

Rayon in Rust vs Python Process and Thread Pools.
Data-parallelism in the real world.

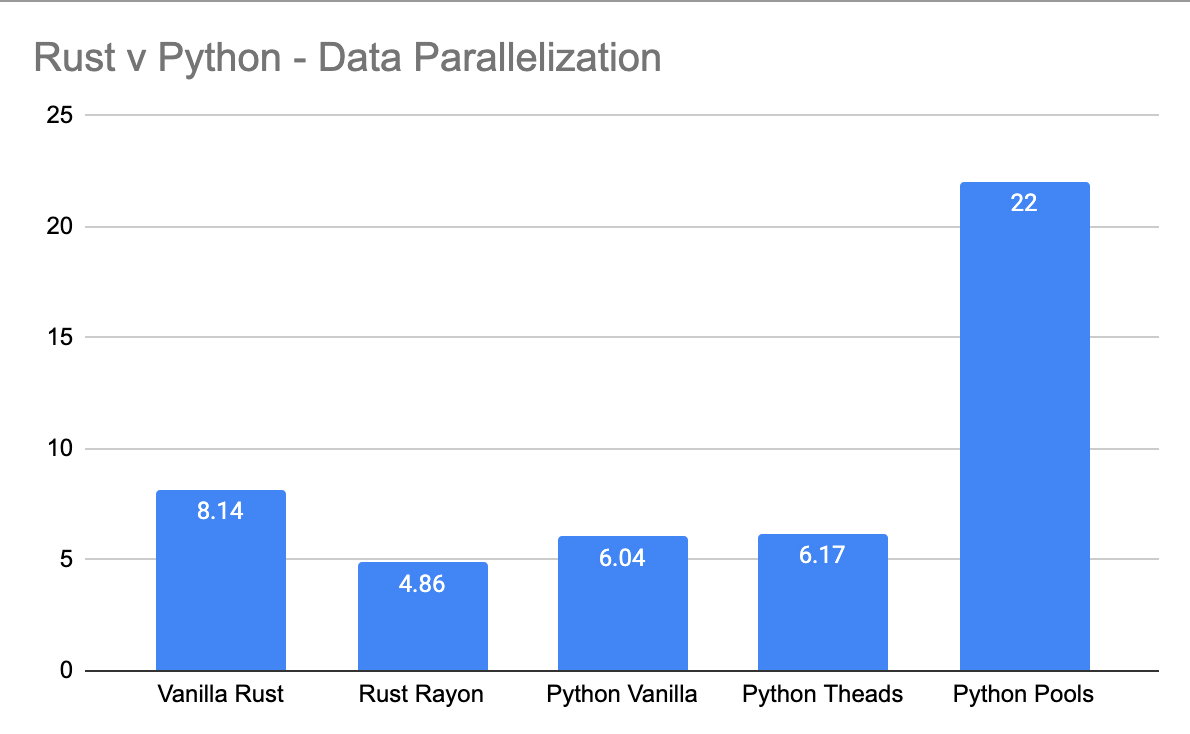
Hmmm. This is one of those topics that drives folks crazy. I love it. When it comes to coding and programming there are few things in this world that will make people light torches and rise pitchforks than parallel data processing. The only thing that makes people madder is probably async code.
Many moons ago I used to have to worry a lot about ProcessPo…
