

10 billion row challenge. DuckDB vs Polars vs Daft.
... just for fun.


Sometimes I find myself lying in my sunroom, staring out the window in the blue sky above me while the sun plays on the maple tree, empty of most all but a few red leaves … wondering what else I can do to make the already angry readers of my babbling even more angry.
There is an art to it, I swear.
I am periodically overcome with esoteric questions about why anyone would read what I have to say in the first place, but then I remind myself of the truth.
There is a massive number of marketing machines that night and day puke forth a glut of data drivel that falls right onto the heads of the (mostly) unsuspecting data engineering victims who happen to be my audience.
I’m here to do the Lord’s work.
Thanks to Delta for sponsoring this newsletter! I personally use Delta Lake on a daily basis, and I believe this technology represents the future of Data Engineering. Check out their website below.

Someone has to keep them in line, someone has to be willing to stand up and fight back and rage against the machine. Today, we will do just that.
We will do that 10 billion times.
Take the survey.
Honestly, this is just for fun, and of course, it will be interesting. I have something I want you to do. Don’t lie. Don’t cheat, vote for who you think is going to be fastest.
Performance on 10 billion records. DuckDB. Polars. Daft.
So, just to keep the talking heads off my back as long as possible when it comes to this non-TCP benchmark, finger in the wind test, I will use an AWS EC2 Instance for the compute and store the data as Parquet files in s3.

2 vCPU and 8GB RAM should be enough to see which one of these tools has the gumption to get the job done without puking. Running things on commodity hardware is important.
Next, we need to generate a dataset with 10 billion records. I’m going to use my recently built Rust-based tool datahobbit. The problem is it only generates CSV files, so I updated it to pump out the results into Parquet format optionally.

Also, we need to do a few basic commands on our new EC2 instance, just a get a few tools that will come in handy.
Side Note: if you are a Data Engineer who is unfamiliar with the command line, Ubuntu/Linux, ssh’ing to machines, etc. It’s an extremely useful set of skills that will make you very valuable. Strike while the iron is hot.
Now that we are in our newly acquired EC2 instance, let’s update some apts, install git, and pull down our datahobbit so we can generate or 10 billion row parquet dataset.

Let’s make our dataset shall we?

Easy enough … you’re welcome. Let’s push these files out to s3, shall we?

Looks like we ended up with about 173 parquet files totaling 16.5 GBs of data. This should be very easily ingested by all the tools we want to test.

In case you are wondering, our data looks like this.

I think this test will be interesting for a few reasons.
How well the tool can read lots of files on s3
How well it can run a basic aggregation
How good the tool is at looking for default AWS creds (in .aws )
Polars vs DuckDB vs Daft … 10 billion records.
Now that the hard part is behind us, let’s do what we came here to do. See if these data tools that each claim to be the GOAT, are just sheep or the real deal.
Let’s start with DuckDB.
DuckDB with 10 billion records in s3 parquet files.
So, I’m not a DuckDB expert, I don’t use it much, but this is my best guess based on the documentation of the best way to read a bunch of parquet files in s3 and write the results out to a CSV on s3.

I am using a depreciated way to grab local AWS credentials, it won’t work magically (unlike other tools), and this depreciated load_aws_credentials() seemed like the path of least pain.
Besides the performance of this DuckDB code, what else do we note about what we had to write?
clean and simple code
doesn’t appear to automatically sense we are doing s3 stuff and pickup default credentials from the system
clearly SQL-based
The first run resulted in OOM (which is nothing new to DuckDB).
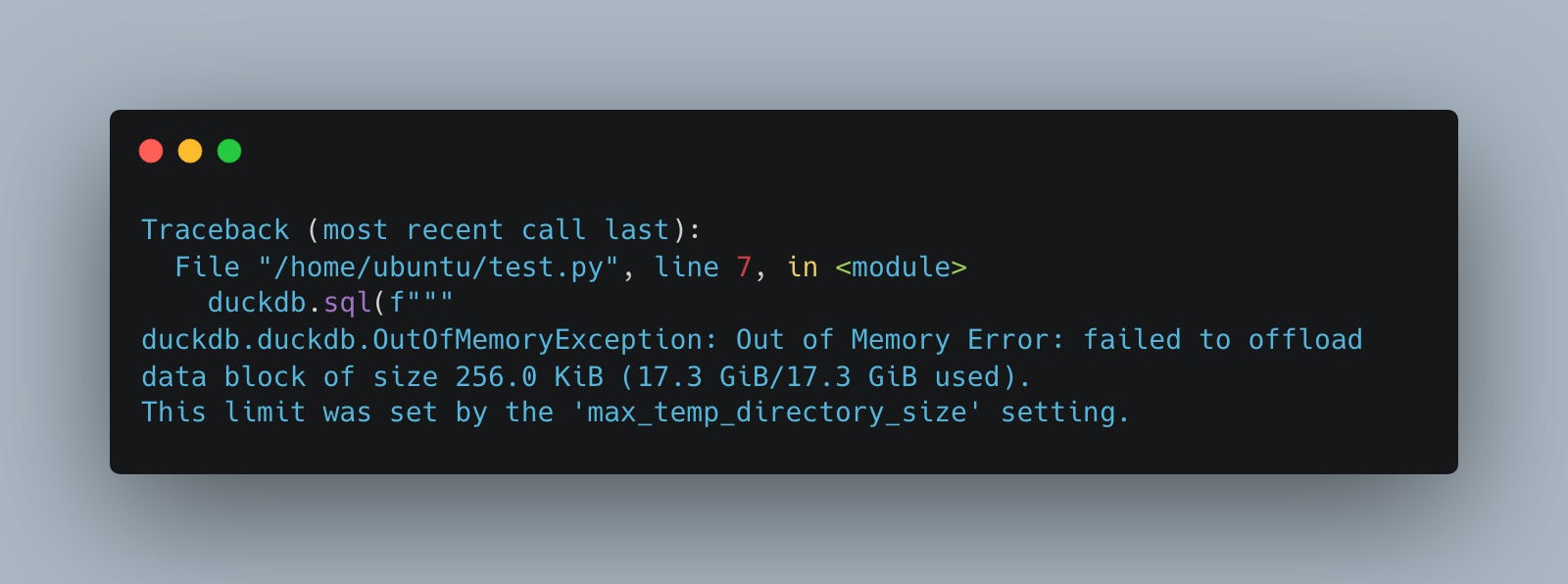
This isn’t really a surprise if the work isn’t done in a lazy manner as our dataset is slightly bigger than our machine’s memory size (16.5GB vs 16GB).
Let’s add three lines to our DuckDB code. I’m throwing mud at the wall and hoping one, or the combination of these settings will allow DuckDB not to choke.
SET temp_direcotry = ‘/tmp/duckdb_swap’;
SET memory_limit = ‘15GB’;
SET max_temp_directory_size= '25GB';

still no juice!
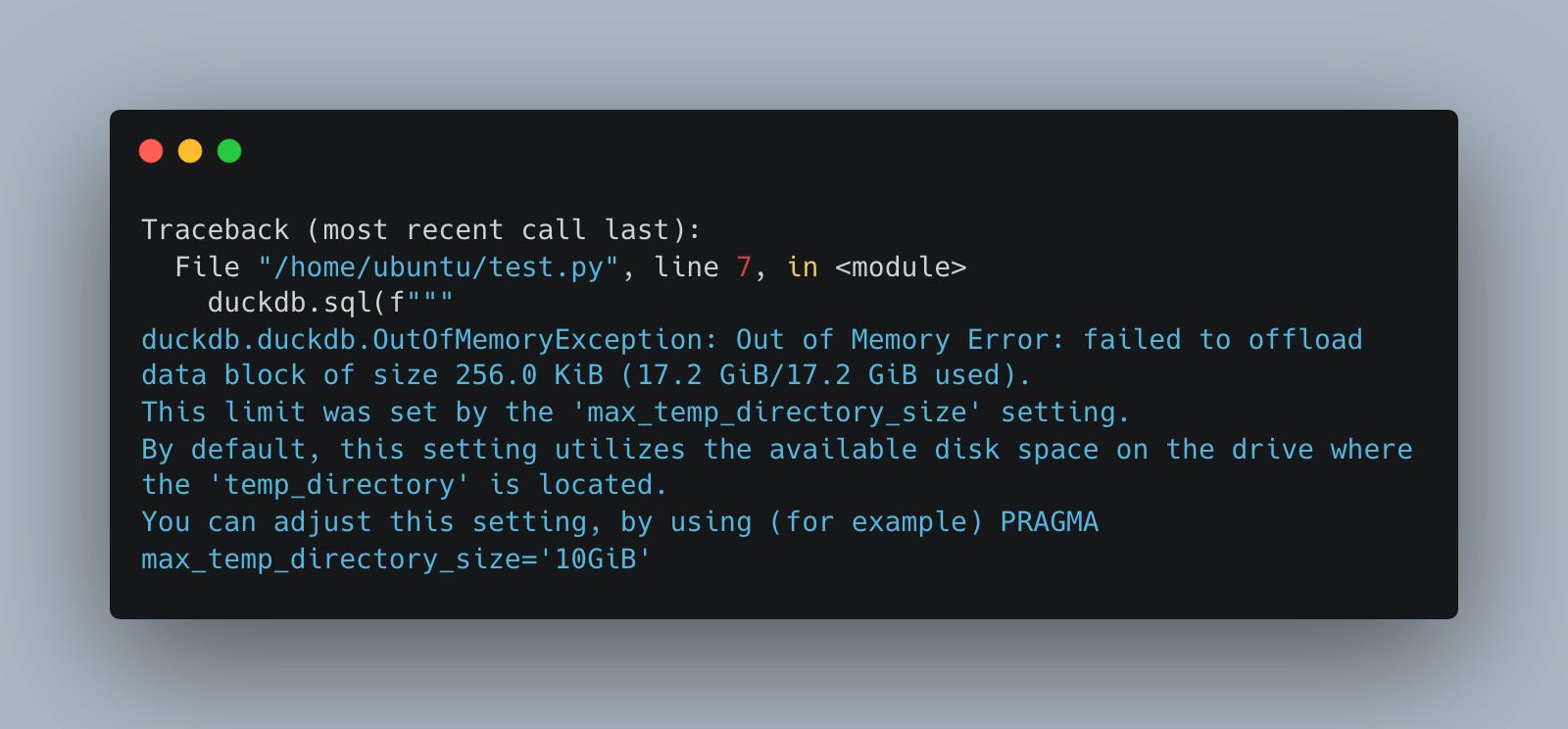
I have no idea, maybe I should just remove the max_temp_directory_size setting, as the above error says …. “By default, this setting utilizes the available disk space on the drive where the `temp_directory` is located.
That was a no go, still the same error. I simply cannot make DuckDB not puke with OOM.
Moving on.
Daft with 10 billion records in s3 parquet files.
Daft is one of my new favorite Dataframe (and now SQL) tools to use. It’s fast as crud and easy to use, it has very straightforward and simple APIs to work with.
You don’t have to throw salt over your left shoulder to get it to work … cough … unlike other tools.
I mean look at this code. Seriously.

I don’t have to tell it about credentials or that I’m doing AWS stuff, I don’t have to tell it to do memory antics at all. It just flipping works.

Now finally some results. Simple clean code with no boilerplate, worked on the first try, 2:25 minute runtime. 10 billion records in s3, not bad Sunny Jim.
Crazy simple code.
It’s smart enough to take away boilerplate like AWS creds etc.
It’s fast.
It has SQL.
All bow before the power of Daft.
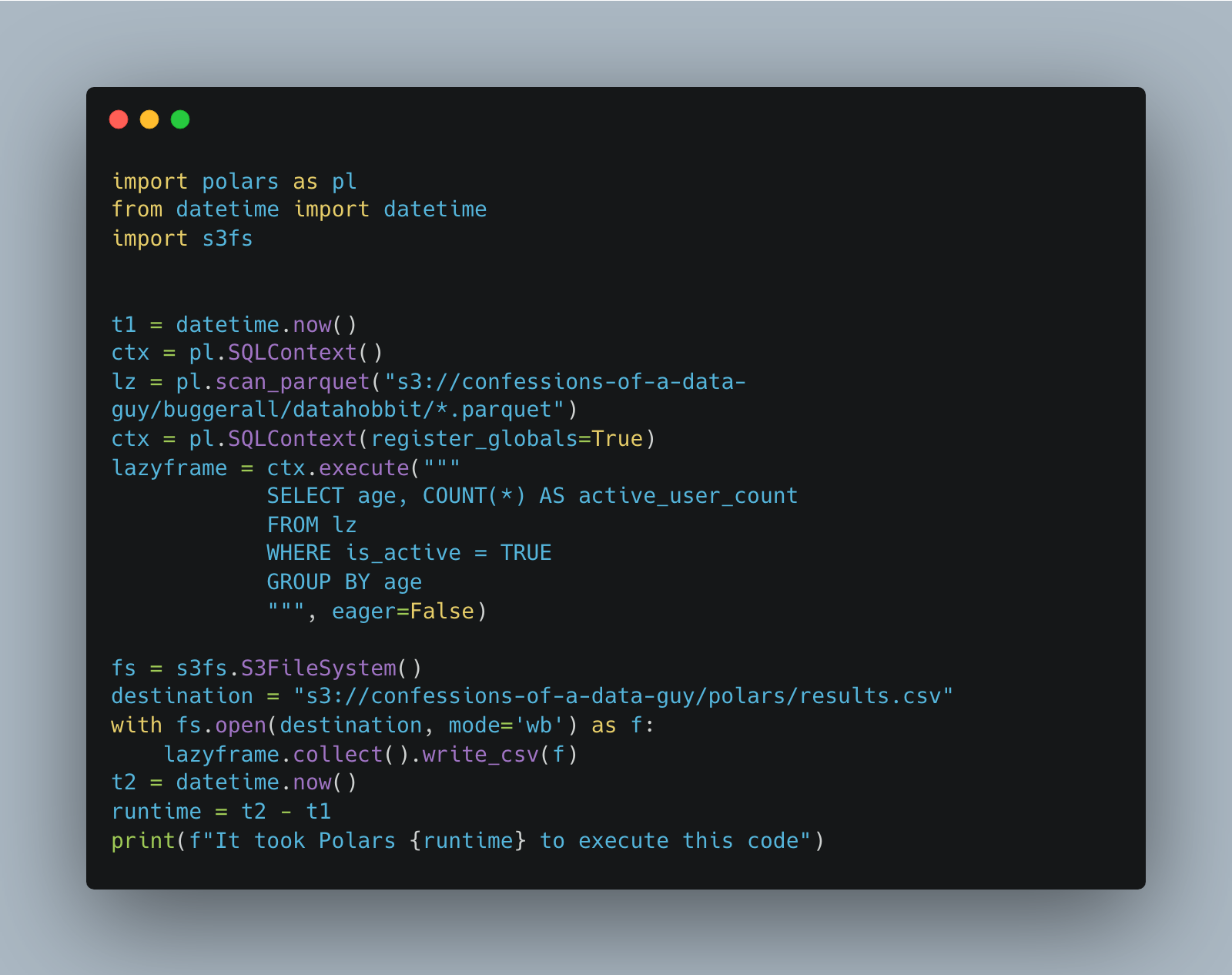
Polars with 10 billion records in s3 parquet files.
And now we come to the self-proclaimed GOAT of the new and rising Rust-based Dataframe tools. Shall we see if it deserves this recognition or not?
Well, not hard to beat DuckDB that simply won’t work without some sort of black magic of which I have not been endowed.
I’m interested to see not the Polars code itself compared to Daft, but the performance. Being both Rust-based gives them each a distinct advantage to be fast, but when we start dealing with files in the cloud, s3, this adds a layer of complexity that is really going to show who put the time in.

What do we note about this code?
Didn’t require any AWS or credential funnies, it picked up the defaults of the machine fine.
We had to use scan_parquet etc to force lazy evaluation.
You have to be in the know about lazy vs eager and things like collect() when using Polars on large datasets.
Offers SQL, and fairly clean code.
First error with Polars.

Apparently, Polars is smart enough to scan_parquet on an s3 folder without trouble, but not smart enough to simply write_csv to an s3 location. Annoying as crud.
We must do some more Python that we are used to, unfortunately. That old s3fs must be used, the little blighter.
And the performance.
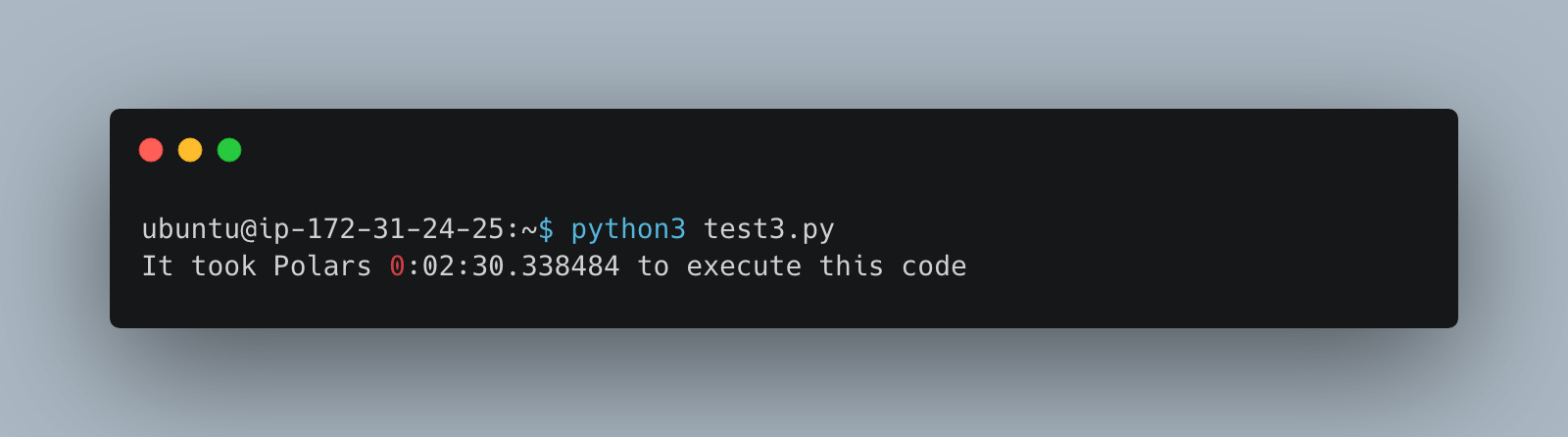
Not bad, pretty fast 2:30, only 5 seconds slower than Daft (which is at 2:25).
Summing it all up.
Well, not sure I saw all that coming. I thought DuckDB had fixed its OOM issues, but apparently parquets in s3 were enough to throw it off. Not sure what else I could have done, I’m simply only going to spend so much time trying to make it work before I move on.
I thought Daft would blow Polars out of the water, but they both came in around the same execution time.
It appears the Daft code is a little cleaner, less nuances and things to deal with, more straightforward compared to the Polars code, although Polars wasn’t that bad.
I accomplished what I wanted today.
In the end I just try to take the best tools available and put them through some sort of normal workflow that would mirror some production pipeline.
Production Pipelines don’t run on people’s laptops. They are on commodity hardware like EC2, they read and write data to s3. This is where the difference is.
Many of the posts I see are people doing things locally, which is all fine and dandy, but honestly, it’s the small things like the ability to work in the cloud that make the difference between a fun play-toy on a laptop, and running the real deal in production.
What say you?
re DuckDB: it has gotten a lot better at larger-than-memory queries. However, in this case, you’re trying to create the database in memory and then run a query on it.
suggest two options:
a) run your aggregation query directly without the CTAS by specifying the table function read_parquet instead of “data”
OR
b) specify a database file so that the database is actually created on disk before trying to execute the aggregation query.
ie con = duckdb.connect(“my.db”) and then con.sql()
Why are you comparing a database with two data engines? Is that a fair comparison?
Did you only run the tests once? For more accurate results, shouldn’t you conduct at least three runs per test to calculate an average? Variability is common in these types of performance tests, so a single run is not reliable AT ALL.
Do you know what time takes only to initialize both engines (Polars and Daft)?
Do you know which libraries Polars and Daft use to connect to S3? Are they the same or different?
How do these tools handle parallelization? Are there differences in how they distribute calculations across resources?
This article lacks depth and raises more questions than it answers.