

Spark vs Polars. Real-life Test Case.
A Brave New World.


Sometimes I think people misunderstand things … like a lot. The Spark vs Polars topic is one of those topics that can be heavily shrouded in hand-waving arguments and other general mud-slinging. I mean, I like to throw mud too, who doesn’t?
Spark vs Polars. Is it a thing? Which one should a Data Team use in their stack?
I venture to step on the old soapbox and give my two cents. I will yell my beliefs from the rooftops for all to hear. I have a prediction, nay, I have a wish and a hope for the future, a desire for what Data Engineering with Spark and Polars could look like.
“ I believe that 80% of Spark workloads don’t require Spark after all. Polars with it’s Lazy nature, will, and can, easily replace a great many expensive and heavy workloads … contributing directly to a reduction in costs.” - me
You should check out Prefect, the sponsor of the newsletter this week! Prefect is a workflow orchestration tool that gives you observability across all of your data pipelines. Deploy your Python code in minutes with Prefect Cloud.

Let me spin you a tale and a story.
This sums up most Datat Teams that I have worked on over the years. Absolutely we need Spark. Many datasets are billions+ and PBs+ of data that need to be aggregated, joined and crunched. Spark is the only way.
But, there is another reason we all use Spark … everywhere. Because the barrier to entry is low (Databricks, EMR, Glue), and it’s easy to use (SparkSQL and Dataframe API). Anyone can do it with a day or two of practice. Maybe not well, but they can do it.
It’s like Python. It’s too easy not to use. So we ended up with Spark running everything.
It’s convenient to be on a single tool.
We can use SparkSQL.
It’s offered as a managed service by everyone.
It’s good for job prospects (it’s expected).
But then we look back and find ourselves in a spot we might not like that much.
What spot is that? It's an expensive spot. Like … really expensive. We found we are creatures of comfort. We ran everything with Spark, for convenience, kept adding, tacking on the side, every new job, every piece of data, all Spark.
And now we are paying out the nose for it.
Testing if Polars is up to the task.
And this my friend, is where the rubber meets the road. Can we prove this theory of mine right or wrong? I mean I have put Polars in production before … but it was replacing a Pandas-type workload.
Can it do more? Is it capable of more?
Polars has a few things on its side.
SQL Context.
Lazy evaluation
Query optimizations
These are Spark-like features. Do they give Polars the ability to step into the breach? This is what our Brave New World in Data Engineering should look like.
Ok, enough chitter chatter, time to get to work. Today’s order of business … 27GBs of flat files stored in s3 … Spark vs Polars on a Linode (cloud) instance. (data from Backblaze open source hard drive data set)

First, we have to find something to do with the 27GBs of data, write some simple data transformation, and deposit the data into a Lake House.
I’m going to copy all the data down from s3 over to the local drive on this Linode machine I’m using. I’m curious how both Spark and Polars compare without adding complexity like network overhead, although that is an interesting question in itself between the two.
Read 27GB+ of CSV data.
Transform data.
Write data to a Parquet Data Lake.
Once with a Spark on a cloud instance.
Once with Polars on a cloud instance.
Here is what the hard drive data set looks like.
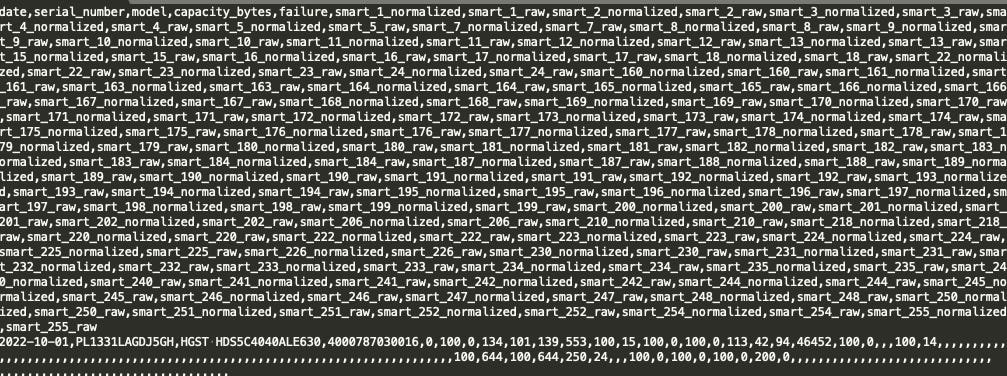
So first we will convert the CSV files to partitioned parquet files, so we can more easily work with the raw data in the future. Next, we will read those partitioned parquet files, do some aggregation to get some metrics and write those metrics to a partitioned parquet dataset. Pretty normal stuff.
What we need to find out is … will Polars step up to the plate?
Spark Pipeline.
First, we need a machine to test this all one. We will use Linode, an Ubuntu 6CPU and 16GB RAM machine. This should be an interesting test.

This isn’t meant to be some perfect side-by-side test. We just want to prove that, generally, can Polars deal with 27GB of data with reasonable performance without dying?
We know Spark can do this, that’s why we use it.
This 27GB data size is good, it represents a big enough dataset that Pandas would most assuredly puke, and at that point, most folk would simply reach for Spark. Again, we are asking, can we reach for Polars, and what is the performance like?
To set up Spark on my Linode, I followed my own instructions, using Spark 3.5.0. It looked something like this.

Let’s start with our baseline data pipeline in PySpark, a pretty normal script that would be written a million times all over the world.

Nothing too crazy about this code …
Read raw CSV files.
Write to partitioned parquet (Data Lake).
Read data from parquet (Data Lake).
Do analysis.
Save results back to parquet (Data Lake).
This first run was a failure with Spark.
23/11/04 21:20:14 INFO CodecPool: Got brand-new compressor [.snappy]
23/11/04 21:20:26 ERROR Utils: Aborting task
java.lang.OutOfMemoryError: Java heap spaceSo I tried with this …
spark = SparkSession.builder.master("local[*]").config("spark.executor.memory", "12g").getOrCreate()Still out of memory. Next this …
spark = SparkSession.builder.master("local[4]") \
.config("spark.executor.memory", "12g") \
.config("spark.driver.memory", "2g")
That was the ticket! Pretty long runtime, about 17 minutes. But, that’s the power of Spark. We processed 27GBs+ of data on machine with 16GB of memory.

More than anything we just wanted a few normal type steps, aka, ingesting raw data in a few Data Lakes and doing some aggregation.
Let’s open the metrics results parquet dataset to ensure this code actually worked.

Good enough.
Polars code.
Not going to lie, I’m jittering with anticipation about how this whole thing will or will not work with Polars. Can its lazy nature truly come through for us?
What I want to know is … can Polars replace Spark for some workloads … Polars can replace Pandas, we know that. But does it have a brighter future as well, can it replace large workloads on single nodes? Can it give us cost savings?
Imagine replacing some Databricks job with a Polars job on an Airflow worker. That’s real money that is.
We should be able to reproduce this script easily enough in Polars. It will be interesting to see the rough performance of each as well.
Here is my Polars code.

Positives of Polars code.
It’s simple and easy to read
Mirrors the PySpark syntax we are used to.
Offers Lazy Evaluation options to work with larger-than-memory data.
Downsides of Polars code.
Here are some complaints about this Polars code. Using a LazyFrame to `sink_parquet`, unlike the normal Dataframe parquet write does not appear to offer pyarrow options to write with partitions. What am I missing?
Why would I want to write parquet files without partitions? Bugger me if I know.
Also, I had to pre-make the sink_parquet directory for writing the parquets, if it didn’t exist the code would error. Not very helpful.
Polars Results.
Well, there is none. Sorry. It ran for hours, I tried again, and let it run all day. It tried. CPU would spike, Disk I/O would spike.

I got my hopes up, then down.
The surprising thing was with the Polars code it could never even finish streaming the CSV’s to Parquets. That’s a letdown. I know this because the script would get as far as creating that write directory.
Also, later when I removed that part of the script to see if I could get Polars to at least stream-read the CSV files and do the aggregation, without the intermediate Parquet step … the script failed with the syntax errors at a spot right after the intermediate parquet write.
I never thought Polars with its “lazy” way of reading a CSV file and then streaming and sinking it to a parquet … without even doing any partitions, would fail.
The Strange Part.
You know the strange thing? I removed the intermediate parquet write and had Polars stream read the CSV file and string sink the groupBy results. And it worked. Fast.

It ran in a little over 30 seconds. That’s amazingly fast, 27GB+ of data. Dang. But what the heck?
Time to run polars pipeline : 0:00:32.158017>>> df = spark.read.parquet("hard_drive_failure_metrics")
>>> df.show()
+----------+----+-----+---+--------------------+--------+
| date|year|month|day| model|failures|
+----------+----+-----+---+--------------------+--------+
|2023-03-23|2023| 3| 23| ST14000NM0018| 0|
|2023-06-16|2023| 6| 16|HGST HUH721212ALE600| 0|
|2023-04-23|2023| 4| 23|TOSHIBA MG08ACA16TEY| 0|
|2023-05-12|2023| 5| 12| ST1000LM024 HN| 0|
|2022-10-19|2022| 10| 19| ST12000NM0008| 2|
|2021-08-03|2021| 8| 3|HGST HUH721212ALE600| 0|
|2023-01-19|2023| 1| 19|HGST HMS5C4040BLE640| 1|
|2023-02-28|2023| 2| 28|HGST HUS728T8TALE6L4| 0|
|2023-01-26|2023| 1| 26|HGST HUS728T8TALE6L4| 0|
|2023-01-01|2023| 1| 1|HGST HUH721212ALE600| 0|
|2022-11-09|2022| 11| 9|Seagate BarraCuda...| 0|
|2023-01-25|2023| 1| 25|HGST HUH721212ALE600| 0|
|2023-02-27|2023| 2| 27| ST16000NM005G| 0|
|2022-11-02|2022| 11| 2|TOSHIBA MG08ACA16TEY| 1|
|2023-03-06|2023| 3| 6| WDC WUH721816ALE6L4| 0|
|2022-10-18|2022| 10| 18| ST10000NM001G| 0|
|2023-04-07|2023| 4| 7|Seagate BarraCuda...| 0|
|2023-05-26|2023| 5| 26|TOSHIBA MG07ACA14TEY| 0|
|2023-04-16|2023| 4| 16| WDC WD5000LPVX| 0|
|2021-08-20|2021| 8| 20|HGST HMS5C4040BLE640| 0|
+----------+----+-----+---+--------------------+--------+
only showing top 20 rows
Now I’m wondering what I did wrong. Is Polars still just new and has some bugs and nuances that need to be worked out? There must be something wrong with my two simple functions, one scan_csv, and one sink_parquet.
def read_csvs(path: str):
lazy_df = pl.scan_csv(path)
return lazy_df
def write_parquets(lz, path: str) -> None:
lz.sink_parquet(path,
compression='snappy',
)I mean that’s all the first step was, and that’s what Polars would choke on. If you think about the difference between these two things … the final working Polars code is simply doing aggregation, it’s still scanning CSVs and sinking parquets. Just not twice like the other one.
It made me curious, what if I changed the code to do a simple SELECT on the subset of columns used for the aggregation, and put that method between the scan_csv and sink_parquet of the original code that wouldn’t finish?
lz = read_csvs(read_path)
lz = lz.select(["date", "model", "failure"])
write_parquets(lz, write_path)I did this above. Simple change. You wouldn’t believe the results.
Time to run polars pipeline : 0:00:34.843670I had to double-check the intermediate results, just to make sure my eyes didn’t deceive me. Heck, how is this possible? Crunching 27GBs+ of data in 34 seconds? Inconceivable.
>>> df = spark.read.parquet("parquets")
>>> df.show()
+----------+--------------------+-------+
| date| model|failure|
+----------+--------------------+-------+
|2023-01-01|HGST HDS5C4040ALE630| 0|
|2023-01-01|HGST HMS5C4040BLE640| 0|
|2023-01-01|HGST HMS5C4040BLE640| 0|
|2023-01-01|HGST HMS5C4040BLE640| 0|
|2023-01-01|HGST HMS5C4040BLE640| 0|
|2023-01-01|HGST HMS5C4040BLE640| 0|
|2023-01-01|HGST HMS5C4040BLE640| 0|
|2023-01-01|HGST HMS5C4040BLE640| 0|
|2023-01-01|HGST HMS5C4040BLE640| 0|
|2023-01-01|HGST HMS5C4040BLE640| 0|
|2023-01-01|HGST HMS5C4040BLE640| 0|
|2023-01-01|HGST HMS5C4040BLE640| 0|
|2023-01-01|HGST HMS5C4040BLE640| 0|
|2023-01-01|HGST HMS5C4040BLE640| 0|
|2023-01-01|HGST HMS5C4040BLE640| 0|
|2023-01-01|HGST HMS5C4040BLE640| 0|
|2023-01-01|HGST HMS5C4040BLE640| 0|
|2023-01-01|HGST HMS5C4040BLE640| 0|
|2023-01-01|HGST HMS5C4040BLE640| 0|
|2023-01-01|HGST HMS5C4040BLE640| 0|
+----------+--------------------+-------+
only showing top 20 rows
>>> df.count()
82181678Above are the intermediate results of that Polars pipeline with the select added. Spark took 17 minutes!!
But, we should revisit that. To be fair we should add the SELECT to our PySpark pipeline, up the cores in use from 4 to 6, and see what happens.
Wow, big difference! 2 more cores (we gave it 4), and putting the SELECT to reduce the intermediate data size.
Time to write raw data to Data Lake: 0:01:23.223409Now that’s more like it. Makes me feel better about the Polars results.

What should we take away?
Here is what I take away from this test. Spark is clearly the gorilla in the room. It can process pretty much anything with ease. But, as someone who’s used it for years … many times we are using a sledge hammer to put in a in trim nail.
Combine Spark with Databricks for an entire Data Platform and costs add up.
Polars is the real deal. If I can, with a little troubleshooting, process 27GB+ of data in 34 seconds on a machine with 16GB’s of memory … well, that should make you pause for a moment. 82 million records in 34 seconds.
My goal was not to do some perfect benchmark, the goal was to test if Polars is able to process “real amounts of data” and “actuallly replace some production Spark workloads.” That answer is yes.
Great write up!
I too hit that wall of sink_parquet not being able to write partitions.
Regardless, polars is very fun to use. Coming from spark and pandas I really like how familiar it feels.
Hi Daniel,
Might be worth to rerun this following this guide:
https://luminousmen.com/post/how-to-speed-up-spark-jobs-on-small-test-datasets
BR
E