

Data Quality with Databricks Labs new DQX tool.
... better be good ...


I recently saw something pop into my LinkedIn feed that made me pee and scream simultaneously. An announcement from Databricks Labs about a Data Quality tool specifically designed for Spark PySpark Dataframes.
Dang. Been a long time coming if you ask me.
Data Quality has been one of those topics that has come and gone within the Data Community like clockwork over the last few years. Yet, it has suffered from a lack of various easy-to-use and open-source tooling. Of course, there is Soda Core and Great Expectations, which I have checked out before.
Anywho, back to the exciting news at hand.

“We’re thrilled to announce the release of DQX, Databricks new Python-based Data Quality framework designed for validating the quality of PySpark DataFrames.
DQX is your go-to tool for proactive data validation, ensuring bad data never enters the system. Whether you’re working with batch or streaming pipelines, DQX helps maintain the integrity and reliability of your data.” - Databricks Labs
Data Quality + PySpark + Databricks.
I’m not sure why Data Quality hasn’t caught on more inside the Data Engineering community, oh wait, it’s because there just isn’t easy and seamless solutions. Funny, you would think withs something as popular as Spark that there would be about 15 solutions to choose from.
I mean how in the world could people not love things like pydeequ?

Or Great Expectations? I mean who doesn’t want to write JSON like this as just one tiny piece of greater system of code trying to implement DQ?

I hope you can hear the sarcasm dripping off my fingers, because it is.
“The problem with most Data Quality tools up this point has been the overhead of complexity on all levels to implement those tools in a production worthy tools. If the thing helping you is more complicated than the thing its helping … adoption will always be abysmal.” - Me
We are going to find out of Databricks Labs has finally delivered something simple, elegant, and easy to use. Here we sit like little birdies with our mouth open waiting for our benevolent Mother Databricks to drop a juicy Data Quality worm in our mouth.
Diving into DQX from Databricks Labs.
Sorry it took me so long to get this point, had to get that all off my chest. Definitely not bitter or anything. Right now all have to go off of is the DQX GitHub page, so we will start there and see if we can implement some Data Quality checks inside a Databricks Workspace etc, and see if their promises are true.

What does DQX have to say about itself, hopefully we can get a sense of what we are in for.
Invalid data can be quarantined to make sure bad data is never written to the output.
Support for Spark Batch and Streaming including DLT (Delta Live Tables).
Different reactions on failed checks, e.g. drop, mark, or quarantine invalid data.
Support for check levels: warning (mark) or errors (mark and don't propagate the rows).
Support for quality rules at row and column level.
Profiling and generation of data quality rules candidates.
Checks definition as code or config.
Validation summary and data quality dashboard for identifying and tracking data quality issues.
I see both things I expect in that list, that are pretty much the status quo of any DQ tool, things that make me nervous (definition as code or config), and new things (Data Quality Dashboard).
We can only eat an elephant one bit a time, so let’s just try to simply use DQX to do some Data Quality checks on a PySpark pipeline and learn and try things as we go.
Trying out DQX for PySpark Data Quality.
Let’s get cracking. We have multiple ways of installing dqx as a tool, both from pip or inside a Databricks Workspace etc.
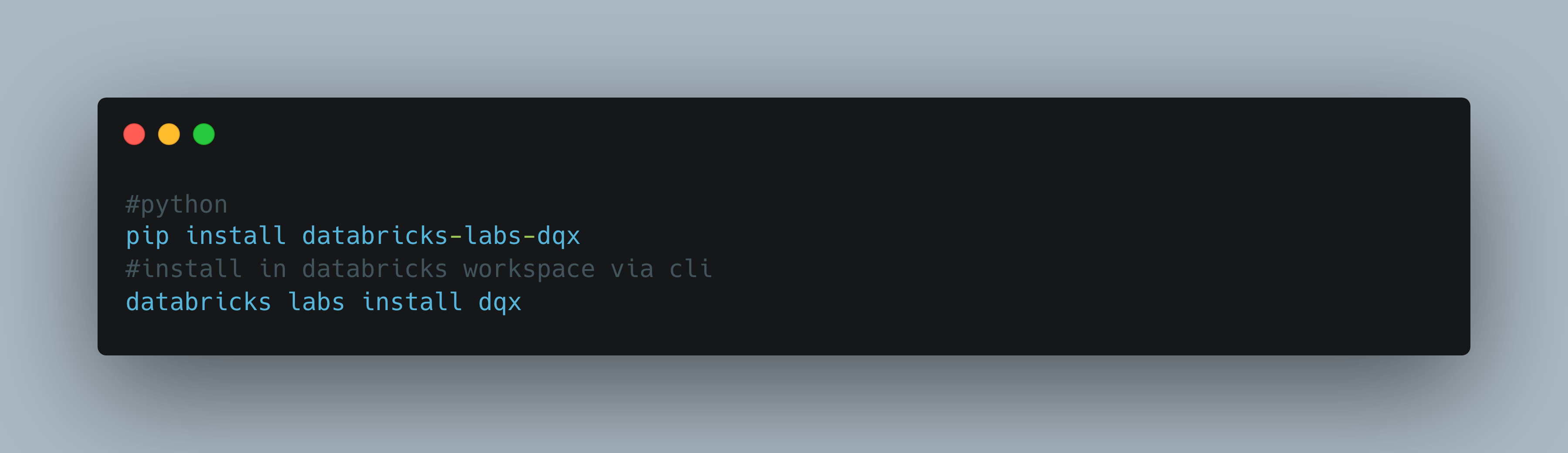
Note: if you decide to install DQX inside a Databricks Workspace with the CLI the following things will happen. Do this at your own risk and watch your wallet.
The cli command will install the following components in the workspace:
- A Python wheel file with the library packaged.
- DQX configuration file ('config.yml').
- Profiling workflow for generating quality rule candidates.
- Quality dashboard for monitoring to display information about the data quality issues.The one that has me wondering is the Dashboard, sounds nice but possible expensive? I wish more detail would have been provided about that.
Let’s just pip install DQX in a Notebook inside my Databricks account and play around ourselves. What I want to do is sorta treat DQX like just another standalone Data Quality tool (similar to GE or Soda), and not really take the approach of “full on Workspace install 100% Databricks tool.)
I tried to visualize how DQX works generally and what it provides.
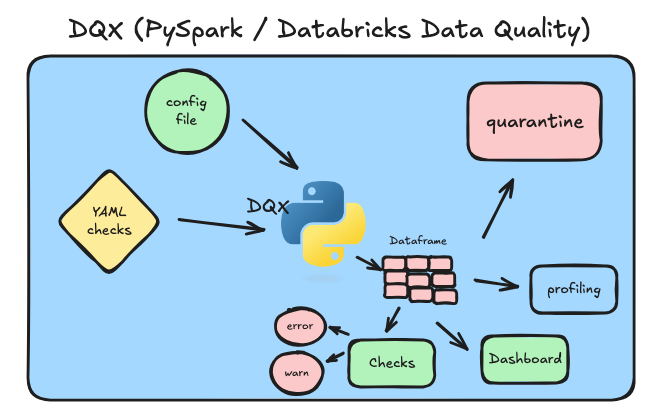
Generally DQX will do these following things for you …
1. Data profiling and generate quality rule candidates with stats
2. Ability to define more checks and validations as code or config
3. Set criticality level and quarantine bad data
4. Works in a batch of streaming system
5. Provide a DashboardIt honestly reminds me a lot of the tools that have come in the past, except it seems less complicated, less overhead, less config and more integrated with Spark (duh, since it was designed for PySpark).
DQX in Code.
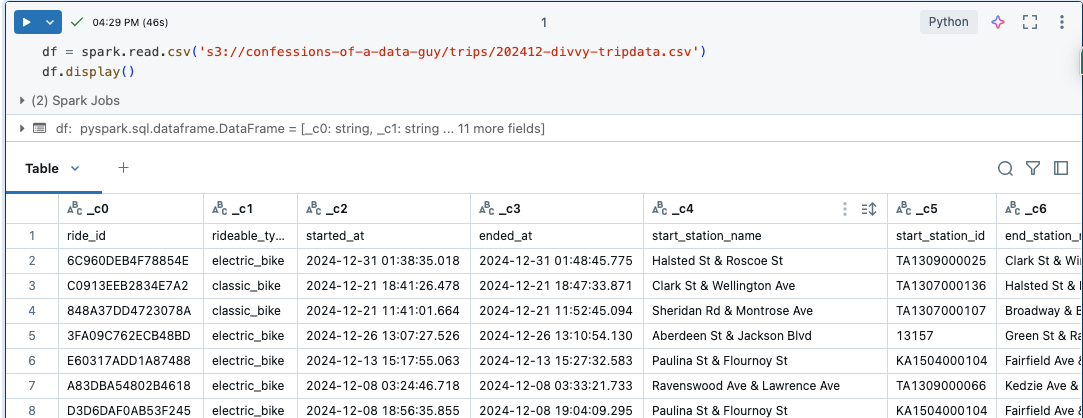
Code time. We are going to use the open source Divvy Bike Trip dataset as our sample data to mess around with. It looks like this. FYI, all this code I wrote for this testing is on GitHub.
Here is the basic code Databricks gives to load up a Dataframe and get the basic default stats.
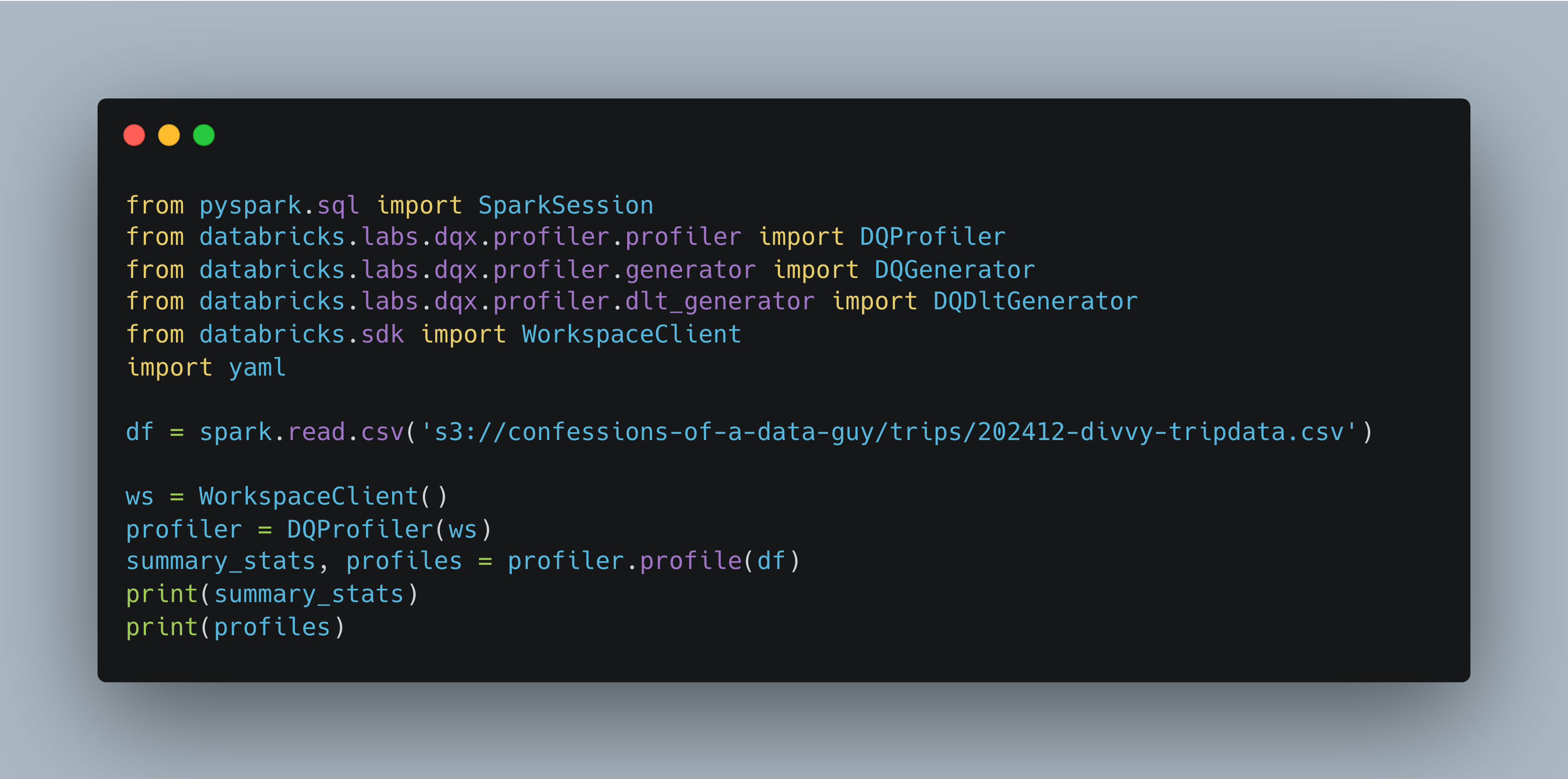
Here are the “summary stats”

Here is the “profiles”

The next part is actually pretty cool. We can take the “profiles” that describe our data (DataFrame), and generate default validation checks based on that.
Here is a sample of the checks that were produced.
- check:
arguments:
col_name: _c0
function: is_not_null
criticality: error
name: _c0_is_null
- check:
arguments:
col_name: _c1
function: is_not_null
criticality: error
name: _c1_is_null
- check:
arguments:
allowed:
- electric_bike
- classic_bike
- rideable_type
col_name: _c1
function: value_is_in_list
criticality: error
name: _c1_other_value
- check:
arguments:
col_name: _c2
function: is_not_null
criticality: error
name: _c2_is_nullNot bad! If you look close it knows if a column should be null or not, it also for example if a column should have values in a pre-defined list!
Not bad for doing no work out of the box. This might be a great first option for a Lake House architecture that has a ton of data tables (sets) and you need to get some basic DQ checks off the ground.
Also, of course we could write our own checks in a `YAML` file and then load that file in Python.

But, something I like even better is the ability to define checks “in-code.”

What’s going on here? Well, an easy way to define PySpark DataFrame data quality checks is what is happening! You can see different kind of checks going on.
checking multiple columns at one for …. “is_not_null”
aka we could check whatever we want
defining a specific check for a single column
defining checks to see if a value is in a list, etc
you can split out the results of the check into a different DataFrame
this would allow flexible approach to quarantine bad data
just add the check results in a column on the DataFrame
Dang, pretty easy and nice to use.
Wait … like late night TV … there is MORE!
Just like that like night preacher on the tube screaming at you, there is always more. I couldn’t believe some of the genius additions they made to DQX.
SQL for data quality checks!!! Say I wanted to make sure the ride start times were before the ride end times.
- criticality: "error"
check:
function: "sql_expression"
arguments:
expression: "ended_at > started_at"
msg: "ended_at is greater than started_at"I mean that right there is butter on the bread. I know all your SQL junkies are running for you keyboards as I type. Addicts.
As well, you can define custom checks with plain old Python. For example we might want to check that our rideable_bike column ends with “_bike” per our expected data outcomes.
import pyspark.sql.functions as F
from pyspark.sql import Column
from databricks.labs.dqx.col_functions import make_condition
def ends_with_foo(col_name: str) -> Column:
column = F.col(col_name)
return make_condition(column.endswith("_bike"), f"Column {col_name} ends with _bike", f"{col_name}_ends_with_bike")The sky is the limit for DQX checks on PySpark DataFrames in our Lake House, if you can imagine it, you can write it … even SQL.
You know what I like about DQX … it’s flipping simple to use. I really hope Databricks puts some effort into marketing this tool, it’s easy of use and implementation would pay back dividends for a lot of users.
But, they need to know it exists. I can imagine it’s only going to get better in the future.
I hope this quick preview of Databricks Labs DQX was enough to whet your whistle and get your mind and fingers moving. It did mine. Excited to dig into it more and put this little bugger to work!
Although Databricks community driven, is it possible to import this library natively in Microsoft Fabric notebooks or other notebooks?
Superbly written, as always. Can 100% relate on the first part 🤣