



Suppose you’re an old-school data person like me, one of those Kimball acolytes who spat on the graves of non-Data Warehouse Toolkit ignoramuses. In that case, you’ve probably sat around in the late hours of the night, staring up at the stars asking yourself this very question…
“If primary and foreign keys were at the heart of the Data Warehouse, and the Lake House has replaced the Data Warehouse, without primary and foreign keys … does that mean we were all misled and drank that Kool-Aid for nothing???”
I feel duped, like a ninny.
All those years, nay, more than a decade spent minutely examining database tables for the perfect primary key, that combination of columns that would lead me to the Promised Land, those foreign keys that would keep the wolf from the door.
Thanks to Delta for sponsoring this newsletter! I personally use Delta Lake on a daily basis, and I believe this technology represents the future of Data Engineering. Check out their website below.

What did I do that for? I mean when is the last time you heard a Lake House zealot raise themself from their golden throne built on the bones of Data Warehouse soldiers and pontificate about a primary or foreign key?
That’s right. NEVER.
What are Primary and Foreign Keys
Let’s start at the beginning, the easy stuff.
Primary Key:
A primary key is a column (or a subset of columns) in a table that uniquely identifies each row in that table or dataset.
It must contain unique values, and it cannot contain
NULLvalues.There can only be one primary key per table, but it can be made up of multiple columns (composite key).
Example:
In a table of
Employees, theEmployeeIDmight be the primary key because it uniquely identifies each employee.

Foreign Key:
A foreign key is a column (or a set of columns) in one table that links to the primary key of another table.
It is used to create a relationship between two tables and ensure referential integrity.
the value in the foreign key column must exist in the referenced primary key column.
A foreign key can contain
NULLvalues if the relationship is optional.Example:
In a table of
Orders, theEmployeeIDcan be a foreign key that references theEmployeeIDin theEmployeestable.
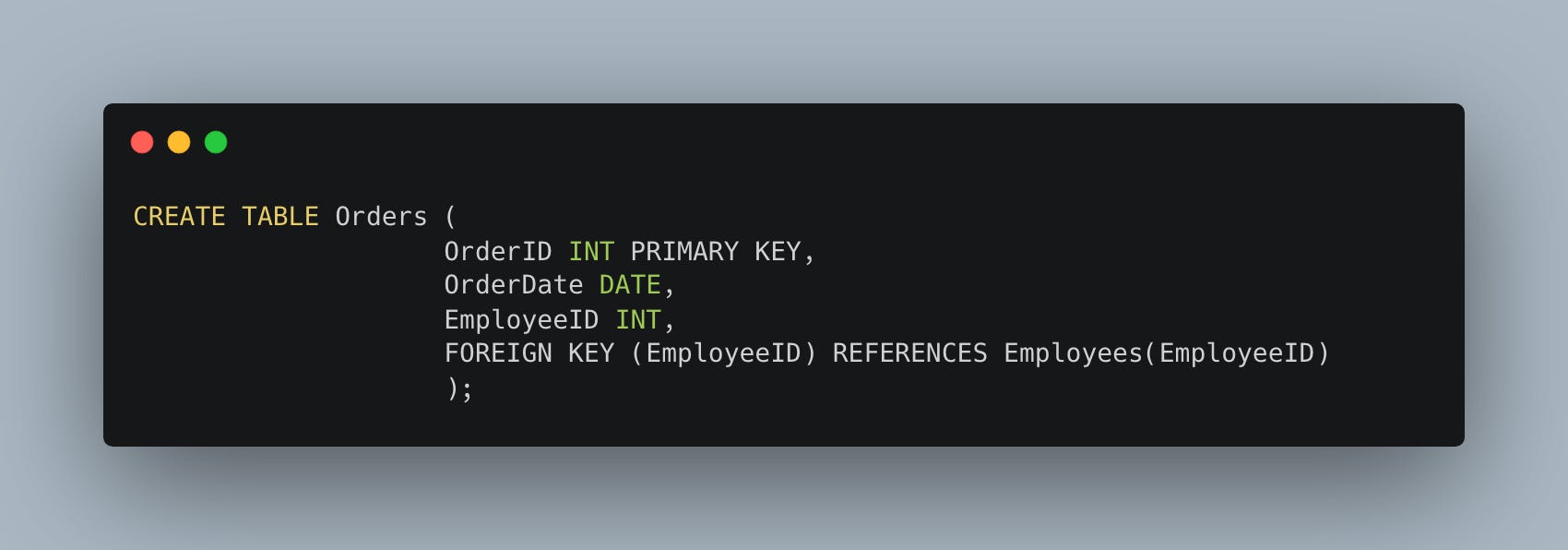
In this example, Orders.EmployeeID is a foreign key that links to Employees.EmployeeID, enforcing that any EmployeeID used in the Orders table must exist in the Employees table.
It’s hard to understate the place the primary and foreign keys have played in the classical OLAP and OLTP data models, and still play, especially in the RDMBS world (Relational Database Management System).
Without a knowledge of what makes a particular record different from another one in the same dataset, you really don’t understand the data at all.
And if you don’t understand what we’ve described above, than everything else falls apart. Metrics don’t work, dashboards won’t be right, nothing will be correct.
A core component of any data model is the ability to understand what makes anyone record UNIQUE.
The ability to concretely tie one record to another via foreign keys is also indispensable.
The assurance and logical clarity of a primary key in one table resulting in a single record that can relate precisely to a record in another table is a foundational data modeling prinicpal.
So why don’t they exist in the Lake House?
The death of primary and foreign keys …
I feel the death of the primary and foreign keys might be a little premature, although there is an argument to be made against them. Some might say “Hey, Databricks and Delta Lake provide primary and foreign keys!”
Yeah, well … not really.
“Primary key and foreign key constraints aren't enforced in the Databricks engine, but they may be useful for indicating a data integrity relationship that is intended to hold true.” Databricks docs
Is a primary and foreign key real if it is not enforced? Not really. In name only, not in practice. Is something better than nothing? I suppose so.
Yet, there is a more excellent way my friend.
Using hashes in the Lake House
While we could use the fake-ish primary and foreign keys in Databricks, if you want less of a vendor locked-in type of primary key, may I suggest a simple hash?
The way to create a primary key in the Lake House architecture, at least one you can trust logically, which is important, is to…
identify which combinations of columns make a row unique
create a hash of those columns
move on with life

There you have it, a unique string that represents a logical primary key for the data. Of course, this requires you to do the groundwork to understand beyond a doubt what the “business defines as the primary key.”
Many times this key, similar to primary and foreign keys, can be cascaded throughout datasets to ease the logic around …
INSERT
UPDATE
MERGE
JOIN
There is nothing worse than opening up some nasty old SQL file with MERGE or UPDATE statement joining 9 different columns. What a pain!
But what about enforcement??
Enforcement of logical primary keys
This might bring up the question of enforcement again, what do we do about that? In a traditional RDBMS like Postgres, we can depend on the database to puke when such a thing is violated (duplicate primary key).
Never fear, we are engineers, and we can code our way around this problem.
It’s easy enough to …
dedupe data on INSERT to avoid duplicate keys
run periodic checks to find duplicates
JOIN in such a way to avoid possible duplicates
ensure keys exist somewhere else
Sure, this sort of thing can add a little bit of code, but it isn’t rocket science and we can still gain all the benefits of logical primary keys.
They ease the use of Lake Houses and add that one last piece of functionality we were missing all along.
What say you friend?
As an an old-school data person and big fan of Kimball - mainly for having amazing success in delivery of data on a repeatable Lego like framework.
That said - way before data lakes and clouds - most MPP Data Warehouse databases did not support primary keys and foreign keys for performance reasons. It allowed you to define them in the DDL for documentation purposes, and even some BI / ETL tools used that metadata to assist the tools in coding. Kimball even included de-duplication checking in within the recommended subsystems for a EDW framework. The more things change, the more things stay the same. ;)
I miss real real databases. And I do love the Kimball (and Ross, and Adamson and Reeves).