



They said Streaming would overtake Batch.
The battle for the data pipeline.


In recent years, the prophetic stance in the data engineering landscape has been that streaming would eat batch ETL (Extract, Transform, Load) processes, fundamentally rearchitecting the way we handle big data.
The peddlers of new and shiny tools have been not shy in saying that batch ETL is dead, and you are a proverbial mammoth wandering around waiting for your doom if you’re not using streaming.
As we find ourselves here towards the end of 2023, it’s high time to examine whether the proclamations have held true and to what extent the transition has impacted data operations.
Were the peddlers of ETL Doom correct in the destruction of everything we hold dear?
Thanks to Delta for sponsoring this newsletter! I personally use Delta Lake on a daily basis, and I believe this technology represents the future of Data Engineering. Check out their website below.

Streaming vs. Batch ETL: A Refresher
I know you are all very smart and wonderful Data Engineers, pumping through all day long. But, to set the stage for our discussion, let's revisit the basics of streaming and batch processing:
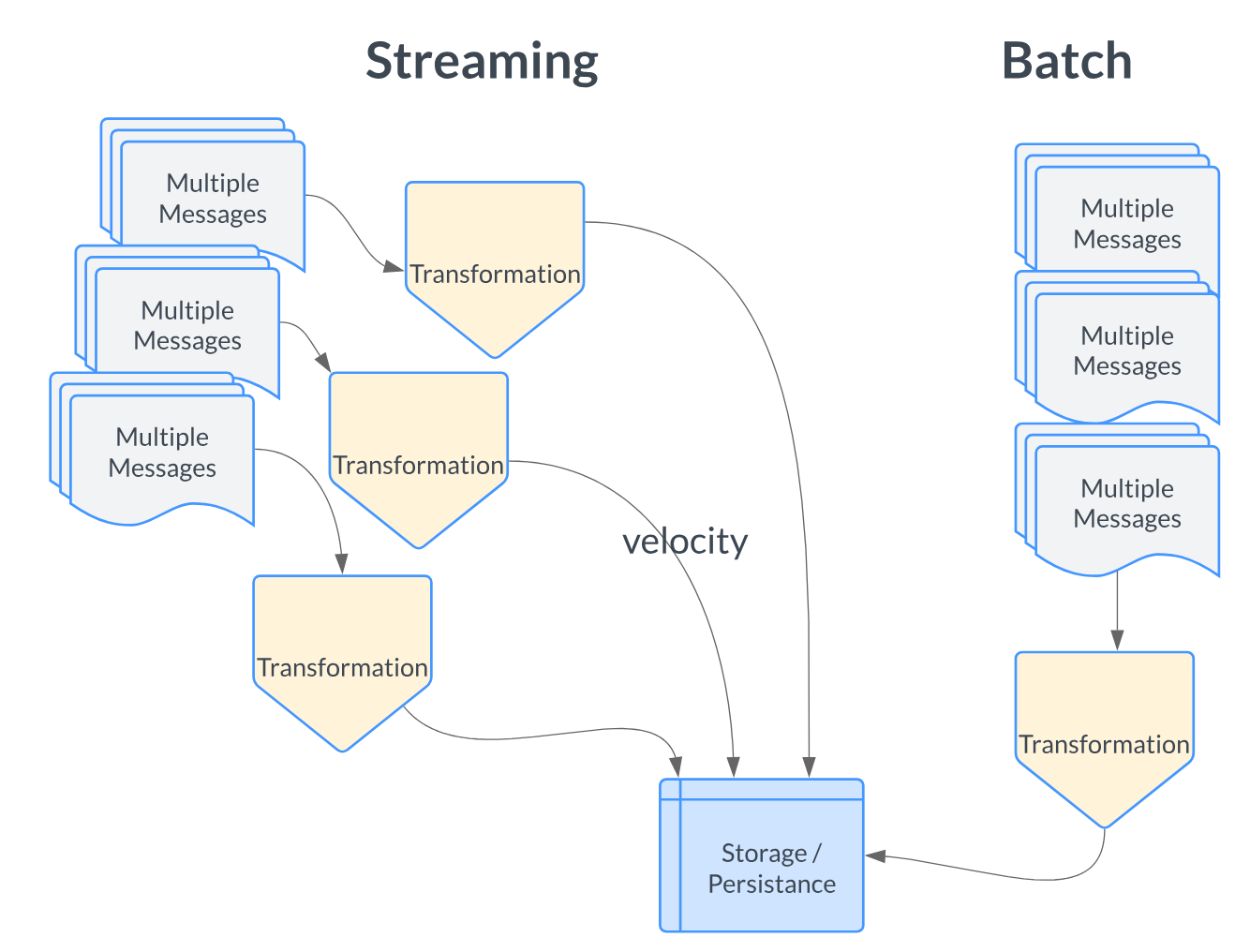
Batch ETL
Historically, data pipelines have relied on batch ETL processes, which involve collecting data in batches and processing it at scheduled intervals. This makes up the vast majority of Data Engineering work done today, probably above the 80% mark.
Batch ETL is what I would call “sequential” in nature. We pile up some work, then do the work, rinse and repeat.
It is less timely, in terms of delivery, but reduces the cognitive burden and development lifecycle in most cases. It’s considered “easier,” although batch can be extremely complex depending on the context.
Streaming
Streaming, on the other hand, promises real-time data processing, handling data virtually as soon as it is generated. It’s about velocity when it comes to streaming. Fast, complex, fancy, and immediate results. It’s seen as the North Star of Data Engineering, like Zeus on Mt. Olympus, such are those Data Engineers who are streaming savants.
In general, you deal in “messages” when it comes to streaming, although some micro-batch systems like SparkStreaming can ride in both worlds. Streaming is continuous in nature, batch is not.
Examining the Progress (Adoption Rate)
Streaming technology adoption has surged over the past years, propelled by the unprecedented growth in real-time analytics demands and IoT applications. Innovations in stream processing frameworks, like Apache Flink and Kafka Streams, have facilitated a smoother transition from batch to streaming architectures.
Tooling and Infrastructure
Over the years, the tooling ecosystem has evolved substantially to support streaming processes. The barrier to entry has been lowered, thanks to the advent of managed services and the consolidation of technologies that offer both batch and stream processing capabilities, simplifying the implementation of Lambda and Kappa architectures.
The Blurred Lines between Streaming and Batch
Why has streaming become easier? Because the lines are now more blurry as far as development around Batch vs ETL in some advanced systems. Take Delta Live Tables for example.

“Delta Lake is deeply integrated with Spark Structured Streaming through
readStreamandwriteStream. Delta Lake overcomes many of the limitations typically associated with streaming systems and files, including:
Maintaining “exactly-once” processing with more than one stream (or concurrent batch jobs)
Efficiently discovering which files are new when using files as the source for a stream”
Essentially what SaaS vendors like Databricks have done is made the use and development of Streaming like capability much easier with less conginative and technical burden!
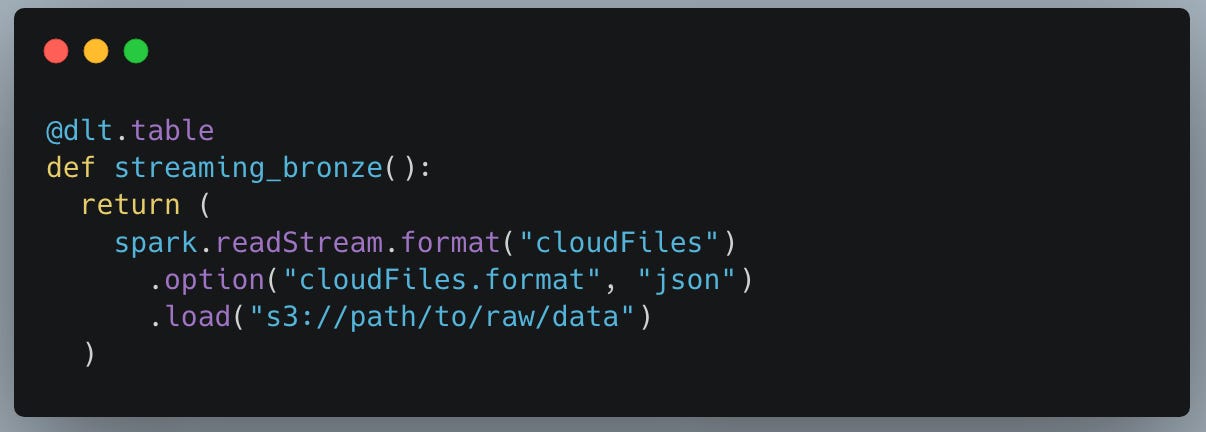
This is a far cry from setting up you’re own Kafka architecture on some Kubernetes cluster, messing with partitions, being a general genius, managing everything, and developing in that sort of environment.
In fact, it’s become such “a thing” to simplify streaming for Data Engineers, companies like Estuary are popping up.

Tools like this take it a step past Databricks Delta Live tables and allow you to setup streaming pipelines in a simple UI. We’ve come a long ways from SSIS haven’t we?
This type of work is a far cry from messing Producers and Consumers in a Python client for Kafka, not including the architecture work.
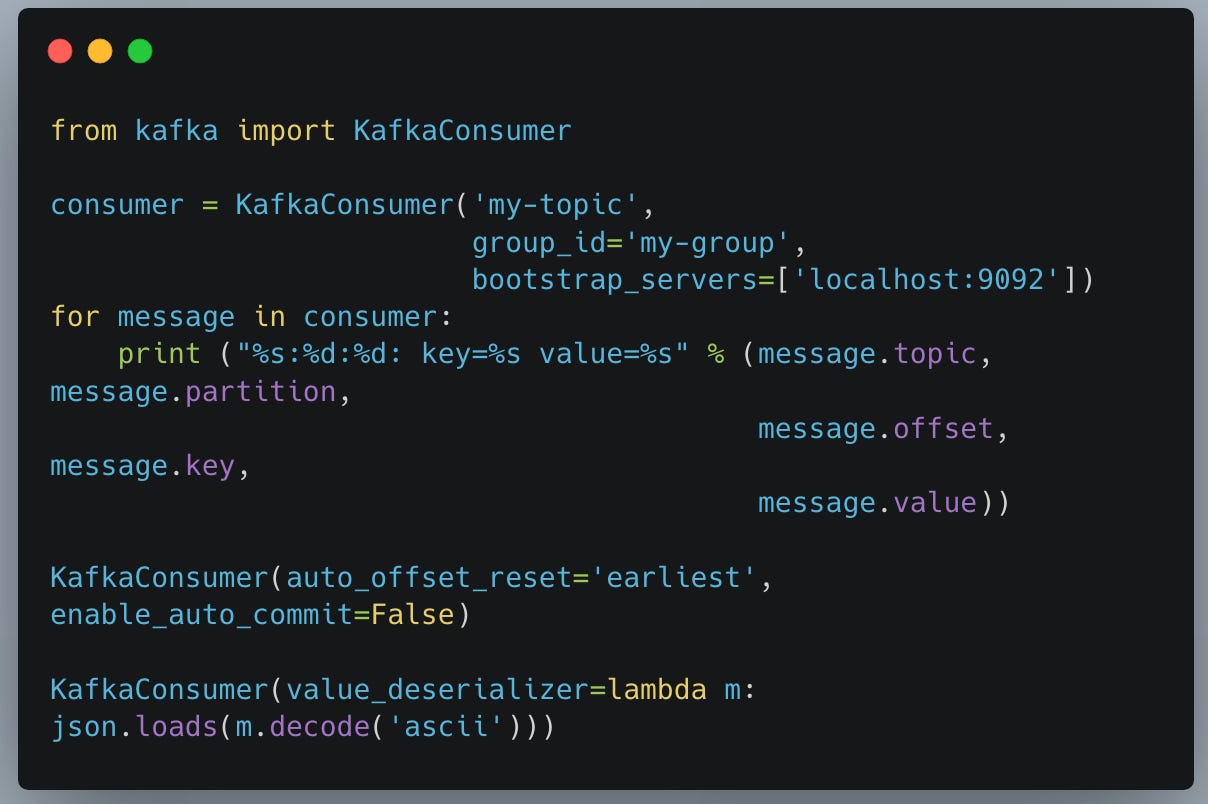
Challenges and Roadblocks
Despite its promising trajectory, the complete takeover of streaming is still hindered by a series of challenges including:
Complexity:
Streaming processes are inherently more complex to design, implement, and manage compared to batch processes.
Resource Intensity:
Streaming applications tend to be more resource-intensive, requiring robust infrastructural support.
Cost:
The transition to streaming architectures can be cost-prohibitive, especially for smaller organizations.
Hiring and Talent:
Honestly, it isn’t easy to hire Data Engineers with streaming experience. It just isn’t as common, it’s harder to hire for.
The reality of Batch ETL.
The reality of Streaming vs Batching in Data Engineerings is that most companies are working on small data that doesn’t not require real-time streaming systems.
It’s the classic 80/20 rule. Most Data Engineers in most companies don’t use streaming. Has that split grown over the last decade to include more streaming? Of course. Is the overwhelming vast majority of ETL still done in batch? Of course.
Future Directions
As we peer into the future, it is clear that batch processes won’t be rendered obsolete anytime soon. Instead, we anticipate a more harmonized approach where organizations leverage both batch and streaming processing to meet diverse data workload requirements.
A promising trajectory is the growing interest in serverless data architectures which might change how we approach data processing, potentially altering the batch vs. streaming debate fundamentally.
Conclusion
Though streaming has not completely overtaken batch ETL, it has carved out a significant and growing niche in the data engineering landscape. The integration of streaming processes in data pipelines has indeed proven beneficial in harnessing real-time insights and fostering a data-driven decision-making culture.
However, batch ETL continues to hold ground, offering a reliable, cost-effective solution for a range of data processing needs. As we navigate the evolving data engineering landscape, it remains imperative to choose the right tool for the job, be it batch, streaming, or a harmonious blend of both.
Long live Batch ETL!
Thanks for the article, Daniel! I find event-driven pipelines are to some degree the sweet spot. They are timely, simple (just a python lambda for example, no need for spark), easy to monitor and trace, often represent the actual data generation process, and even extended their realm with delta tables/iceberg/hudi. What's your take on them?