

Using SQL with Python. The Ultimate Chad Stack.
like it or not ...


You know, you can hate ‘em all you want. I have even done that on a few occasions (SQL and Python) when overtaken by the heat and passion of the moment. But, maybe I will soften in my old age.
Me’thinks it might just be pure SQL only … or pure Python only which is the problem. When someone is married to a single solution and not willing to budge or move.
It’s typically what I see on different Data Platforms, an unfettered love for SQL … or Python … and never shall the twain meet. That love for one or the other is usually baked like some hot and smoldering roadkill into the road and culture of a place. It’s hard to dislodge.
I say what better way to solve problems than to combine them both? SQL + Python. Probably the ultimate Chadstack.
You should check out Prefect, the sponsor of the newsletter this week! Prefect is a workflow orchestration tool that gives you observability across all of your data pipelines. Deploy your Python code in minutes with Prefect Cloud.

Sure, all those Rust and Golang zealots foam and froth at the mouth with those nasty uncompiled and not statically typed Python mongrels running the streets. But, you can’t argue with the results. Python runs that data world, and always will.
SQL + Python
I give Data Engineers a hard time when all they can write is SQL. Eventually, they stumble, bumble, and fall down. You simply cannot be a one-trick pony and be effective in the long run.
Same goes for Python only engineers … I suppose the same goes for any language. I’ve meant my fair share of (Senior) Software Engineers that could code LeetCode around your head until you passout.
But, throw a database into the mix, a little more than a simple SELECT required … and they cast themselves onto the ground, writhing and wriggling in pain, blaming the DBA and AWS RDS for being complete idots.
The moral of the story is simple … SQL + Python … or Python + SQL is the Ultimate Chadstack.
Both dead simple to learn, and master … nay to be expert in … such a person can churn and burn some Data Engineering tasks.

Taking a gander through time.
I think to understand the SQL + Python or Python + SQL space we should take a trip back through time when I was just a young gun, wet behind the ears, hacking code and taking names.
Back in those early days when people were still hitting rocks together and rubbing sticks to make fire, we had to use something called psycopg2 (if working with Postgres), or maybe mysql-connector-python if you were a sucker on a poor MySQL.
This was how you combined Python and SQL, it was pretty much the only (popular way).

This was long before the days of Polars, the popularity of PySpark, Databricks, Snowflake, and the all-consuming SparkSQL that blurred the line between code and SQL … (am I saying SQL is not code???).
Back when when had to code both ways up hill to get to school, you had to know these terms very well if you were a “Data Engineer.”
connection
error catching and handling
cursors
execute
I mean, something like the following was a daily occurrence believe it or not.

Like I said, both ways uphill, in the rain and snow. I mean, did you ever have to push multitudes of CSV file records in Postgres back in the day without COPY INTO?? That’s what I thought you milk toast key scratcher.
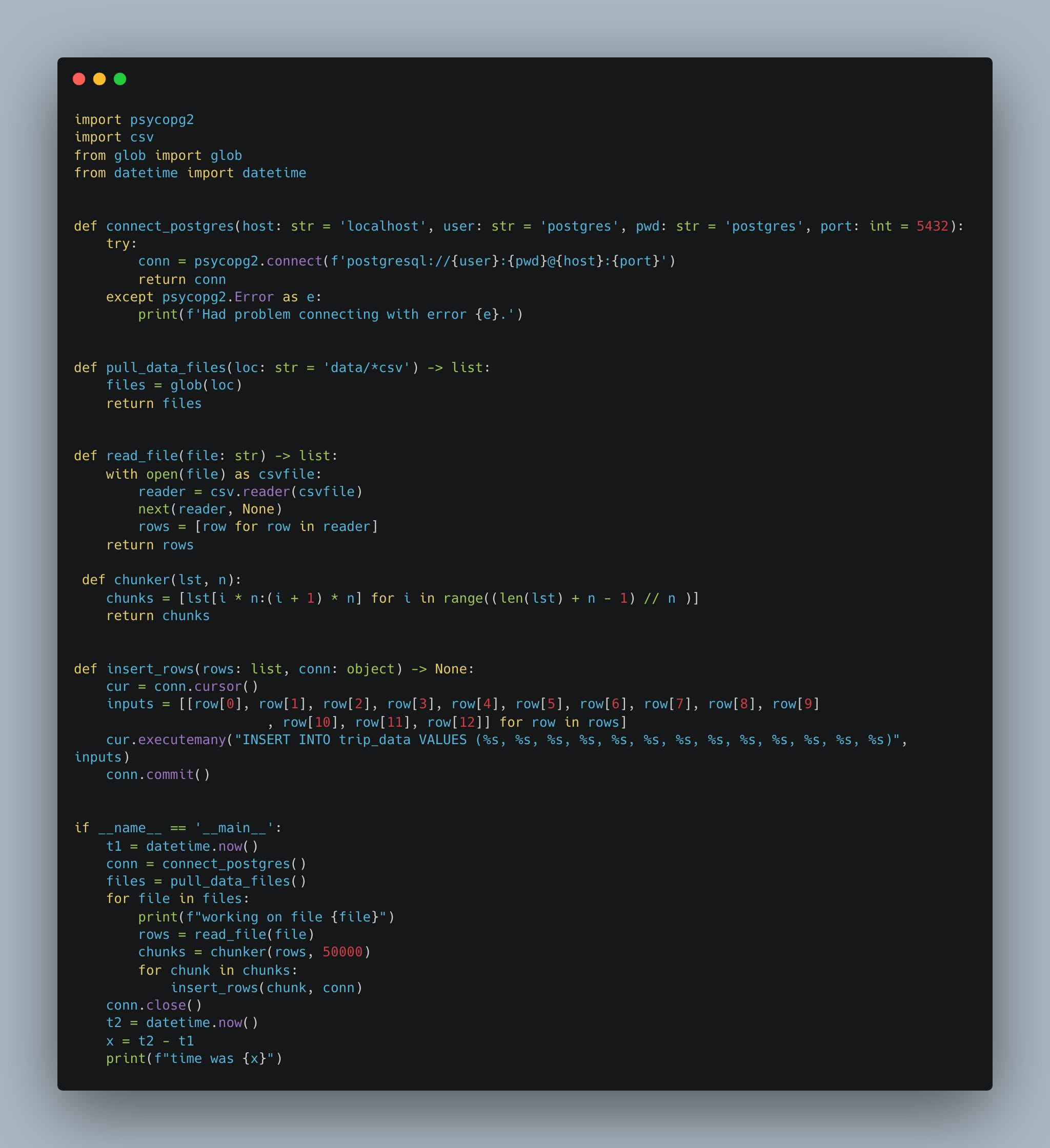
Enough of that junk, let’s talk about today.
Python + SQL in these here fancy days.
What I find amazing, and most others take for granted because it’s all they know … is the way the lines have been blurred between using Python and SQL … at the same time.
Back in the good old days, it was a pain to pull records out of a database with Python … using some embedded SQL … and then get them records into a usable state because you need the power of Python to send something to an API or write to a file, or whatever.
I would say in general the interoperability between SQL and Python was just not good many years ago. You could sometimes use tools like Pandas to do a little this and a little that, but of course, it couldn’t handle anything at scale.
Today, things are different.
Tools like PySpark, Polars, Datafusion, and Apache Arrow have blurred those once-distinct lines.
The ability to switch between Python-centric Dataframes and pure SQL with a SQL-Context has never been easier. Honestly, 10 years ago me would have died in a swoon of happiness if you showed me this code from today.
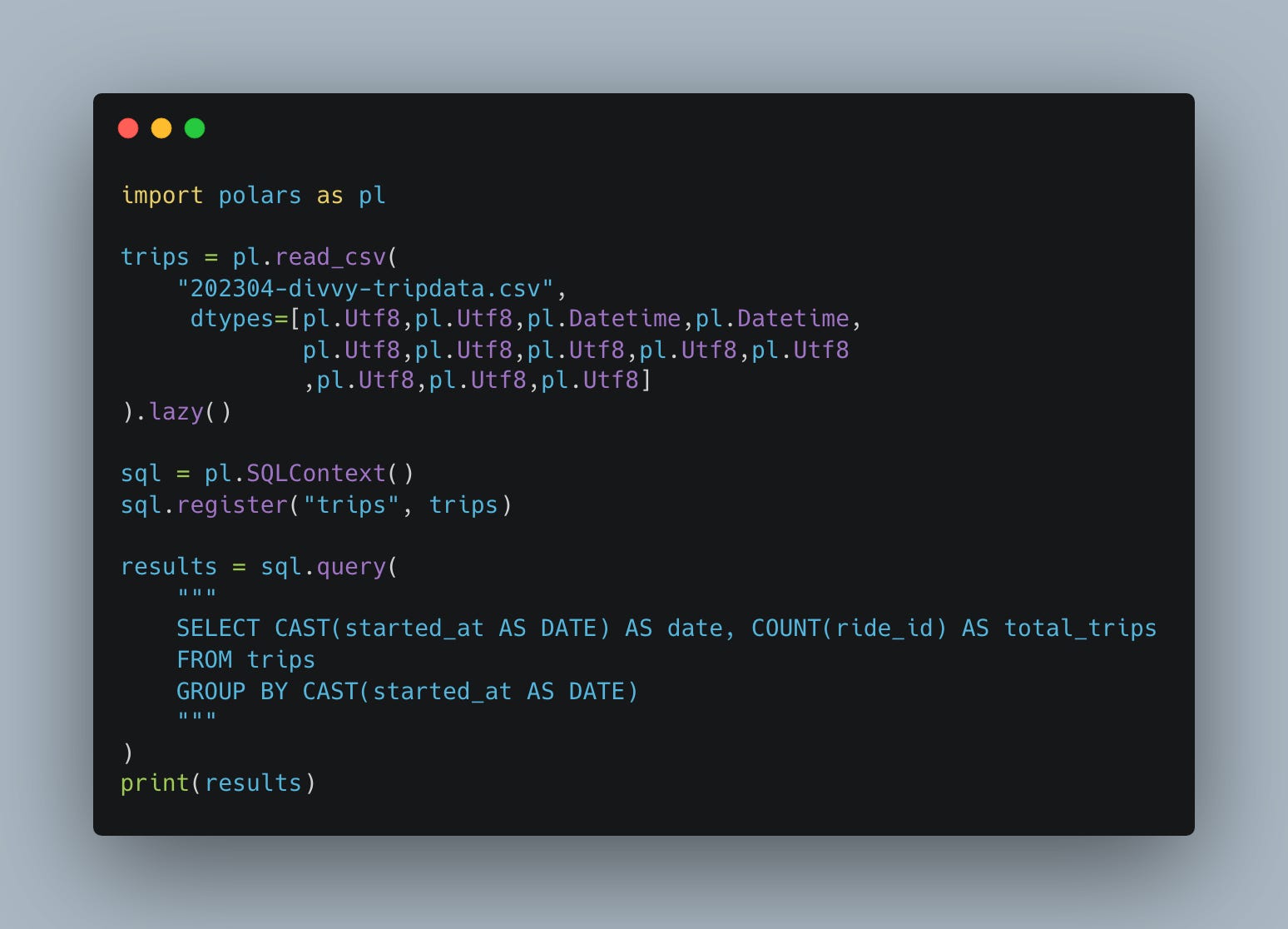
I mean, if this is all you are used to, then I guess you just take it for granted, but this sorta stuff is making Data Engineering easier … it’s the obvious things that these new tools like Polars are doing that are game changers … they change how we solve problems and write code … I call that a big deal.

Having the option to switch over to SQL to accomplish a task that just feels better in SQL is a wonderful thing.
I think that more data engineers need to take this approach of mixing and matching. Who says you have to use Python for the entire data pipeline? Who says you have to use all SQL for every transformation??
This type of single-mindedness is what causes bad things to happen, bad pipelines to be built, and problems to be perpetuated down the line ad infinitum.
Being willing to use the best tool for a particular job or data transformation is powerful, be it Python, SQL, or most likely BOTH.
Perfect. Thanks for sharing. I had started by learning Python and I tried to use Pandas with their weird ways of aggregating. Recently, i’m using a MySQL like lib. Now, I’m gonna start to use Polars