

Real Life Example of the QuickSort Algo (Rust)
For Data Engineering


I, probably much like you, have been tired of hearing the DSA Prophets preaching their good news that Data Structures and Algorithms are here to save us all and enshrine us in everlasting brilliance and glory.
I always think … “Me you say? This old dude who’s been writing SQL and Data Pipelines with eyes crusted over from all the tears of boredom and monotony that wash over me every day? Me? DSA is going to bring me to the Promised Land?”
Beg your pardon while I roll my eyes. Well, that’s typically what I think about that. But, even I succumb to the DSA devils every once in a while. I’ve done a series on DSA before my dear readers, that can be found here.
Thanks to Delta for sponsoring this newsletter! I personally use Delta Lake on a daily basis, and I believe this technology represents the future of Data Engineering. Check out their website below.

This series called “DSA for the Rest of Us” was wildly unpopular and I can’t imagine why. Yawn. One thing I’ve learned about all the internet hobbits like you over the years is that y’all like the Milk Toast stuff, nobody wants the complicated stuff.
But, I’m a glutton for punishment and I don’t take no for an answer if I don’t feel like it. I’m going to pour some more DSA down your throat whether you like it or not.
Real Life Example of the QuickSort Algorithm.
I was hacking around this weekend on a project called Puddleglum. It’s an idea I’ve had for a while that is …
Puddleglum is a Rust-based Python package that allows for complex Data Quality checks on AWS s3 buckets.
It’s still under development, so don’t hold your breath. But basically I’ve gotten tired of handrolling my own S3 bucket gyrations all the time …
When was the last time I got a file
How big is it
How many files did I get this week
How many files did I get last month
blah, blah, blah
This basically involves something like boto3, gathering a bunch of files into a list and than doing this that and the other thing to answer some questions.
Puddleglum is all writing in Rust right now, with plans to use pyo3 to port it to a Python package eventually.
What does this have to do with QuickSort?
Well, I was hacking away at the project and I realized something, I thought to myself … “By Gandalf’s beard! This is a perfect use case for a QuickSort application!”
I was coding the answer to the following questions about a s3 bucket and prefix.
Get the most recent file.
Get N most recent file(s)
Get N day(s) ago file(s)
Get N week(s) ago file(s)
Count files and group by day for n days
etc.
These are just some of the questions I want to be able to answer, among others. What is the obvious thing about answering all of these questions?
If I had a sorted list of files from an s3 bucket and prefix, it would make answering many of these questions trivial, quick, or both.
What better way to sort a list than with the QuickSort algo? In my case I’m using Rust and we would want to sort the list by DateTime from newest to oldest.
To set the stage we first need to be able to get everything out of a s3 bucket matching a prefix. Something like that.
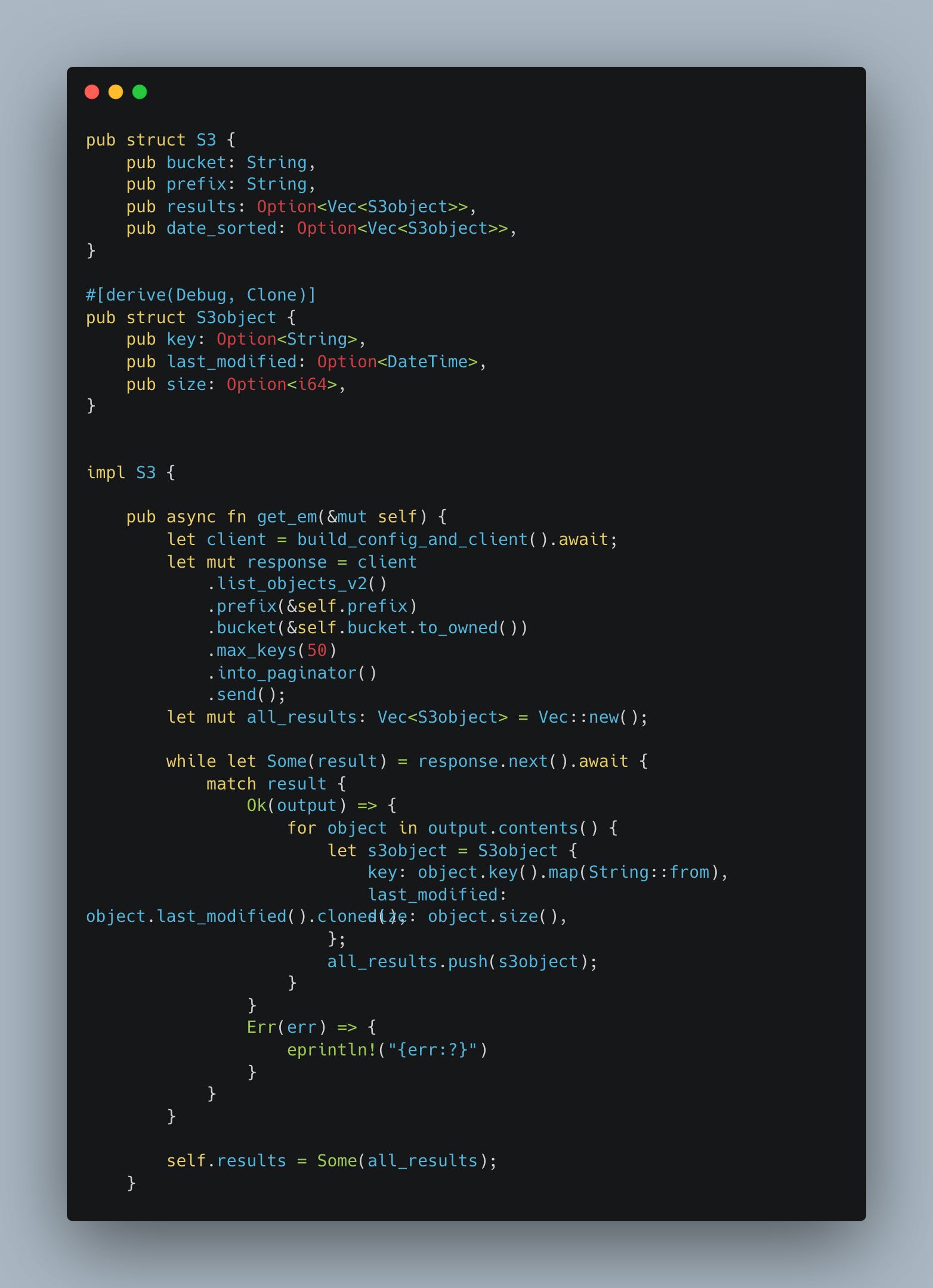
Now with that out of the way we can do something like …

Once we have done get_em, we have a Vector of unordered results from s3. In our case remember we want to answer a number of different questions based on the last_modified property of the objects.
So, it would make sense if we are going to ask an arbitrary number of questions based on the DateTime of said objects, we should do the work to Sort them upfront, to make the downstream questions simple and fast.
Enter our QuickSort algo.

If you need an in-depth and slow explanation of QuickSort, go back above to my links I shared and you can read through QuickSort in Rust.
So what’s the big deal?
Ok, so we now have our Vector (array) of objects sorted by DateTime, does it really make answering questions easier?
Give me the most recent file?

Bing, bang, boom. If our date_sorted Vector is None, sort it, if it is, we pop the first item. Very easy.
What if I want the N most recent files?

No problemo, I got you. Little for loop through N and we got what we need.
What about making quicker to solve … DateTime problems that are a little harder?
Give me files from N days ago?

Again, we know this is going to run quickly why? Because our object set we are iterating is sorted, so we know that all the records we need are going to be right next to each other, not scattered around through the entire list.
Never say never.
I guess you shouldn’t say “I will never do that, I will never need that.” Maybe there is a little DSA sprinkeled all around our life waiting for us to notice them. Crying in the corner like a lonely middleschooler that no one wants to dance with. Poor little bugger.

So, let’s raise our glasses to the road less traveled, to the smart people in their mom’s basements who love the DSA and spend all their life hacking in anonymity.
Heck, even a Data Engineer gets a chance to do something smart every once in awhile, better be careful or it might cause a habit to appear.
I guess the idea is that there are surprising things lurking around in the corners of our code if we stop and give em’ a chance. Yeah, most of use don’t need to know anything about Binary Trees, most of that is for the birds, but a little salt, pepper, and DSA on your taters probably wouldn’t kill ya.
In quick_sort_s3_objects_by_date you can have 1 line of code instead of 9 by doing this:
let (less_than_pivot, greater_than_pivot) = objects.into_iter().partition(|object| object.last_modified.unwrap() <= pivot.last_modified.unwrap());
By Gandalf’s beard! -:)