

Simplifying CI/CD with Databricks Asset Bundles (DABs)
From Chaos to Control


Look, I don’t want to be a YAML engineer any more than you do. It’s one thing to have IAC (Infrastructure as Code), and another thing to have Pipelines as Code. Yikes. This old dog learns new tricks hard.
I’ve started to fix my wicked ways and use that killer of souls and happiness, terraform. Better late than never.
Trust me, I get the north star. We want reproducible, source-controlled, and easy-to-deploy codebases. The reduction of human error and the reduction of complexity are what we all strive for.
The question is, how do we get there? One solution available for Databricks teams is Asset Bundles, also known as DABs.

Today, instead of talking about theory, we are going to crack open Databricks Asset Bundles and try them out ourselves from scratch.
What is the user experience like?
What is the development experience like?
What is the deployment experience like?
Can DABs really be the end-all, be-all for bringing some consistency to out-of-control Spark and Databricks codebases and teams? The talking heads like to talk, be we like to DO.
Diving into DABs (Databricks Asset Bundles)
So, how does Databricks define a DAB?
🧰 Install CLI → 🔑 Auth → 🏗️ Init Bundle → 📦 Deploy → ✅ Test
“Bundle metadata is defined using YAML files that specify the artifacts, resources, and configuration of a Databricks project. The Databricks CLI can then be used to validate, deploy, and run bundles using these bundle YAML files. You can run bundle projects from IDEs, terminals, or within Databricks directly.”
- Databricks DAB DocsOk, so let’s learn by doing, step by step, until we have a feel for DABs and what they are actually like to use. Reading docs is one thing, but you will never learn a thing until you use a thing. It’s the difference between good engineers and GREAT ones.
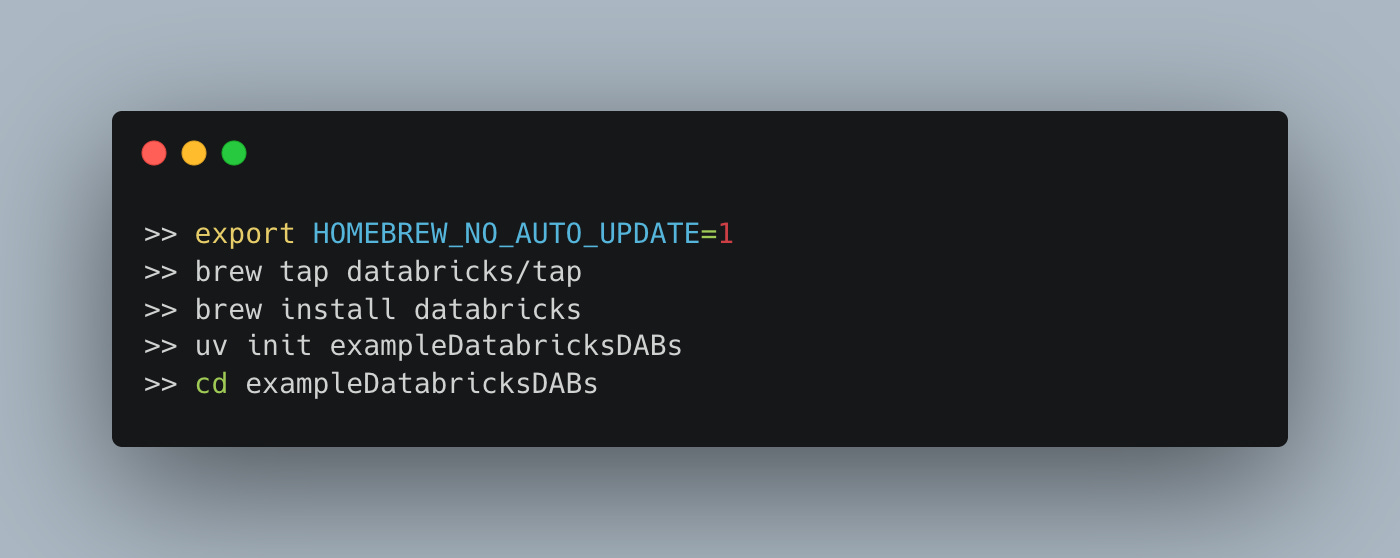
🧩 Step 1 - Installation
The first step in using DABs is to install the Databricks CLI, of course if we are going to use CI/CD for deployment on some system, we will need the CLI installed there as well.
Thanks to Delta for sponsoring this newsletter! I personally use Delta Lake on a daily basis, and I believe this technology represents the future of Data Engineering. Content like this would not be possible without their support. Check out their website below.

⚙️ Step 2 - Building a DAB
Ok, let’s create a brand new DAB bundle. The CLI gives us the option to use prebuilt default templates. Let’s use the Python one. They also provide the other options below for default projects.

To create a new DAB project from scratch … we run the databricks bundle init command.
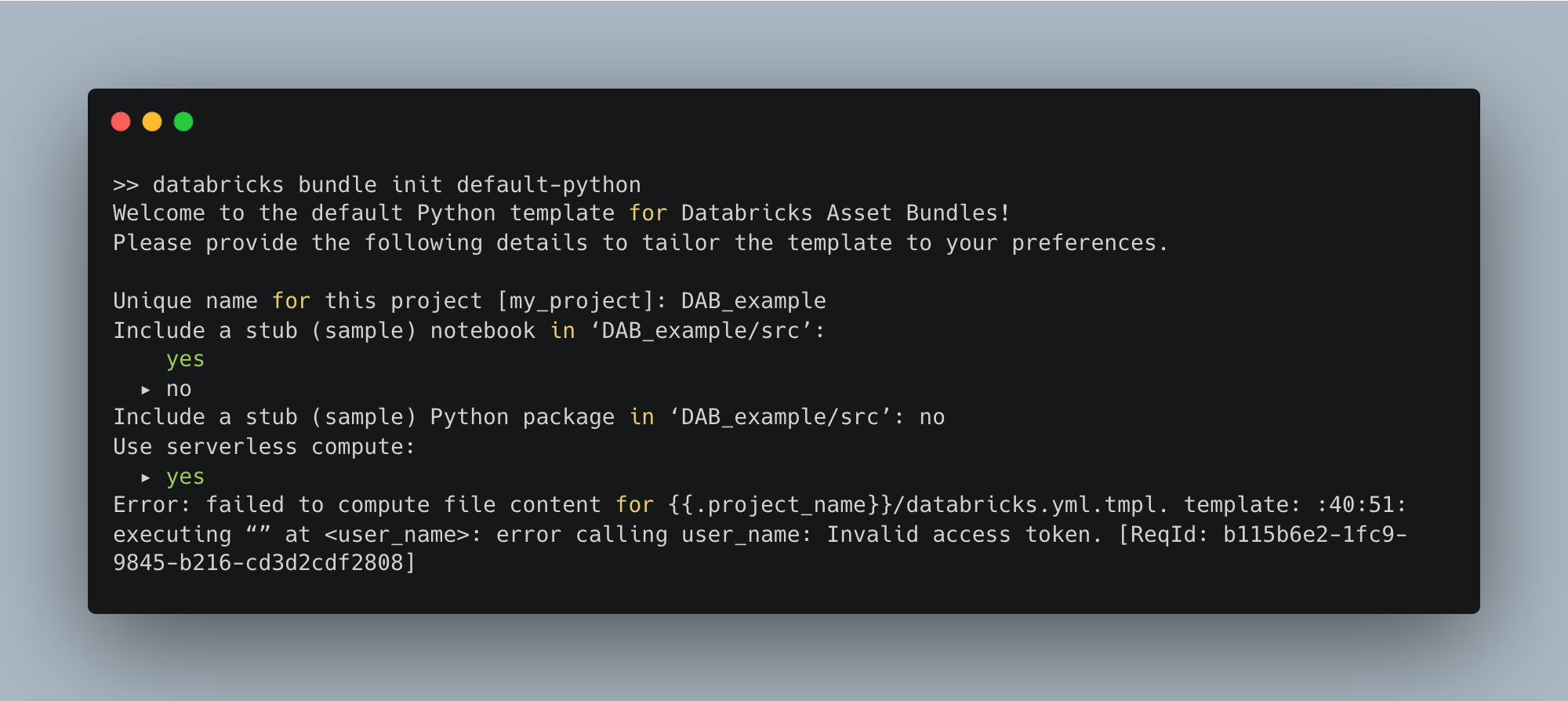
Not sure what that was about at the end, it failed. I’m assuming int was looking for a PAT token, maybe? The docs and instructions on setting up a DAB bundle don’t mention that at all. Most people don’t use the Databricks CLI except in the context of DABs.
💡 Pro Tip: Always auth the CLI before running
databricks bundle init.
🧾 - We need to make sure our Databricks CLI is authenticated.
This time, we get somewhere.
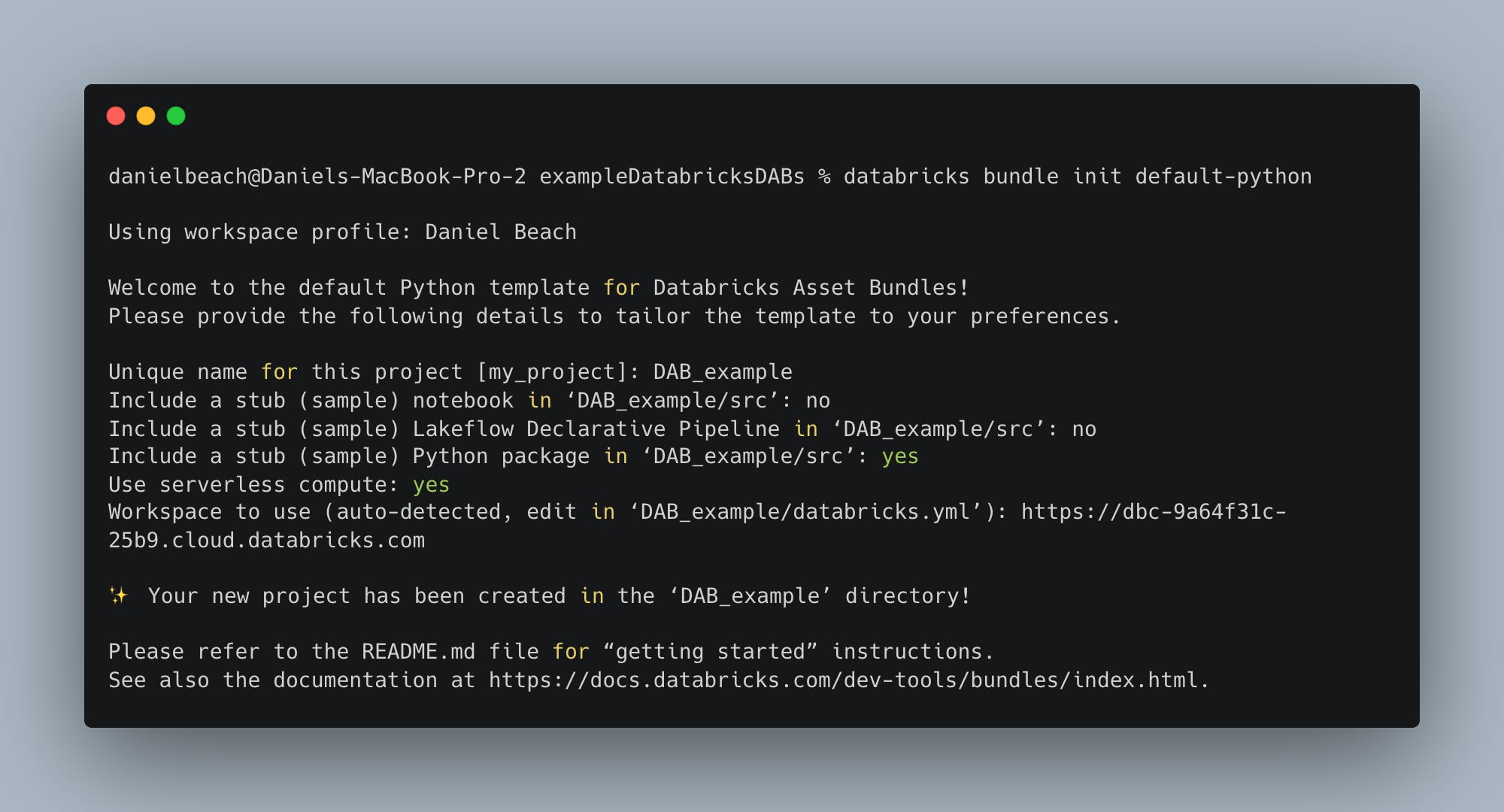
What is files make up a Databricks Asset Bundle?
Ok, so we have made our first DAB bundle, but what comes next and what is contained inside a DAB folder structure?
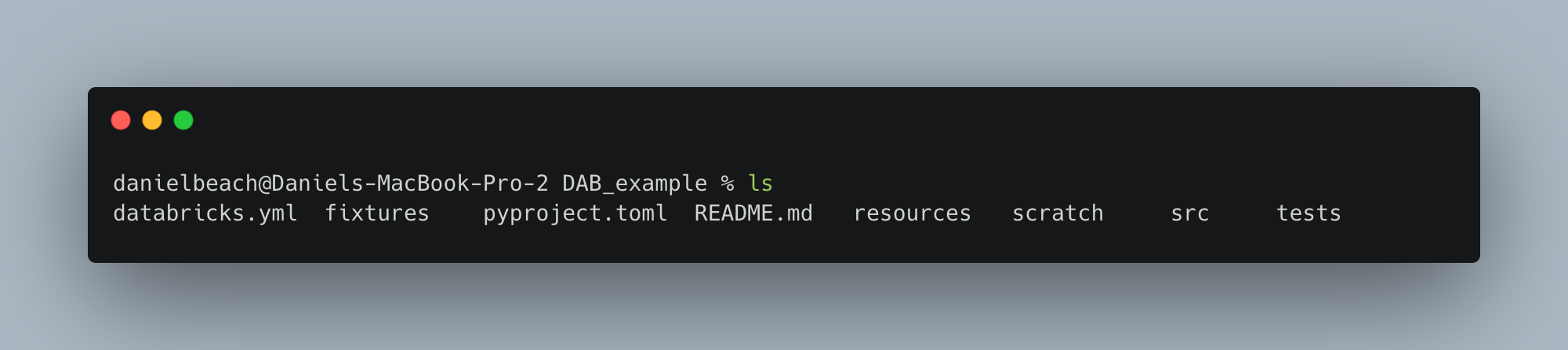
A bunch of folders and files. Below is generally what you would find created. 📂
[databricks.yml]
↓ includes
[resources/]
↓ references
[src/]
↓ used by
[Job Definition YAML]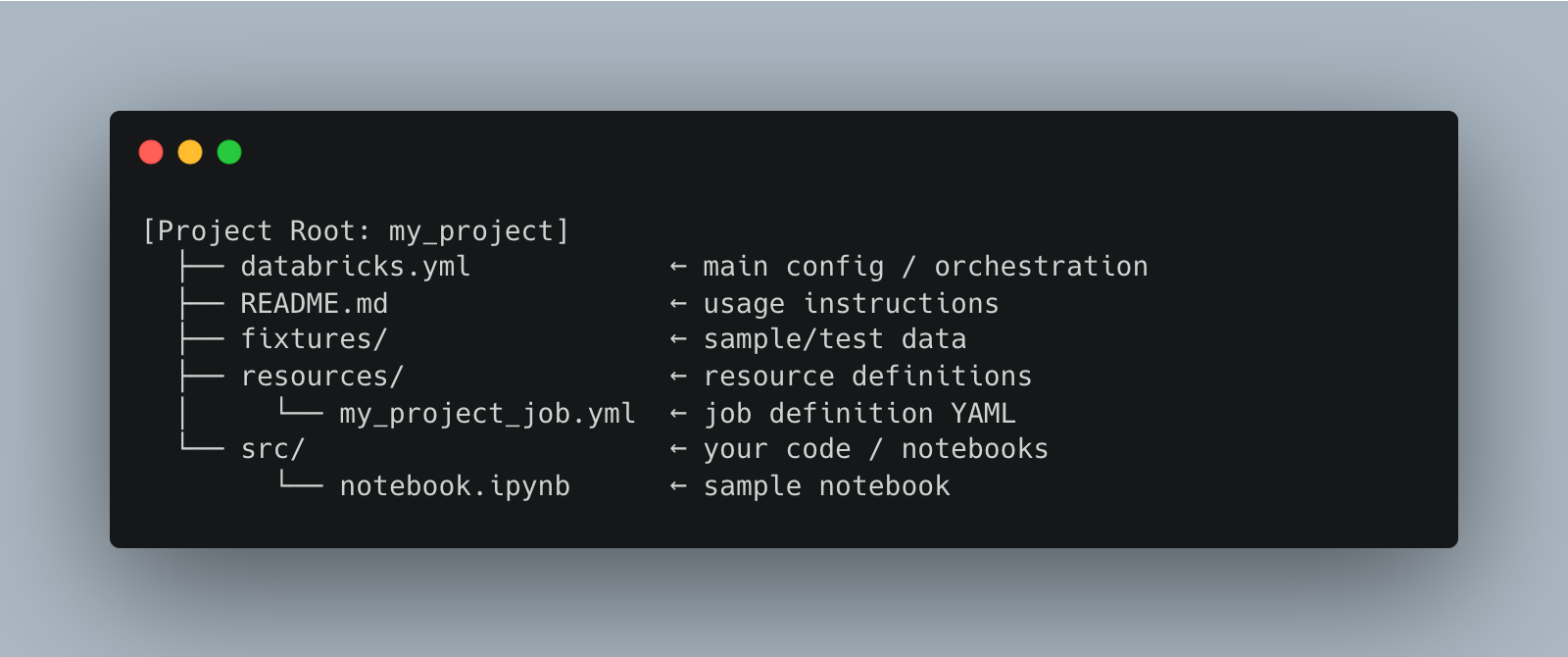
Let’s go over what each of these files and folders are for.
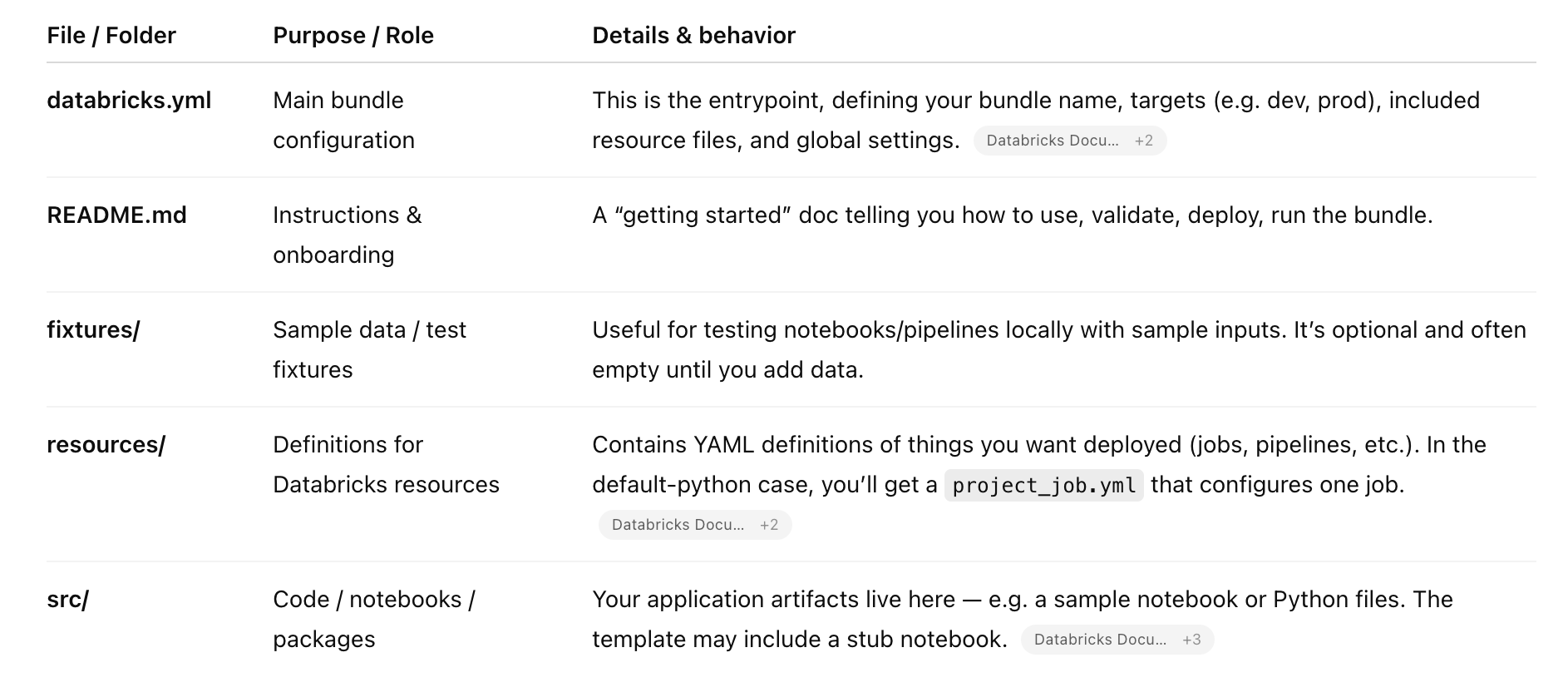
Just what one would expect, a bunch of YML files spread around in different spots, holding different configurations and definitions of Databricks resources.
I suppose there is no black magic hidden in there; it seems fairly straightforward once you get the lay of the land and figure out what each location is/does.

Worth it?
Now one could stop here and ask the simple question … “Is it worth it?” It probably depends on the context in which you are already creating and deploying your Databricks assets and pipelines.
Don’t forget, the main selling point of DABs according to Databricks themselves is “continuous integration and delivery (CI/CD)…”
It’s a way to package a software project and its dependencies so they can be easily managed, developed, and deployed. You might already be doing this without DABs. That’s ok. You should ask yourself if there is enough juice to squeeze to move to Databricks Asset Bundles, if already doing those things a different way.
Which many Data Teams are. Including myself.
“Worth it” is in the eye of the beholder. If you think your team could use a little extra …
structure and direction
ease of CI/CD with the Databricks CLI
… then by all means you should use DABs.
Getting into the meat and taters’
So if we open up our DAB_example project in a visual editor of our choice, we will be drawn to two main files that will probably take most of our time.
resources YAML
src Python code.
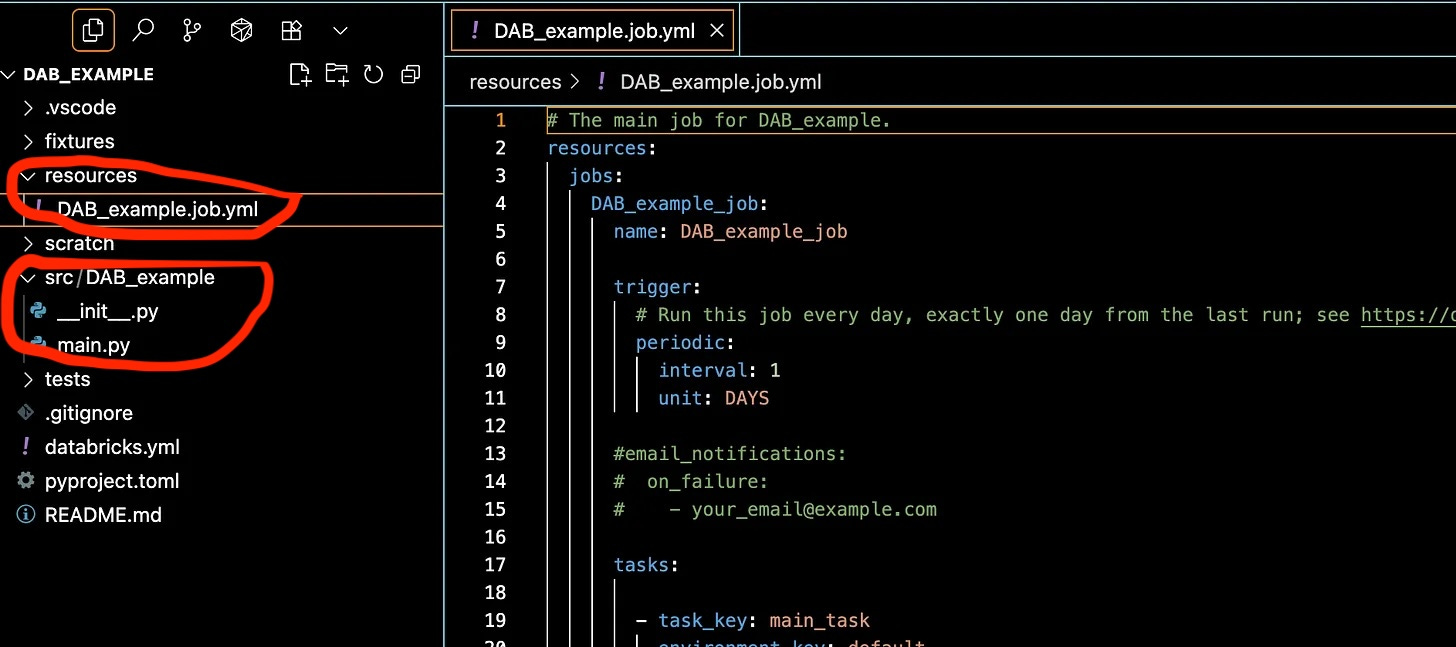
Of course, we do have things like databricks.yml where we can define the locations for Databricks production and development, locations etc. But after all, those things that probably won’t change much … the rest of a “normal development” lifecycle will probably be spent in defining Databricks Jobs with YML, and writing the PySpark code in the src location.
Example …
For example, say we have this table, confessions.default.hard_drive_failures, that holds the model and serial number by day for hard drives, and whether they failed or not.
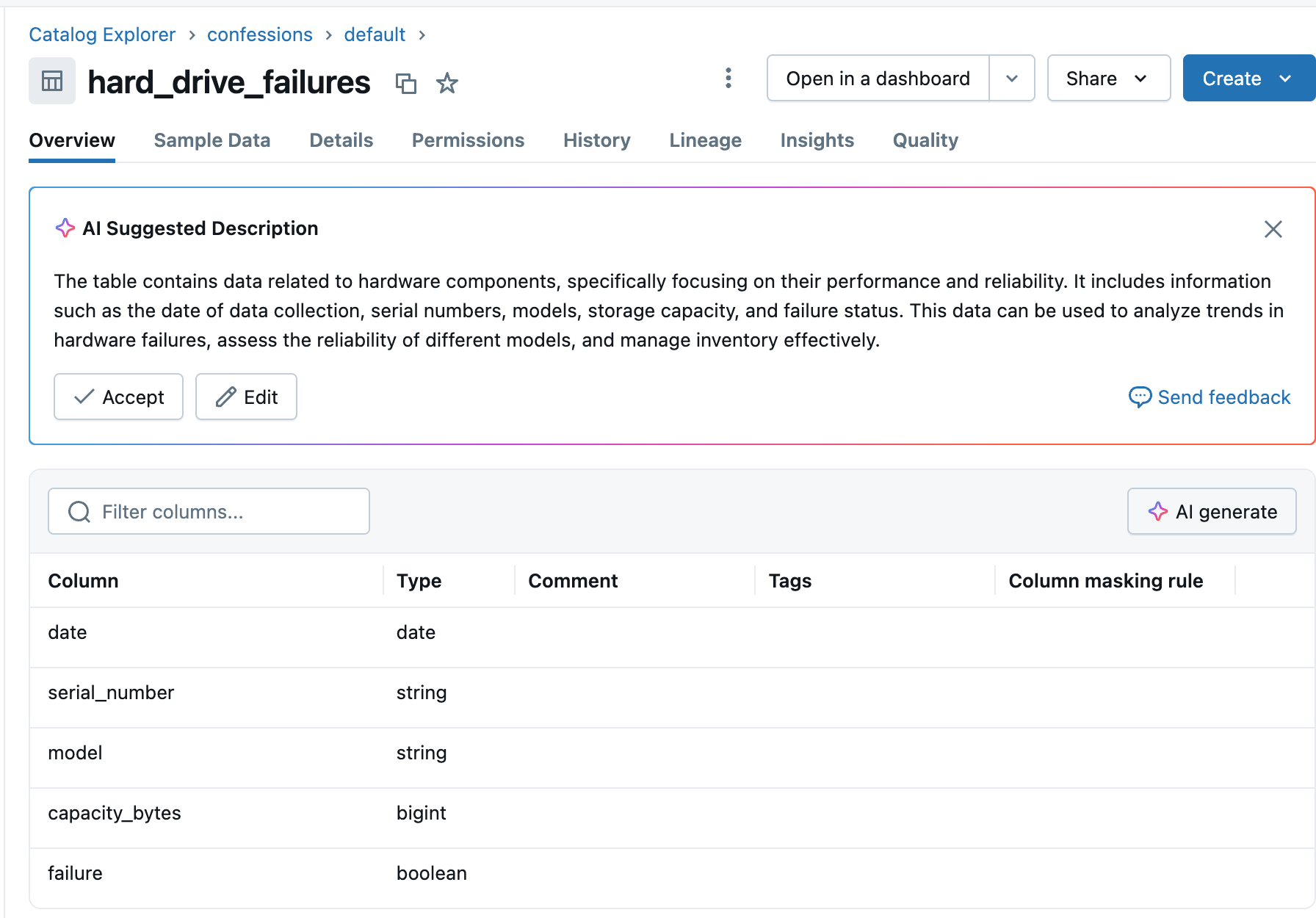
Maybe we want to create an analytics table, organized by month and year, showing the number of hard drive failures we’ve had.
Of course, we would write all our PySpark code and stick it in our src/main.py file. If we had a big project, we could define our customer libraries and logic here, etc. (this file inside the DAB bundle will be reference by other YML definitions)
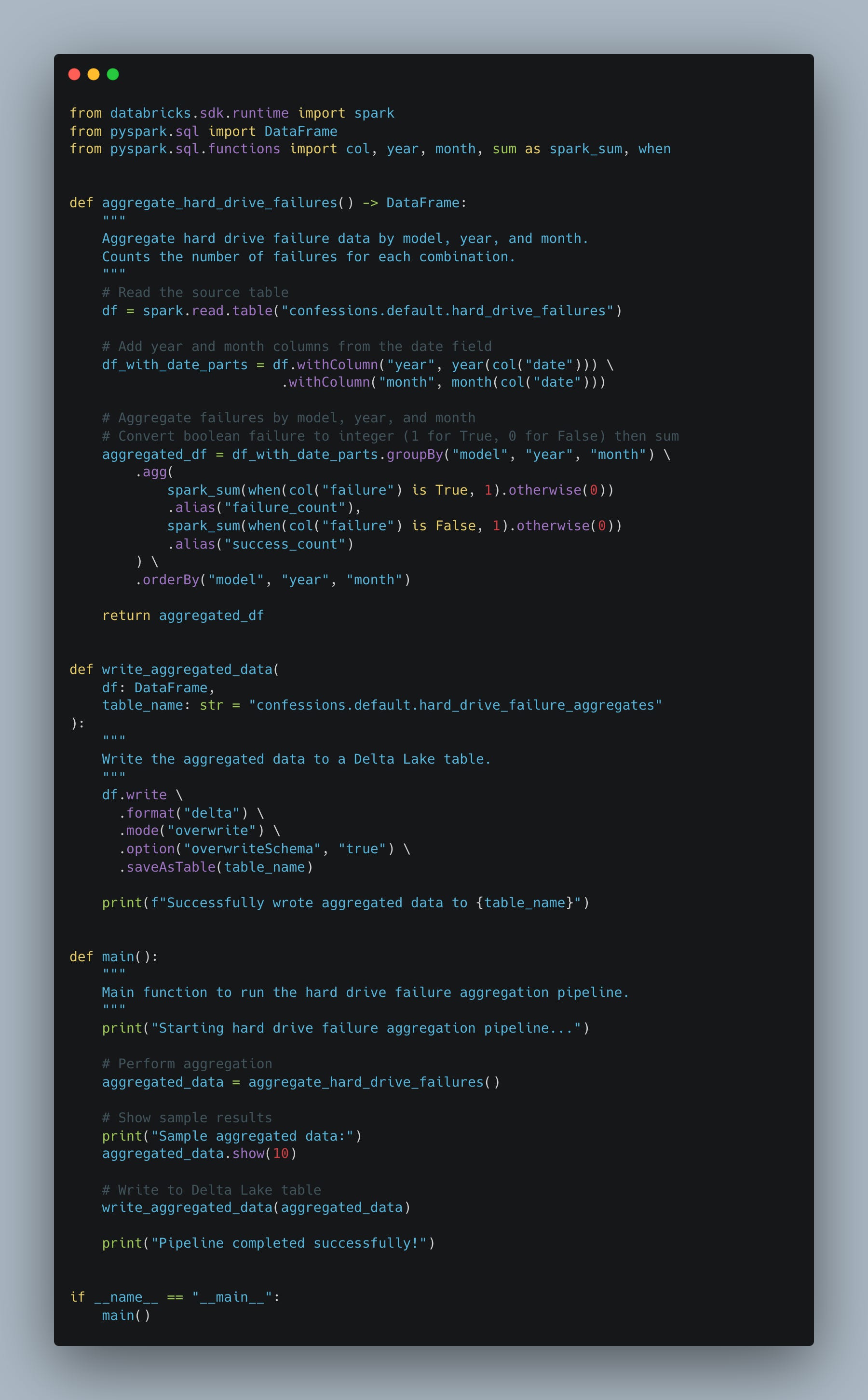
Then we would head over to our YML to define our job for this pipeline.
—> `resources/DAB_example_job.yml`
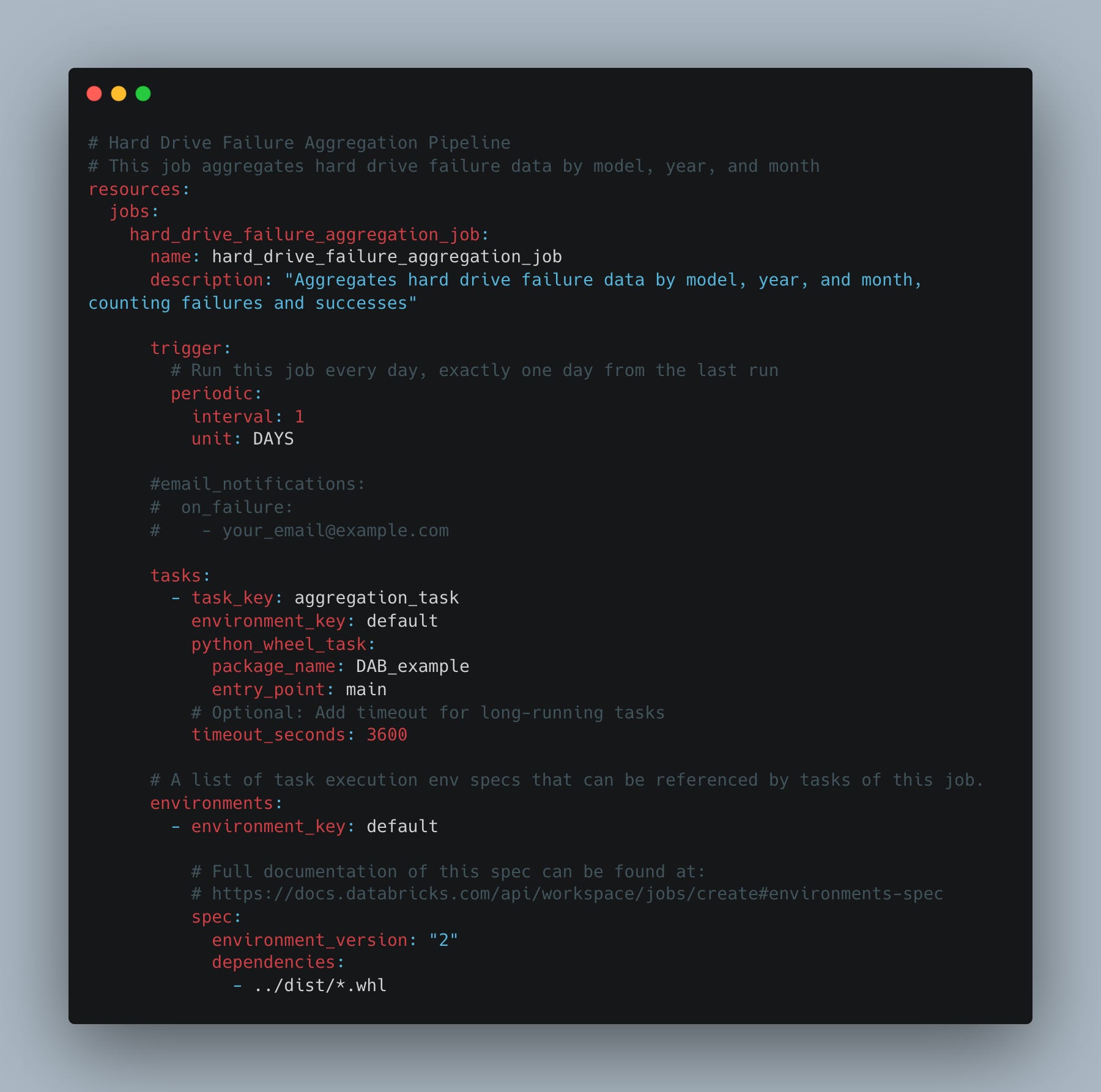
Note: if you look in the tasks, you will see our DAB_example and main resource noted … it’s our pipeline code.
None of this is too surprising or earth-shattering; it’s just the Databricks Jobs that run every day, defined in a YAML file that points to a source containing our source code.
Again, that doesn’t seem to be the big reason why Databricks Asset Bundles (DABs) were designed in the first place.
We are locked into HOW we define our pipelines and Jobs.
We get consistency across projects and pipelines
We get easier CI/CD thanks to this + the Databricks CLI.
The real power of DABs appears to lie in testing and deploying our pipelines. This is where the combination of the Databricks CLI, the fixtures (for testing) we’ve set up, and something like GitHub Workflows can create a bulletproof CI/CD pipeline.
In our example, it’s easy to create GitHub Workflows for both dev and prod deployments.
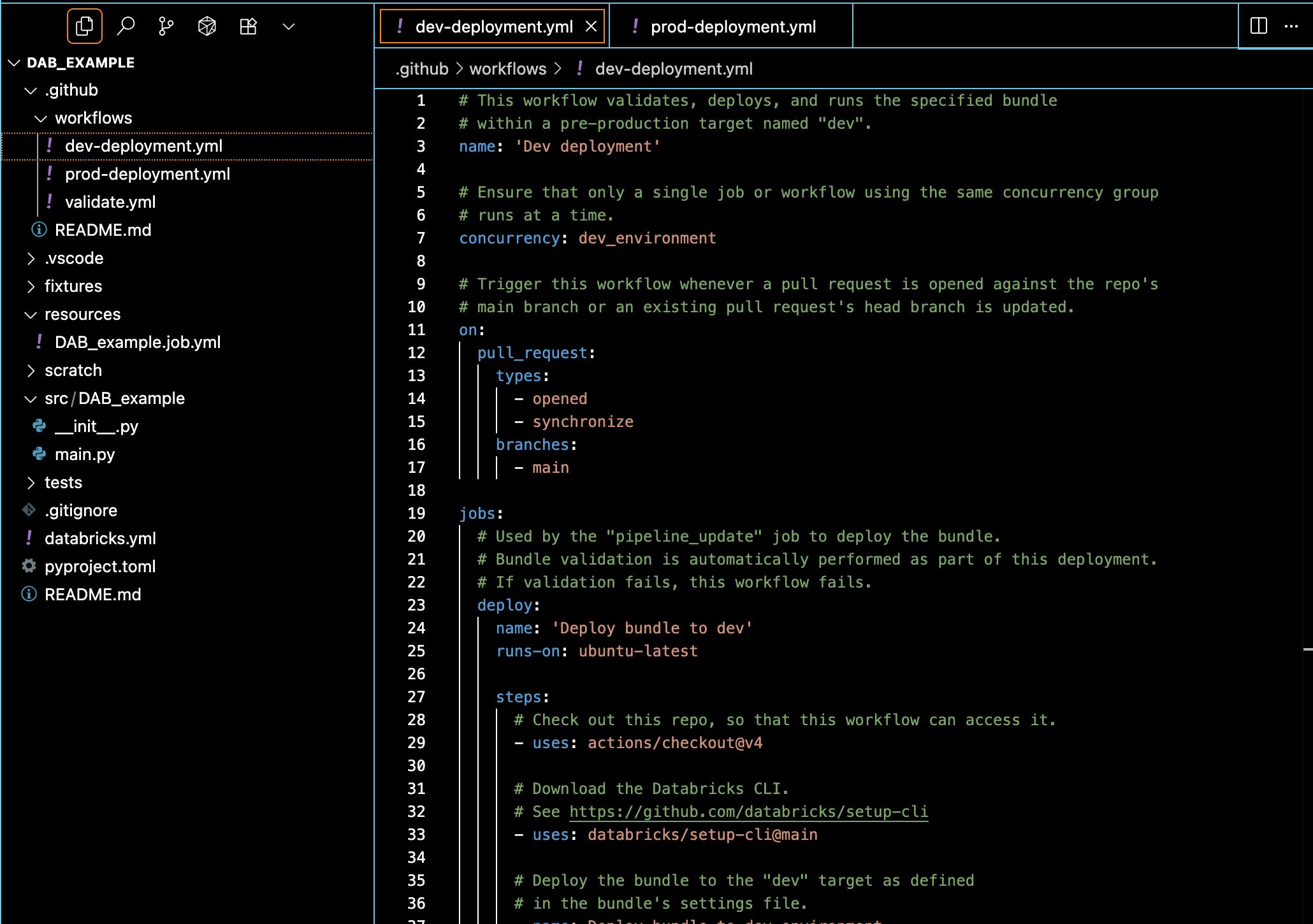
You can get all my code for this example on GitHub if you want to browse through it.

Again, there is no magic to DAB CI/CD. As you can see above, you're essentially telling GitHub: hey, if a pull request is opened, run this test, or hey, if something is merged to main, do that.
Very standard CI/CD stuff you should already be doing.
Yeah, yeah, I know.
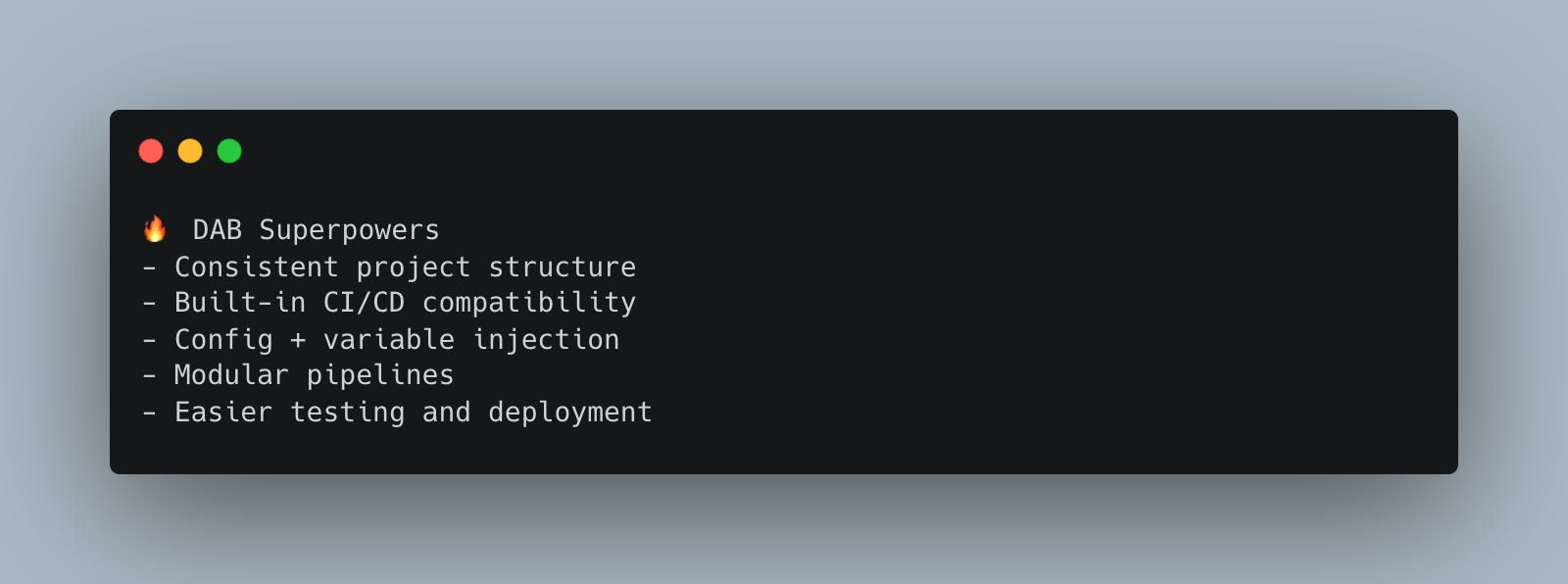
Look, I know we have barely scratched the surface of using Databricks Asset Bundles (DABs); they are as wide and deep as the big blue ocean.
We can with DABs …
Modularize complex sets of code/pipelines/environments
Variable and Configuration injection
Dynamic and artifact versioning
Define Dashboards, Apps, Volumes, Models, Schemas, etc
As with life and technology, you can make DABs as complex and far-reaching as you want, or not. You can keep it simple, as in our example, using DABs to keep everyone on the same page when defining Jobs and storing Spark code.
You can use it as a way to run tests in an automated way, or just as the perfect tool to deploy your production code.
I think it’s the flexibility and combination of all of the above features that make DABs attractive.
Should you, I, we, use Databricks Asset Bundles?
That’s more of a question of the heart and mind, rather than a strictly technical answer. I can tell you today, on the Databricks Platform I built and run, that I do not use DABs to build, manage, test, or deploy the myriad of Databricks Jobs and ML pipelines that get run.
Yes, I’ve thought about it.
It’s a great way to bring continuity to the chaos.
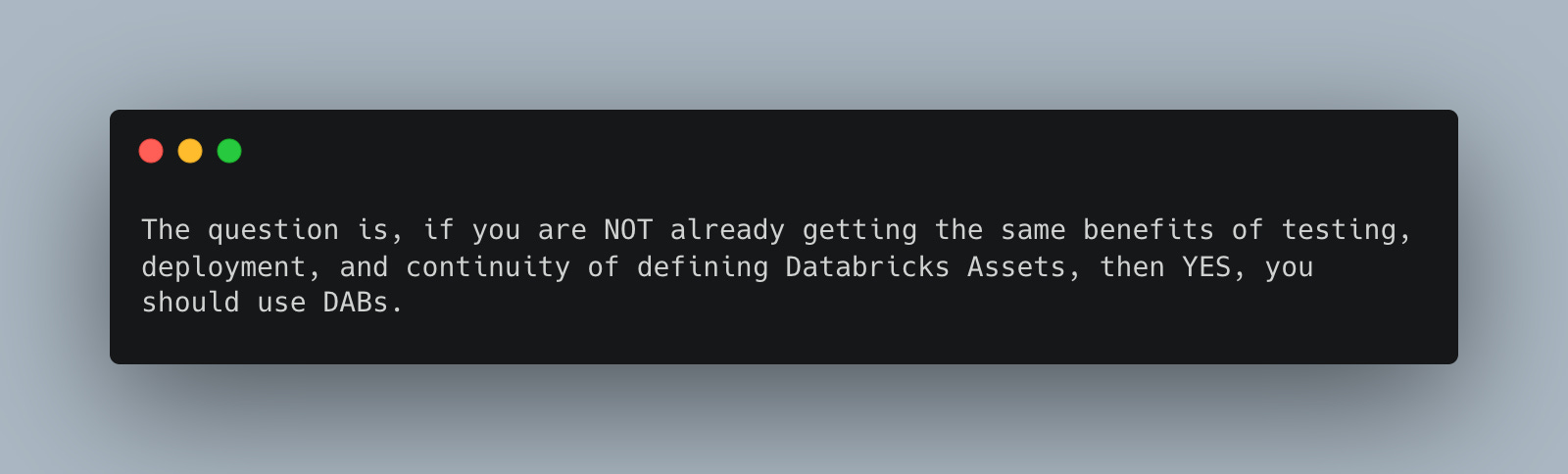
If you are already using other means to test, deploy, and manage your Databricks Pipelines, should you switch to DABs? Depends on how much time you have on your hands.
Assuming Databricks continues to invest time and effort into DABs, then yes, it might be good to do a migration project over the long winter. If you are happy with your current setup and don’t have any holes … then you probably won’t get any “amazing” breakthroughs migrating to DABs.
Only you will know the answer to this question. Most likely, you will never regret migrating to or using DABs; there is no downside if used properly.
Deployed my first pipeline using DABs this week. It works a treat! One thing perhaps worth adding, the Databricks VSCode extension makes creating and testing DABs even easier (for those like me that are command line phobic)
working with PyDaBs is also fun.. much better compared to databricks.yml