

Apache Polaris (Iceberg Catalog) ... with Daft
.. kicking tires ...

Much to my disappointment, that rapscallion upstart Apache Iceberg keeps getting more and more chatter. Whatever. Since when has everyone else been right? Either way, I refuse to give up my first love, Delta Lake, but I can be reasonable when I have to.
I mean, I have used Delta Lake Uniform to pretend like I’m reading and writing Iceberg. That counts for something.
It’s been a hot minute since I wrote something about Iceberg proper, and with all the lemmings talking about Iceberg nonstop, I figured, why not drag myself begrudgingly onto the hype train?
What should we do?
We will do something boring (or exciting depending on your view) like …
Set up the Iceberg catalog on a remote instance.
Create an Iceberg table in s3.
Write some pyiceberg/polars/duckdb? that can be written to said Iceberg table in s3.
Wrap it up in an AWS lambda.
Put a file trigger on the s3 bucket for lambda to consume.
I want to do something that at least somewhat might resemble a production workflow. Honestly, when I see people doing something and it starts with “I setup x, y, or z on my machine and started using local host …” … I start to tune out. To truly understand a tool and how it behaves you have to put it in a production like environment.
Poking at Apache Polaris (incubating)

I plan to attempt to use the Iceberg REST catalog that Polaris provides, installing it on a remote server in the cloud so we can hit it via an AWS Lambda for processing CSV files into a “Lake House.”
To do this we will use Linode, creating an Ubuntu server and installing Polaris on it.

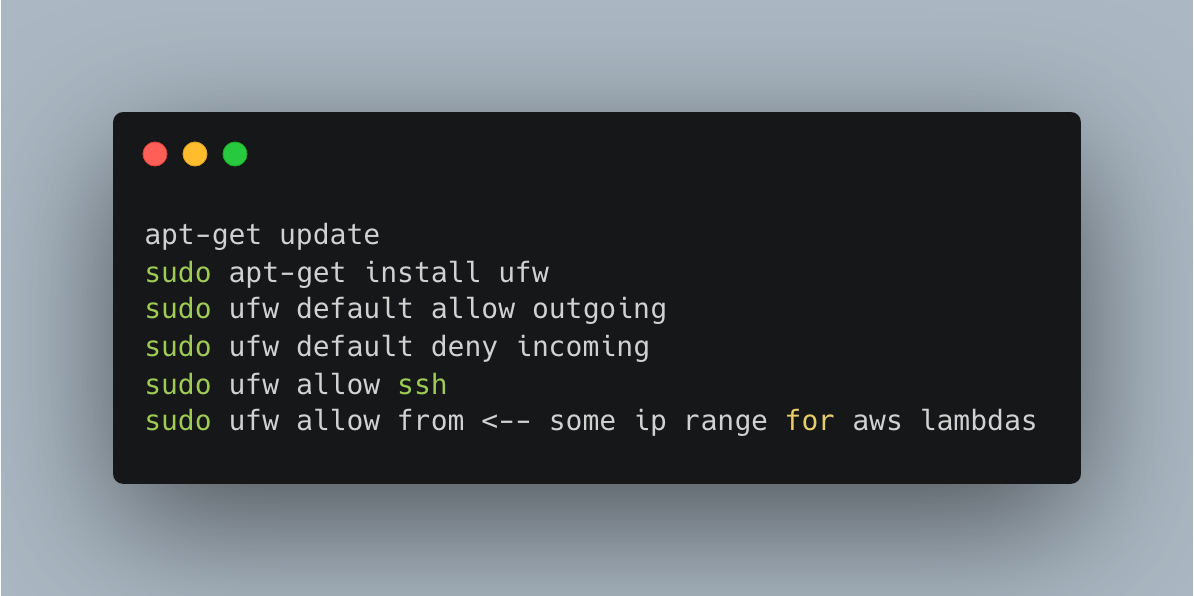
As a side note, since we will be using an REST API via HTTP connections over the web, I’m going to use UFW on Ubuntu to block all incoming connections except IP addresses that I whitelist.
Now that we have the easy part done, let’s check the Documentation for Polars and see what are options are for install.
It appears the docs only give us two options, local install and using Docker. Docker is fine for us, hopefully they made it easy. If you’re running this code like me on a fresh Ubuntu server, you can install docker and docker compose like this.
Below is a screenshot from the docs.

You guessed it, the first error.
root@localhost:~/polaris# docker compose -f docker-compose.yml up --build
open /root/polaris/docker-compose.yml: no such file or directoryApparently no docker-compose file in the base directory. Doing a `ls` confirms this is the case.
root@localhost:~/polaris# ls
aggregated-license-report CODE_OF_CONDUCT.md gradle kind-registry.sh regtests spec
api codestyle gradle.properties LICENSE run.sh tools
bom CONTRIBUTING.md gradlew NOTICE SECURITY.md version.txt
build.gradle.kts DISCLAIMER helm polaris server-templates
build-logic docs ide-name.txt polaris-core service
CHAT_BYLAWS.md extension integration-tests quarkus settings.gradle.kts
client getting-started k8 README.md siteLet’s search the GitHub repo for docker-compose.yaml and see if we can find where they stored it, since they lied to use in the docs.

When looking at the Git repo notes I saw a little note about running it in Docker.
docker run -p 8181:8181 -p 8182:8182 apache/polaris:latestWell, that doesn’t work, that Docker repository on DockerHub is empty. Lies. Fifthly lies.

Well, if you search the repo it turns out they have a lot of docker compose files, for some reason … trying to run a few of them with the following command I get the following error every time.
docker compose -f regtests/docker-compose.yml up --build
✘ polaris Error manifest for apache/polaris:latest not found: manifest unknown: manifest unknown 0.3s
Error response from daemon: manifest for apache/polaris:latest not found: manifest unknown: manifest unknownNo surprise there, all the composer files reference the image apache/polaris which is non existent. Back to the docs.
apt install openjdk-21-jdk
./gradlew clean :polaris-quarkus-server:assemble -Dquarkus.container-image.build=true --no-build-cacheImportant Note! This command would not work and would die half way through, until I upgraded to a 4GB sized Ubuntu server … aka it needs some RAM to run. (I started with 2GB)
Next, they have a getting started docker compose that will start both Polaris and Spark … let’s just use that to make this easy, but we won’t use the Spark image that runs.
docker-compose -f getting-started/spark/docker-compose.yml upWell, something worked, spitting stuff to the command line.

Also, since I whitelisted my IP address, I should be able to hit one of the ports on this server and get something back, good or bad, and indeed, this is the case.

The Polaris quick start we used provided a Notebook that along with Spark can talk to itself. I would like to NOT use this option, but this is a good sign that we have got Polaris up and running on our Ubuntu Server.
Next, let’s see if we can hit the Polaris Iceberg Catalog from something like PyIceberg or whatever Polars provides.
Side note, if you search Polaris on PYPI it appears there is only a single recent release.

Hurdles.
Well, before we set off fireworks and say we are done … we are not. The battle is only half fought. Now that we have Polaris up and running … we still need to create a Catalog.
At this point you might be thinking, like me, hey … we got Polaris up and running let’s connect to it with PyIceberg and do some things. Well, as you can see below from PyIceberg docs, it assumes you already have a Catalog created … gives no options to create on from scratch.

So, we are going to have to rely on the Polaris Python package to create our first catalog. At this point, I just want the thing running, so instead of backing our first catalog up on s3, let’s just use the local file system of the Ubuntu instance that is running Polaris.
Luckily, the GitHub shows an example of this here, we can modify it to fit our needs … and pray to the Tech Bro gods that it will work.
NOTE!
hitting this Polaris default endpoint appears to require a token, took me a minute to realize it, but I could see the token printed to the console logs ... see below. (have fun trying to hack my Polaris server ... it will be long gone by the time you read it)
What’s even better is that we can use the default Notebook I showed a screenshot of above, as it already has the code in it to create a default Catalog in Polaris.
If you are curious what the code looked like to do that, here it is in all it’s glory.

In theory now, we have a Iceberg Polaris Catalog called “polaris-demo.” Now we should be able to switch to pyiceberg.
First … the Python/Iceberg Option.
I’m tired of hearing that ole’ Matt Martin talking about pyiceberg non-stop. Since it’s all I ever hear about, we will be giving that Python package a try inside our AWS Lambda.

But, first let’s just see if we can get pyiceberg to talk to our Polaris Iceberg catalog from my local machine … this is where things get a little weird.

I kept getting 401 Not Authorized if I tried to hit the endpoint WITH or WITHOUT the token passed. I know that token is good, so is it HOW I am trying to pass it??
After piddling around I got a response that Polaris/Iceberg failed to verify the token … although I don’t know what that means.

According to the pyiceberg docs, I should be able to use 'token’. The one thing I noticed below that I have not tried added is the ‘credential’, and I believe we can see the ‘credential’ being used in the sample Notebook that we used to create the default catalog.

After many tears and much anger on my part, reading the pyiceberg docs and example Notebook, I finally got it to work. That is get pyiceberg to remotely connect to this Polaris Iceberg Catalog.

uri
credential
token type
scope
warehouse
access token
The above list is what you need. (you have no idea how many combinations of guessing I tried to make this happen).

Don’t worry, I’m sure I will recovery my sanity at some point. The things I put myself through for you people is unbelievable. I could be sitting outside soaking up rays and touching grass.
Honestly, I’m ready to get down to it. Can I actually now write an AWS Lambda that will trigger on a CSV file loading into S3 and read it into an Iceberg Table?
pyiceberg + polars + Daft.
Now we can get to what we’ve all been waiting for, actually writing some Python code to interact with Polaris Iceberg Rest catalog. First things first, let’s use pyiceberg to create a namespace.
Using the code above to connect to our catalog, it’s as easy as …
catalog.create_namespace('pickles')Now we need an Iceberg table. We will use pyarrow for this. Also, we can use the Divvy Bike Trip open source dataset for our data. Here is a sample file.

Here’s our Python code to load a file with pyarrow and use it to create an Iceberg table.

You thought this was going to work??!! Guess again you hobbit. I told you this would be the hard part.
....
packages/pyiceberg/catalog/rest.py", line 418, in _handle_non_200_response
raise exception(response) from exc
pyiceberg.exceptions.ForbiddenError: ForbiddenException: Principal 'root' with activated PrincipalRoles '[]' and activated grants via '[service_admin, catalog_admin]' is not authorized for op CREATE_TABLE_DIRECT_WITH_WRITE_DELEGATIONApparently my Polaris setup was not complete, I have no access to write tables. Think you want to cry yet? Go read the flipping Access Control docs. Reminds me of AWS IAM crap. Good luck.

The worst part is it doesn’t appear on the surface they have a UI on Polaris you can do this stuff through. Below is a screen shot of the Roles, Principals, Privilege concepts that Polaris uses.

Truth be told we shouldn’t be mad about this. This sort of fine grained control is what you would actually want in a Production environment, access control is a critical part of any Catalog system.
That being said, you can find an example of top-to-bottom walk through from Principal Creation down to Privileges in this Quickstart from Polaris.
I’m going to try walking though it and creating one from scratch myself so I can actually write an Iceberg table. We are so close.
I hate to do this to you, but this is what I had to run to get everything setup for myself. It’s important to print the results and save the output from those commands as it has the client_id and client_secret used for ‘authing via Iceberg Rest.
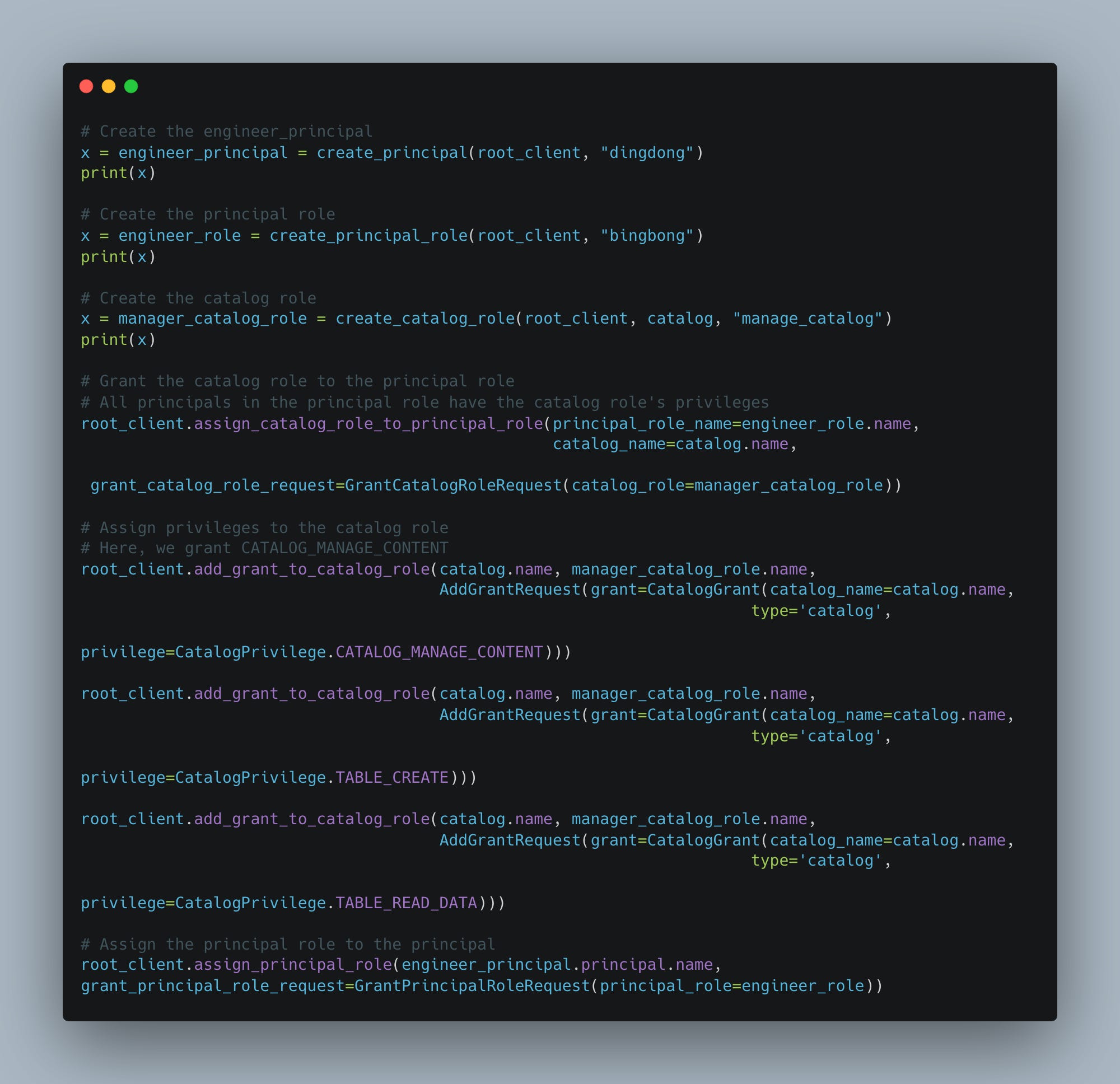
Once that was done I could update and re-run my command to create the Iceberg Table.

This command appeared to work … I didn’t get any errors out of the command line, just some text.
Iceberg does not yet support 'ns' timestamp precision. Downcasting to 'us'.
trip_data(
1: ride_id: optional string,
2: rideable_type: optional string,
3: started_at: optional timestamp,
4: ended_at: optional timestamp,
5: start_station_name: optional string,
6: start_station_id: optional string,
7: end_station_name: optional string,
8: end_station_id: optional string,
9: start_lat: optional double,
10: start_lng: optional double,
11: end_lat: optional double,
12: end_lng: optional double,
13: member_casual: optional string
),
partition by: [],
sort order: [],
snapshot: nullI’m going to assume this means the table was created. Let’s see if we can read it back with Polars.
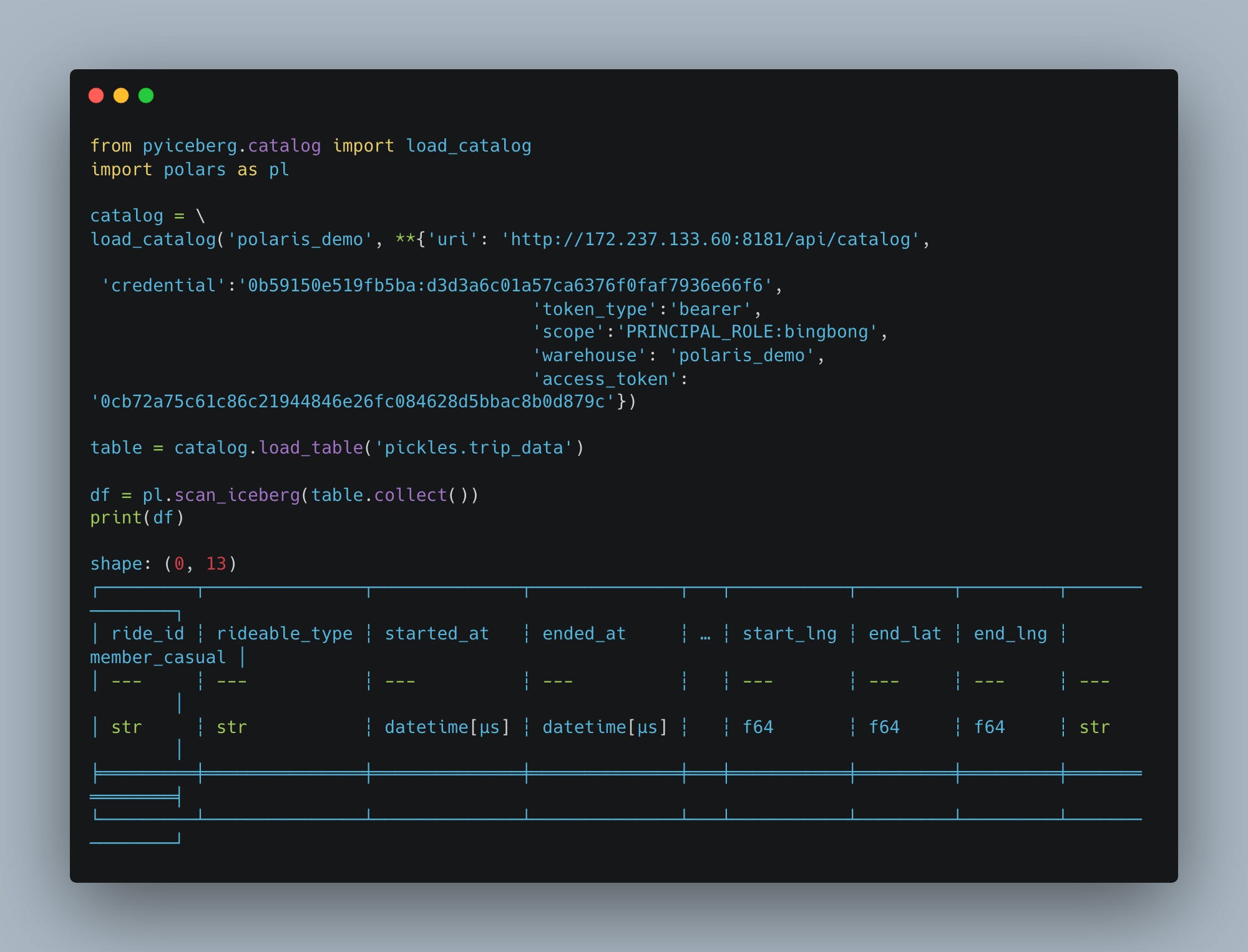
Indeed it works, we have an empty Iceberg table that can be read by Polars. Fascinating. I feel as if I’ve aged 50 years getting here.
I suppose we are this close, let’s
try to make an AWS Lambdajust write some Python that can actually write some data into this table.
I mean if I can just write the Python locally to write to this remote Polaris managed Iceberg catalog, there is no reason it would not work inside an AWS Lambda. I’ve already spent too much time working on this, and I just want to be done.
Let’s switch it up and use Daft to write a CSV file into an Iceberg Table. (Polars refused to work WRITING to an Iceberg table.)
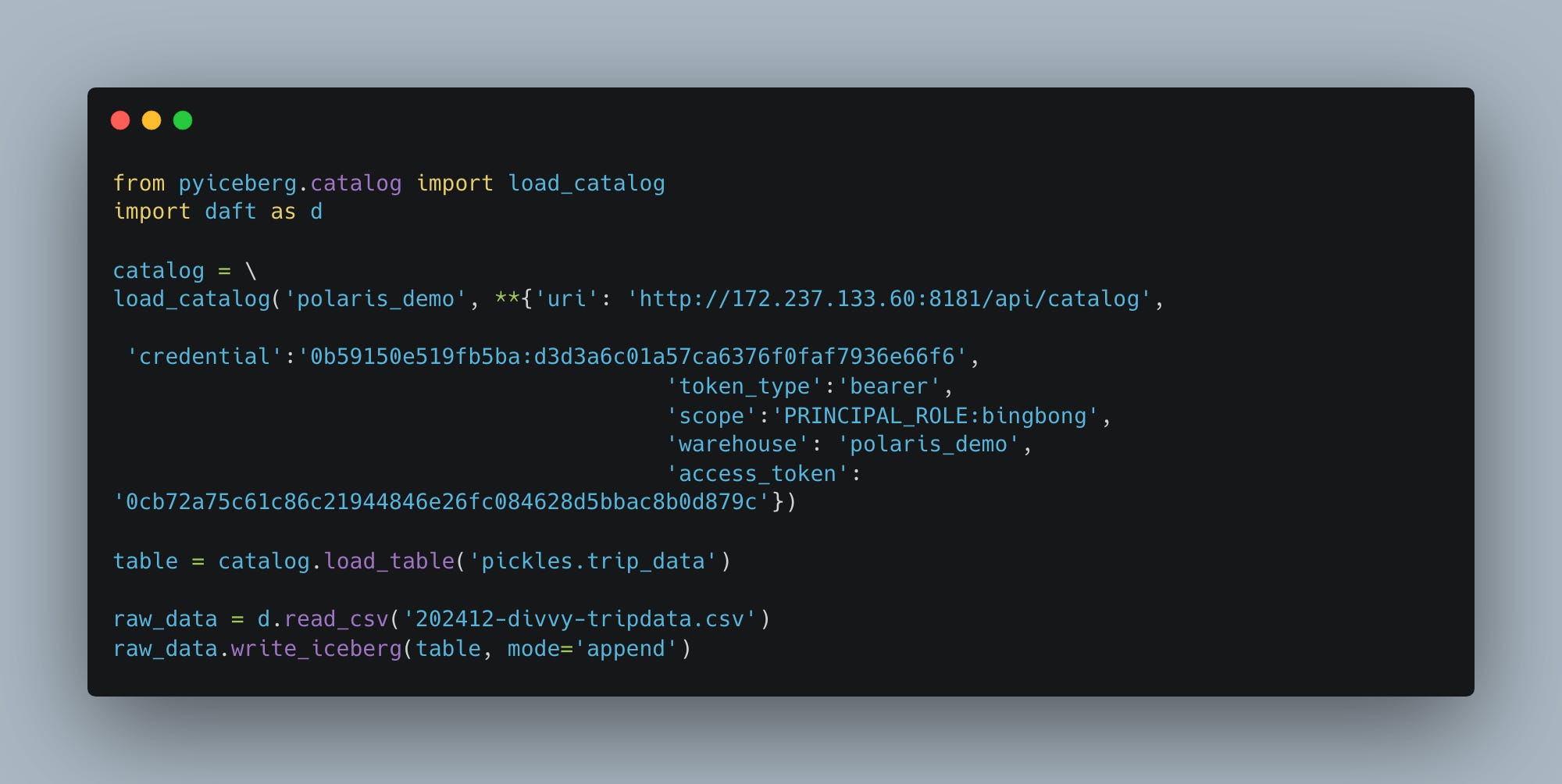
Easy enough. Let’s also use Daft to read it back and see if we have records now.
df = d.read_iceberg(table)
df.show()
Finally, an Iceberg Table we can managed through Polaris for read and write … use OSS all the way to the very bitter end.
The End.
Normally I would stick around and give you some grand overview of my thoughts about Apache Polaris and Iceberg REST catalogs in general. But since I’m now half dead after doing this all for you, (I hid much of the pain and suffering from you), I’m too tired to do so.
I will just bullet point my thoughts and then sign off.
Open Source Iceberg Catalogs suck.
Polaris is full featured, with things like access control which is impressive.
Polaris was one of the few Iceberg Catalogs I tried to setup (like LakeKeeper) and was the ONLY one I could actually get running.
Documentation and instructions suck (nothing new there).
Java based tools tend to be a pain.
My head hurts.
In all seriousness, Catalogs are the future and the KEY to managing Lake Houses now and in the future, at scale, in production. Also, Catalogs are NOT plug and play, they are too complicated for that.
They require setup and a good amount of time to understand and implement fully.
Once done, and the bugs and kinks worked out, the rest (the read/write) is easy with pretty much whatever you desire … plain Python, Spark, whatever.
Bye.
I see you invoked my name as the savior of pyiceberg…you’re welcome Daniel-son