

Databricks Compute. Thoughts and more.
dollar bill 'yall


There are two things certain in data engineering life: death and taxes, as well as S3 and EC2 (compute) costs. Both storage and compute costs probably make up 80% of most cloud bills for running a Data Platform, I imagine.
Regarding Databricks and compute, the ground shifts underneath you without anyone noticing it. Sometimes, we get stuck in a rut and simply ignore the goings on in the world of new features and “things” being released. We become blissfully unaware of our options and how we should use them to our advantage.
I don’t pretend to be a Databricks expert, and I need to remind myself to do my due diligence every year or so. Today, I will review compute options inside Databricks for the average semi-informed user.
It will probably form a semi-coherent blob of half-wrong/half-right information regarding options around Databricks compute, and how we might avail ourselves of some cost savings.
Thanks to Delta for sponsoring this newsletter! I personally use Delta Lake on a daily basis, and I believe this technology represents the future of Data Engineering. Check out their website below.

If you and I come away with a clearer picture of compute options, when generally to use each, and possible cost savings or best practices … that’s a win in my book.
Databricks Compute Options. (AWS point of view)
Let’s start with a simple, high-level overview of general compute options for Databricks and their category.
Serverless
SQL Warehouse
both serverless and classic …
Job
All-Purpose

Instead of getting bogged down in the minute details of each compute type and agonizing over which one would save me three pennies over the other one (context is always key) … I generally stick to the big picture.
Job compute at all times because it’s cheap.
SQL Warehouse only if you need to support on-demand analytics with third-party apps (like Tableau).
All-purpose for short-lived Notebook research, etc.
Serverless for a quick question you want an instant answer to.
Try to keep it simple and keep to the obvious way of solving problems. A few nuances can either cost you or save you serious amounts of money.
Do not overuse All-Purpose compute. If you are letting All-Purpose compute run for 8 hours a day so you can “do your job,” you are most likely wasting massive amounts of money.
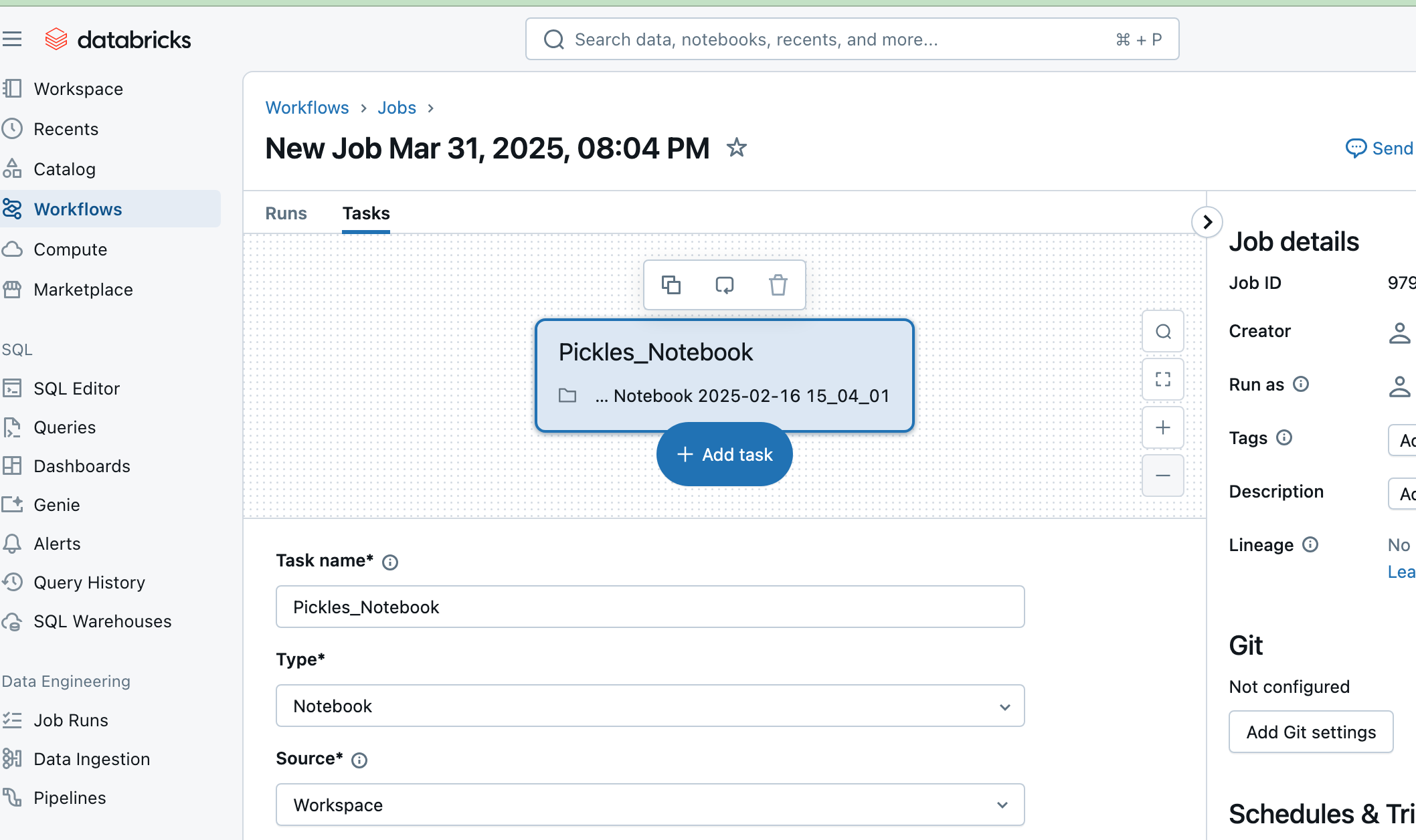
If you have a Notebook that runs a query (or set of them), for more than 30 minutes. Switch it over to a Job!
It’s not that hard. If you *NEED to run something in a Notebook, just go to the Workflows section of the Databricks UI and create a new Job, select your Notebook, etc., and you’ll save everyone money just like that. See below.
Avoid Serverless most of the time; use it for short, quick needs that last only a few minutes.
There’s a lot of changing, including pricing with Serverless; it’s a black box and unclear when you should and should not use it. Be safe and stay away.
If you use a SQL Warehouse, pay attention to what your Scaling looks like. Do you really need three nodes running at all times? Start as low as possible and work your way up.
Did you know you can automate the starting and stopping of a SQL Warehouse? (what would happen if you shut it off between midnight and 5 am??? … you would probably save money, that’s it)

Besides the obvious, what can we do?
Ok, so what if you already know all about the different types of Databricks compute, and you generally use the right tool for the right job? Is there anything else we can do to lower compute usage and cost?
Again, I’m no Databricks savant, but here are a few ideas for you to think about.
Understand the difference between SPOT and ON-DEMAND instances, including WITH FALLBACK.
Almost 99% of Databricks Jobs should use SPOT or SPOT WITH FALLBACK.
It’s not uncommon to save 80% when switching to SPOT clusters.
Use FLEET Clusters when you can.
it auto-selects the best pricing and availability from a pool for you.
Cluster re-use with Databricks Workflows.
Spend 5 minutes tuning your Clusters to the workload.
You should, on a regular schedule, simply analyze all your Jobs that run on a regular basis and see if you can tune them to fit the workload better.
Turn your auto-shut-off settings on All-Purpose clusters to 5 minutes or less. It defaults to something like 45 minutes or something ridiculous.
Make people share Clusters or SQL Warehouses for compute.
Not everyone needs their own compute. Duh.
I think we can stop there for now. That is a good overview of the very basic and most simple things we can do to control and understand Databricks compute costs.
Probably in real life, the answers are a little more nuanced and depend on what your environment looks like and the use cases that most heavily define your workloads.
Like most things in life, it’s the 80/20 rule; the easy stuff probably makes up 80% of the cost overruns or wasted compute that is happening today on your Databricks setup. People getting trigger-happy with their All-Purpose clusters and running them all day, with too many nodes to boot.
Make people pretend they are back in kindergarten, and tell them they can all share a Cluster … wouldn’t kill ‘em, and it will save some bucks.
Overuse Job Compute, if that’s even possible. Turn termination time limits way down. Use SPOT everywhere and FLEET everywhere. To be honest, it is when we get sloppy and stop paying attention that we get in trouble. That’s when your bill starts creeping the wrong way.
We have done a fairly thorough analysis of DBX SL and its use cases across the different applications except AI and find relatively little use for it but that is because we have a platform team and decent cost/utilization monitoring in place. An important thing you should not forget are the VM discounts for bigger orgs e.g. for us on Azure. For the SQL Warehouse Classic compute VM series, we get over 50% in a 3 year pre-purchase. Ofc, this assumes you have decent compute planning and extra usage if you don't use it via DBX, e.g. because same machines may be used in our Kubernetes clusters. That won't be the case for smaller orgs. All-in-all we found that it is really complex to have good cost control and transparency and the more convenient option is certainly to simply use SaaS-like DBX SL.