

AWS S3 Tables?! The Iceberg Cometh.
weep moan, wail all ye Databricks and Snowflake worshipers


Well, what is that old saying? Better late than never? Something like that. Weep, howl, and moan all ye Databricks and Snowflake padiwans, what you have greatly feared has come down upon you with a heavy hand.
I can just see all the meetings being called and pats on the back with “It’s going to be ok,” happening right now inside Databricks and Snowflake conference rooms. I can almost taste the tears running down the faces of those angry Product Managers, those wicked Sales people asking the hyped-up Marketing group how to respond to this most expected, or unexpected, entry into the Lake House world.
I’m pretty sure a few overworked Databricks and Snowflake employees woke up with sweats and nightmares last night, with this headline running like a raging lion through their minds.

Amazon S3 Tables
Ok, enough storytelling, I can’t help it. At the most recent aws:reinvent, aka a few days ago, there was an unsurprising announcement that will most likely have a large impact on the Data World at large … maybe.
What is the hoopla about Amazon’s release of S3 Tables? What are they? What do we care??
“Amazon S3 Tables deliver the first cloud object store with built-in Apache Iceberg support, and the easiest way to store tabular data at scale. S3 Tables are specifically optimized for analytics workloads
…
Table buckets are the third type of S3 bucket, taking their place alongside the existing general purpose and directory buckets. You can think of a table bucket as an analytics warehouse that can store Iceberg tables…”
Ok, so this might require a little background for those uninitiated Lake House virg… I’m mean newbies. A little background.
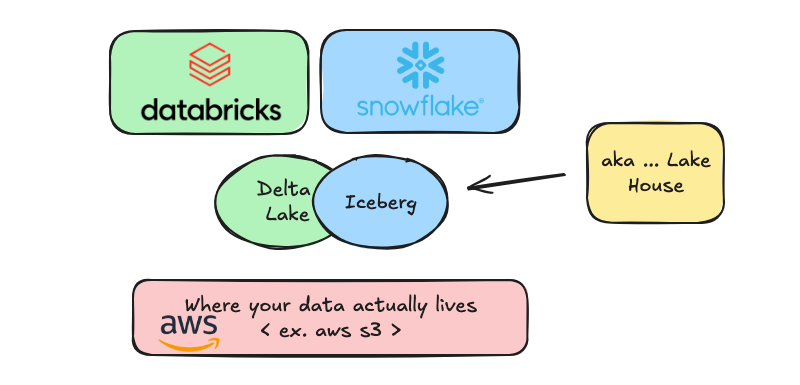
Let’s talk some backstory here, and set the stage.
We will indeed take time today to give these new S3 Tables a try, with code, but let’s first just give ourselves a chance to think theoretically about these new S3 Tables, and try to cut through all the hype and marketing buzz to the truth of the matter.
Databricks and Snowflake dominate the Lake House space.
Databricks and Snowflake struck the almost fatal blow to AWS tools like EMR, Glue, etc.
There is a TON of money to be made in the Lake House space … after all, it is the new Data Warehouse.
Only a fool wouldn’t try to dominate and have their fingers in the as much of the Lake House space as possible.
We cannot think of AWS S3 Tables in a vacuum, because they don’t exist in a vacuum, nor were the designed without context. The Lake House as we know it today is seen as a conglomeration of tools and tech that fit together like a puzzle to provide end users a one-stop shop for their Data Platform needs.

When you read the marketing material put out by AWS on these new S3 Tables you will notice what is mentioned at the very top, in the same or proceeding sentences. Other services of course.

They (AWS) were clearly falling behind in the data race, or at least in “controlling” the race to perfect Lake House system. Sure, they still had a piece of the underlying pie, with much of the compute and storage still running inside AWS, but the more time was going by, the more irrelevant they were becoming.
What would stop AWS or Snowflake from providing cheaper compute and storage seamlessly to their customers if they so choose? Nothing.
In fact, besides the Platform Engineers and System Admins, the day-to-day user of Snowflake or Databricks playing around in a Notebook, God forbid, or SQL, wouldn’t even know AWS was all those layers down the stack, back there in the shadows.
The truth is AWS needs, and wants, to get in on the Lake House action. They want you to use AWS EMR. But why would you when you can go over to Databricks and clickety click have Delta Lake and Compute at your finger tips?
This is where AWS S3 Tables come into play. In theory, AWS is now providing you the ability to have a single one-stop shop Lake House experience using their tools, keyword, in theory.
Is it too late? Can AWS even begin to compete with Snowflake and Databricks and their beautifully and well-crafted Lake House offerings?
A word on Iceberg vs Delta Lake.
I know a lot of people in the Data World, who have a vested interest of course, have been trying to downplay the silent war being ragged behind the scenes to be THEE Lake House format winner.
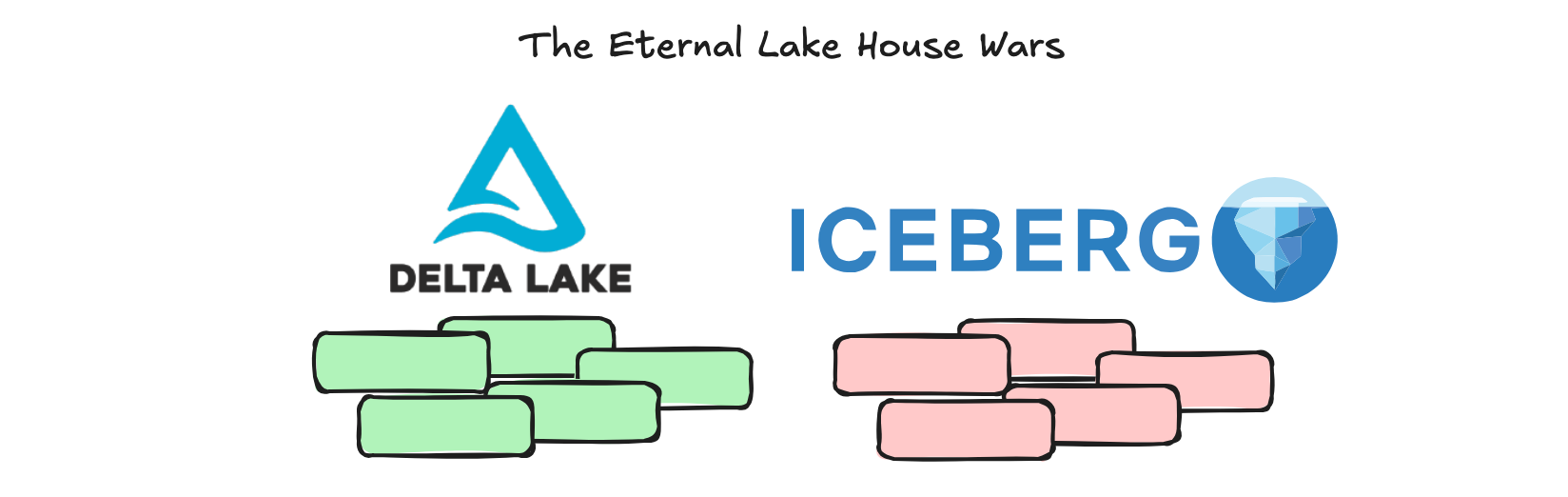
Those are Apache Iceberg and Delta Lake. Now, we don’t have time to dive too much into this, but it was probably a surprise to some that AWS S3 Tables chose Iceberg as their default format.
This is a confusing and complicated war. Databricks more or less drives Delta Lake and it’s at the core of their product. They recently bought Tabular and moved to try and take over Apache Iceberg, more or less.
Also, they’ve been pushing UniForm and other tools to make the storage format (between Iceberg and Delta Lake) sorta pointless, kinda a way of hedging their bets.
Clearly AWS using Iceberg was a sort of jab in the side of Databricks, showing them that hey, AWS still has some fight left in them, and they are willing to play dirty.
Don’t think that AWS S3 Tables being Iceberg-ish is a death knell for Delta Lake, that battle is far from over. Also, there IS a Lake House storage format war going on no matter people tell you. People like one or the other, and most of the tools either integrate better with one or the other. It is a war.
IMPORTANT NOTE - while new news is always exciting, remember that S3 Tables are late to the game. Databricks and Snowflake have been building Lake House platforms, and getting very good at it, for some time. Being the underdog at the back of the pack comes with its own set of problems, even if you are AWS.
Introduction to S3 Tables on AWS.
Ok, we are getting to the point where we need to turn the ship back to the star of the show, AWS S3 Tables. Now that we have set the historical table, with both sides beating their plowshares into swords, let’s try to actually look at this new Lake House format in code.
The idea here isn’t to become experts, but to simply kick at the tires and poke at the holes, and in so doing, be able to better understand for ourselves the REAL LIFE implications of S3 Tables.
First, let’s simply start with the basics of AWS S3 Tables that we can get from all the blogs and docs on AWS. We will move quick, strap in.
S3 Tables are stored in a new bucket type: a table bucket.
“stores tables as subresources” - one would surmise from this that you can store multiple S3 Tables in a single “Table Bucket.”
Table buckets support storing tables in the Apache Iceberg format.
do you think this will include other options in the future?
You can use SQL statements to query your tables.
of course, you rabble of SQL junkies.
You can use any tool that has a “query engines that support Iceberg.”
which is a good number of tools, both distributed and not.
To optimize your tables for querying, S3 continuously performs automatic maintenance operations,I mean really … that’s it.
You can manage access for both table buckets and individual tables with AWS Identity and Access Management (IAM).
This is what people must realize with this S3 Tables announcement, it is cool, yes, but all it is, is AWS joining the ranks of what Databricks and Snowflake have been offering you for years on end.
They are simply adding the missing Lake House piece to their stack, and an integrated storage layer that works seamlessly inside their environment, targeting that one-stop Lake House platform idea.

S3 Tables in Code.
Ok, let’s learn a little more about S3 Tables by trying them out. I think we should do the following.
create Table Bucket with CLI
create S3 Table
INSERT data into our S3 Table
Query our S3 Table with …
PolarsDaftSpark
DuckDB
Then we can review what we saw, learned, and maybe make some more conjectures about the future of S3 Tables based on the results.
On with the show.
First, we must upgrade our aws CLI. If you have an older version if you try to run any commands, you get the following error …
% aws s3tables
>> aws: error: argument command: Invalid choice, valid choices are:
...Run the following to upgrade.
% curl "https://awscli.amazonaws.com/AWSCLIV2.pkg" -o "AWSCLIV2.pkg"
sudo installer -pkg AWSCLIV2.pkg -target /
>> installer: The upgrade was successful.Creating a Table Bucket in S3.
First, we must create what AWS calls a Table Bucket, this is a new kind of S3 bucket specifically for S3 Tables.

“The console automatically integrates your table buckets with AWS analytics services. If you create your first table bucket programatically by using the AWS Command Line Interface, AWS SDKs, or REST API, you must manually complete the AWS analytics services integration.” ← This is called $money$ people, pay attention!
Let’s do this thing.

Ok, easy enough I think. We should now be able to call and get the details of the Table Bucket.

Next, we should try to create an empty S3 Table in this bucket.
This is where things get funny … and disappointing.
We knew there would be a few hitches in the workflow, no surprises there, and when you are a S3 Table newbie, and are at that point of, “Hey, I would like to read and write to a new S3 Table, how do I do it?” It isn’t going to be easy.
If you read the official blog, they use Spark, EMR that is, with a bunch of configs. See below … they sort of “gloss over” the Spark work required to connect and create the table.

If you poke around in the docs, you see this example that shows you what you must do. It isn’t fun or “seamless,” and exemplifies the entire reason EMR lost the game to Databricks and Snowflake.
It’s a bunch of crap that MOST average Databricks or Snowflake users NEVER have to do to work with their Lake House data. This is the achilles heel of S3 Tables.
Here are some snippets from AWS Docs.
create Table Bucket, setup security etc.
create EMR cluster
pass a bunch of configs
set up config file
SSH into machine
pass more configs to start Spark etc.


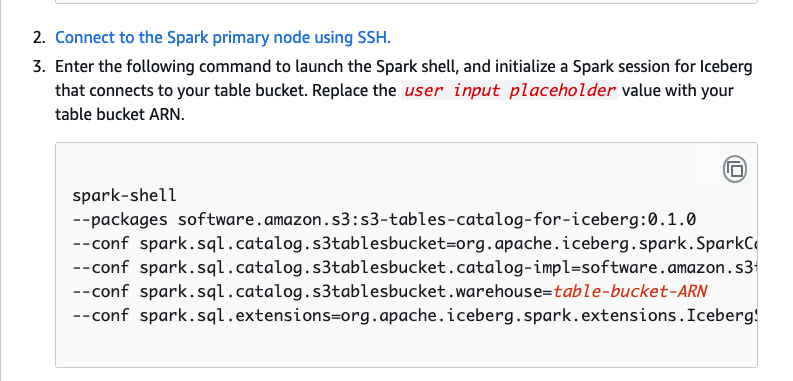
I mean honestly, these AWS people never learn their lesson apparently. They want us to create an EMR cluster, make a config, SSH into a machine, run Spark shell with a bunch of configs.
Look, I’ve spent my fair share of time 14 years ago doing this kind of crap! The world has simply moved on. You’re average Data person has no desire to jump through these hoops. They will not.
They will simply use Databricks or Snowflake.
The saga of creating a S3 Table continues.
I was so sure they had made a CLI command, ANYTHING, that would help us easily make an S3 Table without using a flipping EMR cluster or Spark, but as I dug into the docs, I found this page.

To the casual observer, this seems to indicate that to use “open source query engines” … aka NOT Glue, EMR, Athena, and the rest … we must use “Amazon S3 Table Catalog for Apache Iceberg client.”
And it lists the following engines that are supported …
Apache Spark
Great, does this mean I cannot use Daft, Polars, DuckDB, or anything else that already supports Iceberg to create and write to AWS S3 buckets?? I don’t know, on the surface, it seems so.
Look, I’m not an expert. I’m just an average engineer trying to understand the tool and use it using the available documentation within a reasonable timeframe.
NOTE:
This seems to go well with my earlier theme that AWS is doing this whole S3 Tables thing because they are trying to compete in the world of a single-stop shop Lake House data platform … that doesn’t really exist with their products today.
They WANT you to use S3 Tables in the context of Glue, Athena, EMR, etc.
Ok, if that is the case, I don’t want to spend EMR money, let’s see if we can get this to work on a tiny EC2 instance. I need those AWS hobbits to send this poor by a bunch of credits so I can keep doing the Lord’s work out here in the hinterlands.

We are going to use a t2.small, a beast, running Ubuntu for the OS. After the setup and waiting, we can easily SSH into our little train that could.


Next, we need to get Apache Spark installed.

And it’s working.

Now the fun part, let’s see if we can get the commands right to start Spark with the ability to talk to AWS S3 Tables. Note in the below table the AWS ARN pointing to our previously created Table Bucket.
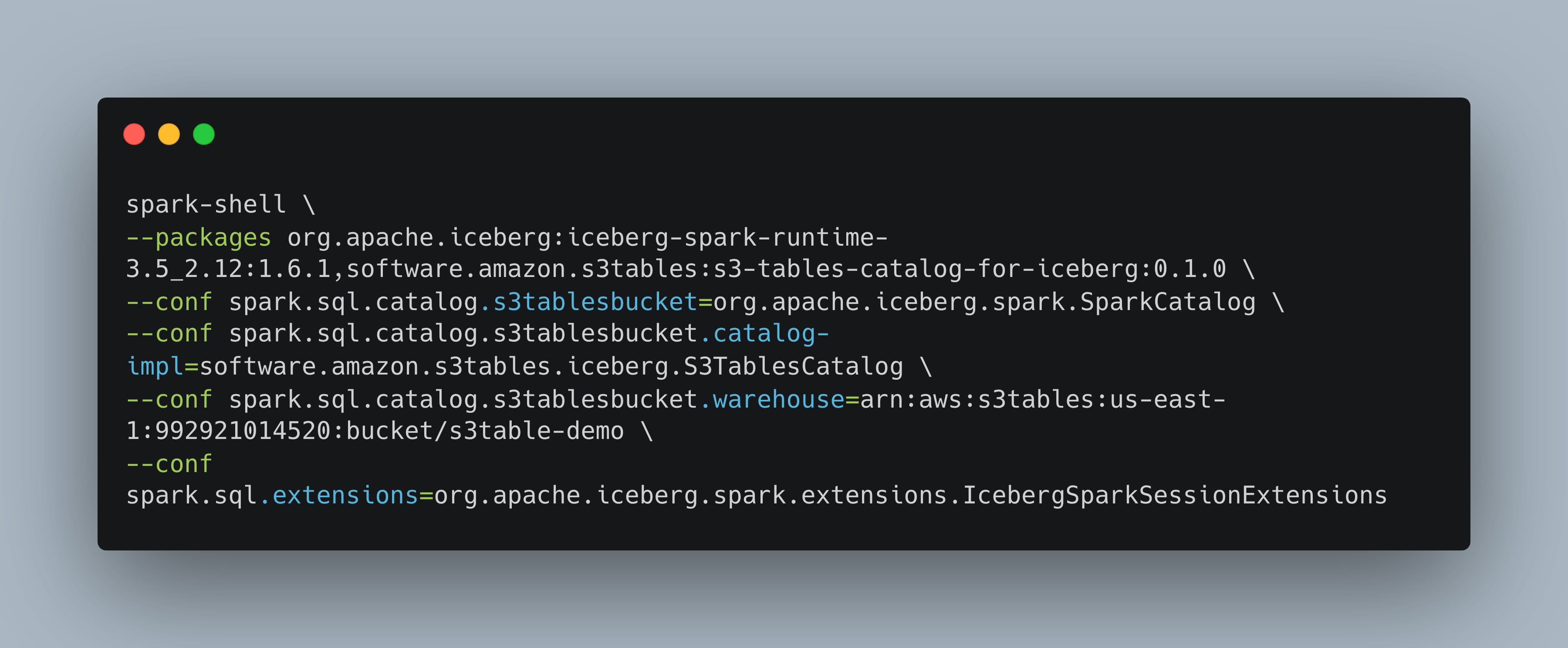
It appears Spark started fine, now, following their documentation let’s try to create a namespace for our table.

It’s looking like it almost worked, but couldn’t find credentials, in fact, I didn’t attach a policy or put keys on this machine, so let me fix that by adding credentials to the environment.
Ok, no errors this time after putting creds on the EC2. Let’s go ahead and create a S3 Table.

Now, if we slide on over to my AWS account and check the Table Bucket, we can actually see that new S3 Table we just created.

So it working well. Let’s just insert some sample data to say we did.

And of course, let’s do a simple query to ensure we can access the data we just inserted.

I guess that was surprisingly easy, aside from the fact I had to set up my own Spark EC2 Instance and piddle with the settings and configs to get things talking, but nothing we haven’t been doing with Spark for the last 10 years.
I’m glad we are done with that, let’s circle back in a little bit and talk about what we learned in relation to S3 Tables and the impact and comparison to current tooling, but first, let’s mention pricing.
Pricing.
I think it’s important to at least mention the pricing of S3 Tables in passing, it’s not going to be cheap, s3 really isn’t, so that’s no surprise.
As far as I can tell it’s broken down 3 ways.
S3 Tables storage pricing
S3 Tables requests pricing
S3 Tables maintenance pricing


You can go ahead and do the math yourselves, but just note, that most real-life Lake Houses storing hundreds of terabytes of data+, these costs will add up quickly.
Boiling it all down to something we can take a bite out of.
Yikes, that was a lot to take in for what we are trying to cover. I hope you at least now can cut through the hype that will be pouring out into the interwebs over the next weeks and months over this release.
But, we need to try to bring it all together here at the end, now that we’ve tried to understand S3 Tables at both a theoretical level, and actually wrote some code!
I might just resort to a good old-fashioned list of things we’ve learned.
AWS S3 Tables are made to be used and integrated with AWS Products like Glue, Athena, EMR, etc.
S3 Tables are just an AWS answer to what Databricks has done with Delta Lake etc.
S3 Tables lack general query engine and interaction support outside Apache Spark.
S3 Tables have a higher learning curve than just “S3,” this will throw a lot of people off and surprise them.
Lake Houses are taking over the Data World and are becoming the defacto standard, replacing the Data Warehouse, and AWS making S3 Tables prove that.
This will deepen the already large divide in Lake House storage format wars, between Apache Iceberg and Delta Lake.
Managed S3 Tables with auto maintenance (per the pricing) appears to be a very expensive way to run a Lake House.
AWS still has some serious continuity and seamless integration problems with the one-stop-shop Lake House platform they are trying to build with the addition of S3 tables.
I’m sure this is a very happy day for all those organizations who are still building their Lake House on AWS without Databricks and Snowflake, this is a real third option for those still using …
EMR
Athena
Glue
… on a daily basis in their environments.
My hope would be that S3 Tables from AWS would be a net positive to the Data Community at large. Having another big player enter this Lake House space will force Databricks and Snowflake to work even harder and provide best-in-class solutions.
My biggest fear for AWS is that they will leave S3 Tables in their current state, and because of that, they will slowly die the same death as EMR and Glue.
They feel a little raw and not so user-friendly yet. It would be a different story if they had released a bunch of docs showing how to build and load data to S3 Tables with Python, boto3, the aws CLI etc.
There is only a small cadre of users willing to dive into EMR full bore to take advantage of S3 Tables, it’s going to be the people already using EMR in the first place.
Who’s going to use Databricks and write to a S3 Table? No one. Doesn’t make sense in 99% of use cases. Also, I’m not looking forward to the continued fighting between Iceberg and Delta Lake zealots (of which I am one).
It would be nice for everyone to converge onto a single approach, but that clearly isn’t going to happen anytime soon, even with all the promises of abstracting Iceberg and Delta Lake away altogether.
I think at this point we’ve said enough, since S3 Tables are so new, I’m sure we can expect to hear and see a lot more about them in the coming weeks and probably all of 2025. Hopefully, you leave us here with a more robust and realistic understanding of S3 Tables.
Please, let us know in the comments below your thoughts on all this! What do you think of them? Iceberg vs Delta Lake, what’s going to happen? What are your thoughts on AWS taking on Databricks and Snowflake with this move?
Excellent breakdown
Creating namespace was successful...
spark.sql(" CREATE NAMESPACE IF NOT EXISTS s3tablesbucket.test_namespace")
But when I create table...
spark.sql(" CREATE TABLE IF NOT EXISTS s3tablesbucket.test_namespace.test_table( id INT, name STRING, value INT ) USING iceberg")
getting below error...
py4j.protocol.Py4JJavaError: An error occurred while calling o34.sql.
: java.lang.NoClassDefFoundError: software/amazon/awssdk/services/s3/model/S3Exception
at software.amazon.s3tables.iceberg.S3TablesCatalogOperations.initializeFileIO(S3TablesCatalogOperations.java:111)
Could u pls suggest?