

Review of Data Orchestration Landscape
... and honest one ...


Sometimes, I force my old caveman self to do things I do not want. Believe it or not, reviewing the landscape as it relates to data orchestration frameworks is not something on the top of my list. People, including me, have their own pet favorites when it comes to orchestration platforms, and it’s hard to be unbiased.
Does it matter what tool you choose? If it works, it works; if it doesn’t, it doesn’t; it’s not like we don’t have a plethora to choose from.
Either way, I suppose something like this could be helpful for those new to the Data Engineering world or those looking to build greenfield projects or migrations.
One of the most distasteful aspects of comparing tooling, in this case, orchestrators, is the desire of folks to simply get a side-by-side list of features. Different tools are good at other things, and a simple side-by-side checkbox list is usually misleading.
Whatever, I’m not sure how to compare different orchestration tools, but I want to cover the high-level things. Then, I’m assuming you will “gravitate” towards one or the other based on your needs. That should be good enough for both of us.
Mostly, I want to provide an unbiased comparison without any marketing drivel blocking the way.
Thanks to Delta for sponsoring this newsletter! I personally use Delta Lake on a daily basis, and I believe this technology represents the future of Data Engineering. Content like this would not be possible without their support. Check out their website below.

Now that we are done with that business let’s get down to it.
Orchestration Tooling Options
We should probably start at the top, simply listing our options, good and evil; I’m sure I will forget someone’s favorite, but so be it. Also, it’s hard to know where to draw the line, so to speak; some tools are pure orchestrators, and some are bent more toward data processing but act as orchestrators.

AWS MWAA
GCP Composer
Astronomer
Another great way to make people angry and break up the playing field into something more manageable is to break the entire group up by open source vs. not … this is a crucial distinction when thinking about options
There are technically three different types of tools, like it or not. I expect to hear some pushback, and talking heads take me to task on this, but whatever.
Closed (100% SaaS)
Semi-Open Sourced (Both Managed (paid) and some open-source)
Open-Source
As Data Engineers and Data Platform builders, we must know whether any tool we use, including these orchestration tools, is a semi-open source. What I mean by that is … do the parties that control the “open-source” GitHub also offer it as a paid service?
This can be both a good AND a bad thing. We have to be realists; we live in a world filled with humans who do human things. Will the best features be reserved for the paid versions? Will they pull the rug without warning?
Pretending like this stuff doesn’t happen is naive and dangerous. I don’t know if this is 100% correct, but here is my take on it. (Everything under the Open/Closed category appears to be offered by the makers as a paid/hosted product).

Sure, some companies take the open-source part more seriously than others, and you can run their tooling yourself and get the best features, but you can’t, or you get the rug pulled at some point. You should just be aware of where things stand.
How to compare Orchestration Tools
Before we can compare and contrast some of these tools, we should cross some off the list. Before you light your torches and grab the pitchforks, hear me out.
If we’re here to pick out a new tool, you start by finding out which tools won’t work for most folk.
How can we do this? Here are some criteria.
Small community and not widely used (
cross it off the list)unless you’re feeling spicy, we don't pick immature tooling.
We want full-feature tools, not those operating on a narrow fringe.
Anything else is fair game, although we will review other vital needs later. Based on the above, let’s cross a few off the list.

Why did I cross off metaflow, luigi, argo, and aws step functions? Because they are either too narrow or simply not widely used enough to have a thriving community.
metaflow has been growing a lot, but it is more focused on data science and ML workflows and hasn’t been around long enough.
argo is made to be run with Kubernetes; although popular, it’s too narrow in implementation.
Luigi has been around for some and does get used, but has lost out to other tools for good reason.
AWS Step Functions just aren’t fully featured enough, and it’s totally closed source.
if you think that’s not a problem, go read about what happened to AWS Data Pipeline.
Orchestra - just strange mix of open-source and paid.
Again, when picking between tools, we have to make cuts somewhere; these guys just didn’t make the cut.
Just because I’m curious I want to look at two stats on GitHub for all these tools so we can see them side by side, GitHub Stars (which means less and less these days), and Open Issues (this is a stronger indication of usage).

Ok, based on this I think we can cross some more off the list, it’s a brutal world we live in uh? Sorry if you’re favorite is getting the boot.
flyte appears to be low usage in comparison to our other options.
Kestra strangely has a lot of stars (??) but appears to have little usage based on issues. Also, some recent notes on reddit indicate the OSS version isn’t full featured and lacks community support.

This is the sort of thing we talked about in the beginning, and need to look out for. That brings us down to the mighty 4.

We are left with …
Prefect
Mage
Dagster
Airflow
Honestly, I’m not surprised, that is where I would expect to end up, if you work in the Data landscape, these tools are not unfamiliar to you. In my opinion, that means we are doing our review correctly.
If you think about it, this is really the single behemoth, Apache Airflow, vs the upstarts tying to get a piece of that action.

Now my intention isn’t to give you a how-to on each one of these tools, but let’s take a look at how to operate and their core concepts so YOU can get an idea of which tool resonates with YOU more.
In the end any of these tools you chose, if they work for you, is fine.
Concepts
Now, I’m no expert in all these tools, I just know how to read documentation and draw conclusions. I’ve read the documentation for these tools and come up with some thoughts to help us understand The Big Four.
It’s clear that these tools approach Workflow Orchestration from different perspectives, which makes sense, they are different tools, no surprise there.
DAG-based approach
Code-centric based approach
Both Airflow and Dagster focus on the DAG as an abstraction to write and orchestrate your needs. Mage and Prefect focus on more on code and the integration between code and the workflow is tight, not as much abstraction.

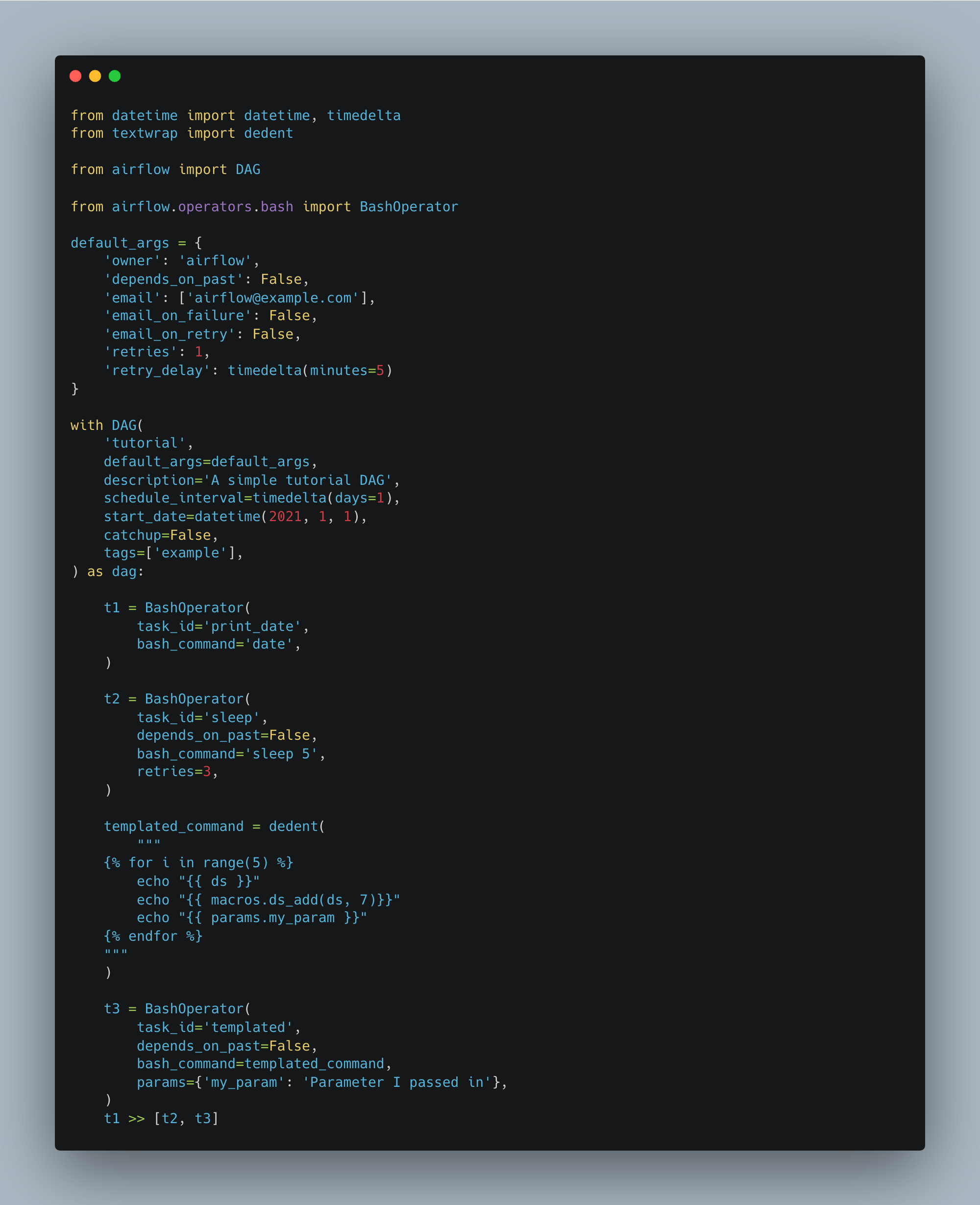
To help that idea sink in, here is an example, from their own docs, of a Workflow/DAG for each tool so you can see what I mean.
Airflow
Dagster
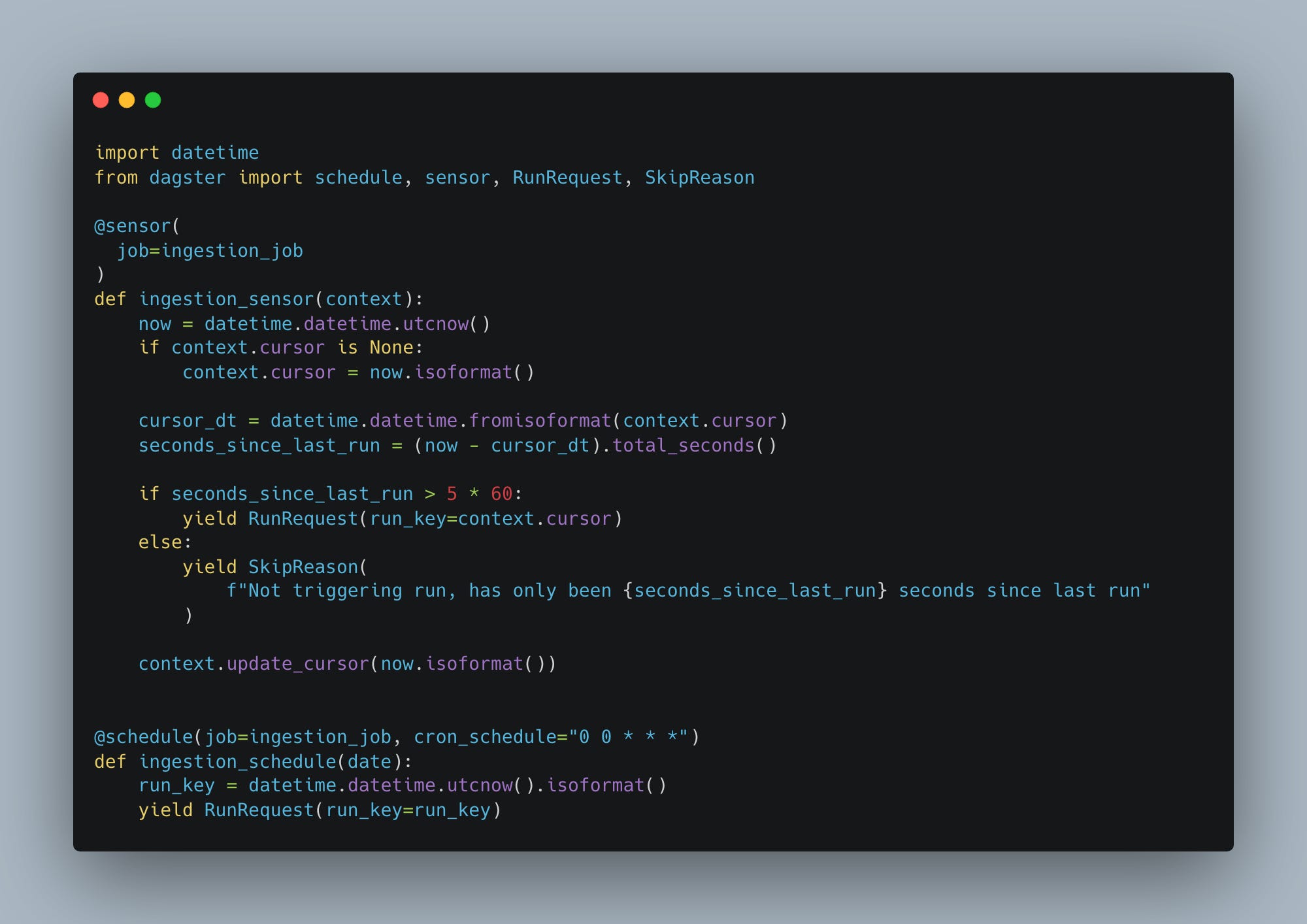
Just as a side note, Dagster sorta rides the rail between Airflow classic DAG setup and code centric approach. But, they look awful similar don’t they?
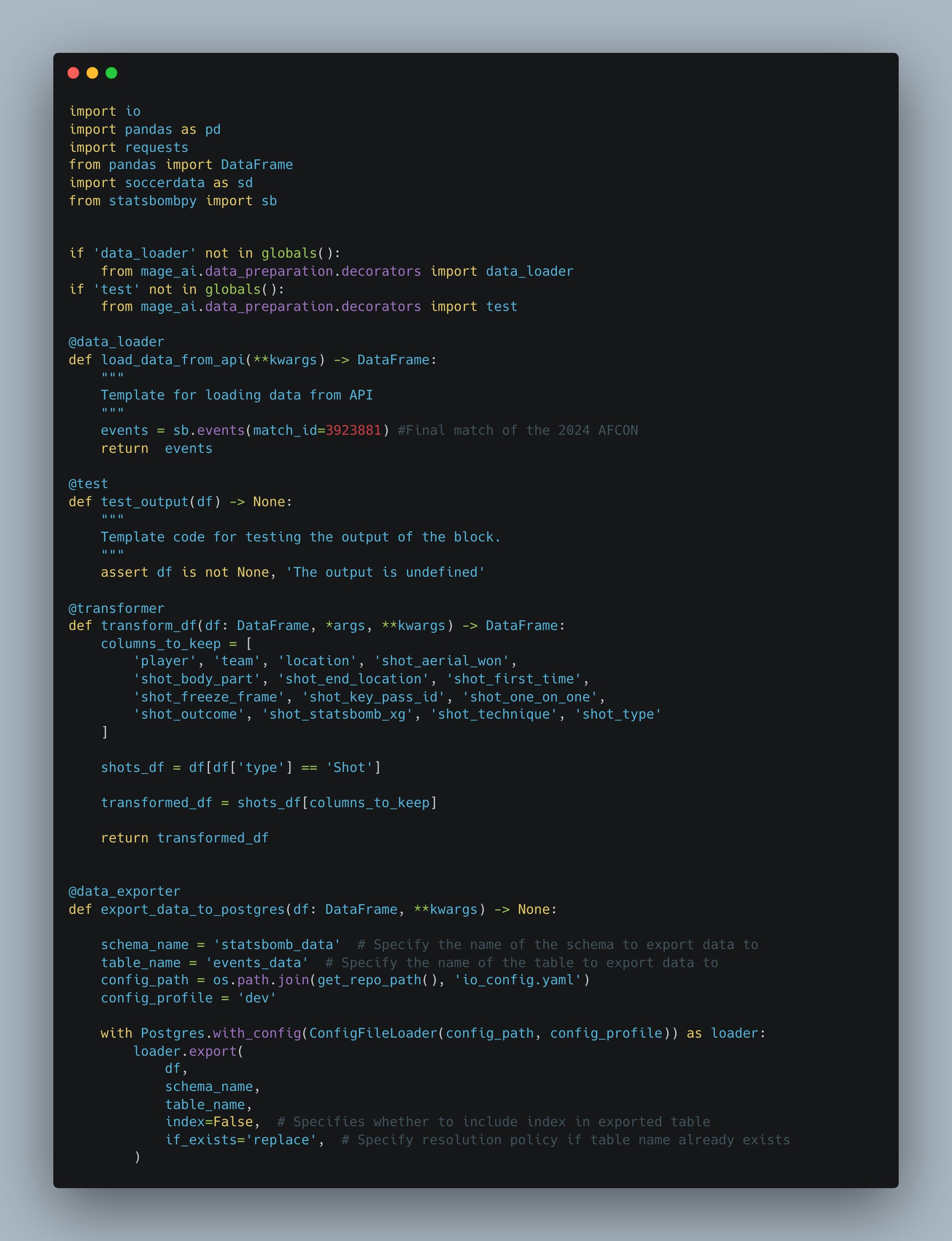
Mage
Pipeline example. (Mage uses Notebooks for code).
Prefect

What do you notice about Prefect and Mage? The are code centric and use decorators to build out pipelines.
Core concepts of Mage.ai …

Pipeline
A pipeline contains references to all the blocks of code you want to run, charts for visualizing data, and organizes the dependency between each block of code.
Block
A block is a file with code that can be executed independently or within a pipeline. Together, blocks form a Directed Acyclic Graph (DAG), which we call pipelines.
There are 8 types of blocks …
Data loader, Transformer, Data exporter, Scratchpad, Sensor, dbt, Extensions, Callbacks.
Core concepts of Prefect…

Flows
A Prefect workflow, modeled as a Python function.
Tasks
Discrete units of work in a Prefect workflow.
Results
The data returned by a flow or a task.
Similar concepts, but that is not a surprise, anyone building a workflow orchestration tool with Python would expect something similar. There is only so much abstraction that can be done.
What do people say about these tools in the wild?
Mage …


Prefect …


We should probably talk about Dagster.

We haven’t given Dagster much attention yet, but we probably should, since it’s one of The Big Four.
Dagster Concepts
Asset
An
assetrepresents a logical unit of data such as a table, dataset, or machine learning model. Assets can have dependencies on other assets, forming the data lineage for your pipelines.
Graph
A
GraphDefinitionconnects multipleopstogether to form a DAG. If you are usingassets, you will not need to use graphs directly.
IO Manager
An
IOManagerdefines how data is stored and retrieved between the execution ofassetsandops. This allows for a customizable storage and format at any interaction in a pipeline.
Job
A
jobis a subset ofassetsor theGraphDefinitionofops. Jobs are the main form of execution in Dagster.
OP
An
opis a computational unit of work. Ops are arranged into aGraphDefinitionto dictate their order. Ops have largely been replaced byassets.
What are people saying?


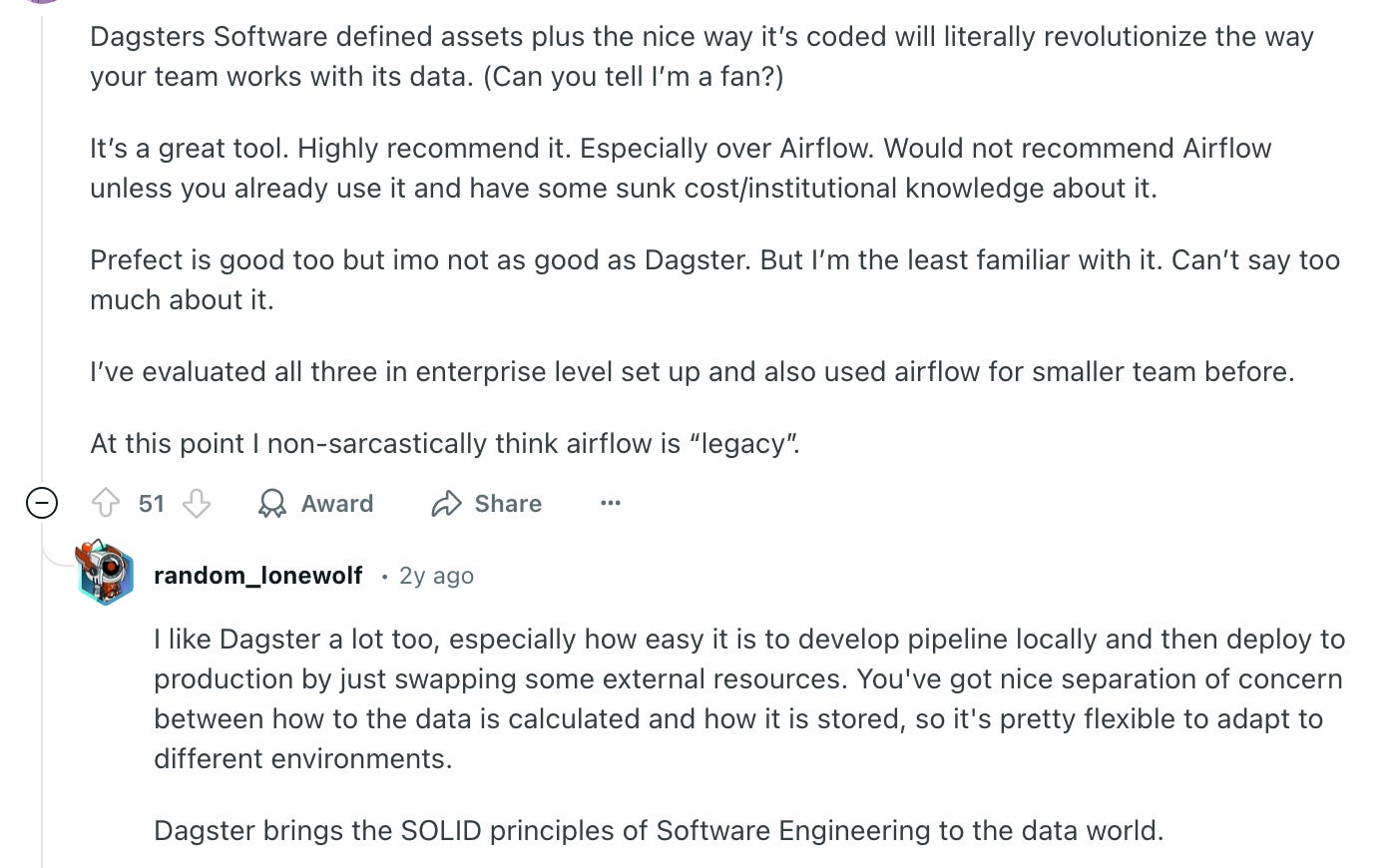
More Thoughts.
It’s my personal opinion that Apache Airflow is the go to for orchestration only, in the most classic sense of the word. It’s the 500lb gorilla in the room that has a massive community, lots of integrations and is “easy” to use. Easy to use in the sense of a massive community, a tutorial covering anything you could dream up exists somewhere.
But, it’s just that. Orchestration.
Anytime you wander into use cases that actually call for the manipulation and processing of data ON that orchestration platform, as your primary use-case, you will find a better solution in Prefect, Dagster, or Mage.
Which should you choose, Prefect, Dagster, Mage? How would I know? You need to use them and test them against your main use case, only that will answer your question.
Speaking of integrations, we should poke at a minute, because that is one of the MAJOR selling points of Apache Airflow. Because of its wide usage and community, it has simply and to use integrations for everything under the sun, which makes life easy in the Modern Data Stack.
Dagster appears to have, on the surface every kind of integration one could image. AWS and all its services (s3, EC2, etc, etc). Databricks, DBT, DuckDB, Kubernetes, Snowflake, Tableau, etc.

Mage integrations appear to be wide, but maybe not as all inclusive as Dagster? In their own documentation in integrations they don’t even list Databricks. It lists AWS s3 but not EC2, etc. Again, what do I know, just going off what they tell me.
What does Prefect list?

The Prefect list of integrations isn’t huge, but it does appear to cover all the big stuff, Snowflake, AWS, Azure, Databricks etc.
We don’t need to go over Airflow integrations because they are as far and wide as the sea.
The end of it all.
To be honest you could simply list every feature of all these orchestration tools side by side, but you will most likely only find that in marketing content. The truth is that picking an workflow orchestration tool is a complex task and requires a lot of nuance.
That nuance usually involves the specific use case of a Data Platform. For example, I crossed of Argo early on during this discussion because it was solely focused on Kubernetes. But, I’m sure there are many teams (even mine a few years ago), that mostly work on Kubernetes and would benefit greatly from Argo.
At the end of the road we should NEED a reason to stray off the beaten path. The beaten path in this case being …
Apache Airflow
Prefect
Dagster
Mage
One should probably also simply start with Airflow or one of it’s SaaS versions, AWS MWAA, GCP Composer, or Astronomer. It will most likely cover most use cases. But, there are aways the brave few looking to push the edges and boundaries of what’s possible. For these, something like Prefect, Dagster, or Mage are the order of the day.
Everyone is probably asking which one is “better,” Mage, Prefect, Dagster. That’s like asking what is the best cloud platform like AWS, Azure, or GCP. There is no REAL answer to that other than you can make each platform what you make of it.
Many successful and large Data Platforms are run on AWS, Azure, or GCP. Many data teams use Dagster, Prefect, or Mage to great effect. It’s more about the team’s needs and their execution rather than the specific tool.
I've been using mage for 6 months and had to add something with the newest pandas which then needed the latest sqlalchemy which then breaks everything.
Just gonna leave this here https://www.getorchestra.io/