

Realtime Streaming data from PostgreSQL to Delta Lake (Unity Catalog)
... with Estuary


It’s been a while since I kicked the tires on a new tool, you know I love to pick and poke at things. Also, in my never-ending attempt to keep on top of the changing landscape and keep the wolves (newer, smarter, younger engineers) from snatching my throne, it’s imperative I at least attempt to keep up with the times.
So, in the spirit of trying new and fun things, today we are going to do something interesting … namely, trying to stream Postgres data to Delta Lake.
Of course, we older and wiser Data Engineers who’ve battled mountains of old and unruly code have come to realize that it’s best to test and try every solution to a problem with open-mindedness and a view to keeping complexity and code to a dull roar.
So, I set up a free account with Estuary.

“The only platform built from the ground up for truly real-time ETL and ELT data integration, set up in minutes.” - Estuary website.
We are going to prove out this tool and see if it can deliver what it claims, I will give you the raw unfettered truth. I’m going to walk through creating an Estuary account all the way to attempting to stream data from an AWS RDS Postgres instance to a Databricks Delta Lake table.
Doing the thing.
In a nice change of pace, the free account only took me three clicks and required no credit card or any other shenanigans.
Without further ado I’m going to jump straight in, document the process, and comment along the way, I will leave the success or failure up to you to decide.
Trying to sync data from Postgres to Delta Lake with Estuary.
They make it super easy, I just clicked New Capture,

A bunch of Connectors popped up, and PostgreSQL of course shows up as one of the main ones, easy enough so far. It appears the two main concepts are …
Connector (source)
Materialization (destination)

No problem, I used my personal AWS account to set up a nice new, albeit tiny, RDS Postgres instance.

Next, back to Estuary where I enter those connection details.

First error, no go on the connection.

Luckily I found some documentation with step-by-step for what needs to be set up on the AWS RDS side to make this all work. That’s no surprise really, it always takes a little tweaking to get things to talk.
(side note, the error logs were extremely easy to read and right in your face)
https://docs.estuary.dev/reference/Connectors/capture-connectors/PostgreSQL/amazon-rds-postgres/
I had to do the following …
mess with the VPC to allow incoming traffic from 34.121.207.128
create a new parameter group and turn on logical replication, assign it to the RDS.
restart database.
I also need a simple sample table to create in my Postgres RDS to use for this test.
CREATE TABLE pickle_bob (id bigint NOT NULL, name text);That should do.
Next, the Estuary documentation tells me I have to connect to RDS (I did via psql) and run the following script.

Notice I had to add my table pickle_bob into that last command. Basically letting Estuary do its thing.
This time the Connection creation in Estuary gets past the first error, but pops this following new one.

The first error about logical replication is interesting, you can see below in my parameter group this is already set to 1, and the instance was restarted.

Interestingly, after running this query the RDS shows it as off.

A second restart of the RDS instance seemed to do the trick on that one, thanks Stackoverflow for the tip.

That seemed to be the final trick, Connection setup in Estuary. What I need now is a Materialization or a target for my Postgres table source.
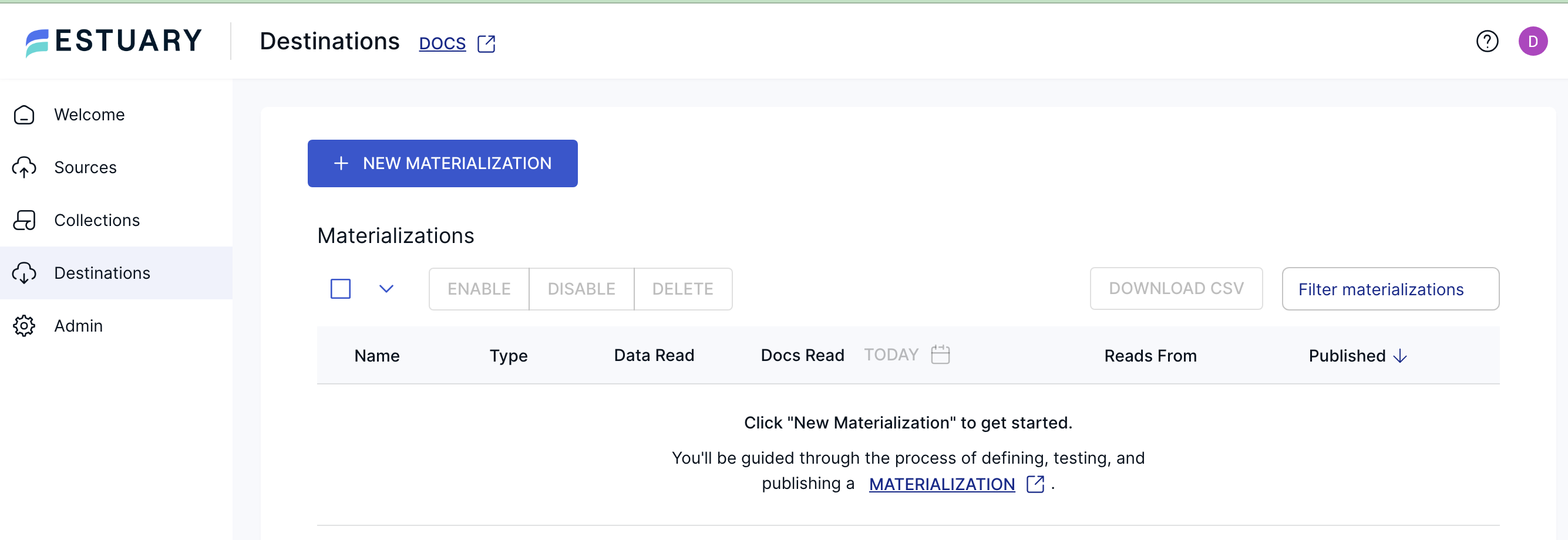
This is the part I’m nervous about, can I get Estuary to write to a Delta Lake table stored with a s3 backend??? Time will tell.
Well, it’s good and bad news. Estuary provides a Databricks connector, but it requires an account with Unity Catalog … aka you have to have a fullblow Databricks Premium account and can’t write to a custom or standalone Delta Lake table you’ve created and managed yourself on somewhere like s3.
At least not out of the box.

And, on top of that, you need an SQL Warehouse apparently, the SQL Warehouse part is strange, not sure why you would need that. SQL Warehouse can be kinda expensive.

The good news for you, my dear readers, is I do have a personal Premium Databricks account that I try to keep to a dull roar, as it will easily eat your bank account for lunch if you’re not careful.
(I also set up this Delta Table table in my Databricks account)
CREATE TABLE pickle_bob (id bigint NOT NULL, name varchar(25));Creating the Connection / Materialization to my Databricks account is pretty straightforward. Just fill out some account info along with a PAT (personal access token).

(this required me to have a few simple things like a Catalog setup in my Databricks Workspace that I could use for this work etc.)

But, easy enough! Done! Not painful at all. You can see my new Databricks “Materialization” in the Estuary UI.

Honestly, it’s been pretty smooth so far … not a lot of code that I’ve to write (none at all) to get connection setup from a Postgres table to a Databricks Delta Lake (Unity Catalog) table.
As you get older in your career of fighting code and data you will start to realize, like me, that easy solutions that require less code = less trouble in the future. (code = bugs).
What next?
Well, I guess all there is to do now is to simply write some records (INSERT) into our Postgres table and then see if we can get them to show up in our Databricks Unity Catalog Delta Table!
I will be impressed if this works the first time.

Ok, we got our records into the Postgres table.

Well, look at that, in the Estuary UI we can see that it picked up some data obviously, (I inserted the records and then went straight to the UI and refreshed, so it’s on the ball).
Unfortunately, when I go to my Databricks Notebook and run a query on that table, I don’t see anything showing up.

After rechecking my Materialization setup, it appears I never set a refresh interval, aka I set it to 1 hour, figuring it would auto sync right away, it was nothing before.

Well, I’ll be. There those little records are!
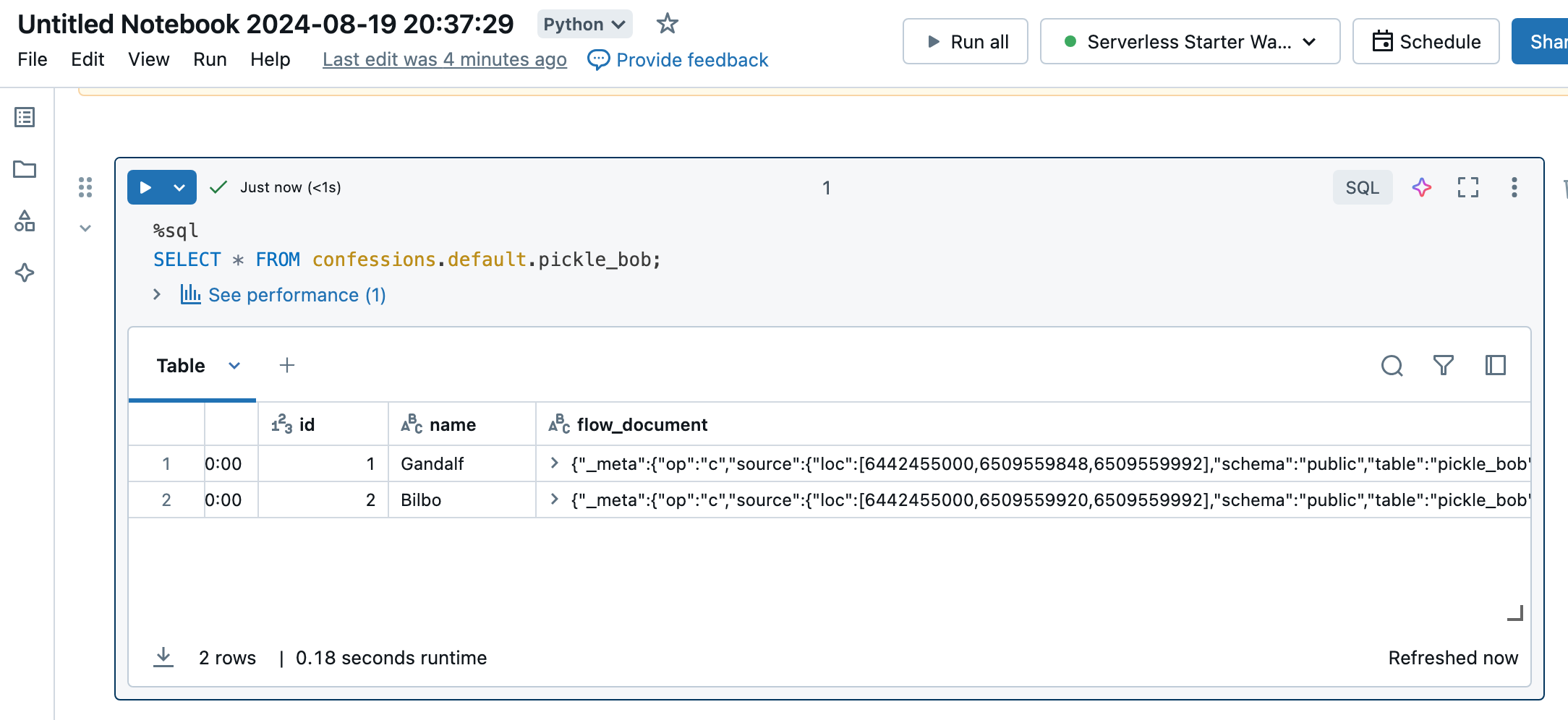
Impressive if I do say so myself, and I’m usually picky handing out those.
Notes on real-time data capture with Estuary between Postgres and Delta Lake tables (Unity Catalog).
I’ve worked a lot with Postgres and Databricks over the years, and I have to accept a slick product when I see one. I can imagine writing a lot of code to solve this same problem, who knows, Spark Streaming, Delta Live Table, and the list goes on.
At this point in my life, I know that “more code” equals “more problems.”
Sure, there are times when hand-rolling your own solution makes sense for certain use cases. Streaming data from Postgres to Delta Lake tables in Databricks (Unity Catalog) is not one of them.
I mean think about the amount of code and complexity you would have to create to simply GET the data from point A to point B. Let alone do what you want with the data.
This one from Estuary is a no-brainer.
They abstract all the code and complexity away, all you have to do is play with the data like you want to anyway.
It’s exciting to new tools like this come into the marketplace, with such slick and easy integrations with tooling like Databricks.
For me, it’s an easy sell … reduce code, simple integration, few button clicks, and whamo, you got data streaming from Postgres into Delta Lake.
It’s definitely becoming easier to buy instead of build in the DE world. But sweet lord if this is your prod solution you’ll probably be paying an arm and a leg just for the databricks/unity catalog piece alone. Would be cool to see a follow-up post on “cost-optimized, off the shelf DE implementations” using this or similar managed services