

The Truth about Prefect, Mage, and Airflow.
The Battle for the Orchestration Future.


Well, even though this is going to be the truth about Prefect, Mage, and Airflow, I do wonder, in 2023, if there is any truth left to be had. The data world is changing, and the pace at which the new tools are being released is mind-numbing. Every week it’s a new library like Polars, or the next hot SQL thing like duckDB. It can be hard to sort out fact from fiction, and marketing goup from the real deal.
What about arguably one of the most important parts of a data stack? The orchestration and dependency tooling?
Airflow has long reigned supreme in the Data Orchestration space for what seems like an eternity. With AWS adopting it as MWAA and GCP as Composer, it seemed like the flag had been planted firmly on top of the hill. The Airflow’ens are entrenched and blasting their weapons down upon anyone or thing that dares to climb that same hill in search of glory.
Thanks to Delta for sponsoring this newsletter! I personally use Delta Lake on a daily basis, and I believe this technology represents the future of Data Engineering. Check out their website below.

But, if one thing is sure, it’s that as soon as something takes the crown of glory and sets it upon its head, somewhere behind the throne the swords and plots are being sharpened. If Rome fell, does Airflow have a chance?
The new Age of Orchestration is here.

In today's fast-paced business world, data has become one of the most valuable assets. With the ever-increasing volume and complexity of data, it has become essential to have efficient data orchestration tools that can manage data workflows. Three popular data orchestration tools are Prefect, Mage, and Airflow. In this article, we will compare these three tools at a high level, explore the concepts, and help you choose the right one for your data stack.
Honestly, I don’t care how shiny the UIs are, I’m sure both Prefect and Mage have better ones than Airflow. That’s ok. We should probably have other reasons for picking a tool than it’s like a shiny quarter you found on the ground.
“What is the true difference between Airflow, Prefect, and Mage? Is it how they approach data flows? Is the integrations? What exactly is it that makes them different, and does it matter?
That’s what I want to start to answer today. I don’t care about performance, what I want to get at is how these tools are designed, how they are used, and how they affect Data Engineers in the way they write and manage data pipelines.
What’s the difference between Airflow, Prefect, and Mage?
How do these tools approach data pipelines and orchestration?
How do these tools affect the way Data Engineers solve problems?
So, whether they like it or not, I’m going to lump all these tools into the “data orchestration and pipeline management” group. I don’t care what the marketing hype is, that is what they are used for. Also, I’m not an expert, I’m just an average engineer trying to do average things.
First, let’s review what I would call the “core concepts” of each tool. Then explore along the way, which tool is the best.
Prefect

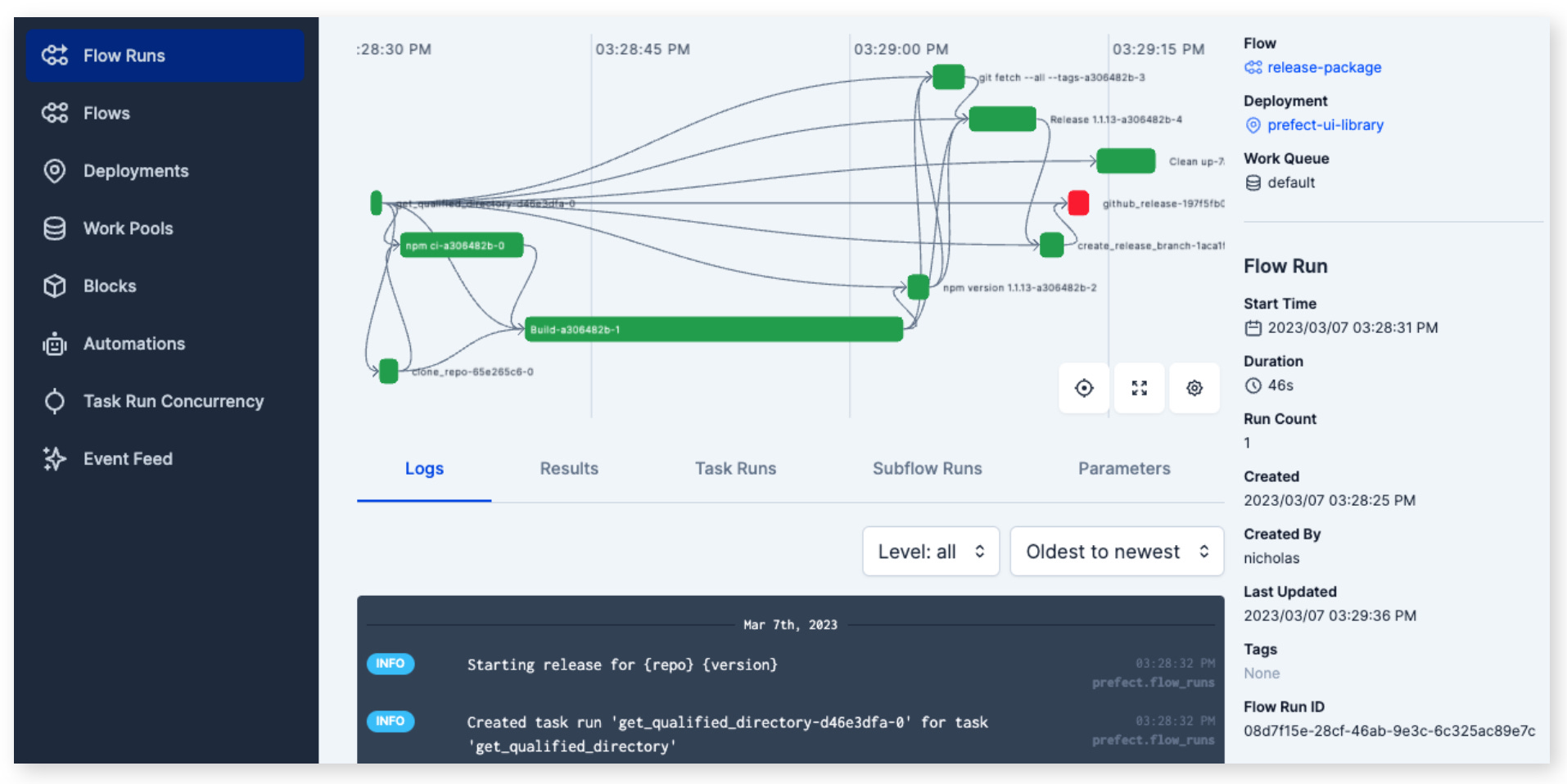
Prefect's core concepts revolve around building, managing, and monitoring data workflows. These concepts are fundamental to understanding and working with Prefect effectively.
Prefect core concepts:
Many moons ago when Prefect was new I did a review and comparison to Airflow. Check that out here. If you go to the Prefect website and start reading … nothing big jumps out. It talks about “Building”, “Running”, and “Monitoring” workflows. There is actually a quote from the Prefect website that sums up Prefect very well and is basically the conclusion I came to.
“Prefect enables you to build and observe resilient data workflows so that you can understand, react to, and recover from unexpected changes. It's the easiest way to transform any Python function into a unit of work that can be observed and orchestrated. Just bring your Python code, sprinkle in a few decorators, and go!”
What I found telling about this quote is that I have not found anything fundamentally different about Prefect, say than Airflow. There isn’t anything earth-shattering or special. It’s simply just trying to be Airflow, except slightly better.
It didn’t excite me. I need a good reason to abandon Airflow’s massive community.
Let’s talk about the core concepts of Prefect. How do they approach Data Engineering problems?
Tasks: Tasks are the basic building blocks of Prefect. They represent individual units of work or operations, such as fetching data from an API, transforming data, or training a machine learning model. Tasks can be created using the
Taskclass, and custom tasks can be defined by subclassing them.Flows: Flows are collections of tasks that have a defined order of execution. They represent a complete data workflow or pipeline. In Prefect, you create flows by linking tasks together and defining their dependencies and execution order. Flows are constructed using the
Flowclass.State: State represents the status of a task or flows at a particular point in time. Prefect uses state to track the progress of tasks and flows during execution. Common states include Pending, Running, Success, Failed, and many others. State objects are instances of the
Stateclass or its subclasses.Results: Results represent the data returned by a flow or a task defined above.
Task Runners: Task runners facilitate the use of specific executors for Prefect tasks, allowing tasks to be executed concurrently, in parallel, or distributed across multiple resources. Task runners are not mandatory for task execution. When you invoke a task function directly, it operates as a standard Python function, without utilizing a task runner.
Of course, Prefect offers a hosted cloud version of their tool. Remember what Prefect said about writing Python and then putting a decorator on top? This is in essence … Prefect. Look at this simple example.

What can we surmise about Prefect based on what we’ve seen? It’s a fancy and nice GUI, focused on making native Python the tool used to write data pipelines. But what about if you want to run Databricks or Snowflake stuff? It can do that of course. For example …
from prefect.tasks.databricks.databricks_submitjob import (
DatabricksRunNow,
DatabricksSubmitRun,
)
Remind you of anything? It should, it’s pretty much a spitting image of Airflow. There is a big list of “Integrations” on their website, although it is not as large as I would have thought, and some seem pointless … like Twitter.

How does Prefect differentiate itself from Airflow?
You might be asking yourself, like me, why would someone choose to use Prefect over Airflow with its vast community, I mean you sorta need a compelling reason to break from the mold.
I combed the website back and forth and the docs. Just a lot of talk about building high-performance data pipelines, but there isn’t actually anything “solid” behind those words. I can’t point to x or y feature, or design concept and say “This is what makes Prefect different or better than Airflow.”
Prefect does offer some interesting features like Projects and Deployments, a better way to organize, deploy, and run your pipelines. Is it enough?
I’m not sure. I personally fail to see how Prefect blows away Airflow in any category. Of course, the UI is better and has more features, although the more complex something becomes, the less easy it is to use and the learning curve steepens. Maybe it’s better running at scale? Again, it just isn’t enough for me to want to invest time or resources into it. Maybe that’s just me.
I feel like it’s reliance on simply using native Python for defining tasks and workflows, along with decorators actually hurts it. It tightly couples data pipeline orchestration to the actual code you are writing to transform data sets. Anymore, data is too large to be processed on an Airflow “worker” or on Prefect for that matter, the world is moving towards connectors for tools like Snowflake, Databricks, and the rest. We don’t actually need or want our orchestration tools to DO the data processing.
I feel this is the only, and main difference between Prefect and Airflow. Prefect does away with the DAG abstraction and uses Python and decorators to do your work.
Think I’m being too harsh on Prefect? Maybe, but as an Airflow user, I don’t see any compelling reason I would switch to Prefect. It doesn’t have any earth-shattering features or breakthroughs that would make me want to switch to it. If I was starting clean would I pick it? Probably not. I want something that has a large community behind it.
Any Data Engineer knows a tool works well for a while, but when it doesn’t, you need somewhere to turn. Do you have some experience with Prefect? Do you love it? Drop a comment and let us all know.
We disappointment in my heart, onto the next tool.
Mage

Mage is a data orchestration tool designed for modern data infrastructure. It provides a simple interface for building complex workflows, it’s also highly scalable and resilient. Mage's interface is intuitive, and it allows you to build and monitor your workflows easily. That’s what the marketing says anyways.
“Open-source data pipeline tool for transforming and integrating data. The modern replacement for Airflow.” - mage.ai
Well, I do like honesty. At least they are being upfront about what they are trying to do, replace Airflow. Before you tell me I’m an Airflow lover and will never find anything to replace it, hold your horses. Airflow does drive me crazy sometimes, its backend architecture leaves a lot to be desired, can be clunky, and frequently pukes to the point it’s easier to spin up a new environment, rather than fix it.
I digress. Back to Mage.
Mage has several unique features that make it stand out from other data orchestration tools. For example, it has a built-in data catalog that allows you to track your data lineage, and it has a powerful retry mechanism that can automatically retry failed tasks. Also, it offers a Notebook UI to develop with, offering quick iteration and feedback. Very nice!!
Now, these are features that are substantially different from what we are used to with Airflow. It’s a different approach, and that’s what matters.

How does Mage approach data pipelines?
Mage Core Concepts.
Project and Pipeline: Project like you would think of a GitHub repo, Pipeline contains all the code blocks you want to run, represented by a YAML file.
Block: A set of code in a file that can be executed at will. Blocks can have dependencies. The types of Blocks that you would recognize …
Transformer
Data Loader
Data Exporter
Sensor
Chart
Engineering Best Practices is a core feature.
Bock reusability.
Automatic Testing of Blocks.
Data Validation is pre-built into Blocks.
Data is core, Blocks produce Data.
Pipeline and Data Versioning, along with Backfilling.
Scalable via Spark.
Develop via Notebook UI.
What does Mage code look like?
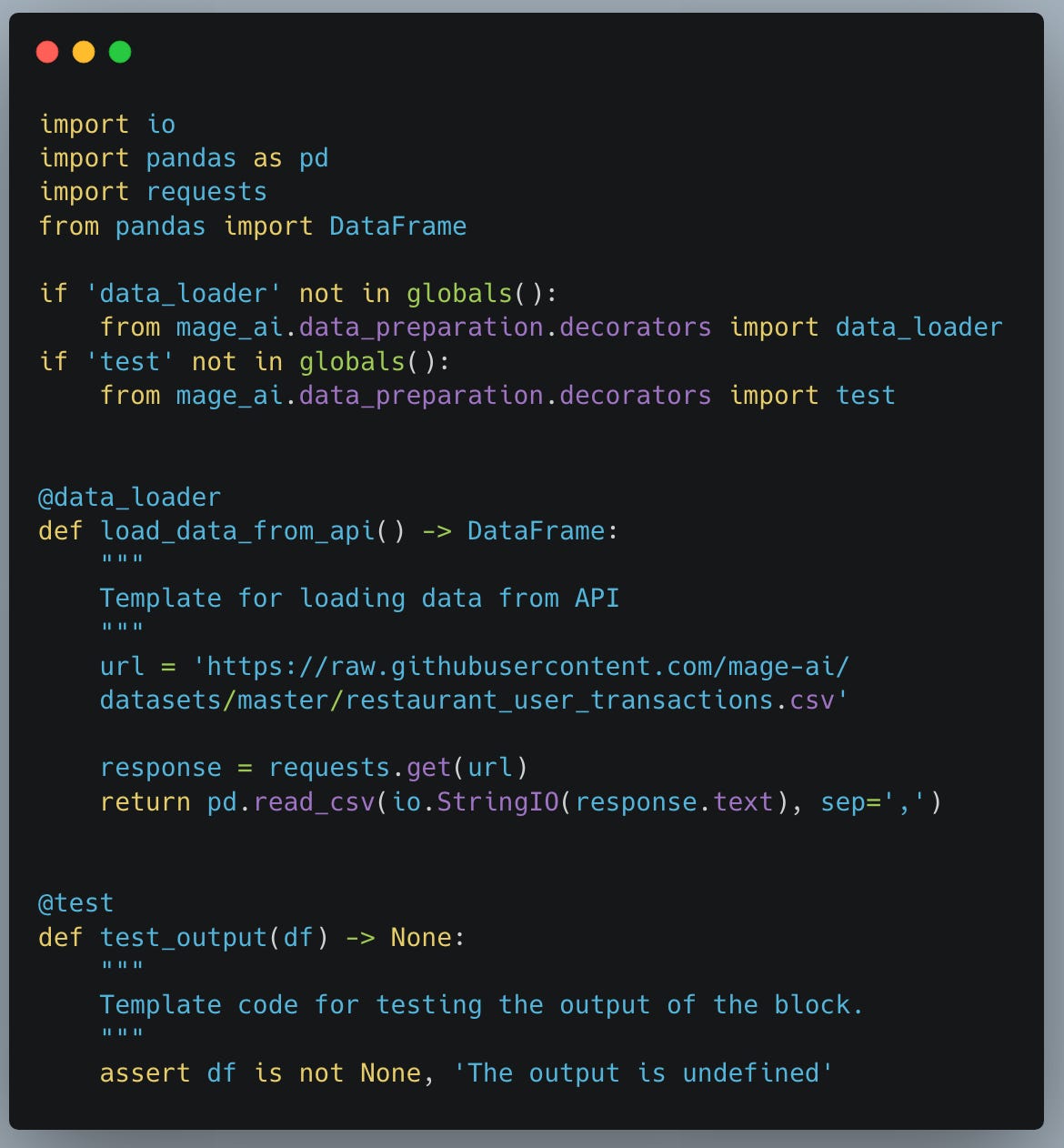
What sets Mage apart and makes it different?
One thing is immediately apparent that sets Mage apart from both Airflow and Prefect. While it appears similar to Prefect in the way it uses simple Python and decorators to define the bulk of processing, the approach to Engineering best practices is where it shines and is completely different from the other two.
Instead of Mage just being another ETL and Orchestration tool with a slightly different take from Airflow (Prefect), Mage tries to fundamentally change the way data pipelines are developed and used, focusing on the developer and Engineering aspects to set itself apart.
What are some things that jump out at me about Mage, without diving into too much detail?
Easy to use Docker setup, going to make life easy when developing.
“Each step in your pipeline is a standalone file containing modular code that’s reusable and testable with data validations.” ← this is a big deal.
“Immediately see results from your code’s output with an interactive notebook UI.” ← This is a big deal.
“Deploy Mage to AWS, GCP, or Azure with only 2 commands using maintained Terraform templates.” ← this is a big deal.
Honestly, if Mage was just another nice UI, with a different take on developing pipelines than Airflow … I would be skeptical. But it appears they took a fundamentally different approach, providing probably not only a better UI, logging, and monitoring … but actually focusing on the Developer experience and pushing Engineering Best Practices in a way that provides clear value that Airflow and Prefect do not.
Apache Airflow.
I’m not going to devote time to this tool. There are reams and volumes of video and text content produced on the topic. You can google it. Airflow is boring and popular.
Comparison
Before you accuse me of nepotism I don’t have any skin in the game of Airflow, Prefect, or Mage. I’ve never used Prefect or Mage in anything but a play-around experience. I’ve used Airflow in a standalone deployment, via Composer, and via MWAA.
As I’ve scaled up with Airflow, even with MWAA, I’ve started to see the crack in the Airflow armour that may not be obvious to everyone. Also, the development experience, the way code is written and deployed, with Airflow doesn’t condon best practices and leaves a lot to be desired.
As I’ve grown and added years to my Data Engineering career I’ve found that certain tools are …
Scalable.
Push you towards best practices.
Reliable.
Don’t require vast amounts of management and a deep understanding of the system architecture simply to use them at scale.
As someone who loves and has used Airflow for years, it isn’t any of those things. It works. It’s enough. It does the job tolerably well. Hence people use it.
When you have fans of all tools, how can you get past the arguments about which features are better, what’s faster, which one does this better, or that better? It can be hard to compare tools and boil down the essence of the matter.
Sure, we could install each tool, build a pipeline, and run it. But, what would that really tell us? We know that each tool, Airflow, Prefect, and Mage are capable of building and running pipelines for probably the majority of situations and circumstances.
What we have to ask ourselves is more of a big picture question, “which tool at a high level is doing something new and better, is approaching the problem of Data Engineering and orchestration and management of pipelines in a new and unique way that would provide REAL benefit, other than just a shiny new tool?“
The answer is clearly Mage.ai. No, I have not been paid to say that, and I’m saying that as someone who’s been an active Airflow user for years, via both self-hosted, GCP Composer, and MWAA on AWS.
I’ve nothing against Prefect, other than that it just isn’t providing enough differentiation from Airflow. Maybe it’s just their bad marketing, who knows? I could be missing something amazing.
Airflow is here to stay for a long time, but cracks start showing at scale.
I will always love Airflow, it’s a unique tool that does a decent job with an amazing community, and it’s simple to learn and use. But, anyone who has used Airflow at scale and doesn’t have a dedicated team to support it (why should you need one?), knows that you can easily shoot yourself in the foot, and what was once easy to use becomes a bear to manage and massage at scale to keep it performant.
It’s also inevitable that newcomers show up and start to pick and scratch at the corners of Airflow, putting best practices in place and solving pain points for next-level Airflow users.
UI is clunky, even the latest versions.
At scale, Airflow takes serious management and understanding to keep performant.
Good development experience is non-existent.
Sure, there is plenty of use cases for Airflow at a small scale where it works like charm. Should those organizations migrate away? Probably wouldn’t hurt them too, but it most likely doesn’t make a ton of sense.
How do you know you should switch from Airflow to either Mage (probably), or Prefect?
I’m going to ask you a few questions about your Data Engineering culture and use cases.
Is your Airflow setup starting to run over 50+ DAGs and growing?
Are your DAGs and pipelines wandering from simple to complex?
Is your Data Engineering culture embracing best practices?
Unit tested code.
Automated deployments (CI/CD).
Data Quality is important.
Do you aim for a seamless code experience?
If the above items are where you want to go, and you care about excellence in Engineering Culture, then I would suggest checking out a tool like Mage.ai over Airflow if you get the choice.
At the end of the day when running a bunch of pipelines at scale would most likely thank yourself. Why? Because your codebase will probably be clear, more reliable, and follow best practices better. Your deployments will probably be better, your Data Quality will be, and testing will be.
The Development of your Engineers working on the codebase to maintain and write new pipelines will be a much smoother and more efficient process. If I got to pick between the three for a new project, which one would I pick? Mage.
Have a different opinion? Share.
As always, your content is 🔥 🔥 🔥 . Thanks so much for sharing this 🙏 🙏 🙏
Dagster didn’t get a look in? Any reason why?