


The "Brittleness" Problem in Data Pipelines.
The "Brittleness" Problem in Data Pipelines.
How to identify and solve brittleness problems in Data Engineering.


Brittleness. What an interesting topic. What is it? What’s it like to live in it? How can it be contained and quelled? Data Engineering is hard enough in its own right. The landscape is riddled with potholes and chasms spewing forth putrid bugs and data ready to strike your beautiful pipeline to the ground.
You probably don’t notice the problem of brittleness in Data Pipelines when starting out your career. The more you’ve been up and down the mountain, like a forlorn pilgrim on a long and weary journey, where every Data Pipeline and Data Platform are the same thing, you start to notice such things.
Brittleness. What is it?
Thanks to Delta for sponsoring this newsletter! I personally use Delta Lake on a daily basis, and I believe this technology represents the future of Data Engineering. Check out their website below.

Defining Brittle Data Pipelines and Architectures.
You might think this definition of brittleness is a little nebulous and hard to define. I don’t really think that’s the case. I think you know what you see it, when you experience it. In fact, I think it’s likely that probably 90% of the Data Pipelines running today and that you and I are working on are brittle.
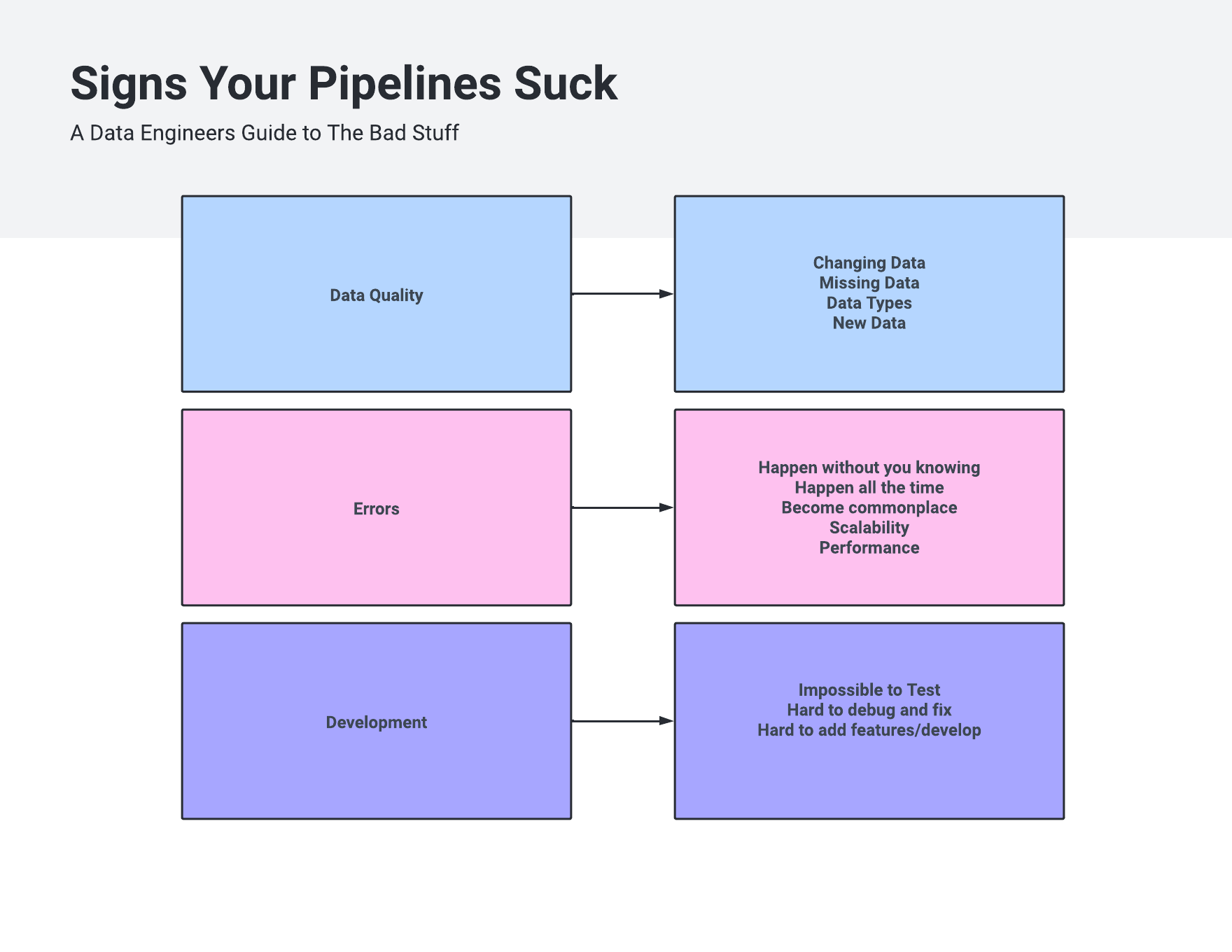
“Brittle data pipelines and architecture are those pipelines that never run consisently because of …
- Data Quality issues.
- Many errors and problems go un-noticed for days or weeks.
- Are hard/impossible/overly burdensom to debug and fix.
- Are slow and un-performant, don’t scale.
- Feature changes and imrovements are hard to make and test.
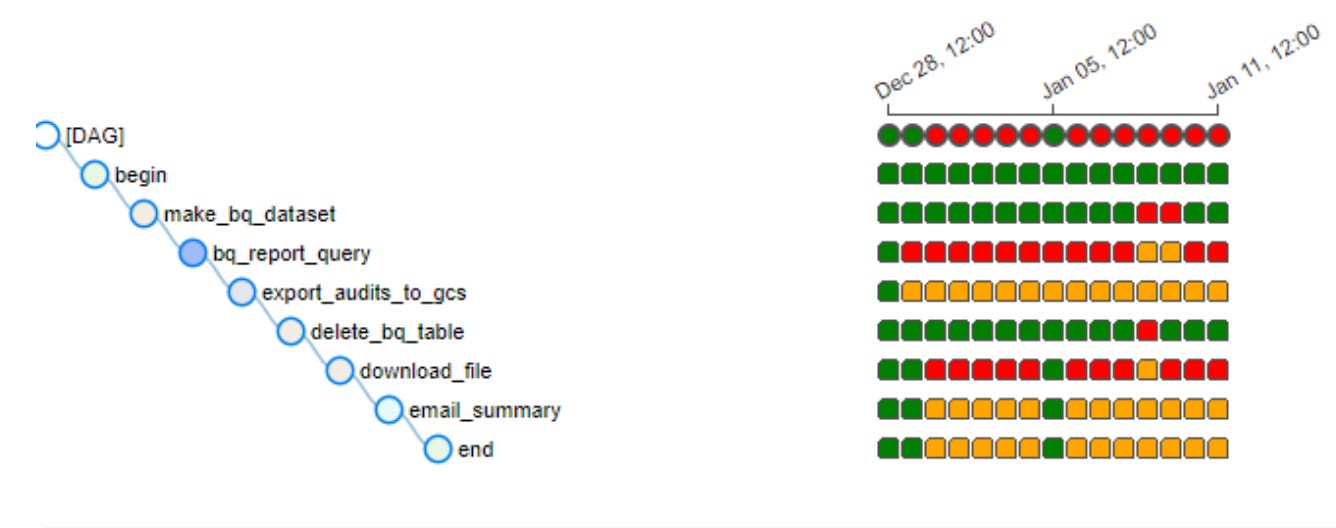
You might have a brittle pipeline if …
You might be thinking, “Why, I deal with these problems every day.” I dare say most of us do. But, should we be? There are sundry and various reasons that Data Platforms and Pipelines end up in this sad state of tattered affairs.
Not least of those reasons being …
Moving too quickly.
Not tackling technical debt on a regular basis.
Not enough project planning and foresight.
Bad engineering culture.
A bad business culture that drives results, without regard to cost.
But again, we could just say that’s life. It’s the life some people live without change, like a story that never ends.
How can a regular old Data Engineer, a little drop in the ocean overcome such obstacles?
Overcoming Brittle Pipelines.

Courage my friend. Courage, foresight, battle-hardened nerves of steel, sweat, blood, and tears. It is possible to change the overwhelming tide of dark foes that try to overpower your pipelines, your work, and your stack on a daily basis.
It’s time to put up some bulwarks, man the battlements. Here are some common and approachable ideas to help you combat these evil brittle pipelines, things that are within reach of the Average Engineer.
Data Quality Issues.
Dang, it’s always the data, isn’t it? It’s hard to get control of the data, and what to expect when knowing when things change. Sure, if you’re working on GBs of data, maybe you can, but in high volume and multiple TB+ systems, the simple task of getting a handle on the data can be hard.
What are some easy approaches to fixing brittle Data Pipelines when it comes to DQ?
Volume monitoring and alerting.
Basic sanity checks of data volume.
Basic sanity checks of important data values.
Using constraints inside data stores.
There are two options when doing such things. You can do it yourself, or you can use some tool like Great Expectations or Soda Core for example. I’ve written about both, see those previous links.
Just remember, even simple checks will probably get you a long way down the path. Think about how much simple checks could change your pipelines.
// counts
assert df.count() >= 1
// nulls
assert df.filter("x IS NULL").count() == 0
// sanity checks
assert df.filter("length(x) < 23").count() == 0
assert x in df.columns()The list goes on. The point I’m trying to make is that taking little steps can help be a stopgap for brittle breakages due to having no control over the data. Or if you’re using something like Soda Core or Great Expectations, you can get fine-grained control over your data.
table_name: tripdata
metrics:
- row_count
tests:
- row_count > 0
columns:
ride_id:
valid_format: string
sql_metrics:
- sql: |
SELECT COUNT(DISTINCT rideable_type) as rideable_types
FROM tripdata
tests:
- rideable_types = 2Let’s move on to some other things that make data pipelines brittle, and how to overcome those issues.
Development Issues.

Probably one of the single greatest indicators of brittle data pipelines is problems with the “Development Lifecycle.” What do I mean by development issues? I mean it’s a nightmare to be a Data Engineering working on those pipelines, you know what I’m talking about.
Inability/absence of running tests on the pipeline.
Extreme difficulty in debugging.
Extreme difficulty in adding new features.
These are all symptoms of a bigger problem. A piece of junk data pipeline(s). These issues usually point to a stinking pile of code that has been hastily thrown together over the years, and become a tangled web of traps and intricacies. Bad architecture on top of bad code, now that is a recipe for a bubbling cauldron of brittleness that eats Data Engineers for lunch.
What are some of the first things I look for to tell if a data pipeline is going to be brittle?
There is no Docker or containerization in the repo.
There are no unit tests.
The code can’t differentiate between “Production” and “Development.”
There is no Development environment.
All the code is 50+ lines per method/function.
Zero documentation or README’s.
No CI/CD exists.
Deployments are hard.
What does it all boil down to? Simply put, there is a complete lack of an attempt at Engineering best practices. Test, containers, CI/CD, clean reusable code, and documentation. It’s all missing, and it all indicates one single sad fact. The pipeline has brittleness oozing out of every pore.
What I’m not saying.
I’m saying that every pipeline has to be a perfect shining and gleaming pile of treasure, as if developed by some savant squirreled away at Netflix or Facebook. What I am saying is that it’s clear which pipelines are cared for and which are not.
You can read the Engineering Culture by its repos.
If all the problems indicated above exist where you work, then it’s most likely you work with people who want the world when it comes to data, but refuse to recognize the fact that good things do take some time and effort.
It doesn’t take much to change direction for the better.
Create a Dockerfile for your repo.
Write a few unit tests.
Write some README’s.
Make a development environment.
Run `ruff` and/or `black` on your code.
Clean up the code, and break it down into small functions.
Nothing listed above is earth-shattering or above your abilities. They will set up a data team and pipeline on the road to redemption. You will fall in love with good practices, and you will reap the benefits of your hard work.
Resources.
Here are some resources to help you on your journey to brittle-free Data Pipelines.
Great read and perfectly said!