



What?! An Iceberg Catalog that works?
who would have thought ...


I will be the first to admit, in an unapologetic way, that working with Apache Iceberg is far from a pleasant experience once you move past the “playing around on my laptop” stage. The tight, inflexible relationship between Iceberg and a catalog, combined with the lack of easy-to-use catalogs, created a pile of junk.
The only beam of light in the dark tunnel of despair that is Apache Iceberg in production has been Cloudflare’s wonderful but completely ignored R2 Data Catalog … that is, until now.
May the data gods bless Julien Hurault and the new boring Apache Iceberg catalog he has made, apparently something the behemoths of Iceberg were unable to do … like AWS, etc.
Enter the boring-catalog.

“A lightweight, file-based Iceberg catalog implementation using a single JSON file (e.g., on S3, local disk, or any fsspec-compatible storage).”
- boring GitHub
I’m sure some of you unbelievers and whiners who’ve never actually tried Apache Iceberg in a cloud-like production environment will say in a very simpering voice … “But we’ve had SQLite catalogs for Iceberg forever … it has a REST catalog blah blah blah.”
Clearly, if that’s what you think, you can’t be argued with because you’ve never actually written any code to use Apache Iceberg (totally open-source) in a cloud-like environment.
Apache Iceberg’s catalogs are in desperate need of …
Easy-to-use implementations
Implementations that don’t need Google-scale and a server to run
Work in the cloud
Thanks to Delta for sponsoring this newsletter! I personally use Delta Lake on a daily basis, and I believe this technology represents the future of Data Engineering. Content like this would not be possible without their support. Check out their website below.

Essentially, what is needed as a first step is a viable catalog that works in the Cloud without a major setup routine, which can support the 80% use case for small to medium-sized data teams.
*Most* people aren’t crunching Petabyte data with thousands of workers … they don’t need a high-performance Apache Iceberg catalog on a set of servers ready to handle anything.
They need a simple, easy-to-use catalog that just works.
Kicking the tires on boring-catalog.
I hope that this will be straightforward, a very boring (pun intended) code and example walk-through of using boring-catalog in a Cloud environment to read AND write to Apache Iceberg using a variety of tools.
If it doesn’t work as intended, we can still be pleased that people are acknowledging the fact that Iceberg has some significant catalog hurdles to overcome if it hopes to reach Delta Lake-level parity and usage.
Here are some notes from GitHub about boring-catalog that might help frame what’s about to happen.
Boring Catalog stores all Iceberg catalog state in a single JSON file:
- Namespaces and tables are tracked in this file
- S3 conditional writes prevent concurrent modifications when storing catalog on S3
- The .ice/index file in your project directory stores the configuration for your catalog, including:
- catalog_uri: the path to your catalog JSON file
- catalog_name: the logical name of your catalog
- properties: additional properties (e.g., warehouse location)Let’s get everything set up with `uv`, and then we can go off to the races.
uv init boringiceberg
uv add pyiceberg duckdb polars boringcatalog
Good first note and problem, I need a newer Python version, at least 3.10, to use boring-catalog. Easy enough to fix that problem.
uv init boringiceberg --python 3.11
uv add pyiceberg duckdb polars boringcatalogNext, much like any other Iceberg catalog, we need to set up a warehouse, in our case, we want it located in s3 somewhere.
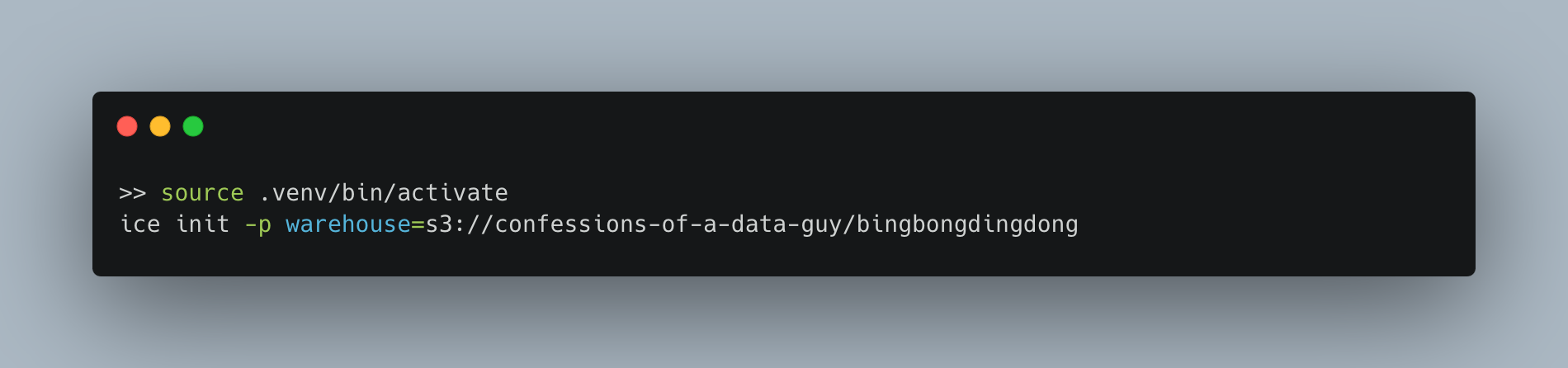
(boringiceberg) danielbeach@Daniels-MacBook-Pro boringiceberg % ice init -p warehouse=s3://confessions-of-a-data-guy/bingbongdingdong
Error initializing catalog: Failed to initialize catalog at s3://confessions-of-a-data-guy/bingbongdingdong/catalog/catalog_boring.json: When getting information for key 'bingbongdingdong/catalog/catalog_boring.json' in bucket 'confessions-of-a-data-guy': AWS Error ACCESS_DENIED during HeadObject operation: No response body.
Aborted!I figured this might happen; the docs don’t mention credentials, and I have multiple AWS profiles stored in my .aws configs. Running the help command doesn’t indicate anything for me to point to a specific .aws profile.
(boringiceberg) danielbeach@Daniels-MacBook-Pro boringiceberg % ice --help
Usage: ice [OPTIONS] COMMAND [ARGS]...
Boring Catalog CLI tool.
Run 'ice COMMAND --help' for more information on a command.
Options:
--version Show version and exit
--help Show this message and exit.
Commands:
catalog Print the current catalog.json as JSON.
commit Commit a new snapshot to a table from a Parquet file.
create-namespace Create a new namespace in the catalog.
duck Open DuckDB CLI with catalog configuration.
init Initialize a new Boring Catalog.
list-namespaces List all namespaces or child namespaces of PARENT.
list-tables List all tables in the specified NAMESPACE, or all...
log Print all snapshot entries for a table or all tables...Let me export my AWS creds into the environment and see if that does the trick.

Perfection.
So, as long as that is working, we should be able to write some Python now and see what happens.

This code doesn’t work unfortunately …
Traceback (most recent call last):
File "/Users/danielbeach/code/boringiceberg/.venv/lib/python3.11/site-packages/pyiceberg/catalog/__init__.py", line 922, in _resolve_table_location
return self._get_default_warehouse_location(database_name, table_name)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/danielbeach/code/boringiceberg/.venv/lib/python3.11/site-packages/pyiceberg/catalog/__init__.py", line 935, in _get_default_warehouse_location
raise ValueError("No default path is set, please specify a location when creating a table")
ValueError: No default path is set, please specify a location when creating a tableEven though the table location is an optional None in the source code, which makes sense, we are passing in the full namespace and table name to the catalog, it should be smart enough to create the location itself without me telling it where to go.
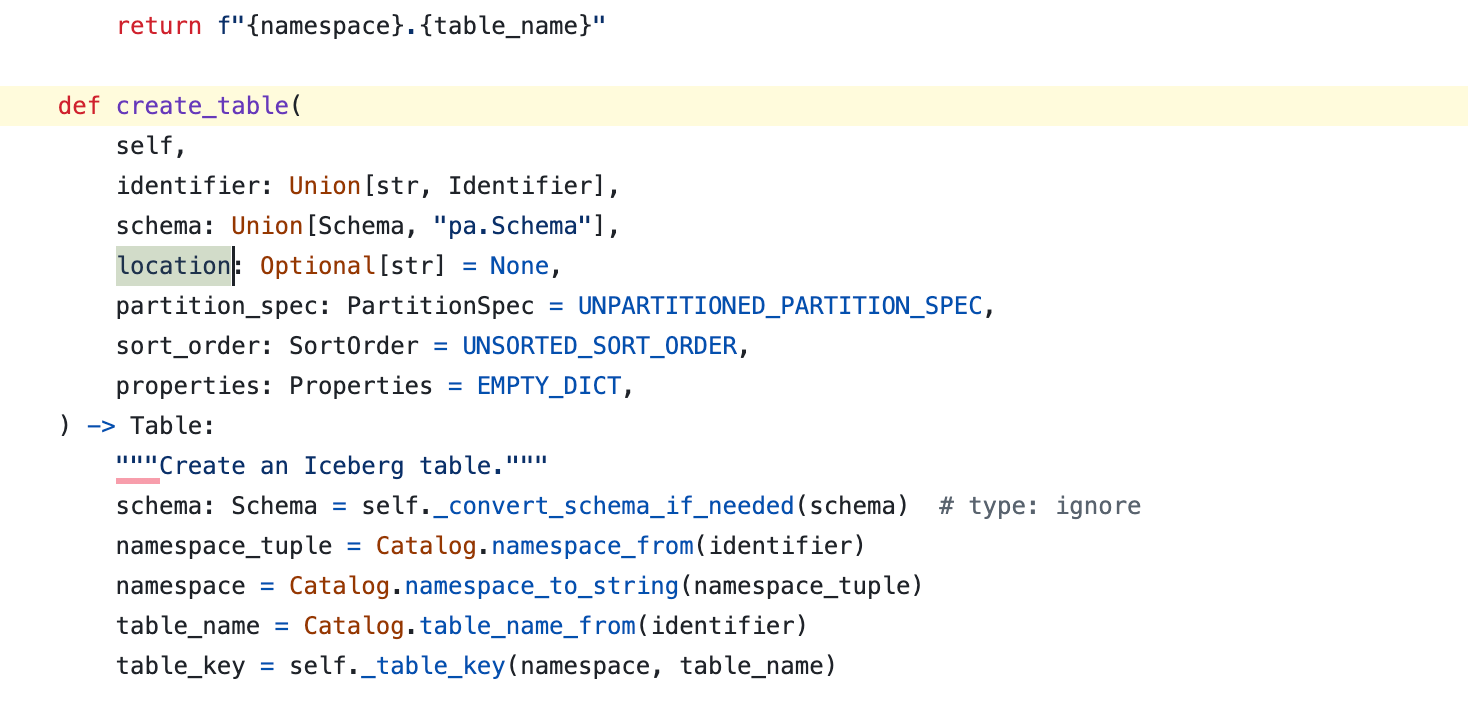
Either way, I can do its job for it and tell it where to store the table. That seemed to do the trick; updating the following line with a specific table location worked.
catalog.create_table(identifier=("pickles", "trip_data"), schema=data.schema, location='s3://confessions-of-a-data-guy/bingbongdingdong/')Ok, so now we have created an Iceberg catalog and warehouse and created a table inside it. Let’s see if we can write some trip data to it.
(You will note I used the Divvy Bike trip dataset, reading it via Polars and converting to Arrow and using that for the schema of the Iceberg table).
Now, we can see if the real test works. Can we use something like Polars to write directly to this Apache Iceberg table using our boring-catalog.

All we are going to do, is in the above code use … df.write_iceberg(table).

So easy. It’s almost like we are using Delta Lake.
Here is the code to read the data back to prove it worked.

warnings.warn(
pyarrow.Table
ride_id: large_string
rideable_type: large_string
started_at: large_string
ended_at: large_string
start_station_name: large_string
start_station_id: large_string
end_station_name: large_string
end_station_id: large_string
start_lat: double
start_lng: double
end_lat: double
end_lng: double
member_casual: large_string
----
ride_id: [["AF3863596DF9D94B","8B38081EBE918800","1C7F1DE826BBBC8D","CAD23D69A79A6C3B","BE241E601482E0AB",...,"3A350F6EF7EBBE32","D1D3DE0B041A0619","E23151BA351A9F0C","D932E1160214FD7F","A49BBBC483A8C824"],["7F89DAF53151591F","F868AC218A8DCDD3","32C1295AEFCCD873","106A7E3CB0DCFC59","83FF6EE3387486EA",...,"42A3DC25B6F1A61C","EB4A20D2CF7B843C","2AD698618BF66003","5B1C269FB6352DFA","1C7B8011918D458C"],["62359148F3BD42E9","82417490E9339CE8","D8B6BD81A778C228","3B5187D1B7DCEFFD","9ADDBDD39ECAD340",...,"00EE7C31C568974F","B6DBC7FD6DD0DEF3","B099E6E3285BE09B","76BD307B9C12E25F","420F78CF3AD3E7FF"]]
rideable_type: [["classic_bike","electric_bike","electric_bike","classic_bike","electric_bike",...,"electric_bike","electric_bike","electric_bike","electric_bike","classic_bike"],["electric_bike","classic_bike","classic_bike","electric_bike","electric_bike",...,"electric_bike","classic_bike","classic_bike","electric_bike","electric_bike"],["classic_bike","classic_bike","classic_bike","classic_bike","electric_bike",...,"electric_bike","electric_bike","electric_bike","electric_bike","electric_bike"]]
started_at: [["2025-04-27 14:29:34.619","2025-04-23 17:48:51.863","2025-04-05 17:55:30.845","2025-04-03 08:22:04.493","2025-04-15 06:09:55.293",Dang, what a nice tool. That’s the real deal right there. Production ready tomorrow.
What the crap?
Now riddle me this you hobbit, why is it that it took a lone Data Engineer wandering this broken world, this far into Apache Iceberg being around, to write a simple to use cloud-compliant Catalog that actually works???
Let’s be honest, we have all sort of massive companies like AWS (with S3 Tables) and others trying to take advantage of the Iceberg hype. We have a myriad of utterly complex Icberg catalog options that you can install and setup that require magic and servers.
You know what we didn’t have until now?
I realistic and reliable simple cloud enabled Iceberg Catalog that you could use in an TRULY open-source way.
It’s incredible yet predictable that the entire Apache Iceberg universe of talking heads and companies are EACH taking advantage of Iceberg users without actually putting DEVELOPERS FIRST and providing a real, simple, and workable catalog option into the open-source space.
The Iceberg community at large needs take a note from the page of Databricks and Delta Lake, like it or not. They have put open-source usability and developers first, and it shows in their product.
I highly suggest you send a thank-you note to Julien Hurault and follow him on Linkedin and check out his Substack.

This article might be up your alley too
https://quesma.com/blog-detail/apache-iceberg-practical-limitations-2025
+1 for Julien and his work! It’s great stuff!