

Databricks Compute.
Examining the Inscrutable


I am certainly no master of the minutiae of Databricks compute, able to unwind the wound-up ball of string that leads us to where we are today. Yet DBUs matter in the world of the Lake House. It’s the difference between an angry CTO and a happy one.
For a more accurate, academic approach to Databricks compute, I recommend you follow and read Josue Bogran — the true master.
I will give you the 5-cent tour of Databricks compute, from the vantage point of someone who only half pays attention to the comings and goings of drop-down selections in the UI. Like Robin Hood, maybe we can dream of swooping in to steal some money back for ourselves.
Databricks Compute for the Uninitiated
For certain, there is a whole mad cadre of consultants who’ve built careers and large bank accounts simply by advising Databricks customers when to use what compute for what “thing.”
Makes a guy wonder. Where did I go wrong in life?
I run most of my Databricks Compute life with a strict set of simple principles that have served me well.
Never use All-Purpose clusters.
Job Clusters for all.
Fleet Clusters at large.
Serverless for quick hits.
I’ve yet to be fired, but you never know, never say never. My hero is Grug, and I follow those principles.
Finding the Amusing.
In a pragmatic sort of way, I’m always looking for a reason to laugh, you know, not take life and tech too seriously. When it comes to Databricks compute, you don’t have to go far to find a smile.
Say you are new to the whole gambit and simply Google “Databricks compute,” then click the first link that pops up. You will come straight to the main “Compute” page on Databricks.

Behold, what are the first things your eyes will feast on, and what will automatically get embedded into your subconscious brain? Serverless.
I would like to pontificate upon this more, but for lack of time, and fear of the ever-watchful Eye of Sauron watching over my every word, we will return to Serverless later.
Databricks Compute Options.
The academics among you may cringe and give some boring and bland list of compute options that will probably change next week, but I’m going to take a different tack. As always.
On a regular basis, I must remind people that not everything is a technical problem to solve, but more of a thought-provoking conundrum of choices.
Let’s actually review Databricks Compute by the options that show up in the UI!
Wow, who would have thought to do that? The UI is where most Databricks newbies get their digital feet wet. Below are the options when we click on the Compute button in Databricks.

First and foremost, you will actually see the most used options today, regardless of what the talking heads say. Funny enough, starting with the most expensive.
- All-purpose compute
- Job compute
- SQL WarehouseThe Big Three. Ignore the other stuff.
This is where the psychological warfare comes into play. The Orwellian marketing gambit. The Spice of the Intergalactic Cloud compute bills.
What don’t you see here? Serverless. Doesn’t show up here. Strange.
The other thing you will note is that Databricks is changing the wording of how compute is generally refered too, if you’ve been around more than 2 years, you will know this.
I’m not here to sit in judgment on the inner workings of the demi-god like Illuminati who run that company and pull the strings. I wouldn’t dare. You can make up your own mind.
Let me sum up the current state of affairs for you.
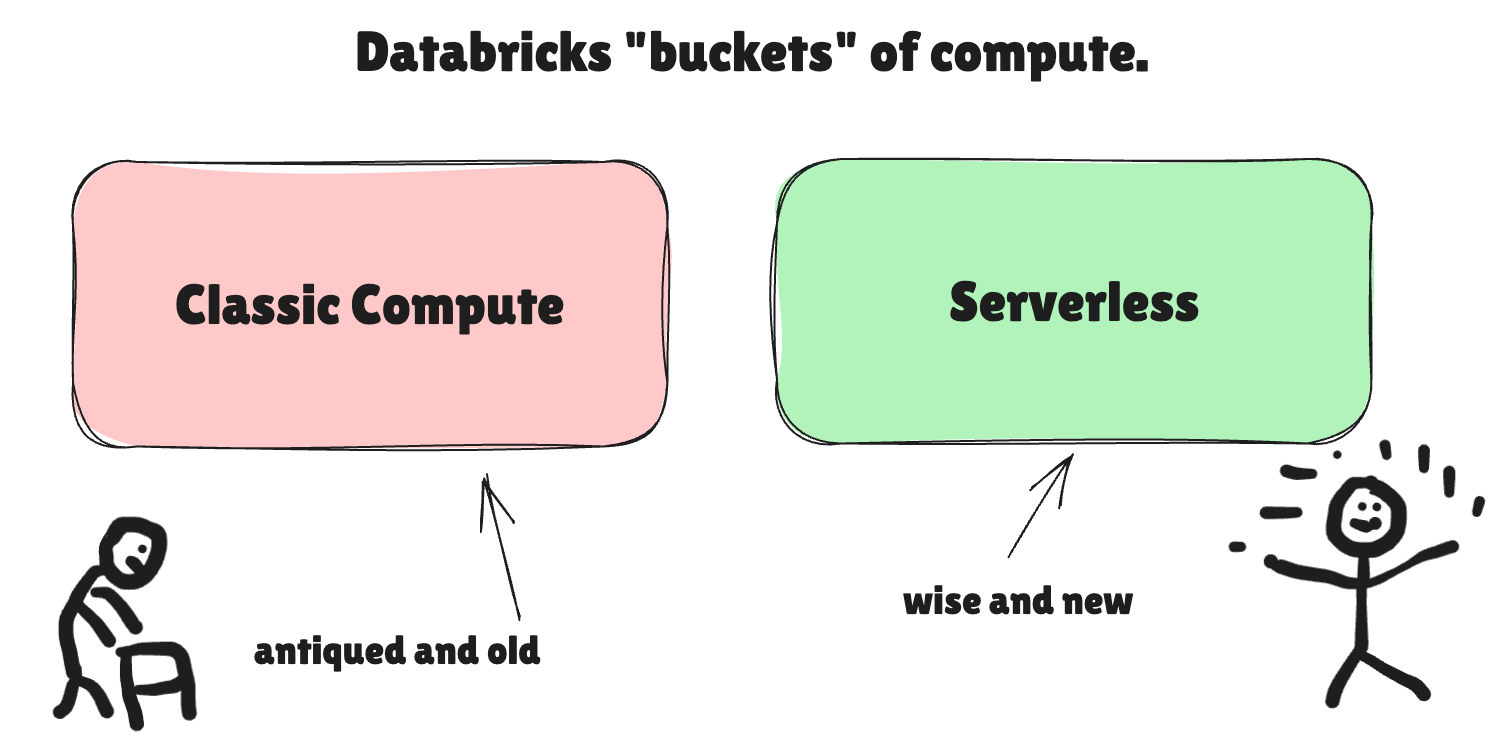
I ain’t making this stuff up, I’m just a corn-fed boy raised on a river. Databricks compute documentation refers to two overarching types of compute.
Basically, anything that isn’t a new-fangled serverless is Classic. Old. Mundane. Manual. Buggery.
More or less, Classic Compute options give you the ball — put me in, coach. You get to set the instance size, blah, blah, blah. You’re the captain of your own ship, either to crash on the shoals or smoothly sail to wherever those elves went in the west.
More funny.
If you simply Google, yet again, “all-purpose compute Databricks,” it seems the internet, or Databricks docs, have been scrubbed of an actual page(s) devoted specifically to this very expensive compute type.
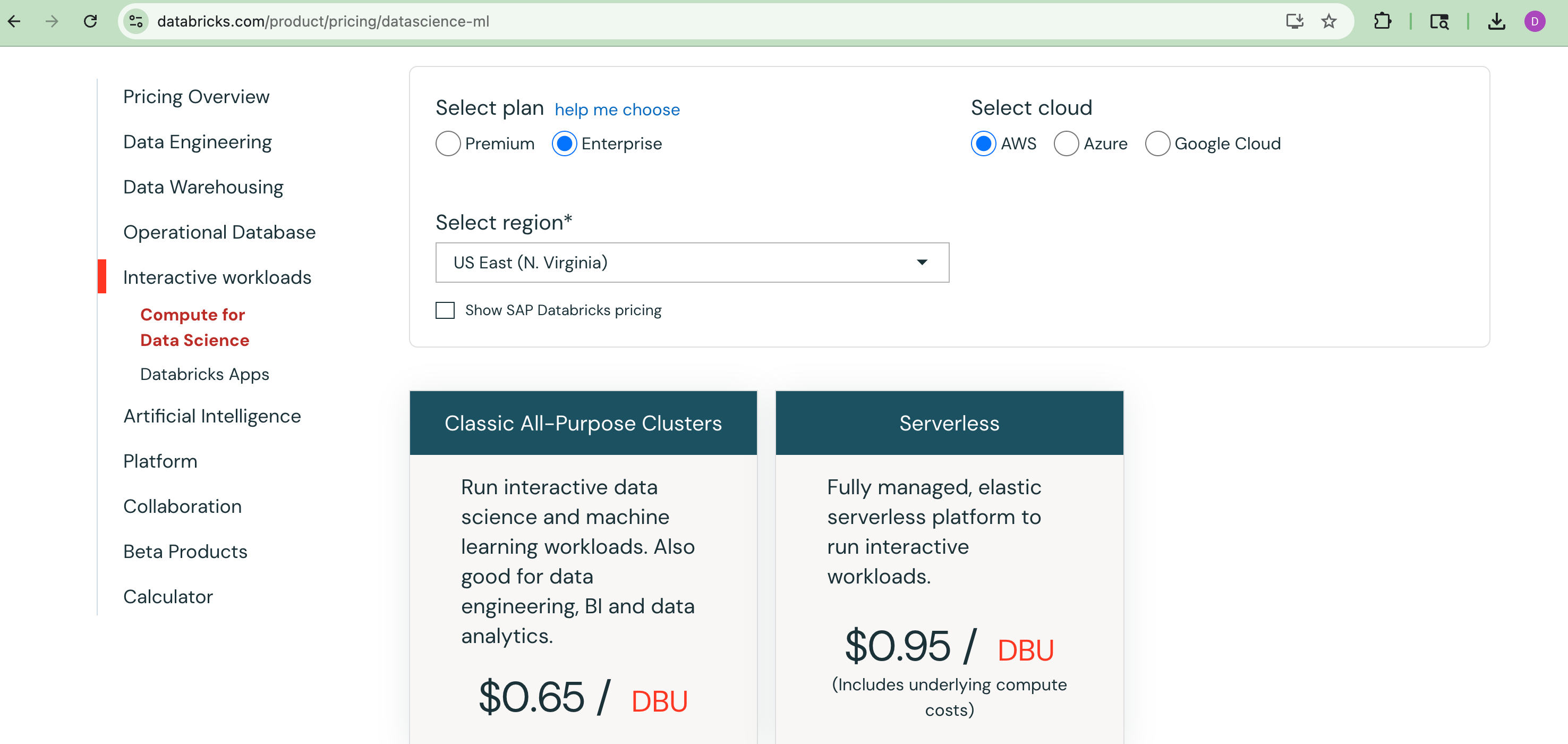
The ball of string has been tangled and woven into an intricate web of inscrutability. If we go to the pricing page, if you know anything about Serverless vs Jobs vs All Purpose, you can start to smell out the difference in pricing.
“Interactive workloads” here would be where that All Purpose compute that SHOWS UP IN THE UI AS THE FIRST OPTION, falls. Sometimes the left hand has a hard time keeping up with the right hand, if you catch my drift.

What is even funnier is that if you click on the “starting at $.40 per DBU” option, the next page shows our word we’ve been looking for: “Classic All-Purpose Clusters” at $.65 per DBU.
Generally, this means avoiding All Purpose Compute.
<< insert angry comment from a consultant who says having a single All Purpose Cluster used by multiple people is cheaper than a bunch of Jobs running helter-skelter. >>
Job Compute.
I mean, good Lord, if you go to the official Job Compute page on Databricks, you will find a list of Tasks and their corresponding recommended Compute type.
Let me help you read the table, Rita. It says SERVERLESS for everything.

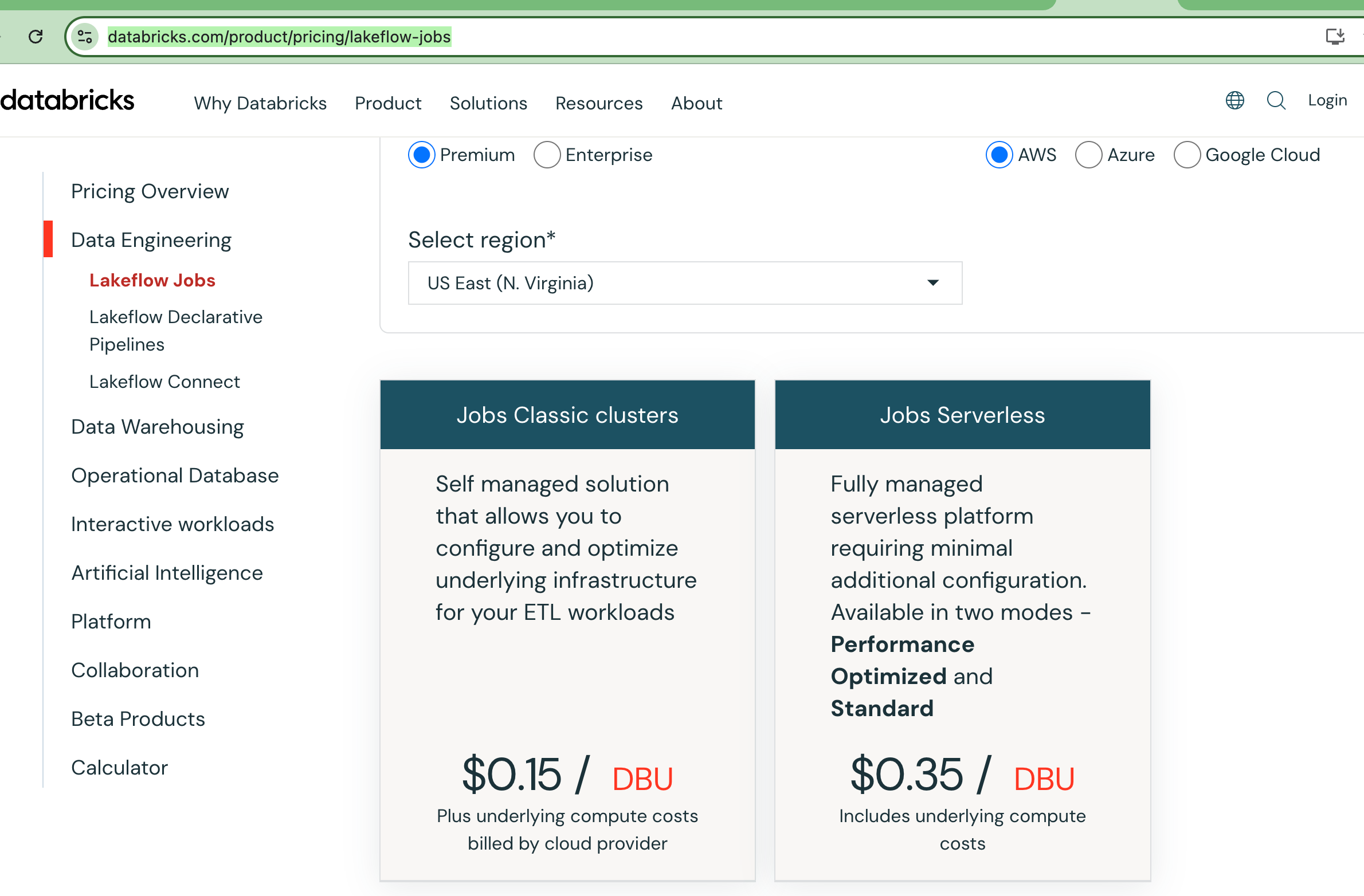
Well, if we scroll to the bottom, we can select Classic Jobs. Which is the bread and butter of a lot of compute today. Good ole’ Spark Submit.
There you are my old friend. You’ve been relegated to the past, shuffled off to the care home … classic … pun intended.
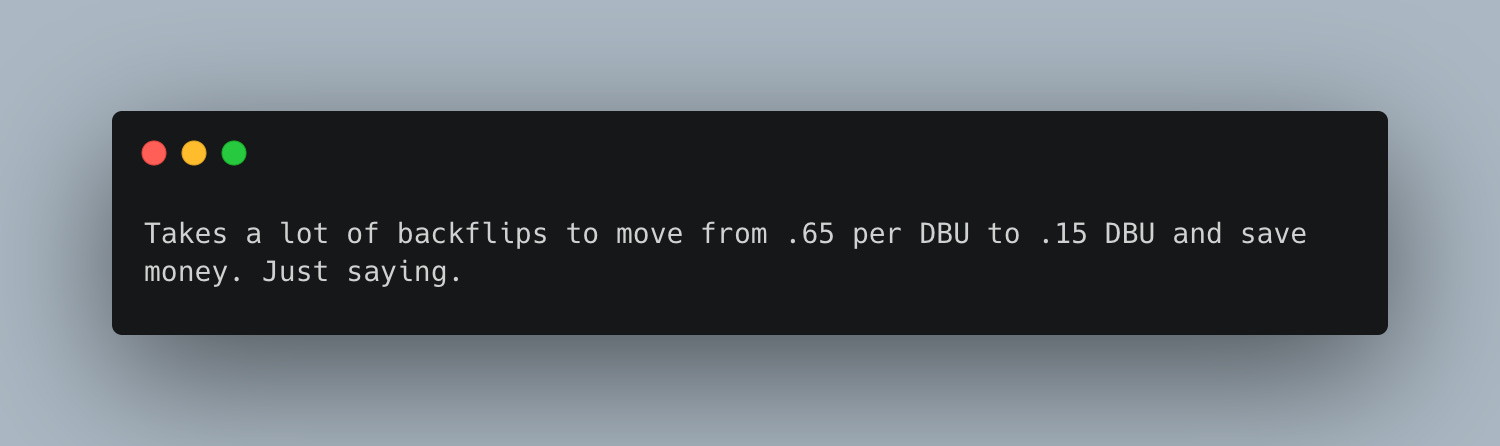
So strange, Serverless Jobs are recommended for pretty much everything on the list. Hey, I’ve got a bad memory. What was the cost of Classic Job compute vs Serverless Job compute pricing?
Serverless Jobs are twice as expensive.
They better be twice as fast for twice the cost eh.
Dang bruv. We ain’t even got to that SQL Warehouse compute we have in our original UI compute list from the Databricks UI. If you are now very curious, welcome to the club. What should you choose?
Jobs over All-Purpose
Use Serverless for “quick” or “short” compute needs
That’s all this Grug can give you. Other than that, you will simply have to test your workloads and figure it out yourself.
I suggest, again, you read and watch Josue talking more about Serverless Compute and the problems it solves.

Now that we’ve beaten the dead horse to death, let’s move on.
SQL Warehouse
If you remember from the previous screenshots, SQL Warehouse compute appears in the middle of the cost list.

Again, within that selection, you get three different options with very large swings in pricing. From $.22 - $.70 DBU.

What’s that you say? Huh? You want to know WHAT is a SQL Warehouse as compared to All-Purpose, Jobs, and the like? Oh, I’m sure Databricks Docs will tell us what a SQL Warehouse is.

Ok, I lied. They literally will NOT tell you what SQL Warehouse is, other than that you should use the Serverless option!!! LOL!!!!
Dang, I’m sorry they wouldn’t tell you what it is. Let me try.

If you were to ask Grug, he would simply say that a SQL Warehouse is, or was in the past, a long-running compute resource for SQL workloads that could sit out there in a nebulous manner and run as needed.
In the past I’ve seen BI tools like Tableau hooked to SQL Warehouses as a sort of endpoint. In this case Serverless although expensive, is probably better for not used much Warehouses, wereas classic might still be ok for something that gets hammered all day.
The Serverless Question.
I mean, how in the good Lord have I managed to only mention Serverless compute this whole time when it’s literally being shoved down your unwilling throat at every turn?
Clearly, the writing is on the wall.
Serverless is the desired future of Databricks compute. And, contrary to what you may think, I believe Serverless options are indeed a wise choice in many instances.

Serverless is the natural extension of human laziness and annoyance at having only one option to do something.
Spark resources take a while to spin up
People don’t want to fine-tune resources to workloads
People want simplicity more than low costs
Want to pay for what you use? Want simplicity of use and configuration? Don’t want to spend hours trying to figure out what size Cluster to set up for your Job or another random task?
Serverless is what the masses want, and that’s what they got.
Point and click, baby.
Does it come with a price? Well, if you have been paying attention to the numbers, it does, of course. Does that mean it’s a bad idea? Not at all.
Depends.
It could very well save you a bunch of time, it could very well increase your costs. Will it reduce overhead, complexity, and the like? Yes indeed it will.
This is the part where you get to do what you’re paid to do: be an Engineer, think, and figure out what’s best for your Data Platform, your workloads, and your organization.
Sorry, not sorry.
Hey, I told you from the start I’m not a Databricks Compute savant. I just like talking theoretically about how Databricks approaches these things and the changes I’ve seen over the years.
Here are some good resources to further your Databricks Compute journey that I think you will find interesting.
https://www.reddit.com/r/dataengineering/comments/1gpxcfm/serverless_costs_for_databricks/
https://www.reddit.com/r/databricks/comments/1jnefyv/how_do_you_guys_think_about_costs/
https://docs.databricks.com/aws/en/lakehouse-architecture/cost-optimization/best-practices
https://www.databricks.com/product/pricing/product-pricing/instance-types
Databricks Compute. Thoughts and more.
·
There are two things certain in data engineering life: death and taxes, as well as S3 and EC2 (compute) costs. Both storage and compute costs probably make up 80% of most cloud bills for running a Data Platform, I imagine.

Databricks want a piece of cake on the SQL-oneTrickPony Snowflake users. On their platform, they click a button and a compute instance appears in 2 seconds, and they can run sql.
they cannot orcherstrate jobs like workflows can. they cannot version their ML models like MlFlow can, they cannot version the sql code they love into github, no integration. the data they hold so dear is not in a bucket with a open-source table format that a lot of tools can query, is locked into the platform with a proprietary format that only a warehouse can query.
they are lost man.
> And, contrary to what you may think, I believe Serverless options are indeed a wise choice in many instances.
Till your manager figures out that there are cheaper kind of compute and starts bothering you. Then it will tell you to go with an even cheaper one.
Their platform is becoming every day more overcomplicated, with more tools and options which are often half baked (despite what their marketing says)