until you start looking at the Benchmarking code on GitHub.

But at least the benchmarking code gives us somewhere to start. Let’s just start with a benchmark query in Polars we can run a few times and get a baseline of performance.
The Baseline.
I want to talk as much variability out of my homegrown test as possible, so let’s download a bunch of data locally, and skip s3 to take network IO out the picture.
Let’s use Divvy bike trip data, from 2025 so far.

Also, in case you are not already, you should, like me, be using UV to make Python development suck less.
uv init polarsGPU
cd polarsGPU
uv add polars
uv venv
source .venv/bin/activateNext, let’s just count the number of records we are dealing with, how many rides have happened on Divvy in 2025 so far?
2,904,857That ain’t going to cut it Sunny Jim, let’s pivot towards the Backblaze Harddrive dataset, it’s free also, and much larger. Appears we can look at all of 2024 and get about 40GBs on disk to play with.

That should be enough to maybe tease out some Polars GPU vs Non performance if we are lucky. Time will tell.
Cracks in Polars already.
Ok, so we have 4 subfolders (one for each quarter) with 90+ CSV files in each other them. 40GBs in total.
What do you think the chances are that the schema over 400ish files match across all those CSVs? About zero.
So what happens polars when you do a simple read?
Yeah, well, of course they are different you hobbit. Apparently, excuse my lack of knowledge of Polars, you can’t simply MERGE schema mismatches.
You can see the maturity (lack thereof) of the product here.
Well this is dumb. What other option do I have than simply create my own schema and pass it in?
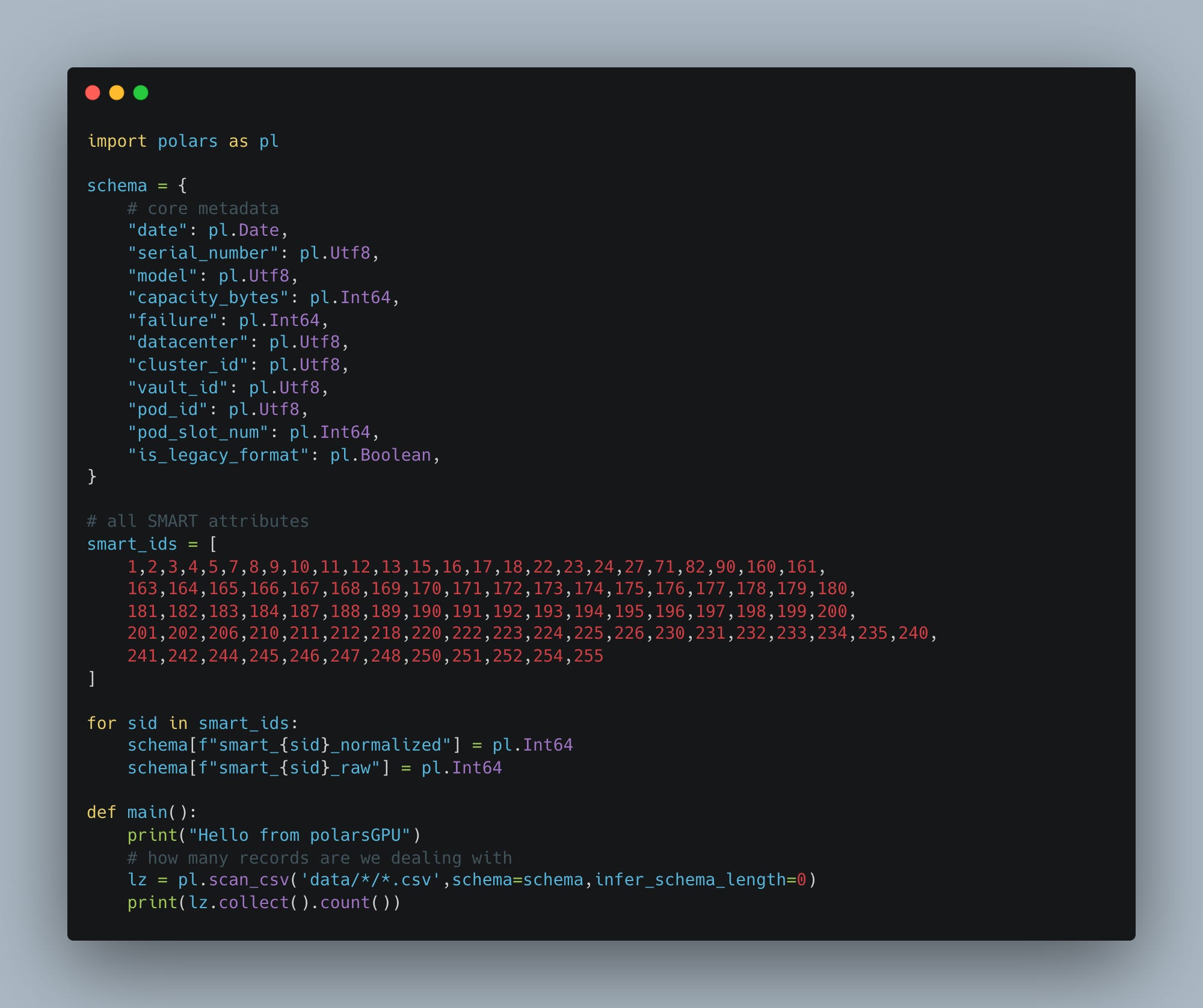
This sucks and I would prefer not do this, but this is the schema.
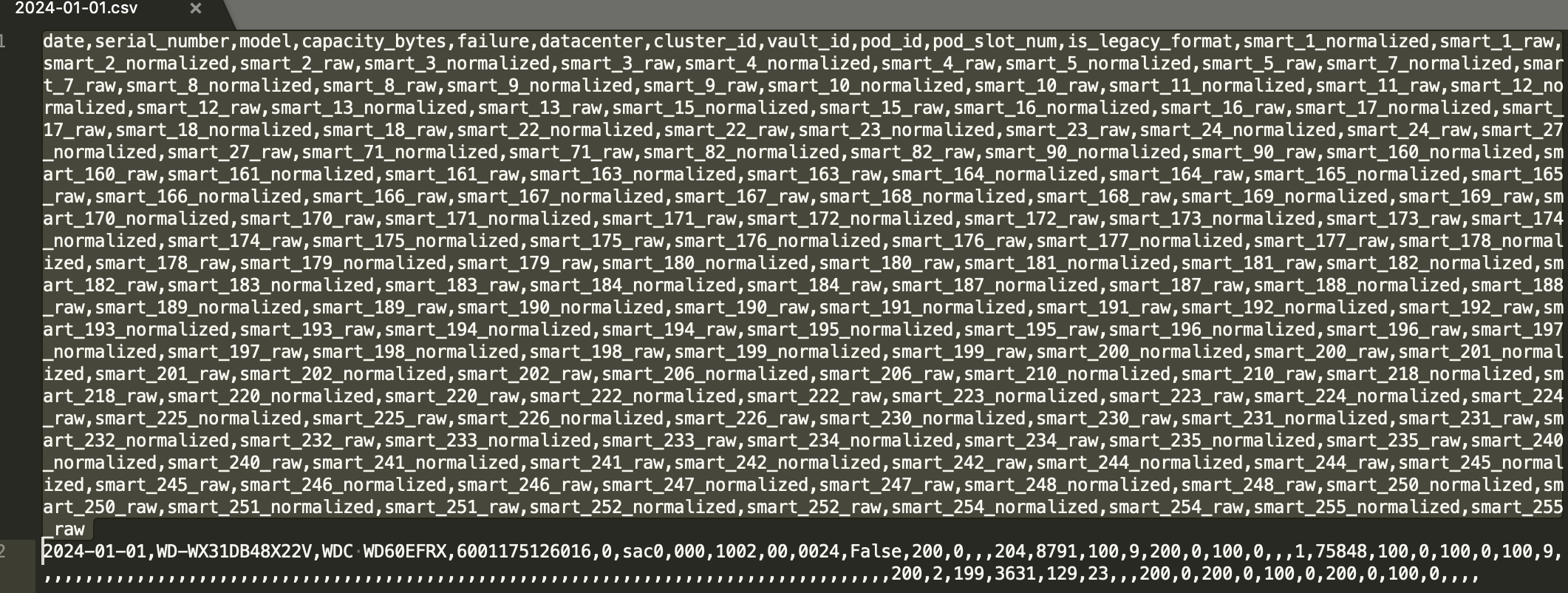
But, if we look through the Polars code on GitHub for these methods for reading CSV files, there is no options for merging schemas that I can see.

Digging Deeper
After digging around a little harder on Google, I found this little open Issue on the Polars GitHub, that seems to be similar, with a nasty ole’ solution.

Here is that modified code for my use case.
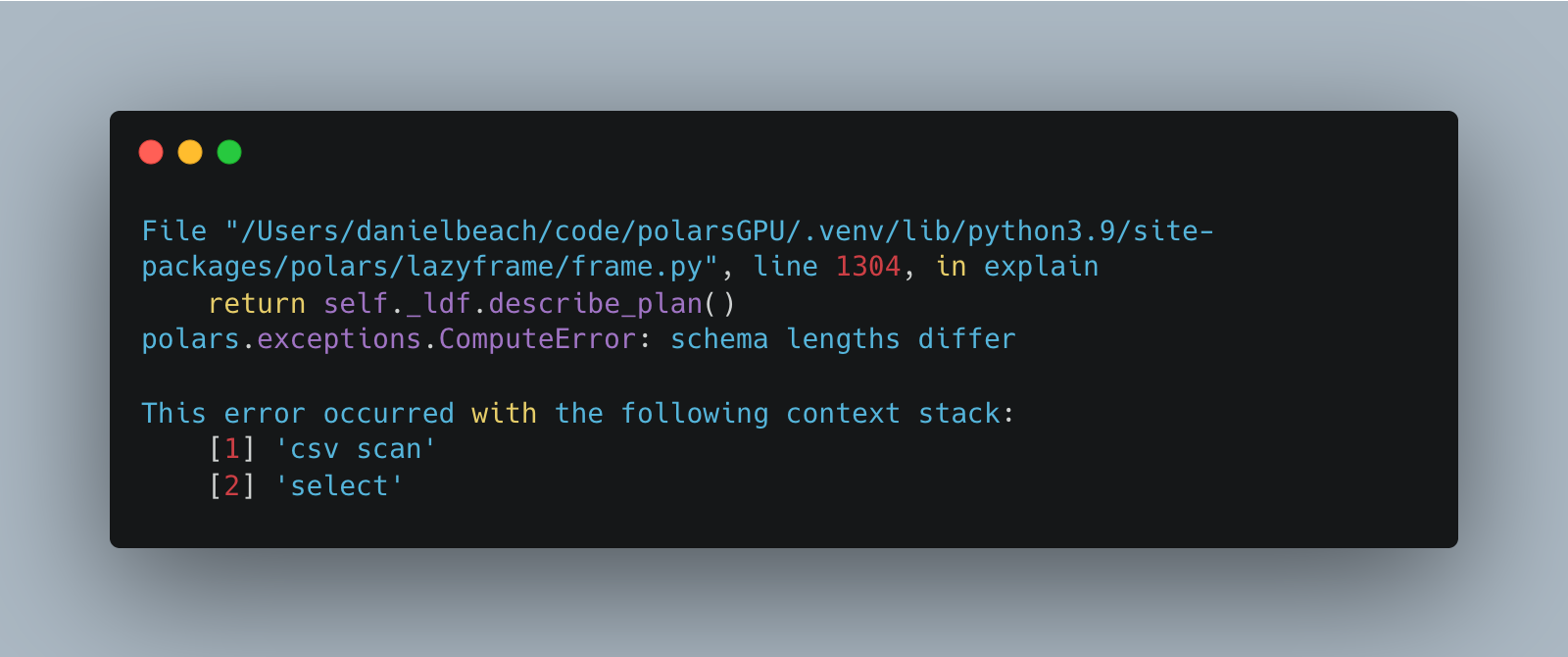
No go, still fails.
polars.exceptions.ComputeError: schema lengths differ
Resolved plan until failure:
---> FAILED HERE RESOLVING 'sink' <---
Csv SCAN [data/data_Q1_2024/2024-01-22.csv]So, back to the drawing board. I used a little munging around to figure out which files in which folders had the “extra” columns. Adding this “extra” columns into the original schema and code will hopefully let the code run.
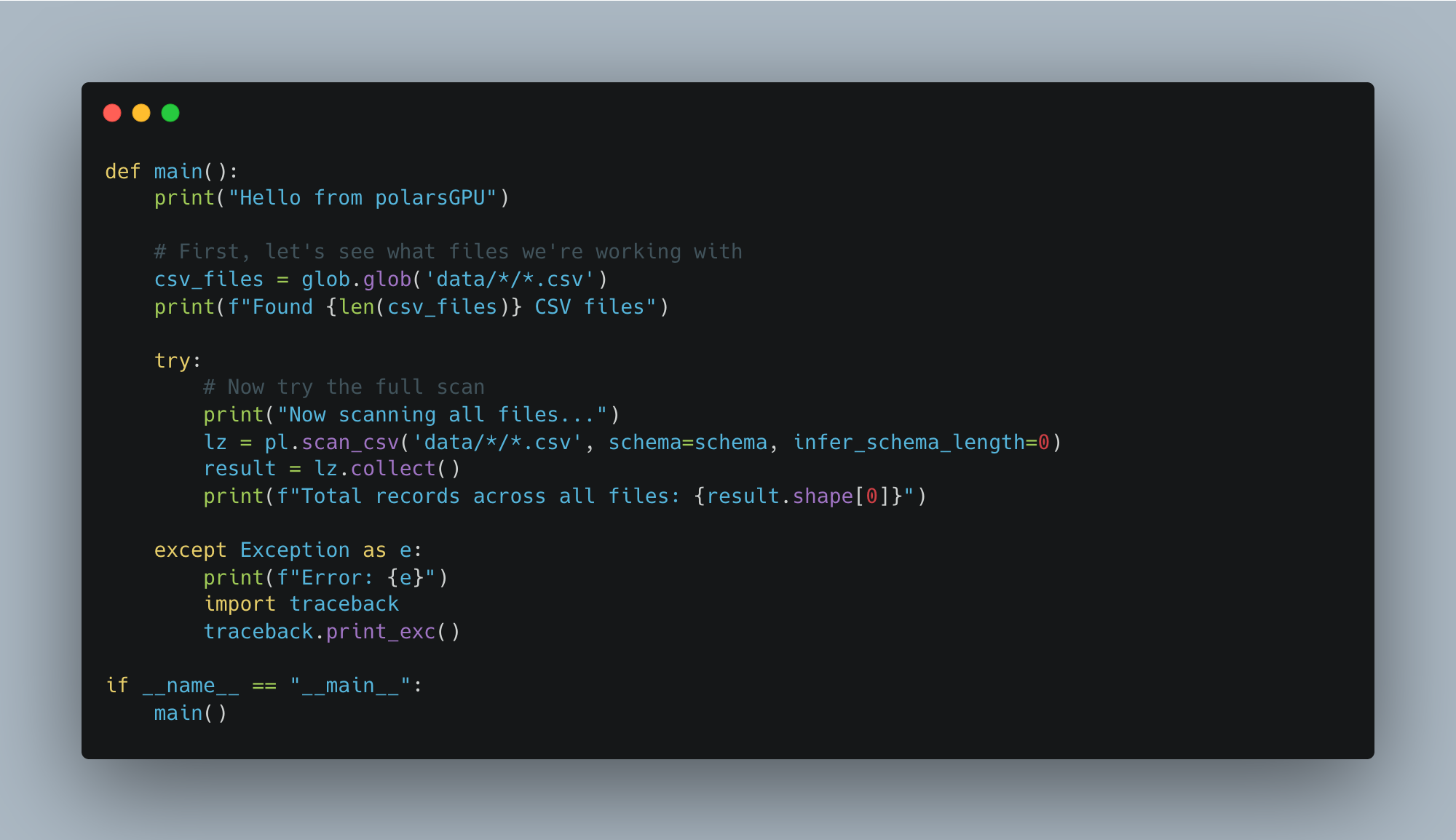
Opp. OOM errors, of course, I’m sure the .collect() tries to materialize the entire 40GBs into memory. The scan_csv() we are using is Lazy in nature.
Let’s just select a single column, the first one, collect() that and count().
And results!!!
Hello from polarsGPU
Found 366 CSV files
Testing schema with first file...
Testing with: data/data_Q4_2024/2024-11-02.csv
Now scanning all files...
Total records across all files: 105,379,761Jezz, took a while to get there. Let’s do a simple aggregation and get a baseline for Polars’ performance.
Polars aggregation performance baseline.
So, we will write a simple aggregation for Polars that we can run and get a good baseline of performance, so when we get to GPU execution, we can see if any real difference is made.
To avoid any local cache of data that the operating system will do, I will run the code twice, discard those results, then run it three time again and log the performance metrics.
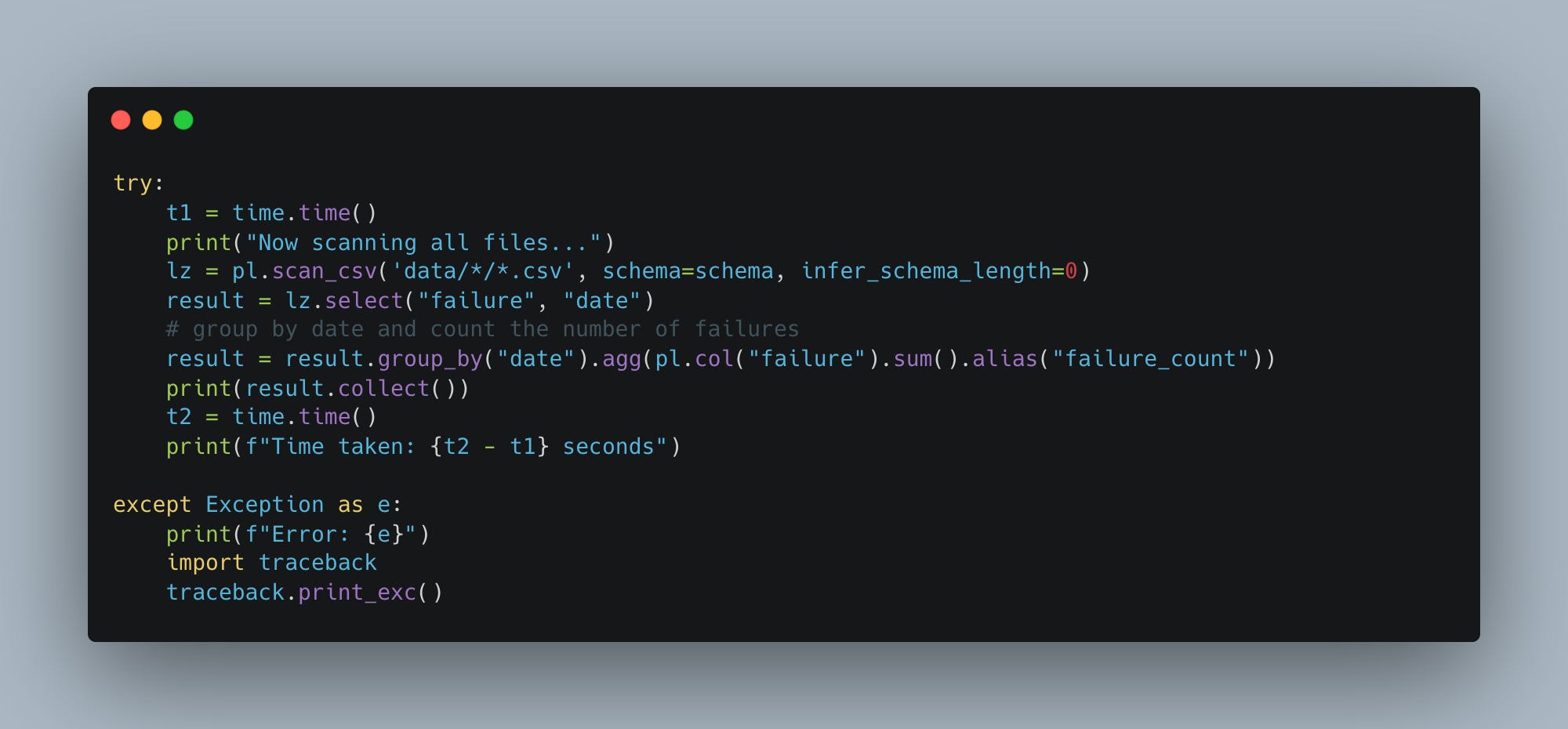
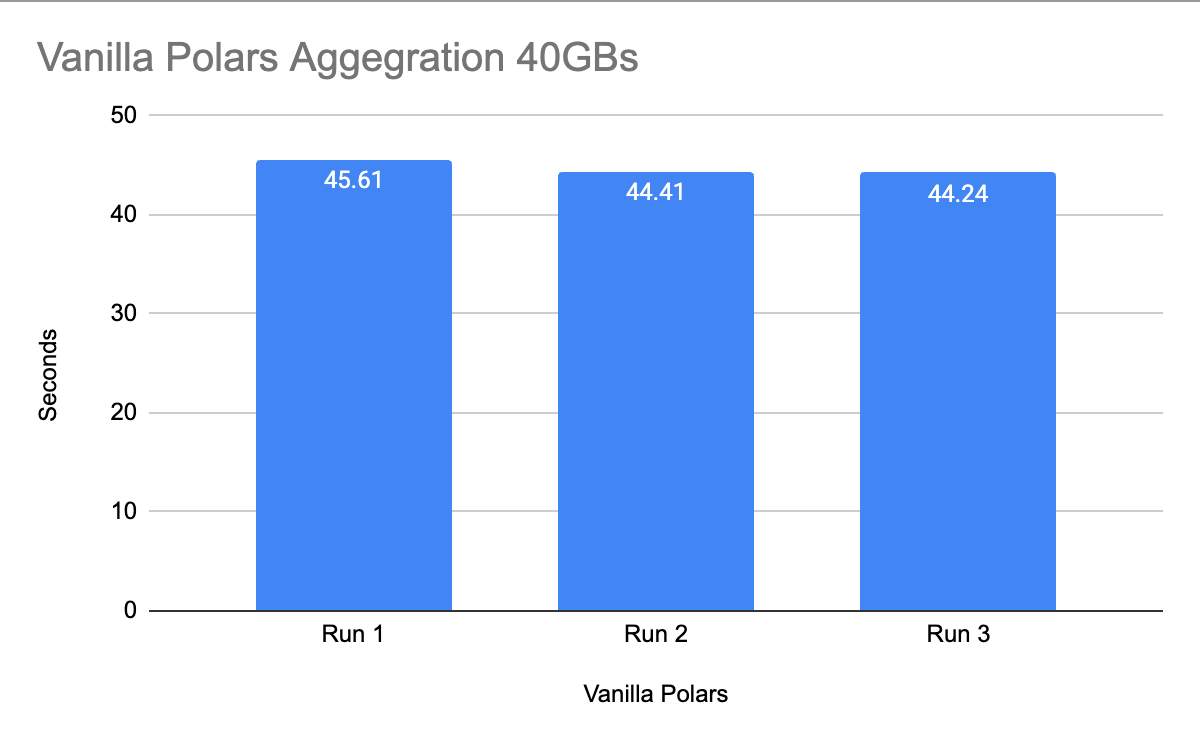
There you go, 40ish seconds for vanilla Polars doing 40GBs worth of aggregation.
GPU exceleration with Polars.
Ok, so here comes the hard part, can we get this to work, or has this all been for naught. That’s nothing new to me, that’s the price you pay when you poke at new stuff.
uv add "polars[gpu]"And our first error.
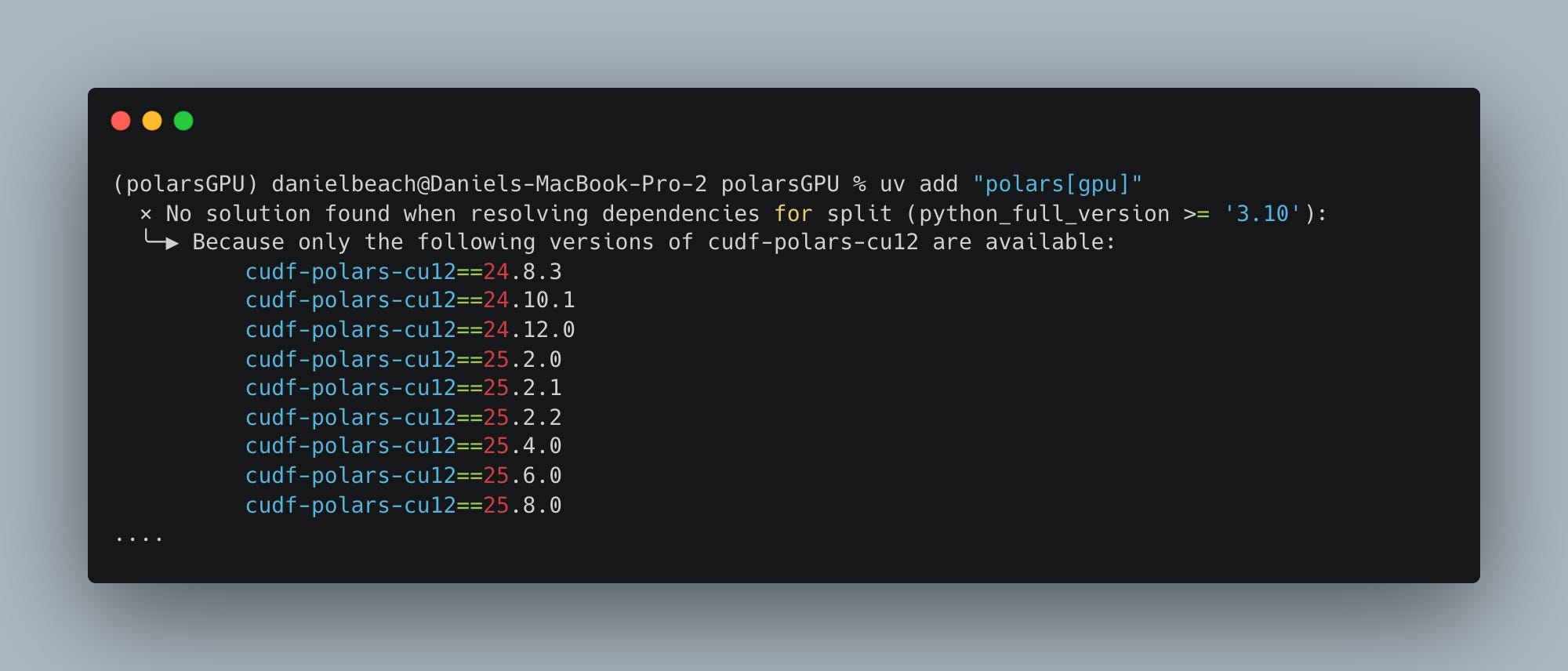
Read, read, read …
uv pip install "polars[gpu]" --extra-index-url=https://pypi.nvidia.comSuccess.
So how do we use the power of the GPU with Polars.
“Designed to make processing 10-100+ GBs of data feel interactive with just a single GPU, this new engine is built directly into the Polars Lazy API – just pass engine="gpu" to the collect operation.”
- Polars Notebook
I am skeptical that this will will either work, or do anything … but if anyone can pull this off … it’s the Polars team.
Note: They said we have to use Lazy Polars API, which we were already doing.
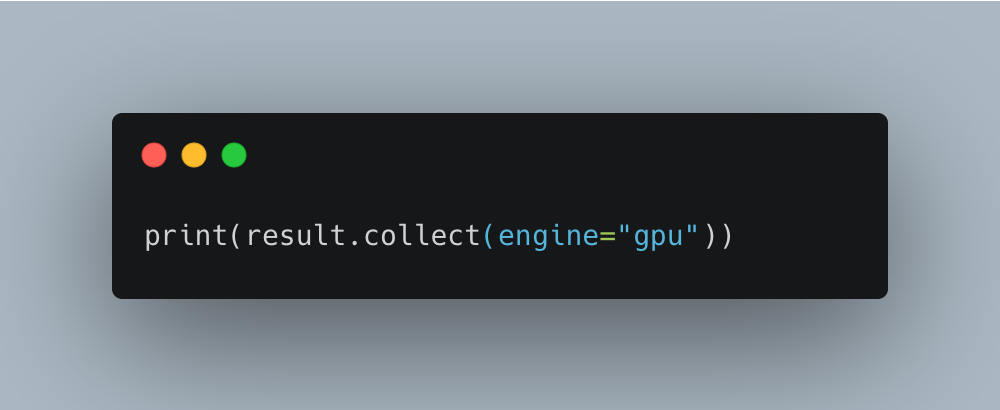
This is the only thing I changed in the code. Could this work??
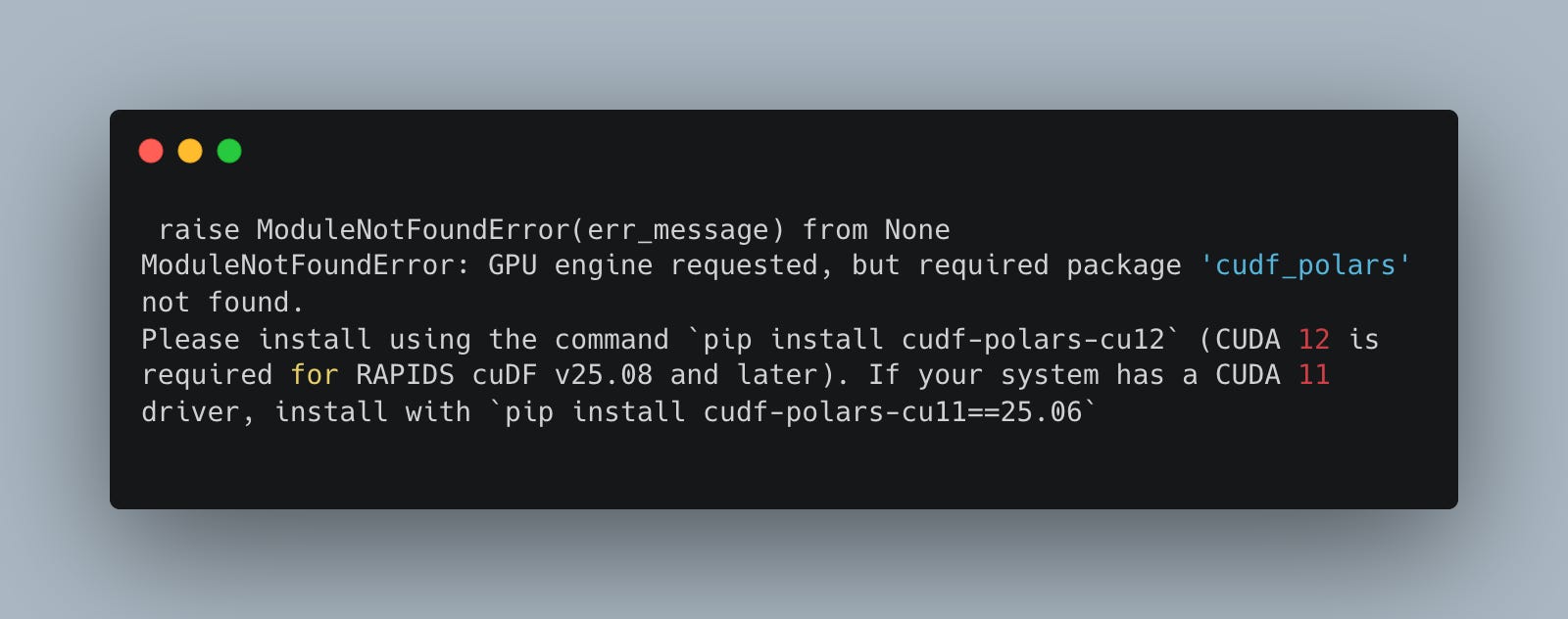
You thought it was just going to be like that? Sucker. The data god’s require more blood than that.
polarsGPU) danielbeach@Daniels-MacBook-Pro-2 polarsGPU % uv pip install cudf-polars-cu11==25.06
× No solution found when resolving dependencies:
╰─▶ Because the current Python version (3.9.21) does not satisfy Python>=3.10 and cudf-polars-cu11==25.6.0 depends on
Python>=3.10, we can conclude that cudf-polars-cu11==25.6.0 cannot be used.
And because you require cudf-polars-cu11==25.6, we can conclude that your requirements are unsatisfiable.Ok, I noticed we are running Python 3.9X
Because the current Python version (3.9.21) does not satisfy Python>=3.10 and cudf-polars-cu11>=24.10.1 depends on
Python>=3.10, we can conclude that cudf-polars-cu11>=24.10.1 cannot be used.Let’s get Python 3.10+ in our UV environment.
uv python install 3.12
uv python pin 3.12All this seems to have NOT solved the cudf-polars issues with versions, it still pukes.
uv pip install --extra-index-url https://pypi.nvidia.com cudf-cu12
hint: `cudf-cu12` was found on https://pypi.nvidia.com/, but not at the requested version (all versions of cudf-cu12). A compatible
version may be available on a subsequent index (e.g., https://pypi.org/simple). By default, uv will only consider versions that are
published on the first index that contains a given package, to avoid dependency confusion attacks. If all indexes are equally trusted, use
`--index-strategy unsafe-best-match` to consider all versions from all indexes, regardless of the order in which they were defined.
hint: Wheels are available for `cudf-cu12` (v25.8.0) on the following platforms: `manylinux_2_24_aarch64`, `manylinux_2_24_x86_64`,
`manylinux_2_28_aarch64`, `manylinux_2_28_x86_64`
Is there anything worse than fighting with Python dependencies?

I should have done more reading at the start. Sounds like CUDA stuff simply isn’t available on MacOS Hardware, probably obvious enough if you are paying attention more than me.
Back to good ole’ Linode. I had better work fast at the price of .50 cents per hour.
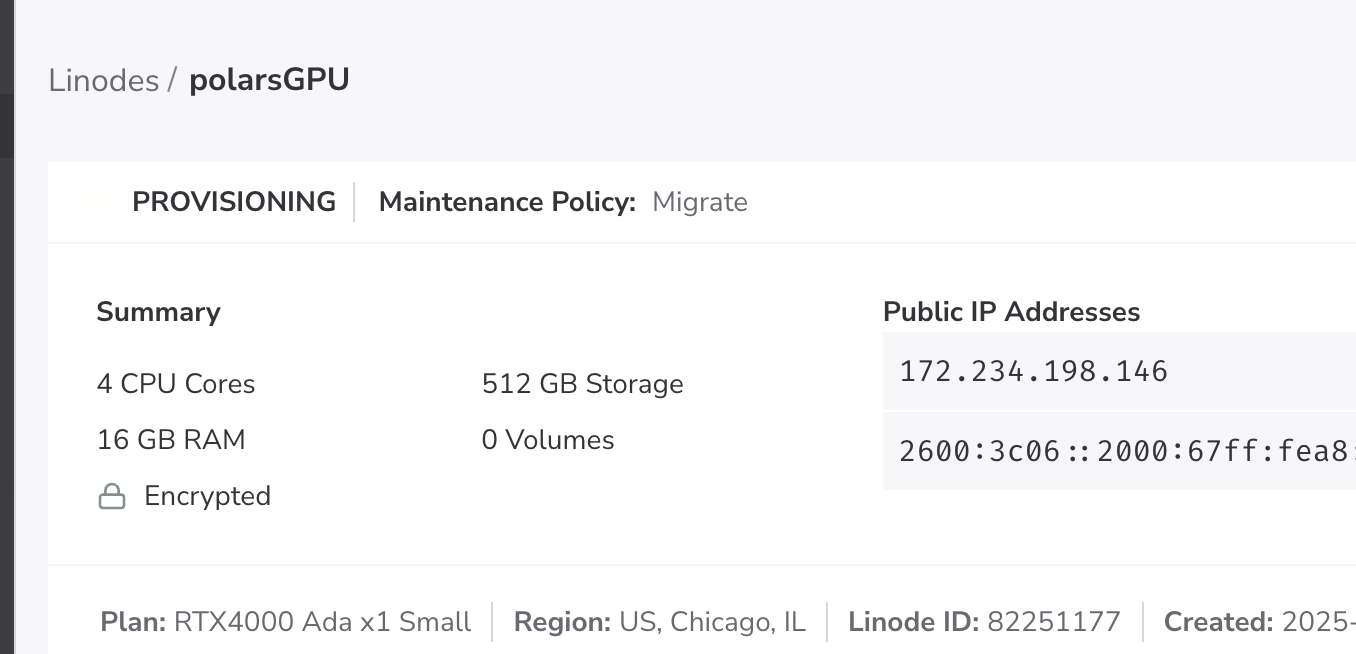
We are using an RTX4000 Ada x1 GPU-accelerated machine. The things I do for you.
Well, all the installs went fine with Python 3.12 on this GPU Linux box.
(polarsGPU) root@localhost:~/polarsGPU# uv pip install "polars[gpu]" --extra-index-url=https://pypi.nvidia.com
Resolved 16 packages in 246ms
nvtx ------------------------------ 476.46 KiB/532.80 KiB
rmm-cu12 ------------------------------ 276.78 KiB/1.08 MiB
Installed 16 packages in 34ms
+ cuda-bindings==12.9.2
+ cuda-pathfinder==1.1.0
+ cuda-python==12.9.2
+ cudf-polars-cu12==25.8.0
+ libcudf-cu12==25.8.0
+ libkvikio-cu12==25.8.0
+ librmm-cu12==25.8.0
+ numpy==2.3.2
+ nvidia-ml-py==13.580.65
+ nvtx==0.2.13
+ packaging==25.0
+ polars==1.31.0
+ pylibcudf-cu12==25.8.0
+ rapids-logger==0.1.1
+ rmm-cu12==25.8.0
+ typing-extensions==4.14.1Now we have to wait while I scp all the data (40GBs of CSV) to that machine. Check back in an hour when the almost 400 files are uploaded.
scp -r data root@172.234.198.146:/root/polarsGPU/dataForget that, let’s get the zip files and put those up there, then extract them.
wget https://f001.backblaze2.com/file/Backblaze-Hard-Drive-Data/data_Q1_2024.zip
... etc, etcOnce we got 'em all, extract 'em… etc.
for f in data_Q3_2024.zip; do
folder="${f%.zip}"
unzip -d "$folder" "$f" && rm "$f"
doneHEY! You bored yet??!! I’m just showing you what it takes to give you the real juice in these articles. You want fluff, go read someone else’s article doing “hello world,” this is real life.
Round Two.

Ok, so now we have the files on our GPU-accelerated Linux box, let’s re-run the baseline tests and see what happens. (Again, I ran the command a few times to get data caching over with, and recorded the last 3 runs)
Basically, the times didn’t change at all vs my Mac.
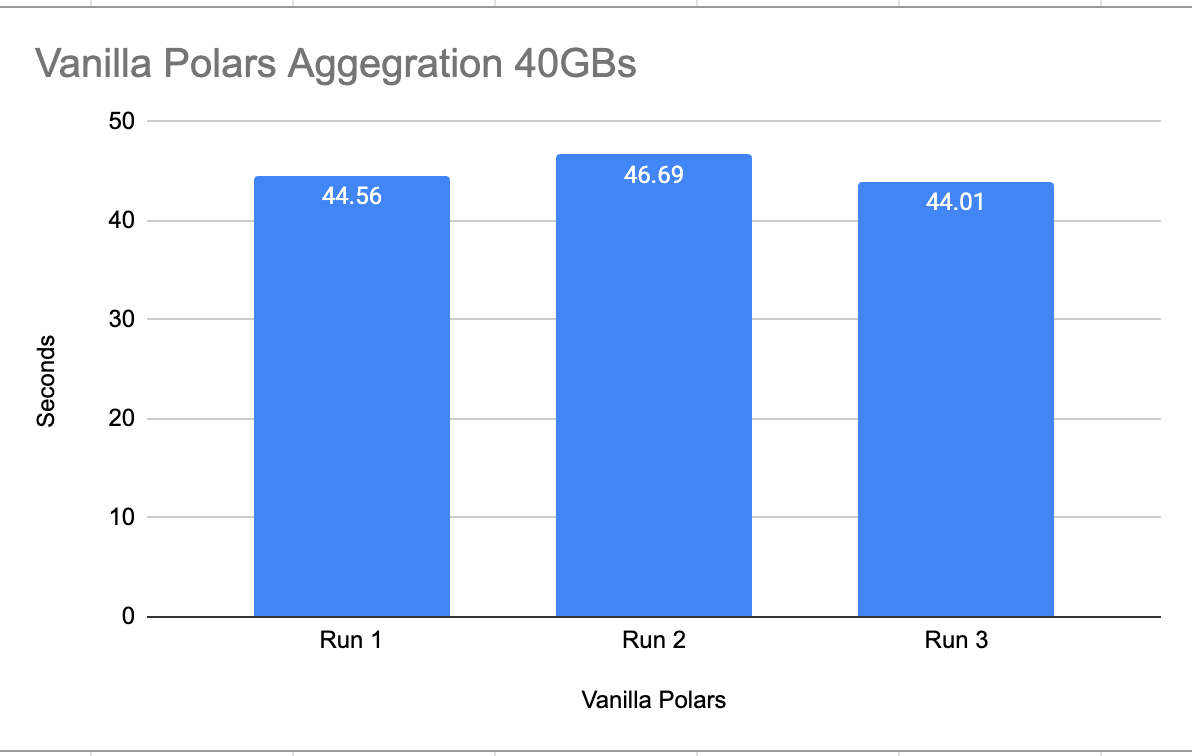
Ok, how about adding in our GPU acceleration, now that we are using a NIVIDA machine??!!
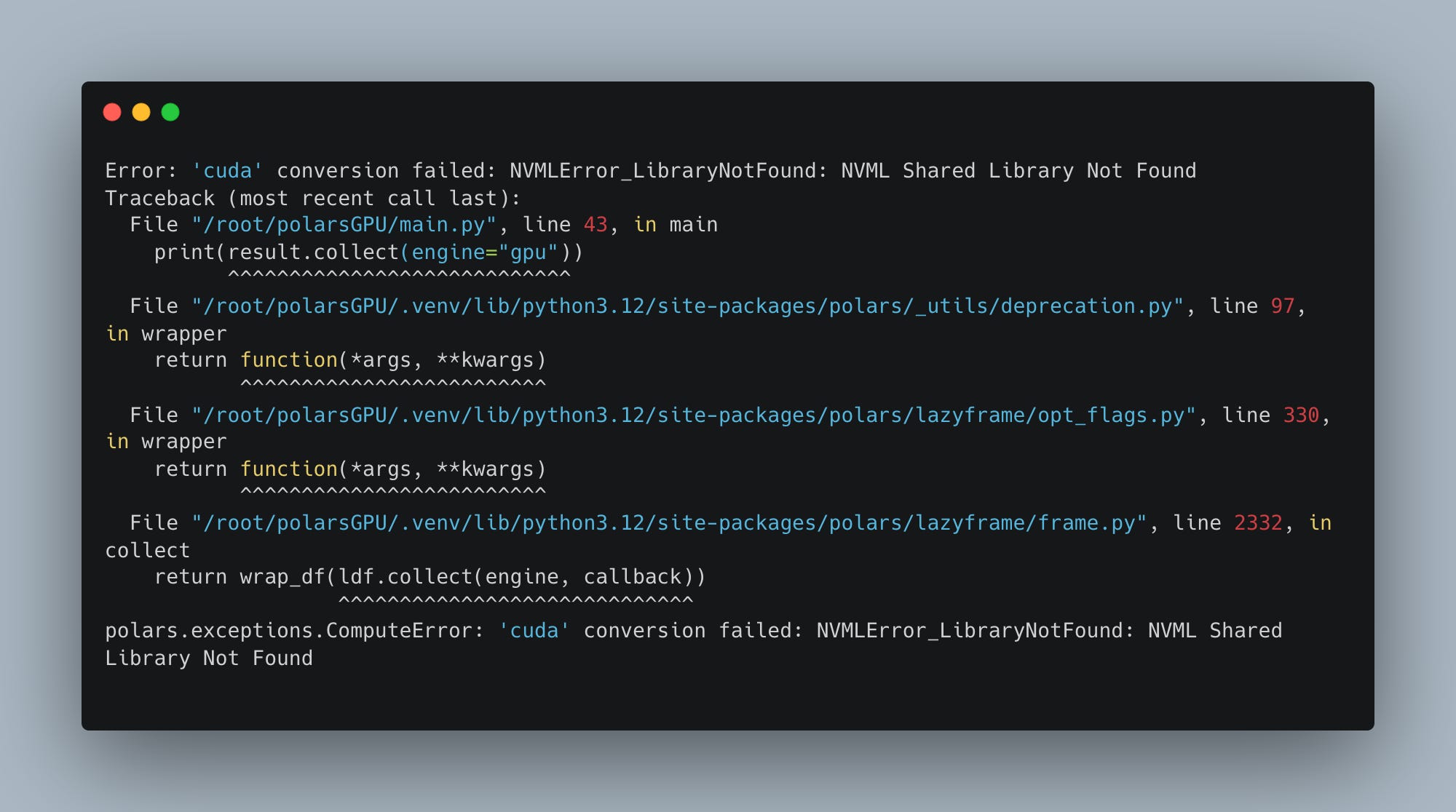
You knew that was coming, didn’t you? I almost thought it was going to work, you know? Almost forgot we can run this …
pip install --extra-index-url=https://pypi.nvidia.com cudf-cu12No go, still fails with the same error.
Good Lord, here comes some mud being thrown at the wall, see what sticks.
sudo apt install nvidia-driver-535 nvidia-utils-535Ok, so we have NVIDIA drivers showing now.
I do have a question for you, though. If you were Linode and provided someone with a GPU Nvidia-accelerated machine, would you ensure the drivers were installed on that machine?
Just saying. Hobbits.
Here goes nothing.
uv run main.pyBY THE HAMMER OF THOR!
Holy crap.
(polarsGPU) root@localhost:~/polarsGPU# uv run main.py
Hello from polarsGPU
Now scanning all files...
shape: (366, 2)
┌────────────┬───────────────┐
│ date ┆ failure_count │
│ --- ┆ --- │
│ date ┆ i64 │
╞════════════╪═══════════════╡
│ 2024-10-17 ┆ 17 │
│ 2024-06-26 ┆ 11 │
│ 2024-05-13 ┆ 12 │
│ 2024-08-26 ┆ 24 │
│ 2024-11-17 ┆ 8 │
│ … ┆ … │
│ 2024-10-06 ┆ 8 │
│ 2024-01-18 ┆ 11 │
│ 2024-06-25 ┆ 15 │
│ 2024-09-12 ┆ 9 │
│ 2024-03-04 ┆ 14 │
└────────────┴───────────────┘
Time taken: 13.280710220336914 seconds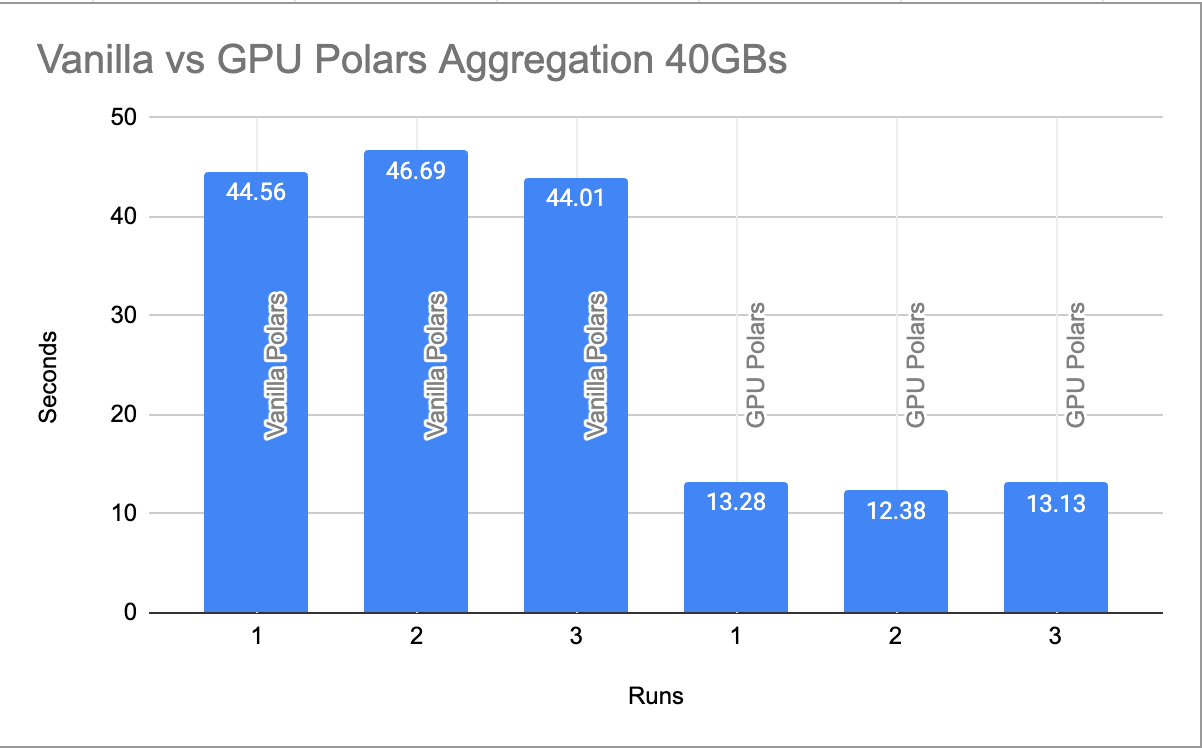
What the actual Black Magic?

That’s insane. That’s like a 70% performance increase using Polars GPU with a simple collect(engine=”gpu”).
Not going to lie, wasn’t expecting that.
So what’s the TDLR?
I'm not sure, but it’s hard for the excitement to wear off, leaving my brain clear enough to think straight and make more grounded judgments. I’m already wondering in my mind …
“What’s the cost look like if you dropped some Databricks compute and replaced it with some short-lived GPU compute to do some big data processing on GPU-accelerated Polars?”
No one would bother if the speed improvements were 10-20% even, you just stick with what you got. But 70% speed up? It makes a Data Engineer wonder and stare into the sky.
GPUs are notoriously expensive to run, but you know, turn something on and off quick-like, do some crunching, how bad could it be?
I don’t know what the future holds, but it looks bright for Polars.
Super cool write up, did you expect the GPU speed up to hit 70 percent, or was that a total surprise after all the setup struggles?
You just burned down an entire forest with all that unnecessary gpu compute 😂