Spark. Postgres. Duplicates. Dang it.
a lesson in fundamentals

I recently came across the most classic Data Engineering problem of the last 50 years. Duplicates records. It was some “old code”, if you call 5-year-old Databricks Spark code old, which is like 15 years in Databricks years. To me, it was the perfect example of taking time, a lesson in the most basic fundamentals of data.
It’s not a particularly earth-shaking problem in and of itself, rather boring, but it’s a story that re-enforces the age old ideals.
Since the days of my data youth, heck, harkening back to my LAMP stack years in college, data duplication has been an issue that somehow manages to creep into database tables of all shapes and sizes.
History is doomed to repeat itself; programming and logic errors, conundrums, and slipups are par for the course. I mean, those little blighter LLMS were literally trained on our collective sins, so what makes you think things will get any better?
That’s what I thought.
Thanks to Delta for sponsoring this newsletter! I use Delta Lake daily,
and I believe it represents the future of Data Engineering. Content like this
would not be possible without their support. Check out their website below.
We start at the beginning.
What is your life really like if at some point during the past 365 days you get a message from someone “on the business side” that so-and-so is showing duplicate records? A tale as old as time, this.
First off, and before you throw a fit, hear me out: What is a duplicate record?
That is indeed NOT a stupid question. Didn’t your middle school teacher ever tell you that there is NO such thing as a stupid question? It’s true. When it comes to data, you simply cannot assume anything. Like anything … at all.
Sometimes duplicates are by design. It might have been a faulty assumption or a bad decision, but by design in many cases. One of the recurring fundamentals of data, when you encounter a new, or a new-to-you dataset, should be the question … “What is the grain of this dataset?”
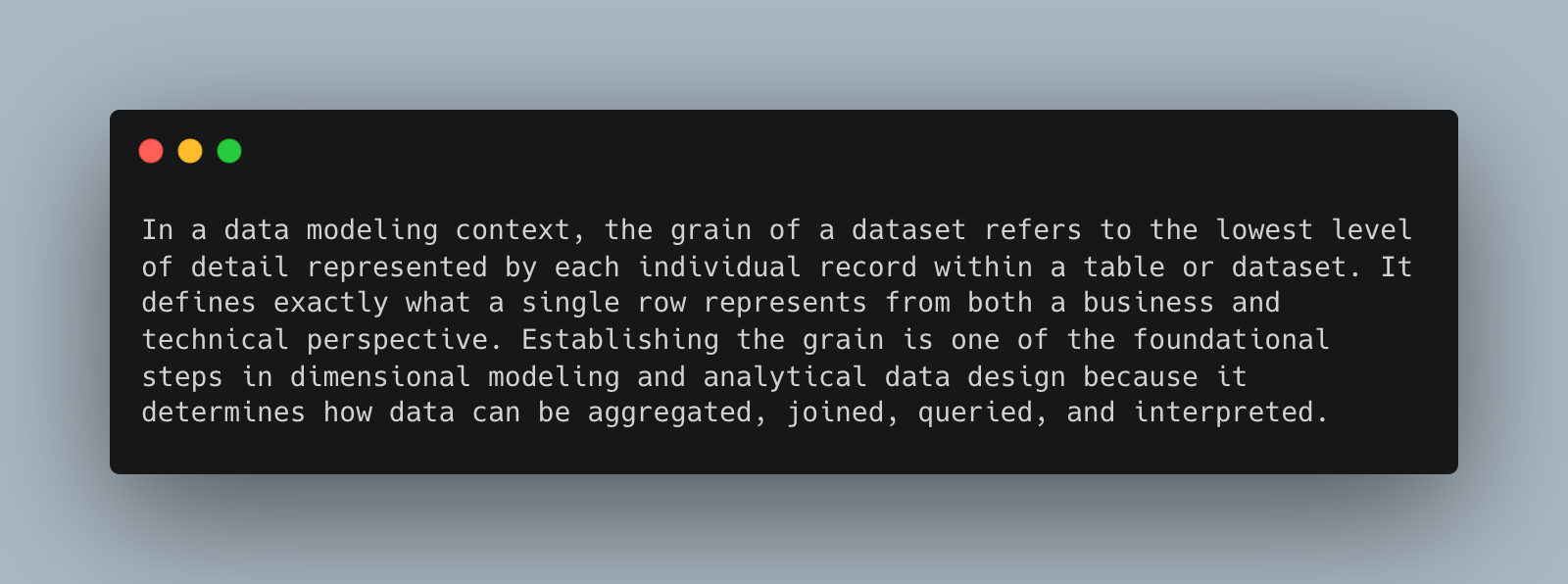
Before running off to solve any duplicate data problem or looking for a bug that might not exist, one should start from the ground floor. It’s just good table manners, and good for you as a technical person.
It’s hard to solve a problem, especially a data problem involving duplicates, unless you have solved the many times tricky problem of figuring out what makes each record in the dataset unique. It’s never the same for any two datasets, or rarely is.
Also, before we talk about the problem I encountered, I think we should break down another great way to approach duplicate data to ease the stress of solving issues that can be buried in a complex and large system.
We should separate any data system or duplicate data research into three big boxes. These boxes can help us narrow down the scope of the problem and where to best unleash the Claude hounds to find it.
Source
Transformation
Destination
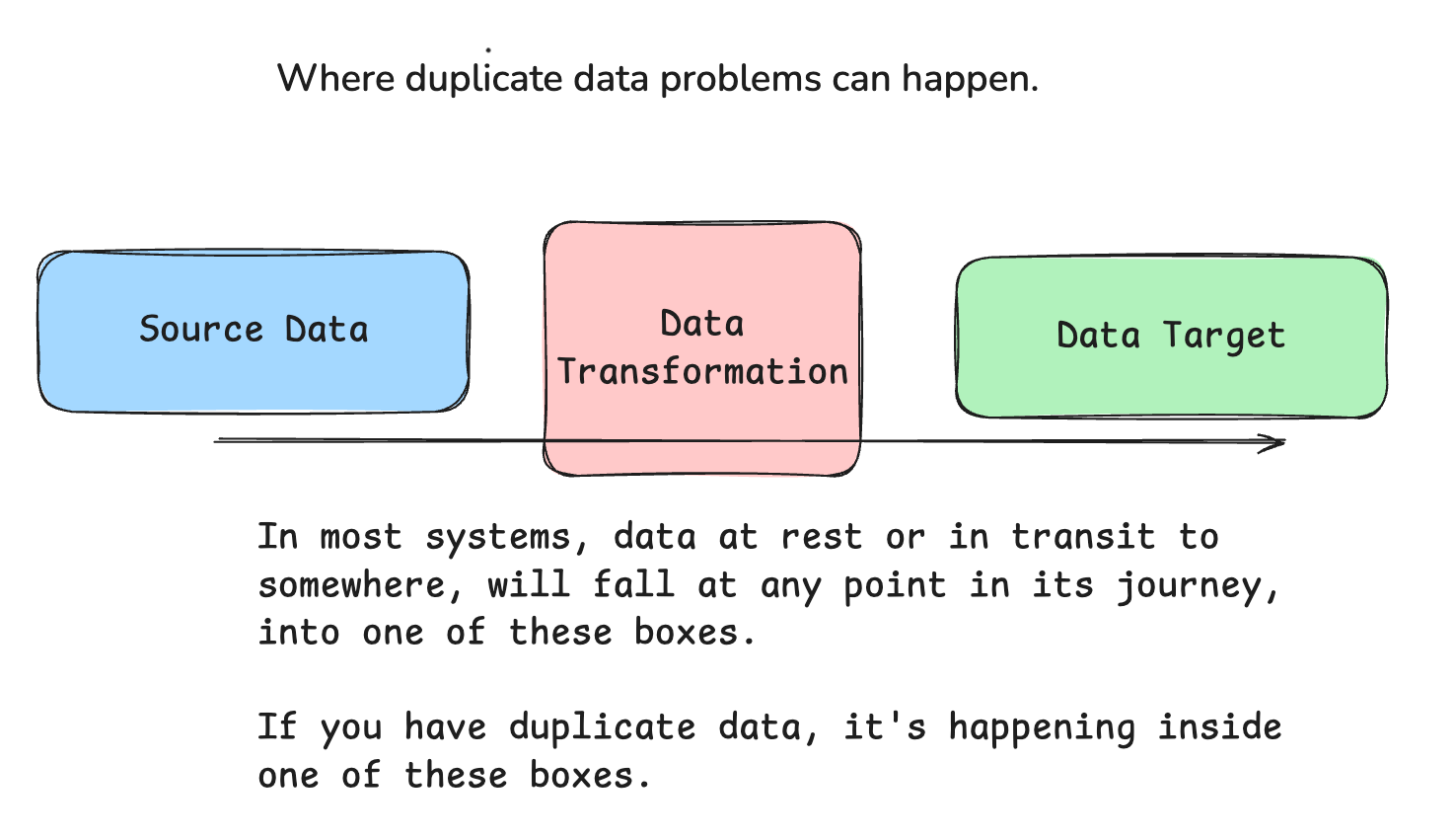
This may seem painfully obvious, but when we approach a problem like duplicate data in large, complex systems, finding the bug can be overwhelming. Being able to logically and technically differentiate where a problem is, or isn’t, will make our jobs and time to resolution much quicker and less stressful.
Back to the problem at hand.
So, back to my boring storing of trying to solve an intermittent duplicate data issue within a few short hours, so I could get back to the AI salt mines.
Here’s what I knew.
Duplicate data issue showing up inconsistently in a Web UI.
Some days there are duplicates, some days are not.
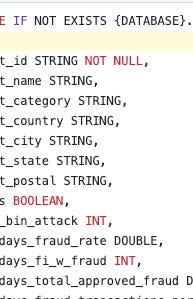
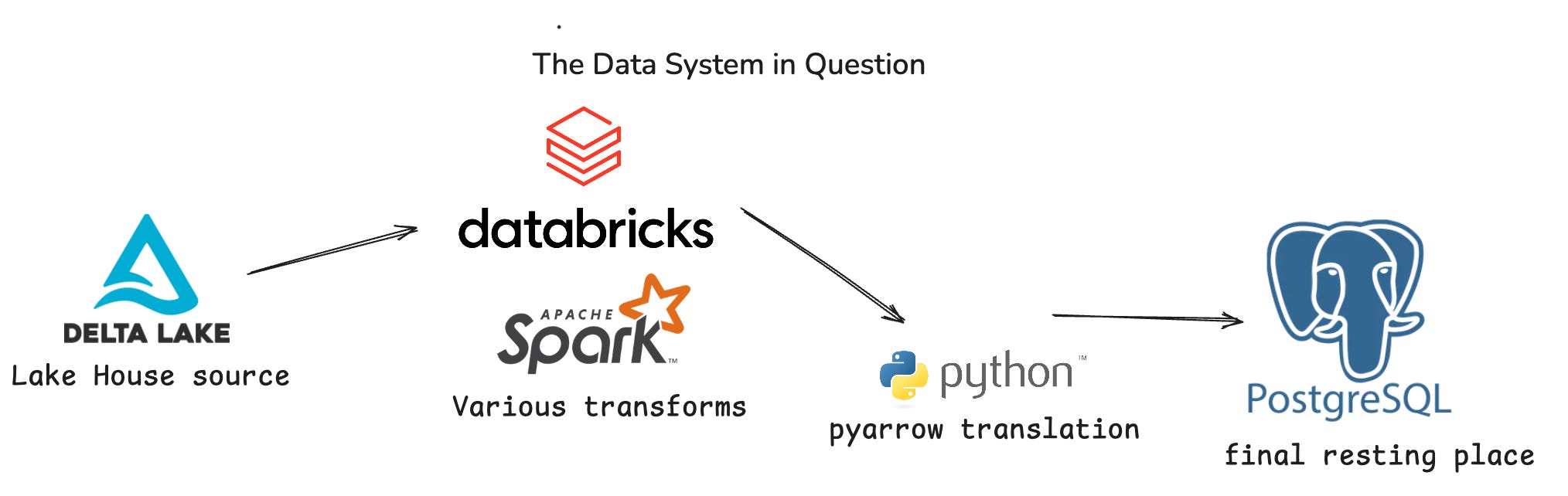
Pipeline from source to finish included …
Delta Lake House
Databricks Spark transformation
Python script to push said data to Postgres.
Web App pulling data from Postgres.
Now, logically, the data problem could be anywhere, although the intermittent nature of the duplicate data would probably preclude problems in the Web App.
Also, when working in large data systems, the best you can do is control the controllables rather than blame others. My plan was simply to eliminate the possibility of duplicates insofar as the data systems I CONTROL.
A good rule of thumb for data, and life … control the controlables, don’t worry about the rest until you have too.
When I first heard the word “intermittent”, I had some suspicions in my mind. But, being the fundamentalist I am, I started with the Delta Lake Table.