

Delta Lake vs Iceberg. UniForm and Unity Catalog.
... will there ever be harmony?


I don’t know what to think. I imagine both Apache Iceberg and Delta Lake will be with us for a long time to come. At this point, I don’t think it’s possible for one format to totally defeat the other. Each is ingrained into different sections of the market, with Delta Lake in the large and growing Databricks Community and Iceberg in the open-source and AWS land.
I much prefer Delta Lake myself; the developer experience is far superior. But to be a good Data Engineer, we should explore everything we can find. Having some experience with everything is better than being a one-trick pony.
I’ve heard rumblings about UniForm and Unity Catalog solving the issue of having two table formats to choose from.
Marketing folks make it seem like you can use UniForm and/or Unity Catalog to seamlessly integrate Apache Iceberg and Delta Lake on the same platform. This sounds too good to be true. My guess is that key features are missing, and they get glossed over. But hey, let’s find out, shall we?
Trying out UniForm and Unity Catalog to deal with Iceberg AND Delta Lake

First off, I’m not sure I totally understand the desire to run both Delta Lake and Iceberg on the same platform, but I guess with larger companies at scale they will end up in a situation like this. That’s just life.
Either way, I’m curious about a few questions that I want to see if we can answer.
Can we create Iceberg tables on Databricks and use UniForm to read them?
Can we register Iceberg tables in Unity Catalog?
What does the code look like to read both Delta Lake AND Apache Iceberg.
Can we WRITE to Iceberg tables with UniForm/Unity Catalog?
Got any guesses? I don’t even know if these are the correct questions to ask, or if they are possible. Let’s just play with the tools and find what we find.
Where to start?
I’m not totally sure where to start, but I think with a flip of a coin we will start with (Delta) Uniform. Now if you’re like me and you’ve only heard the name, or never heard the name, what is it and what does it have to do with Delta Lake and Apache Iceberg???
“Delta UniForm takes advantage of the fact that Delta Lake, Iceberg, and Hudi are all built on Apache Parquet data files. Under the hood, Delta UniForm works by automatically generating the metadata for Iceberg and Hudi alongside Delta Lake - all against a single copy of the Parquet data.” - Databricks
Well that makes sense on the surface don’t it? One way to beat your opponent is to put on a mask and make yourself look like their friend? Classic trojan horse. Just saying.

We will use the Backblaze Hard Drive failure dataset.

Let’s see how easy and simple it is to create a UniForm Delta Lake table.

Not bad eh? Just a few extra Table Properties indicating we want Iceberg compatibly. So can we read this table as both Iceberg AND Delta from Spark?
Let’s insert some data.

Now let’s see if we read the table two ways.

I mean on the surface it appears to work.

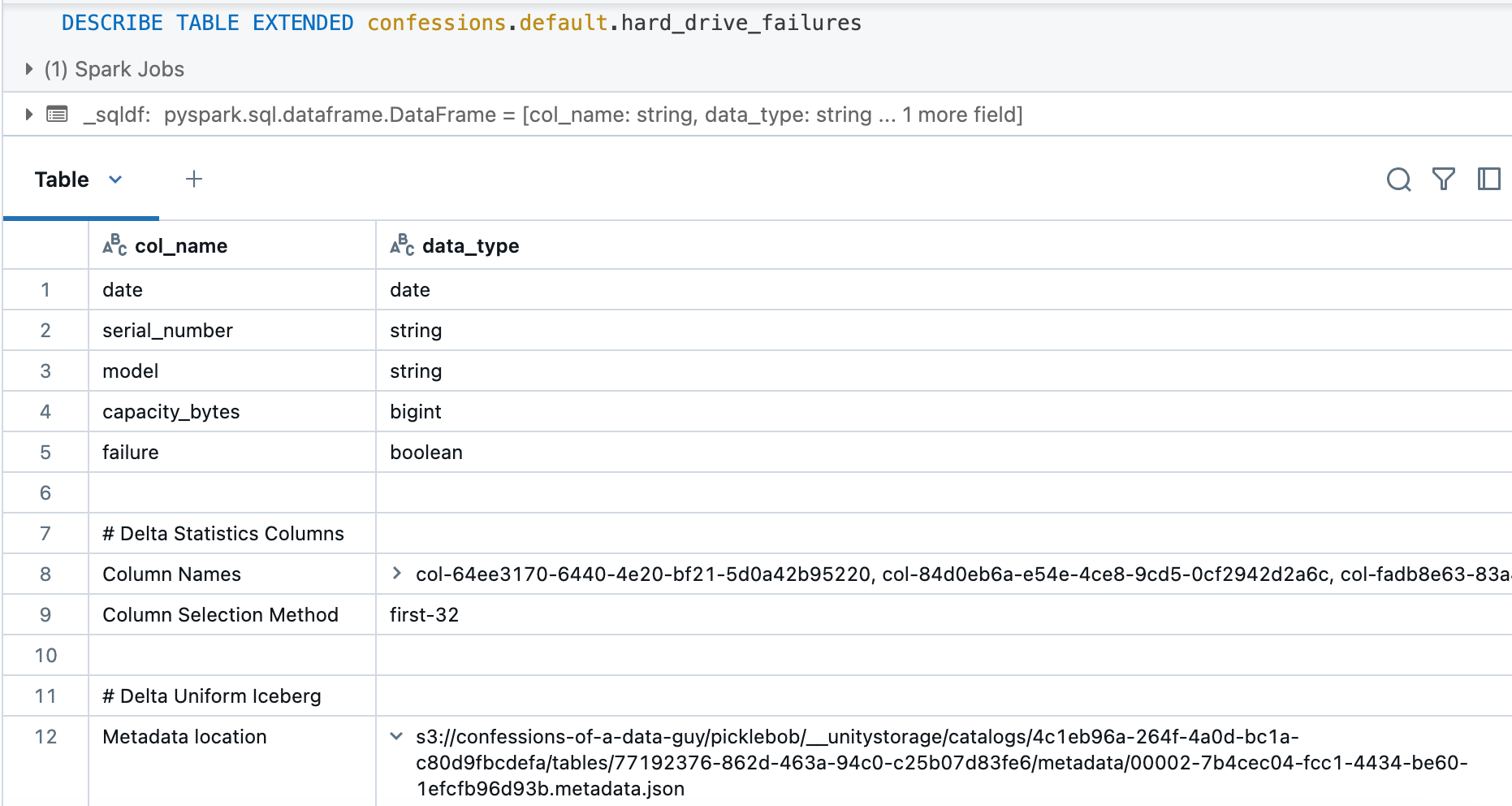
I suppose the real test would be if we can read the Delta UniForm table as Iceberg with something like Polars maybe. From everything I’ve read we need to find the meta.json file for Iceberg, which we can get by running DESCRIBE TABLE EXTENDED on our UniForm Delta table.
Below you can see the s3 path of the Iceberg meta.json
Well … look at that. Didn’t expect that to work the first time that’s for sure.
All I had to do was install polars and pyicberg, set the location of our Delta Uniform Iceberg meta.json file and we are off to the races with any sort of Apache Iceberg reader thinking it’s eating a Iceberg table when in fact it’s just been tricked.

This does make me wonder something important.
If you were an Apache Iceberg fanatic, for whatever reason, why wouldn’t use just use Delta Uniform to pretend store Iceberg tables as Delta Uniform???
You get the best of both world out of the box. You can, depending on your use case and client, read Delta or Iceberg. I mean it seems like a no brainer to me.
I’m curious, can we WRITE to our UniForm table like it’s an Iceberg table with Spark?
This would make Uniform truly a nice slice of bread with a slab of butter on it, would it not?
Well, look at that!

You can see I read the table as Iceberg before and after appending more records and the count went up. Must be working!
Note on Unity Catalog.
It’s probably because I don’t know what I’m doing, but I tried various ways to connect an Iceberg client (pyiceberg) to my Unity Catalog endpoint for Iceberg for WRITE support, but I couldn’t make it work.

Unity Catalog does indeed provide a Icerberg endpoint, so in theory it should work, mine did not. I imagine it has something to do with credentials.
I honestly didn’t feel like fighting it. As long as I have read and write support with Spark, and read support for Iceberg via Uniform for things like Polars … than I don’t really need to pyiceberg (which would give me write support in theory for NON-Spark workloads).
Also, when reading the docs for UniForm, I ran across a line that said Iceberg client support for write is not available. Which, again, we say we have write support with “Iceberg” via Spark, so whatever.

Thoughts
I do find Delta Uniform very enticing indeed, it’s wonderful that you may be able to persuade those filthy Iceberg lovers just to slide on over to Databricks and eat their fill of Iceberg when they are really swallowing Delta Lake.
I do enjoy seeing this sort of work done by the Databricks and Delta Lake folk, they are really trying to make the storage format wars obsolete with this type of development. I mean they didn’t HAVE to put the time and effort into doing this.
Yet another reason I choose Delta Lake, clearly the folks behind the development of this are engaged and thinking ahead about how to make our lives easier.
Ingenious, if you ask me.